Kafka大廠高頻面試題:在保證高性能、高吞吐的同時保證高可用性
Kafka的消息傳輸保障機制非常直觀。當producer向broker發送消息時,一旦這條消息被commit,由于副本機制(replication)的存在,它就不會丟失。但是如果producer發送數據給broker后,遇到的網絡問題而造成通信中斷,那producer就無法判斷該條消息是否已經提交(commit)。雖然Kafka無法確定網絡故障期間發生了什么,但是producer可以retry多次,確保消息已經正確傳輸到broker中,所以目前Kafka實現的是at least once。

一、冪等性
1.場景
所謂冪等性,就是對接口的多次調用所產生的結果和調用一次是一致的。生產者在進行重試的時候有可能會重復寫入消息,而使用Kafka的冪等性功能就可以避免這種情況。
冪等性是有條件的:
只能保證 Producer 在單個會話內不丟不重,如果 Producer 出現意外掛掉再重啟是無法保證的(冪等性情況下,是無法獲取之前的狀態信息,因此是無法做到跨會話級別的不丟不重)。
冪等性不能跨多個 Topic-Partition,只能保證單個 partition 內的冪等性,當涉及多個Topic-Partition 時,這中間的狀態并沒有同步。
Producer 使用冪等性的示例非常簡單,與正常情況下 Producer 使用相比變化不大,只需要把Producer 的配置 enable.idempotence 設置為 true 即可,如下所示:
- Properties props = new Properties();
- props.put(ProducerConfig.ENABLE_IDEMPOTENCE_CONFIG, "true");
- props.put("acks", "all"); // 當 enable.idempotence 為 true,這里默認為 all
- props.put("bootstrap.servers", "localhost:9092");
- props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
- props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
- KafkaProducer producer = new KafkaProducer(props);
- producer.send(new ProducerRecord(topic, "test");
二、事務
1.場景
冪等性并不能跨多個分區運作,而事務可以彌補這個缺憾,事務可以保證對多個分區寫入操作的原子性。操作的原子性是指多個操作要么全部成功,要么全部失敗,不存在部分成功部分失敗的可能。
為了實現事務,網絡故障必須提供唯一的transactionalId,這個參數通過客戶端程序來進行設定。
見代碼庫:
com.heima.kafka.chapter7.ProducerTransactionSend
- properties.put(ProducerConfig.TRANSACTIONAL_ID_CONFIG, transactionId);
2.前期準備
事務要求生產者開啟冪等性特性,因此通過將transactional.id參數設置為非空從而開啟事務特性的同時需要將ProducerConfig.ENABLE_IDEMPOTENCE_CONFIG設置為true(默認值為true),如果顯示設置為false,則會拋出異常。
KafkaProducer提供了5個與事務相關的方法,詳細如下:
- //初始化事務,前提是配置了transactionalId
- public void initTransactions()
- //開啟事務
- public void beginTransaction()
- //為消費者提供事務內的位移提交操作
- public void sendOffsetsToTransaction(Map<TopicPartition, OffsetAndMetadata> offsets, String consumerGroupId)
- //提交事務
- public void commitTransaction()
- //終止事務,類似于回滾
- public void abortTransaction()
3.案例解析
見代碼庫:
- com.heima.kafka.chapter7.ProducerTransactionSend
消息發送端
- /**
- * Kafka Producer事務的使用
- */
- public class ProducerTransactionSend {
- public static final String topic = "topic-transaction";
- public static final String brokerList = "localhost:9092";
- public static final String transactionId = "transactionId";
- public static void main(String[] args) {
- Properties properties = new Properties();
- properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
- properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
- properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, brokerList);
- properties.put(ProducerConfig.TRANSACTIONAL_ID_CONFIG, transactionId);
- KafkaProducer<String, String> producer = new KafkaProducer<> (properties);
- producer.initTransactions();
- producer.beginTransaction();
- try {
- //處理業務邏輯并創建ProducerRecord
- ProducerRecord<String, String> record1 = new ProducerRecord<>(topic, "msg1");
- producer.send(record1);
- ProducerRecord<String, String> record2 = new ProducerRecord<>(topic, "msg2");
- producer.send(record2);
- ProducerRecord<String, String> record3 = new ProducerRecord<>(topic, "msg3");
- producer.send(record3);
- //處理一些其它邏輯
- producer.commitTransaction();
- } catch (ProducerFencedException e) {
- producer.abortTransaction();
- }
- producer.close();
- }
- }
模擬事務回滾案例
- try {
- //處理業務邏輯并創建ProducerRecord
- ProducerRecord<String, String> record1 = new ProducerRecord<>(topic, "msg1");
- producer.send(record1);
- //模擬事務回滾案例
- System.out.println(1/0);
- ProducerRecord<String, String> record2 = new ProducerRecord<>(topic, "msg2");
- producer.send(record2);
- ProducerRecord<String, String> record3 = new ProducerRecord<>(topic, "msg3");
- producer.send(record3);
- //處理一些其它邏輯
- producer.commitTransaction();
- } catch (ProducerFencedException e) {
- producer.abortTransaction();
- }
從上面案例中,msg1發送成功之后,出現了異常事務進行了回滾,則msg1消費端也收不到消息。
三、控制器
在Kafka集群中會有一個或者多個broker,其中有一個broker會被選舉為控制器(Kafka Controller),它負責管理整個集群中所有分區和副本的狀態。當某個分區的leader副本出現故障時,由控制器負責為該分區選舉新的leader副本。當檢測到某個分區的ISR集合發生變化時,由控制器負責通知所有broker更新其元數據信息。當使用kafka-topics.sh腳本為某個topic增加分區數量時,同樣還是由控制器負責分區的重新分配。
Kafka中的控制器選舉的工作依賴于Zookeeper,成功競選為控制器的broker會在Zookeeper中創建/controller這個臨時(EPHEMERAL)節點,此臨時節點的內容參考如下:
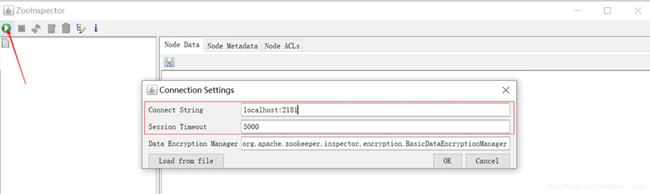
1.ZooInspector管理
使用zookeeper圖形化的客戶端工具(ZooInspector)提供的jar來進行管理,啟動如下:
- 定位到jar所在目錄
- 運行jar文件 java -jar zookeeper-dev-ZooInspector.jar
- 連接Zookeeper
- {"version":1,"brokerid":0,"timestamp":"1529210278988"}
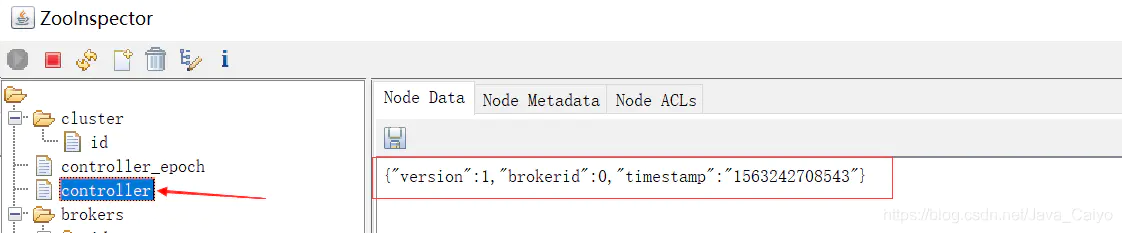
其中version在目前版本中固定為1,brokerid表示稱為控制器的broker的id編號,timestamp表示競選稱為控制器時的時間戳。
在任意時刻,集群中有且僅有一個控制器。每個broker啟動的時候會去嘗試去讀取/controller節點的brokerid的值,如果讀取到brokerid的值不為-1,則表示已經有其它broker節點成功競選為控制器,所以當前broker就會放棄競選;如果Zookeeper中不存在/controller這個節點,或者這個節點中的數據異常,那么就會嘗試去創建/controller這個節點,當前broker去創建節點的時候,也有可能其他broker同時去嘗試創建這個節點,只有創建成功的那個broker才會成為控制器,而創建失敗的broker則表示競選失敗。每個broker都會在內存中保存當前控制器的brokerid值,這個值可以標識為activeControllerId。
Zookeeper中還有一個與控制器有關的/controller_epoch節點,這個節點是持久(PERSISTENT)節點,節點中存放的是一個整型的controller_epoch值。controller_epoch用于記錄控制器發生變更的次數,即記錄當前的控制器是第幾代控制器,我們也可以稱之為“控制器的紀元”。

controller_epoch的初始值為1,即集群中第一個控制器的紀元為1,當控制器發生變更時,沒選出一個新的控制器就將該字段值加1。每個和控制器交互的請求都會攜帶上controller_epoch這個字段,如果請求的controller_epoch值小于內存中的controller_epoch值,則認為這個請求是向已經過期的控制器所發送的請求,那么這個請求會被認定為無效的請求。如果請求的controller_epoch值大于內存中的controller_epoch值,那么則說明已經有新的控制器當選了。由此可見,Kafka通過controller_epoch來保證控制器的唯一性,進而保證相關操作的一致性。
具備控制器身份的broker需要比其他普通的broker多一份職責,具體細節如下:
- 監聽partition相關的變化。
- 監聽topic相關的變化。
- 監聽broker相關的變化。
- 從Zookeeper中讀取獲取當前所有與topic、partition以及broker有關的信息并進行相應的管理。
四、可靠性保證
- 可靠性保證:確保系統在各種不同的環境下能夠發生一致的行為
- Kafka的保證
- 保證分區消息的順序如果使用同一個生產者往同一個分區寫入消息,而且消息B在消息A之后寫入那么Kafka可以保證消息B的偏移量比消息A的偏移量大,而且消費者會先讀取消息A再讀取消息B
- 只有當消息被寫入分區的所有同步副本時(文件系統緩存),它才被認為是已提交
- 生產者可以選擇接收不同類型的確認,控制參數 acks
- 只要還有一個副本是活躍的,那么已提交的消息就不會丟失
- 消費者只能讀取已經提交的消息
1. 失效副本
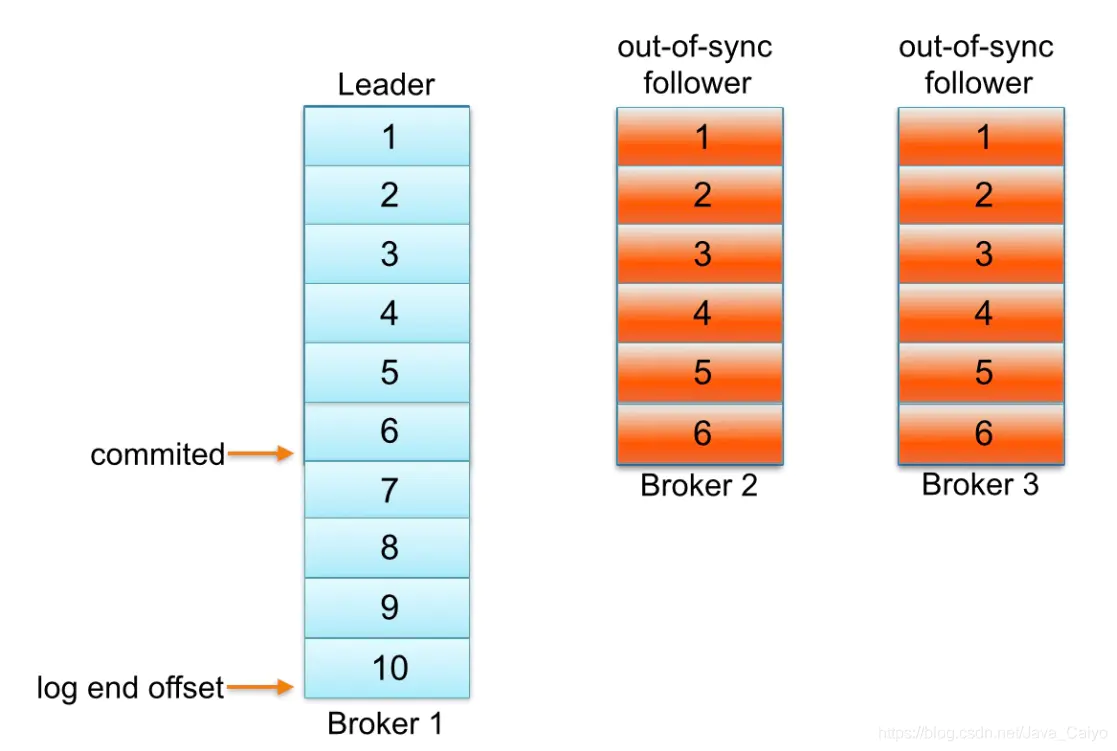
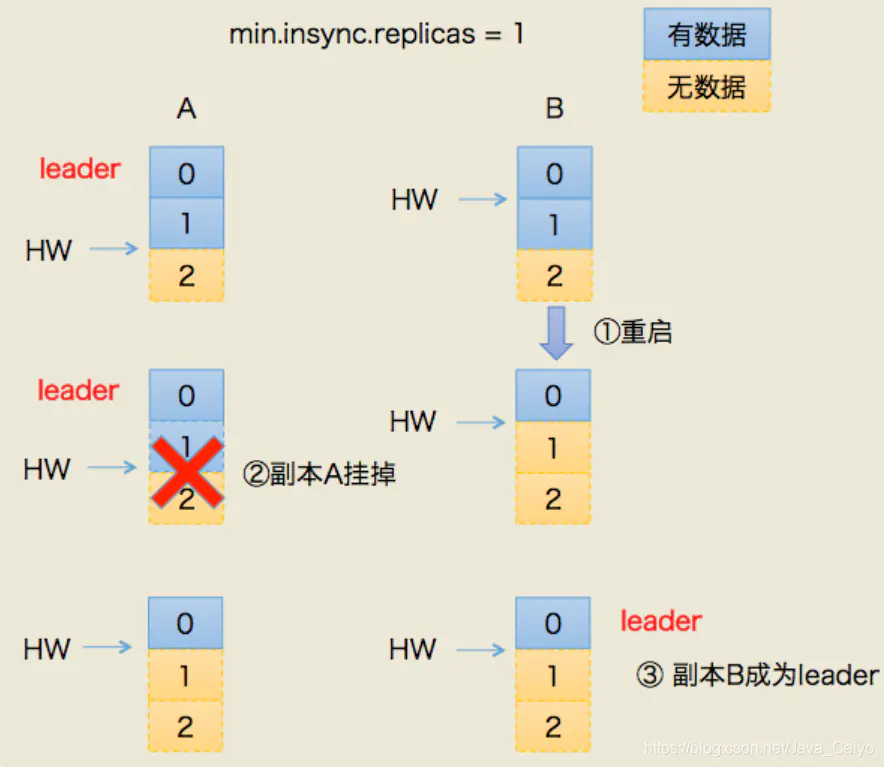
怎么樣判定一個分區是否有副本是處于同步失效狀態的呢?從Kafka 0.9.x版本開始通過唯一的一個參數replica.lag.time.max.ms(默認大小為10,000)來控制,當ISR中的一個follower副本滯后leader副本的時間超過參數replica.lag.time.max.ms指定的值時即判定為副本失效,需要將此follower副本剔出除ISR之外。具體實現原理很簡單,當follower副本將leader副本的LEO(Log End Offset,每個分區最后一條消息的位置)之前的日志全部同步時,則認為該follower副本已經追趕上leader副本,此時更新該副本的lastCaughtUpTimeMs標識。Kafka的副本管理器(ReplicaManager)啟動時會啟動一個副本過期檢測的定時任務,而這個定時任務會定時檢查當前時間與副本的lastCaughtUpTimeMs差值是否大于參數replica.lag.time.max.ms指定的值。千萬不要錯誤地認為follower副本只要拉取leader副本的數據就會更新lastCaughtUpTimeMs,試想當leader副本的消息流入速度大于follower副本的拉取速度時,follower副本一直不斷的拉取leader副本的消息也不能與leader副本同步,如果還將此follower副本置于ISR中,那么當leader副本失效,而選取此follower副本為新的leader副本,那么就會有嚴重的消息丟失。
2.副本復制
Kafka 中的每個主題分區都被復制了 n 次,其中的 n 是主題的復制因子(replication factor)。這允許Kafka 在集群服務器發生故障時自動切換到這些副本,以便在出現故障時消息仍然可用。Kafka 的復制是以分區為粒度的,分區的預寫日志被復制到 n 個服務器。 在 n 個副本中,一個副本作為 leader,其他副本成為 followers。顧名思義,producer 只能往 leader 分區上寫數據(讀也只能從 leader 分區上進行),followers 只按順序從 leader 上復制日志。
一個副本可以不同步Leader有如下幾個原因 慢副本:在一定周期時間內follower不能追趕上leader。最常見的原因之一是I / O瓶頸導致follower追加復制消息速度慢于從leader拉取速度。 卡住副本:在一定周期時間內follower停止從leader拉取請求。follower replica卡住了是由于GC暫停或follower失效或死亡。
新啟動副本:當用戶給主題增加副本因子時,新的follower不在同步副本列表中,直到他們完全趕上了leader日志。
如何確定副本是滯后的:
- replica.lag.max.messages=4
在服務端現在只有一個參數需要配置replica.lag.time.max.ms。這個參數解釋replicas響應partition leader的最長等待時間。檢測卡住或失敗副本的探測——如果一個replica失敗導致發送拉取請求時間間隔超過replica.lag.time.max.ms。Kafka會認為此replica已經死亡會從同步副本列表從移除。檢測慢副本機制發生了變化——如果一個replica開始落后leader超過replica.lag.time.max.ms。Kafka會認為太緩慢并且會從同步副本列表中移除。除非replica請求leader時間間隔大于replica.lag.time.max.ms,因此即使leader使流量激增和大批量寫消息。Kafka也不會從同步副本列表從移除該副本。
Leader Epoch引用
數據丟失場景
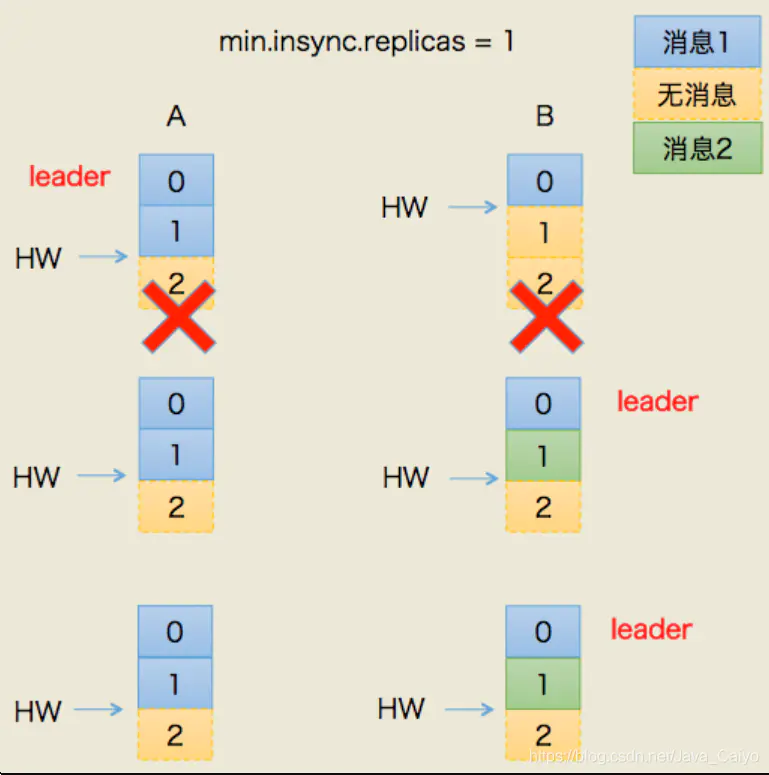
數據出現不一致場景
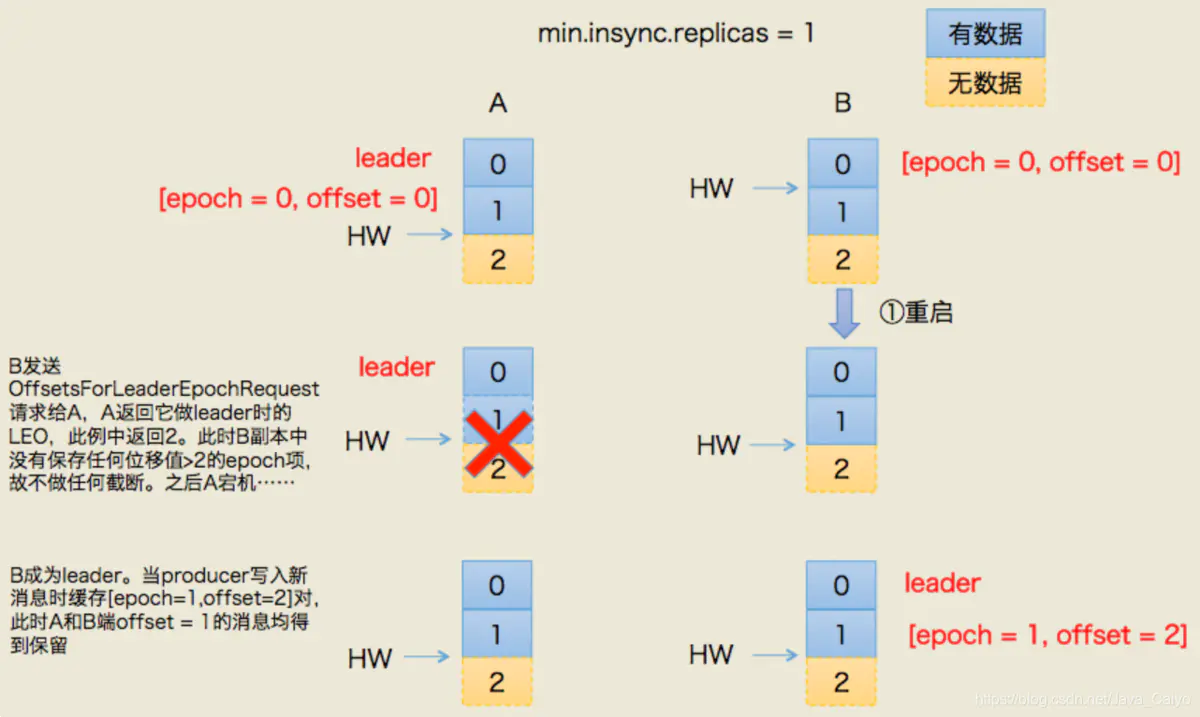
Kafka 0.11.0.0.版本解決方案
造成上述兩個問題的根本原因在于HW值被用于衡量副本備份的成功與否以及在出現failture時作為日志截斷的依據,但HW值得更新是異步延遲的,特別是需要額外的FETCH請求處理流程才能更新,故這中間發生的任何崩潰都可能導致HW值的過期。鑒于這些原因,Kafka 0.11引入了leader epoch來取代HW值。Leader端多開辟一段內存區域專門保存leader的epoch信息,這樣即使出現上面的兩個場景也能很好地規避這些問題。
所謂leader epoch實際上是一對值:(epoch,offset)。epoch表示leader的版本號,從0開始,當leader變更過1次時epoch就會+1,而offset則對應于該epoch版本的leader寫入第一條消息的位移。因此假設有兩對值:
- (0, 0)
- (1, 120)
則表示第一個leader從位移0開始寫入消息;共寫了120條[0, 119];而第二個leader版本號是1,從位移120處開始寫入消息。
leader broker中會保存這樣的一個緩存,并定期地寫入到一個checkpoint文件中。
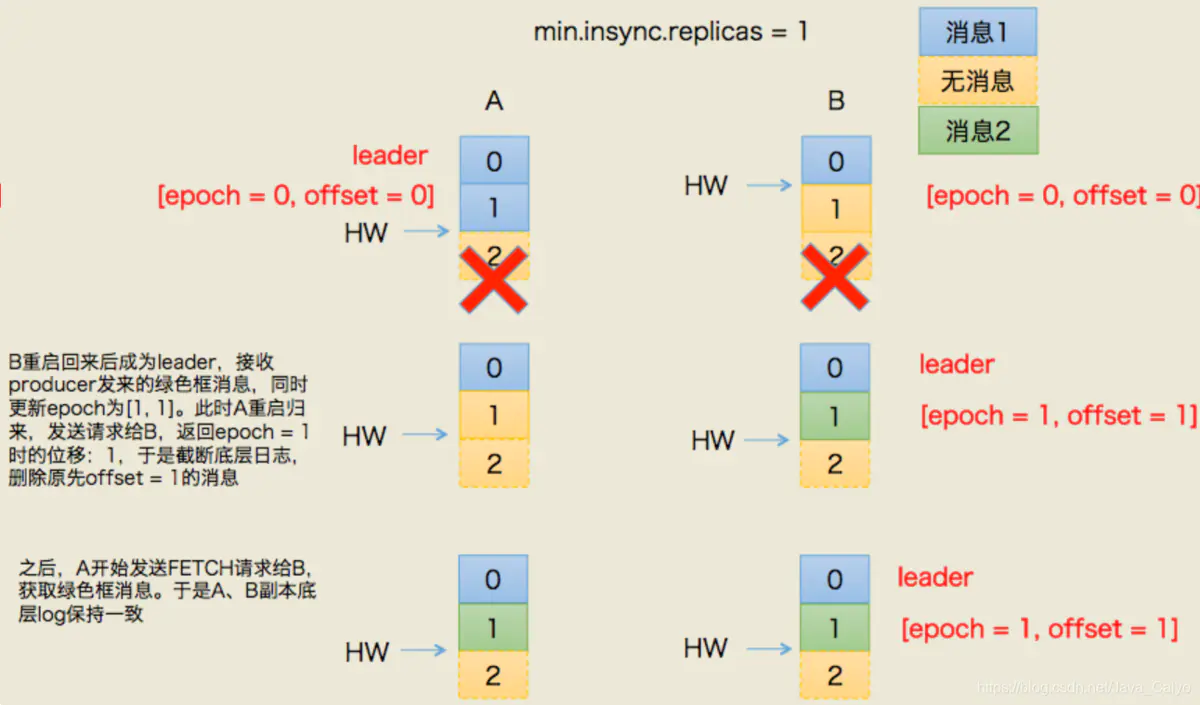
避免數據丟失:
避免數據不一致
六、消息重復的場景及解決方案
1.生產者端重復
生產發送的消息沒有收到正確的broke響應,導致producer重試。
producer發出一條消息,broke落盤以后因為網絡等種種原因發送端得到一個發送失敗的響應或者網絡中斷,然后producer收到一個可恢復的Exception重試消息導致消息重復。
解決方案:
- 啟動kafka的冪等性
要啟動kafka的冪等性,無需修改代碼,默認為關閉,需要修改配置文件:enable.idempotence=true 同時要求 ack=all 且 retries>1。
- ack=0,不重試。
可能會丟消息,適用于吞吐量指標重要性高于數據丟失,例如:日志收集。
消費者端重復
根本原因
數據消費完沒有及時提交offset到broker。
解決方案
取消自動自動提交
每次消費完或者程序退出時手動提交。這可能也沒法保證一條重復。
下游做冪等
一般的解決方案是讓下游做冪等或者盡量每消費一條消息都記錄offset,對于少數嚴格的場景可能需要把offset或唯一ID,例如訂單ID和下游狀態更新放在同一個數據庫里面做事務來保證精確的一次更新或者在下游數據表里面同時記錄消費offset,然后更新下游數據的時候用消費位點做樂觀鎖拒絕掉舊位點的數據更新。
七、__consumer_offsets
_consumer_offsets是一個內部topic,對用戶而言是透明的,除了它的數據文件以及偶爾在日志中出現這兩點之外,用戶一般是感覺不到這個topic的。不過我們的確知道它保存的是Kafka新版本consumer的位移信息。
1.何時創建
一般情況下,當集群中第一有消費者消費消息時會自動創建主題__consumer_offsets,分區數可以通過offsets.topic.num.partitions參數設定,默認值為50,如下:
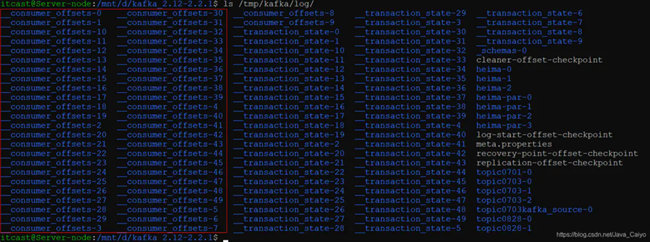
2.解析分區
見代碼庫:
- com.heima.kafka.chapter7.ConsumerOffsetsAnalysis
獲取所有分區:
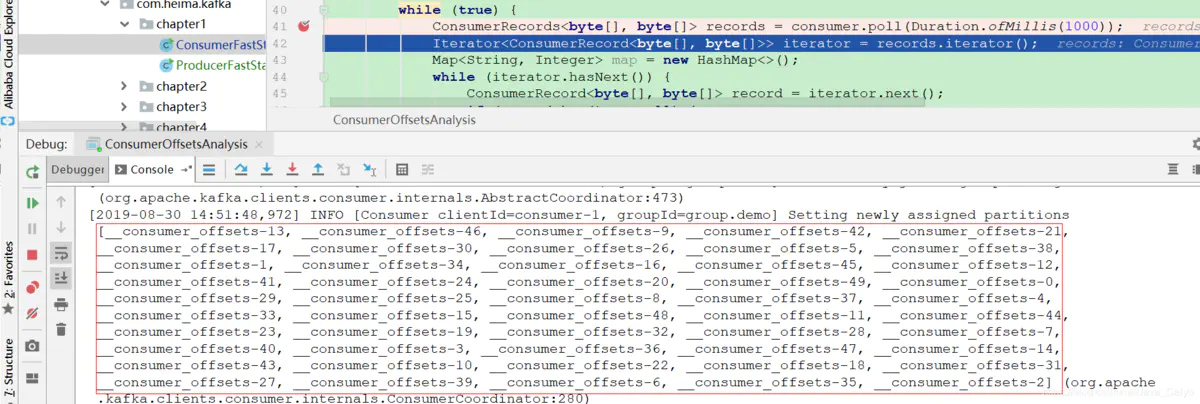
總結
本章主要講解了Kafka相關穩定性的操作,包括冪等性、事務的處理,同時對可靠性保證與一致性保證做了講解,講解了消息重復以及解決方案。