在理解通用近似定理之前,你可能都不會理解神經網絡
此前,圖靈獎得主、深度學習先驅 Yann LeCun 的一條推文引來眾多網友的討論。
在該推文中,LeCun 表示:「深度學習并不像你想象的那么令人印象深刻,因為它僅僅是通過曲線擬合產生的插值結果。但在高維空間中,不存在插值這樣的情況。在高維空間中,一切都是外推。」

而 LeCun 轉發的內容來自哈佛認知科學家 Steven Pinker 的一條推文,Pinker 表示:「 通用近似定理很好地解釋了為什么神經網絡能工作以及為什么它們經常不起作用。只有理解了 Andre Ye 的通用近似定理,你才能理解神經網絡。」

Pinker 所提到的 Andre Ye,正是接下來要介紹《You Don’t Understand Neural Networks Until You Understand the Universal Approximation Theorem》文章的作者。雖然該文章是去年的,但在理解神經網絡方面起到非常重要的作用。
在人工神經網絡的數學理論中, 通用近似定理(或稱萬能近似定理)指出人工神經網絡近似任意函數的能力。通常此定理所指的神經網絡為前饋神經網絡,并且被近似的目標函數通常為輸入輸出都在歐幾里得空間的連續函數。但亦有研究將此定理擴展至其他類型的神經網絡,如卷積神經網絡、放射狀基底函數網絡、或其他特殊神經網絡。
此定理意味著神經網絡可以用來近似任意的復雜函數,并且可以達到任意近似精準度。但它并沒有告訴我們如何選擇神經網絡參數(權重、神經元數量、神經層層數等等)來達到我們想近似的目標函數。
1989 年,George Cybenko 最早提出并證明了單一隱藏層、任意寬度、并使用 S 函數作為激勵函數的前饋神經網絡的通用近似定理。兩年后 1991 年,Kurt Hornik 研究發現,激活函數的選擇不是關鍵,前饋神經網絡的多層神經層及多神經元架構才是使神經網絡有成為通用逼近器的關鍵
最重要的是,該定理解釋了為什么神經網絡似乎表現得如此聰明。理解它是發展對神經網絡深刻理解的關鍵一步。
更深層次的探索
緊湊(有限、封閉)集合上的任何連續函數都可以用分段函數逼近。以 - 3 和 3 之間的正弦波為例,它可以用三個函數來近似——兩個二次函數和一個線性函數,如下圖所示。
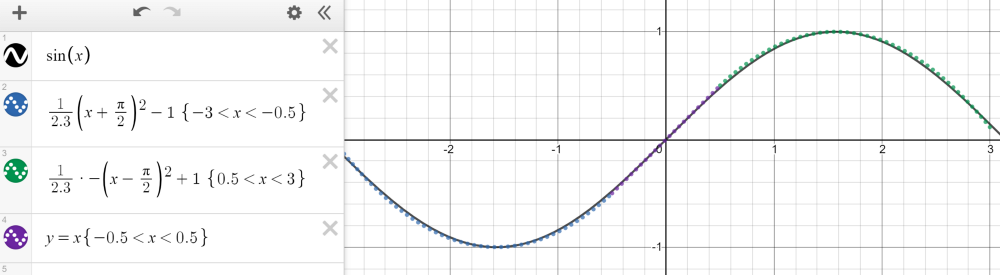
然而,Cybenko 對這個分段函數描述更為具體,因為它可以是恒定,本質上通過 step 來擬合函數。有了足夠多的恒定域 (step),我們就可以在給定的范圍內合理地估計函數。
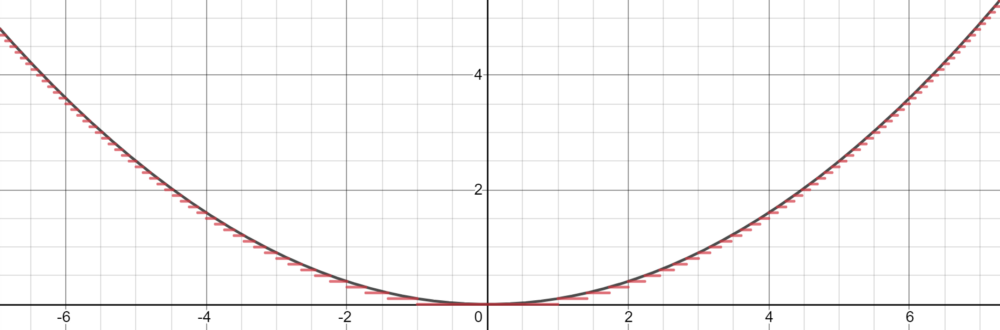
基于這種近似,我們可以將神經元當做 step 來構建網絡。利用權值和偏差作為「門」來確定哪個輸入下降,哪個神經元應該被激活,一個有足夠數量神經元的神經網絡可以簡單地將一個函數劃分為幾個恒定區域來估計。
對于落在神經元下降部分的輸入信號,通過將權重放大到較大的值,最終的值將接近 1(當使用 sigmoid 函數計算時)。如果它不屬于這個部分,將權重移向負無窮將產生接近于 0 的最終結果。使用 sigmoid 函數作為某種處理器來確定神經元的存在程度,只要有大量的神經元,任何函數都可以近乎完美地近似。在多維空間中,Cybenko 推廣了這一思想,每個神經元在多維函數中控制空間的超立方體。
通用近似定理的關鍵在于,它不是在輸入和輸出之間建立復雜的數學關系,而是使用簡單的線性操作將復雜的函數分割成許多小的、不那么復雜的部分,每個部分由一個神經元處理。
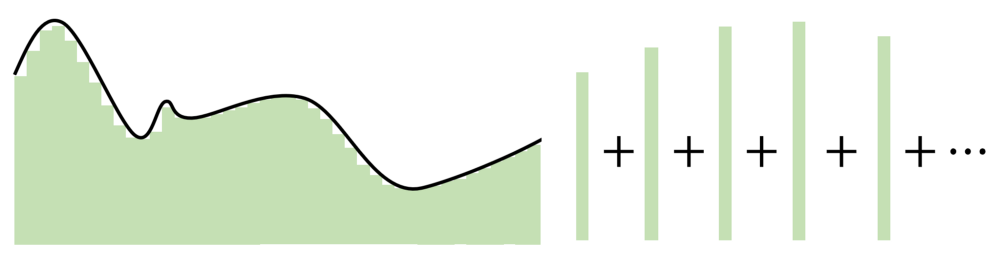
自 Cybenko 的初始證明以后,學界已經形成了許多新的改進,例如針對不同的激活函數(例如 ReLU),或者具有不同的架構(循環網絡、卷積等)測試通用近似定理。
不管怎樣,所有這些探索都圍繞著一個想法——神經網絡在神經元數量中找到優勢。每個神經元監視特征空間的一個模式或區域,其大小由網絡中神經元的數量決定。神經元越少,每個神經元需要監視的空間就越多,因此近似能力就會下降。但是,隨著神經元增多,無論激活函數是什么,任何函數都可以用許多小片段拼接在一起。
泛化和外推
有人可能指出,通用近似定理雖然簡單,但有點過于簡單(至少在概念上)。神經網絡可以分辨數字、生成音樂等,并且通常表現得很智能,但實際上只是一個復雜的逼近器。
神經網絡旨在對給定的數據點,能夠建模出復雜的數學函數。神經網絡是個很好的逼近器,但是,如果輸入超出了訓練范圍,它們就失去了作用。這類似于有限泰勒級數近似,在一定范圍內可以擬合正弦波,但超出范圍就失效了。

外推,或者說在給定的訓練范圍之外做出合理預測的能力,這并不是神經網絡設計的目的。從通用近似定理,我們了解到神經網絡并不是真正的智能,而是隱藏在多維度偽裝下的估計器,在二維或三維中看起來很普通。
定理的實際意義
當然,通用逼近定理假設可以繼續向無窮大添加神經元,這在實踐中是不可行的。此外,使用神經網絡近乎無限的參數組合來尋找性能最佳的組合也是不切實際的。然而,該定理還假設只有一個隱藏層,并且隨著添加更多隱藏層,復雜性和通用逼近的潛力呈指數增長。
取而代之的是,機器學習工程師依據直覺和經驗決定了如何構造適合給定問題的神經網絡架構,以便它能夠很好地逼近多維空間,知道這樣一個網絡的存在,但也要權衡計算性能。