阿里大數據云原生化實踐,EMR Spark on ACK 產品介紹
一、云原生化挑戰及阿里實踐
大數據技術發展趨勢

云原生化面臨挑戰
計算與存儲分離
如何構建以對象存儲為底座的 HCFS 文件系統
完全兼容現有的 HDFS
性能對標 HDFS,成本降低
shuffle 存算分離
如何解決 ACK 混合異構機型
異構機型沒有本地盤
社區 [Spark-25299] 討論,支持 Spark 動態資源,成為業界共識
緩存方案
如何有效支持跨機房、跨專線混合云
需要在容器內支持緩存系統
ACK 調度
如何解決調度性能瓶頸
性能對標 Yarn
多級隊列管理
其他
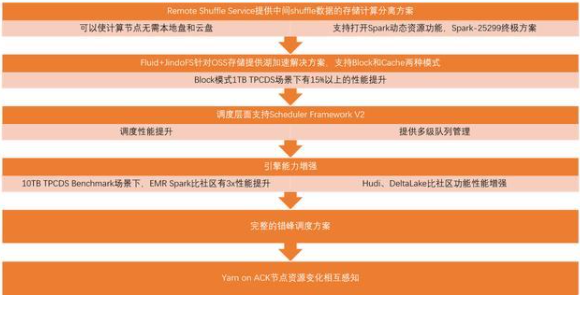
錯峰調度
Yarnon ACK 節點資源相互感知
阿里實踐 - EMR on ACK
整體方案介紹
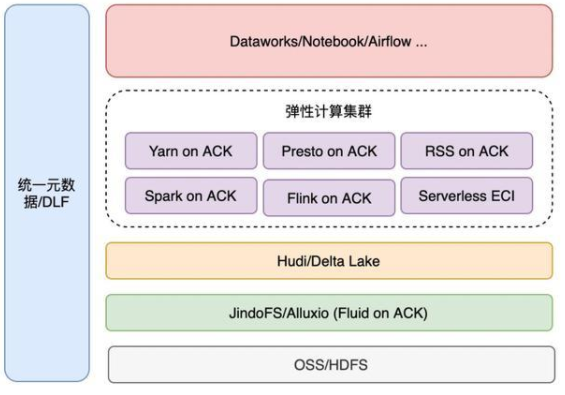
通過數據開發集群/調度平臺提交到不同的執行平臺
錯峰調度,根據業務高峰低峰策略調整
云原生數據湖架構,ACK 彈性擴縮容能力強
通過專線,云上云下混合調度
ACK 管理異構機型集群,靈活性好
二、Spark 容器化方案
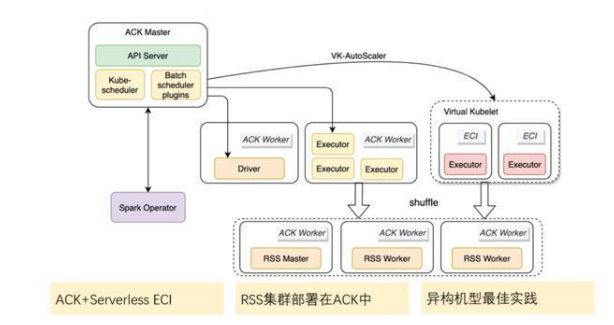
方案介紹
RSS Q&A
1、為什么需要 Remote Shuffle Service?
RSS 使得 Spark 作業不需要 Executor Pod 掛載云盤。掛載云盤非常不利于擴展性和大規模的生產實踐。
云盤的大小無法事前確定,大了浪費空間,小了 Shuffle 會失敗。RSS 專門為存儲計算分離場景設計。
Executor 將 shuffle 數據寫入了 RSS 系統,RSS 系統來負責管理 shuffle 數據,Executor 空閑后即可以回收。[SPARK-25299]
可以完美支持動態資源,避免數據傾斜的長尾任務拖住 Executor 資源不能釋放。
2、RSS 性能如何,成本如何,擴展性如何?
RSS 對于 shuffle 有很深的優化,專門為存儲與計算分離場景、K8s 彈性場景而設計。
針對 Shufflefetch 階段,可以將 reduce 階段的隨機讀變為順序讀,大大提升了作業的穩定性和性能。
可以直接利用原有 K8s 集群中的磁盤進行部署,不需要加多余的云盤來進行 shuffle。性價比非常高,部署方式靈活。
Spark Shuffle
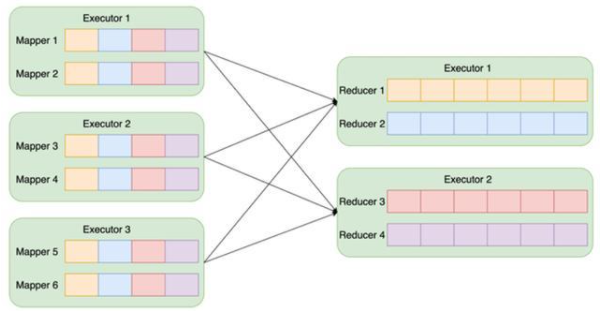
產生 numMapper * numReducer 個 block
順序寫、隨機讀
寫時 Spill
單副本,丟數據需 stage 重算
EMR Remote Shuffle Service
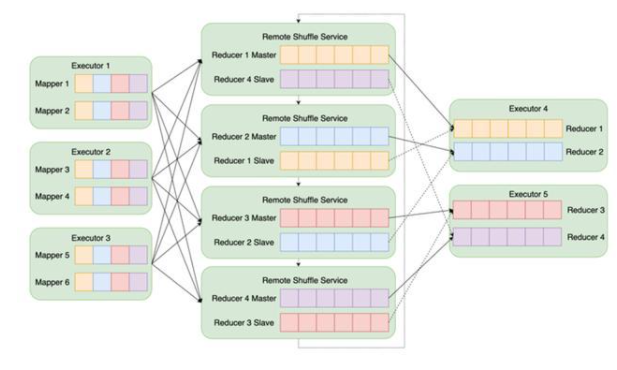
追加寫、順序讀
無寫時 Spill
兩副本;副本復制到內存后即完成
副本之間通過內網備份,無需公網帶寬
RSS TeraSort Benchmark
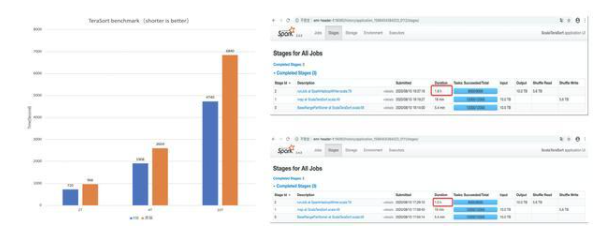
備注說明:以10T Terasort 為例,shuffle 量壓縮后大約 5.6T。可以看出該量級的作業在 RSS 場景下,由于 shuffle read 變為順序讀,性能會有大幅提升。
Spark on ECI 效果
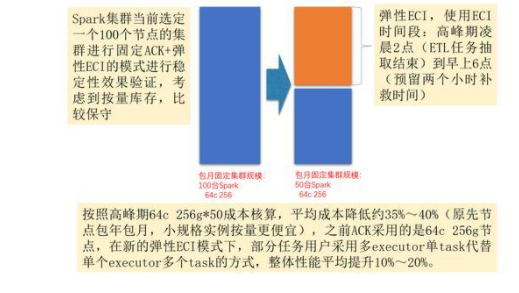
Summary