我最近偶遇的六個很酷的Python庫
譯文【51CTO.com快譯】Python是機器學習不可或缺的一部分,庫讓我們的生活更簡單。最近,我在處理機器學習項目時遇到了6個很棒的庫。它們幫我節省了大量時間,本文將介紹它們。
1. clean-text
clean-text是真正很出色的庫,如果您需要處理抓取內容或社交媒體數據,它應該是您的首選。最棒的是它不需要任何冗長的花哨代碼或正則表達式來清理數據。不妨看幾個例子:
安裝
- !pip install cleantext
例子
- #Importing the clean text library
- from cleantext import clean# Sample texttext = """ Zürich, largest city of Switzerland and capital of the canton of 633Zürich. Located in an Al\u017eupine. (https://google.com). Currency is not ₹"""# Cleaning the "text" with clean textclean(text,
- fix_unicode=True,
- to_ascii=True,
- lower=True,
- no_urls=True,
- no_numbers=True,
- no_digits=True,
- no_currency_symbols=True,
- no_punct=True,
- replace_with_punct=" ",
- replace_with_url="",
- replace_with_number="",
- replace_with_digit=" ",
- replace_with_currency_symbol="Rupees")
輸出

我們從上面可以看到,它在Zurich一詞中含有Unicode(字母“u”已被編碼)、ASCII 字符(在Al\u017eupine 中)、盧比貨幣符號、HTML 鏈接和標點符號。
您只需在clean函數中提及所需的ASCII、Unicode、URL、數字、貨幣和標點符號。或者,可以將它們換成上述函數中的替換參數。比如說,我將盧比符號換成了Rupees。
絕對不需要使用正則表達式或長代碼。非常方便的庫,如果您想清理來自抓取內容或社交媒體數據的文本,尤為方便。您還可以根據要求單獨傳遞參數,而不是將它們全部組合在一起。
欲了解更多詳細信息,請查看該GitHub 存儲庫。
2. drawdata
drawdata是我發現的另一個很酷的Python庫。需要向團隊解釋機器學習概念這種情形有多常見?肯定經常發生,因為數據科學注重團隊合作。該庫可幫助您在Jupyter筆記本中繪制數據集。
我向團隊解釋機器學習概念時,確實很喜歡使用這個庫。感謝創建這個庫的開發人員!
Drawdata僅面向有四個類的分類問題。
安裝
- !pip install drawdata
例子
- # Importing the drawdata
- from drawdata import draw_scatterdraw_scatter()
輸出

執行draw_Scatter()后將打開上述繪圖窗口。很顯然,有四個類,即A、B、C和D。可以點擊任何類,并繪制所需的點。每個類代表圖形中的不同顏色。您還可以選擇將數據作為csv或json文件來下載。此外,可以將數據復制到剪貼板,并從下面的代碼中讀取:
- #Reading the clipboardimport pandas as pd
- df = pd.read_clipboard(sep=",")
- df
這個庫的局限之一是它只提供有四個類的兩個數據點。但除此之外,它絕對有其價值。欲了解更多詳細信息,請查看該GitHub 鏈接。
3. Autoviz
我永遠不會忘記花在使用matplotlib進行探索性數據分析上的時間。有很多簡單的可視化庫。然而,我最近發現Autoviz僅用一行代碼即可自動直觀顯示任何數據集。
安裝
- !pip install autoviz
例子
我在這個例子中使用了IRIS數據集。
- # Importing Autoviz class from the autoviz library
- from autoviz.AutoViz_Class import AutoViz_Class#Initialize the Autoviz class in a object called df
- df = AutoViz_Class()# Using Iris Dataset and passing to the default parametersfilename = "Iris.csv"
- sep = ","graph = df.AutoViz(
- filename,
- sep=",",
- depVar="",
- dfte=None,
- header=0,
- verbose=0,
- lowess=False,
- chart_format="svg",
- max_rows_analyzed=150000,
- max_cols_analyzed=30,
- )
上述參數是默認值。欲了解更多信息,請點擊此處。
輸出
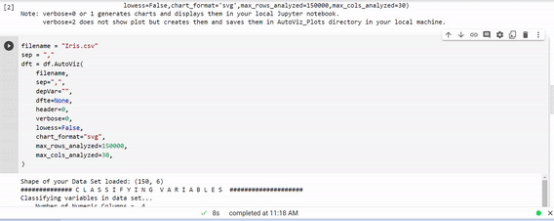
我們可以看到所有的視覺元素,僅用一行代碼完成我們的EDA。有很多自動可視化庫,但我特別喜歡這個庫。
4. Mito
每個人都喜歡Excel,是不是?它是初次探索數據集的最簡單方法之一。幾個月前我遇到了Mito,但最近才試了試,我絕對愛不釋手!
它是一個帶GUI支持的Jupyter-lab擴展Python庫,添加了電子表格功能。您可以加載 csv數據,將數據集作為電子表格來編輯,它可自動生成Pandas代碼。很酷。
Mito值得寫一篇完整的博文來介紹,但是今天不作詳細介紹。這是為您提供的簡單的任務演示。欲知更多詳情,請查看此處。
安裝
- #First install mitoinstaller in the command prompt
- pip install mitoinstaller# Then, run the installer in the command prompt
- python -m mitoinstaller install# Then, launch Jupyter lab or jupyter notebook from the command prompt
- python -m jupyter lab
想了解安裝方面的更多信息,請查看此處。
- # Importing mitosheet and ruuning this in Jupyter labimport mitosheet
- mitosheet.sheet()
執行上述代碼后,mitosheet將在jupyter實驗室中打開。我使用IRIS數據集。首先,我創建了兩個新列。一個是Sepal平均長度,另一個是Sepal總寬度。其次,我更改了Sepal平均長度的列名。最后,我為Sepal平均長度列創建了一個直方圖。
執行上述步驟后,代碼會自動生成。
輸出
為上述步驟生成以下代碼:
- from mitosheet import * # Import necessary functions from Mito
- register_analysis('UUID-119387c0-fc9b-4b04-9053-802c0d428285') # Let Mito know which analysis is being run# Imported C:\Users\Dhilip\Downloads\archive (29)\Iris.csv
- import pandas as pd
- Iris_csv = pd.read_csv('C:\Users\Dhilip\Downloads\archive (29)\Iris.csv')# Added column G to Iris_csv
- Iris_csv.insert(6, 'G', 0)# Set G in Iris_csv to =AVG(SepalLengthCm)
- Iris_csv['G'] = AVG(Iris_csv['SepalLengthCm'])# Renamed G to Avg_Sepal in Iris_csv
- Iris_csv.rename(columns={"G": "Avg_Sepal"}, inplace=True)
5. Gramformer
另一個出色的庫Gramformer基于生成模型,可幫助我們糾正句子中的語法。這個庫有三個模型,有檢測器、熒光筆和校正器。檢測器識別文本是否有錯誤的語法。熒光筆標記錯誤的部分,校正器修復錯誤。Gramformer是完全開源的軟件,目前處于早期階段。但它不適合長段落,因為它僅適用于句子,已針對64個字符長度的句子進行了訓練。
目前,校正器和熒光筆模型切實有用。不妨看幾個例子。
安裝
- !pip3 install -U git+https://github.com/PrithivirajDamodaran/Gramformer.git
為Gramformer創建實例
- gf = Gramformer(models = 1, use_gpu = False) # 1=corrector, 2=detector (presently model 1 is working, 2 has not implemented)

例子
- #Giving sample text for correction under gf.correctgf.correct(""" New Zealand is island countrys in southwestern Paciific Ocaen. Country population was 5 million """)
輸出
我們從上面的輸出中可以看到它糾正了語法,甚至糾正了拼寫錯誤。一個非常棒的庫,功能也很棒。我還沒有在這里試過熒光筆,您可以試試,查看該GitHub文檔,以獲取更多詳細信息。
6. Styleformer
在使用Gramformer方面的良好體驗鼓勵我尋找更多獨特的庫。我因此發現了Styleformer,這是另一個極具出色的Python庫。Gramformer和Styleformer都是由Prithiviraj Damodaran創建的,兩者都基于生成模型。感謝創建者開源。
Styleformer幫助將隨意句轉換成正式句、將正式句轉換成隨意句、將主動句轉換成被動句以及將被動句轉換成主動句。
不妨看幾個例子:
安裝
- !pip install git+https://github.com/PrithivirajDamodaran/Styleformer.git
為Styleformer創建實例
- sf = Styleformer(style = 0)# style = [0=Casual to Formal, 1=Formal to Casual, 2=Active to Passive, 3=Passive to Active etc..]
例子
- # Converting casual to formal sf.transfer("I gotta go")
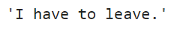
- # Formal to casual
- sf = Styleformer(style = 1) # 1 -> Formal to casual# Converting formal to casual
- sf.transfer("Please leave this place")

- # Active to Passive
- sf = Styleformer(style = 2) # 2-> Active to Passive# Converting active to passive
- sf.transfer("We are going to watch a movie tonight.")

- # passive to active
- sf = Styleformer(style = 2) # 2-> Active to Passive# Converting passive to active
- sf.transfer("Tenants are protected by leases")

看到上面的輸出,轉換準確。我使用這個庫將隨意句轉換成正式句,尤其是在我有一次分析時用于社交媒體帖子。欲了解更多詳細信息,請查看GitHub。
您可能熟悉了前面提到的一些庫,但像Gramformer和Styleformer這樣的庫是最近出現的庫。它們被嚴重低估了,當然值得廣為人知,因為它們為我節省了大量時間,我在NLP項目中大量使用它們。
原文標題:6 Cool Python Libraries That I Came Across Recently,作者:Dhilip Subramanian
【51CTO譯稿,合作站點轉載請注明原文譯者和出處為51CTO.com】