新一代云原生數據倉庫 AnalyticDB「SQL 智能診斷」功能詳解
SQL是一種簡單易用的業務邏輯表達語言,但隨著掃描數據量和查詢復雜度的增加,查詢性能會變得越來越慢。想要對SQL進行調優,往往需要關注以下幾個部分:
需要了解引擎架構:用戶往往需要對SQL引擎的架構特點有一定的了解,才能和業務的數據分布特征以及業務場景特征完美結合,來進行數據建模,從而設計出符合SQL引擎架構特點的表結構。
SQL特征差異較大:即席查詢的SQL往往變化較大,包括參與Join的表個數、Join條件、分組聚合的字段個數以及過濾條件等。
數據特征差異較大:用戶的數據分布特征是會隨著業務特征的變化而變化的,如果一直按照最初的建模方式和SQL語句,也是無法保障能發揮出SQL引擎的最大優勢,數據特征或者業務模型的變化,都會導致SQL性能回退。
基于此,AnalyticDB For MySQL(新一代云原生實時數據倉庫,語法兼容MySQL,以下簡稱ADB)為用戶提供了高效、實時、功能豐富并且智能化的「SQL智能診斷」和「SQL智能調優」功能,提供用戶SQL性能調優的思路、方向和具體的方法,降低用戶使用成本,提高用戶使用ADB的效率。
下面我們通過「發現慢查詢」+「診斷慢查詢」兩個步驟,并結合一個場景Case,來介紹ADB新發布的「SQL智能診斷」功能。(PS:「SQL智能調優」會在后續版本中發布)
一、發現慢查詢
用戶要定位慢查詢,首先需要找到慢查詢。ADB的用戶控制臺提供了多樣的方式來幫助用戶,例如「甘特圖」和「查詢列表」等,都可以在多個維度進行檢索,幫助用戶快速定位慢查詢,而且診斷工具確保用戶可以進行最近兩周的全量查詢檢索和分析。
(一)甘特圖
用戶可以通過「集群控制臺」-「診斷與優化」 - 「SQL診斷」進入SQL智能診斷功能。
首先會看到一個甘特圖(也稱泳道圖,查詢從不同的泳道流過,這里的泳道并不是ADB的查詢隊列,只是為了區分開不同時間執行的查詢),甘特圖以圖形化的方式形象的展示了查詢在ADB實例上的執行順序,每個色塊表示了一條查詢,色塊左側為查詢的提交時間,色塊右側為查詢的結束時間,色塊的相對長度表示了某條查詢的執行時間,色塊的顏色沒有特殊含義,只是為了區分不同的泳道。

通過甘特圖,用戶可以非常直觀的看到當前時間范圍內執行耗時較長的查詢,并且可以直觀的看到哪些查詢是在并行的執行以及并行執行的時間段,這可以幫助用戶判斷出哪些查詢是受到了某條Bad SQL的影響。色塊的密集度則可以用來直觀的判斷ADB實例壓力較大的時段是否和某些查詢的并發度較高相關。
(二)查詢列表
甘特圖能夠以直觀的方式體現出查詢之間的時間相關性,但是當用戶選擇的時間范圍較大,甘特圖中的色塊會密集分布不容易分辨,而且甘特圖上的指標較為有限,此時用戶可以使用診斷工具中的查詢列表功能。查詢列表提供了多大10余項查詢級別的重要指標,例如數據庫名、用戶名、客戶端段IP、耗時、消耗內存以及掃描量等,這些信息和指標可以幫助用戶進一步判斷慢查詢的來源和資源消耗等。
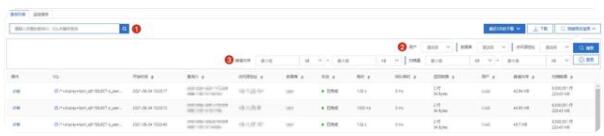
高級檢索能力方面,診斷工具提供了三種類型的檢索方法:
1.模糊檢索和精確檢索:用戶可以根據SQL中的關鍵字進行模糊匹配,精確檢索功能則幫助用戶在確定查詢ID的情況下,精確的檢索到這條查詢;
2.字符串類型的檢索條件:檢索工具會自動識別出用戶所選時間范圍內使用的數據名、用戶名、客戶端IP以及資源組等,提供下拉框的形式供用戶選擇,提高用戶檢索效率;
3.數值類型的檢索條件:用戶可以自由選擇檢索的指標單位,例如KB、MB、GB等,不需要進行手動的換算。
同時,用戶在使用診斷工具時,往往有對慢查詢的下載需求,下載后的慢查詢可以在例如Excel等工具中進行更多自定義的慢查詢治理和分析,所以我們也提供了查詢列表的下載功能。
二、診斷慢查詢
(一)查詢在ADB中的執行流程
在介紹ADB執行流程前需要簡單介紹一下三個相關的基本概念:
Stage
在執行階段,ADB中的查詢會首先根據是否產生Shuffle被切分為多個Stage來執行,一個Stage就是執行計劃中某一部分的物理實體。Stage的數據來源可以是底層存儲系統中的數據或者網絡中傳輸的數據,一個Stage由分布在不同計算節點上相同類型的Task組成,多個Task會并行處理數據。
Task
Task是一個Stage在某個Executor節點上的執行實體,多個同類型的Task組成一個Stage,在集群內部并行處理數據。
Operator
Operator(算子)是ADB的最小數據處理單元。ADB會根據算子所表達的語義或算子間的依賴關系,決定使用并行還是串行執行來處理數據。
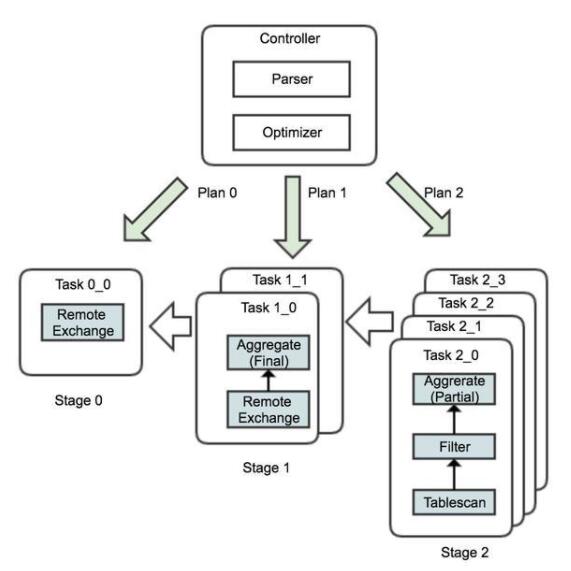
下面以一個典型的分局聚合查詢為例來了解ADB中查詢的執行流程,SQL語句如下:
- SELECT COUNT(*), SUM(salary)
- FROM emplayee
- WHERE age>30 ADN age<32
- GROUP BY sex
在ADB內部,首先由前端的Controller節點接收SQL語句請求,并對SQL語句進行語句解析和語法分析(Parser),最后使用優化器(Optimizer)生成最終的執行計劃,整體執行計劃會根據Stage的劃分原則被切分為子計劃,如圖中的Plan0、Plan1和Plan2,分別被下發到對應的節點上。
其中子計劃Plan2會并行的在4個計算節點上以Task實例的形式處理數據,首先執行數據的掃描和過濾,然后執行數據的局部聚合,處理完之后的數據會根據sex字段Repartition到下游的計算節點,即Stage1的節點,按照子計劃Plan1的要求執行數據的最終聚合。最后,數據由Stage0的節點匯總并返回到客戶端。
和典型的數據倉庫一樣,ADB的執行計劃一般分為「邏輯執行計劃」和「物理執行計劃」:
邏輯執行計劃:宏觀層面了解查詢的處理流程
邏輯執行計劃在較高的層面展示查詢的處理邏輯,基于規則的執行計劃(RBO)會判斷過濾條件是否可以下推,而基于代價的執行計劃(CBO)會判斷出多表關聯時的順序等。所以邏輯執行計劃并不關注在物理執行時的具體處理方式,例如是否在執行時需要對多個算子進行融合以減少函數調用,或者自動生成代碼的粒度,這些邏輯執行計劃并不關注,這也就導致了邏輯執行計劃往往只包含了Stage級別的執行統計信息。但是用戶調優時往往是需要精確到算子級別的統計信息。
物理執行計劃:微觀層面了解每個算子的處理性能
相對于邏輯執行計劃,物理執行計劃包含了算子間的數據處理流圖,也包含了算子的執行統計信息,可以精確的看到某個Join算子或者聚合算子占用的內存,也可以看到過濾算子過濾前后的數據量。但是并不是所有的算子用戶都需要能正確理解其含義,特別是有些物理算子和用戶的SQL語句找不到關聯之處,這也會給用戶單獨使用物理執行計劃定位問題帶來較大的疑惑。
ADB的「SQL智能診斷」功能,提供給了用戶一個邏輯執行計劃和物理執行計劃的融合視圖,用戶使用融合的執行計劃即可以從宏觀層面了解查詢的處理流程,也可以從微觀層面了解每個算子的處理性能,從而可以更加準確快速的幫助用戶定位查詢的性能瓶頸點。
(二)SQL自診斷功能
雖然我們提供了融合的和分層的執行計劃來幫助用戶分析查詢的性能問題,但是我們發現在兩類場景中用戶使用融合執行計劃會遇到困難:
ADB的初級使用者
ADB為了減少MySQL用戶的學習和遷移成本,做到了絕大多數語法和MySQL兼容,但是ADB的后臺并非MySQL內核,而是獨立自研的一套分布式數據存儲和分布式計算系統,面對ADB的執行計劃,ADB的初級使用者往往不知道優化的重點在哪里,無從下手。
ADB中的復雜SQL
對于復雜的SQL,往往涉及幾百張表的連接操作,Stage個數會達到幾百個以上,算子個數更是會達到上千,執行計劃圖非常大,即使是ADB的高級使用者,面對這樣復雜的執行計劃,往往也無從下手,如下圖是個196個Stage的執行計劃圖:

針對以上問題,我們在執行計劃圖中加入了SQL自診斷能力,SQL自診斷能力會將專家經驗以規則的形式體現在執行計劃中,對于ADB的初次接觸者,即可以根據診斷結果確定查詢執行過程中的性能瓶頸點,也可以根據診斷結果學習到ADB執行計劃中需要關注的重點算子。針對復雜執行計劃,SQL自診斷可以幫助用戶快速定位到執行計劃中需要調優的位置,并提供了調優的相關方法和文檔,讓用戶在調優過程中更有針對性。
SQL自診斷能力通過「Query級別診斷結果」、「Stage級別診斷結果」、「算子級別診斷結果」這三層來展示診斷結果和優化建議。
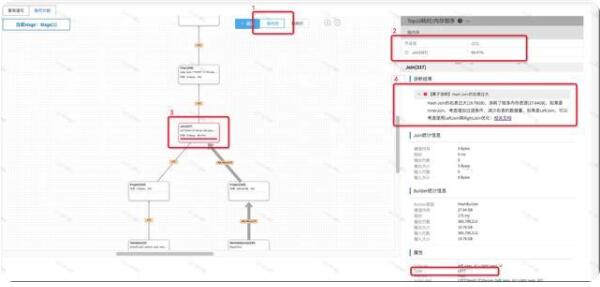
我們以一個線上的復雜SQL為例來介紹使用執行計劃和SQL自診斷工具來進行性能問題定位的例子。首先我們通過慢查詢檢索工具搜索到一個內存消耗較大的查詢,點擊「診斷」打開該查詢的診斷頁面,切換到「執行計劃」頁簽,我們會看到查詢級別診斷結果已經判斷出當前查詢數據一個內存消耗較大的查詢,如下圖中的1所示:
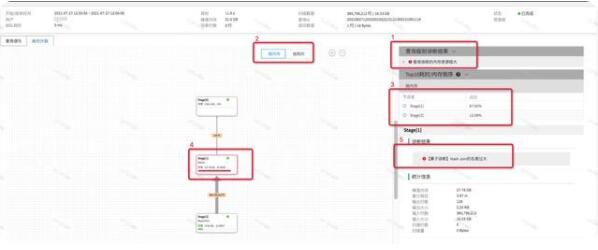
這時,我們需要定位內存效果較大的原因,我們點擊按內存排序,可以看到在右側,會根據Stage消耗的內存百分比進行了倒敘排序,可以非常明顯的看出,Stage[1]占用的當前查詢87%以上的內存比例,我們點擊Stage[1],診斷工具會自動聚焦到執行計劃樹的Stage[1]的位置,點擊Stage[1],我們可以看到Stage[1]的執行統計信息,同時,我們可以看到在5的位置,提示我們當前Stage1內部有個算子占用內存較大,但是并沒有詳細信息,所以接下來,我們需要進入到Stage[1]的內部,看看Stage[1]具體是哪個算子占用了較多內存。
點擊「查看Stage執行計劃」,進入到Stage[1]內部,首先,我們依然根據內存排序,可以看到,其中的Join[317]這個算子占用了整個Stage 99%以上的內存,點擊該算子,算子執行計劃樹自動定位到當前算子,這時我們就可以看到算子診斷結果的詳細信息了,信息提示我們,在構建Hash表用戶Left Join時,占用了較大的內存,診斷結果還提供了官方的調優文檔鏈接,根據文檔中給出的調優方法,我們就可以減少該算子的內存占用。
以上的例子通過「查詢級別診斷結果」和「算子級別診斷結果」進行SQL性能問題定位的方法,我們再來看一個「Stage級別診斷結果」的例子。
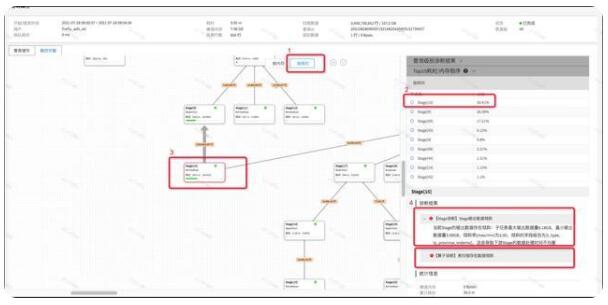
如下圖所示,我們可以看到根據耗時排序后,Stage[10]的耗時比例最大,點擊執行計劃圖中的Stage[10],可以在診斷結果欄看到兩類診斷結果,一類是“Stage診斷”,一類是“算子診斷”,其中的Stage診斷告訴我們當前Stage的輸出數據有傾斜,并且告訴我們傾斜的字段是哪些(數據傾斜是分布式系統中嚴重影響性能的問題,Stage輸出數據傾斜不但會當時當前Stage處理數據在時間上存在長尾,而且會導致下游的數據處理存在長尾),同時可以看到有一個算子診斷結果,提示我們表掃描存在傾斜,那么我們可以初步判斷當前Stage輸出數據傾斜是因為掃描了一個數據傾斜的表導致的。接下來我們進入到Stage[0]內部進行定位和分析。
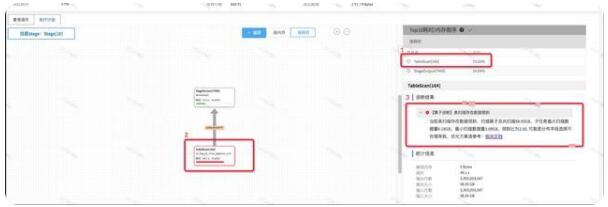
進入到Stage內存,我們根據耗時排序,可以看到TableScan算子耗時最大,這時我們點擊TableScan算子,可以看到在診斷結果里,有關于該表數據傾斜的詳細診斷結果信息,這張表由于數據分布字段選擇的不合適,存在嚴重的數據傾斜問題,同時可以看到有相關的官方調優文檔,我們根據調優文檔,就可以調整為合適的分布字段,減少表數據傾斜對查詢性能的影響。
通過以上的兩個例子,我們可以看到,融合執行計劃和SQL自診斷功能,可以快速的幫我們定位到查詢的性能問題,并給出一定的調優建議,減少大量不必要的時間和精力的浪費,降低了初級使用者使用ADB的門檻。關于SQL自診斷更多的診斷結果可以參考官網文檔:SQL自診斷,目前已經有20+診斷規則上線,涉及查詢相關的內存消耗、耗時、數據傾斜、磁盤IO以及執行計劃等多個方面,后續還有更多診斷規則陸續上線。
三、 后續規劃
通過以上的闡述和例子分析,可以看到當前的診斷調優工具已經可以幫助用戶進行多方面的SQL性能問題排查,但是我們在實際的線上問題處理和值班時仍然發現總結了多個用戶在分析實例性能問題時的需求:
我應該調優哪些SQL?
用戶在打開診斷調優頁面時,面對實例上運行的上萬甚至上千萬條SQL,雖然可以通過耗時、內存消耗或者掃描量等進行排序來初步篩選出需要調優的SQL,但是其實其實用戶欠缺了一個特定診斷結果的視角,例如:
哪些SQL是數據掃描傾斜的?
哪些SQL是索引過濾不高效的?
哪些SQL是Stage輸出傾斜的?
哪些SQL是分區選擇不合理的?
用戶在針對某一個SQL的特定診斷結果調優完成后,其實需要知道有哪些類似的SQL都需要調優的,所以我們后續會提供給用戶一個從特定診斷結果維度進行分析的工具,一次性地解決某個特定問題。
我的SQL有問題,和建表方式不優有關嗎?
ADB后臺是一個分布式的數據存儲和分布式的執行框架,依賴數據均勻的分布到各個后臺節點上,同時ADB針對不同的業務場景設計了不同的表類型,例如分區表、復制表,有些表字段在存儲時進行聚集存儲,也會提升查詢性能,但是用戶往往不知道建表方式不優到底影響了哪些查詢。后續我們會把「數據建模診斷結果」和「查詢診斷結果」關聯,用戶通過數據建模的診斷結果即可快速知道不良的表結構影響了哪些SQL,同時反過來也可以通過某條SQL的診斷結果知道哪些表需要優化。兩類診斷結果聯動調優,可以從根源上解決實例的查詢性能問題。