













高并發整體可用性:一文詳解降級、限流和熔斷
水滿則溢,月盈則虧,任何事物都不可能無限制的發展,我們的系統服務能力也一樣。
當隨著流量的不斷增長,達到或超過服務本身的可承載范圍,系統服務的自我保護機制的建立就顯得很重要了。
本文希望可以用最通俗的解釋和貼切的實例來帶大家了解什么是限流、降級和熔斷。
Part1限流 - 自知之明和眼力見
一個是本身的承載能力,一個是依賴方的服務能力,其實都是從當前系統的角度來說,
1.1自知之明之被動限流
我只有這么大的能力,只能服務這么多客戶!
系統對自身的承載能力需要有一個清晰的認識,對于超過承載能力的額外調用,要適當拒絕。
而怎樣衡量系統承載能力是一個問題。
一般的我們有兩種常見方案:一是定義閾值和規則,二是自適應限流策略。
閾值和規則是owner通過對業務的把控和自身的存儲、連接的現狀,根據人工經驗制定的。這樣的策略一般不會出什么大問題,但是不夠靈活,對請求反饋的靈敏度和資源的利用率不夠。
相對的,自適應策略則是一種動態限流策略,是通過對系統當前的運行狀況,動態的調整限流閾值,在機器資源和流量處理之間尋找一個平衡。
如阿里開源的Sentinel限流器,在動態限流策略上支持[1]:
- Load 自適應:系統的 load1 作為啟發指標,進行自適應系統保護。當系統 load1 超過設定的啟發值,且系統當前的并發線程數超過估算的系統容量時才會觸發系統保護。
- CPU usage:當系統 CPU 使用率超過閾值即觸發系統保護(取值范圍 0.0-1.0),比較靈敏。
- 平均 RT:當單臺機器上所有入口流量的平均 RT 達到閾值即觸發系統保護,單位是毫秒。
- 并發線程數:當單臺機器上所有入口流量的并發線程數達到閾值即觸發系統保護。
- 入口 QPS:當單臺機器上所有入口流量的 QPS 達到閾值即觸發系統保護。
1.2眼力見之主動限流
合作方只有那么大的能力,我只能索取這么多!
對下游依賴系統的服務能力,需要有一個精準的判斷,對于服務能力弱的下游系統,要適當減少調用,得有點眼力見,對不對。
因為,絕大部分的業務系統都不是單獨存在的,會依賴很多其他的系統,這些依賴方的服務能力,就像是木桶短板,限制了當前系統的處理能力。這個時候就需要把下游當做一個整體來考慮。
因此,需要把集群限流和單機限流配合起來使用,特別是下游服務的實例數、服務能力等和當前系統有較大差距的時候,集群限流還是必要的。
一種方案:是通過收集服務節點的請求日志,統計請求量,并通過限流配置,控制節點限流邏輯:
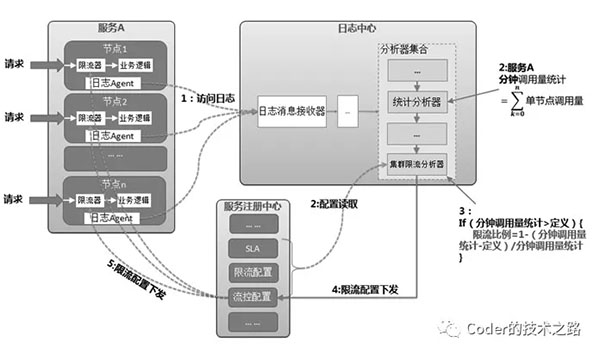
摘自:微服務治理:體系、架構及實踐
我將其稱為后置限流,即收集各個節點的請求量和既定閾值對比,超過則反饋到各個節點,依賴單機限流進行比例限流。
另一種方案:是限流總控服務,根據配置生產token,然后各個節點消費token,正常獲取token后才能繼續業務:
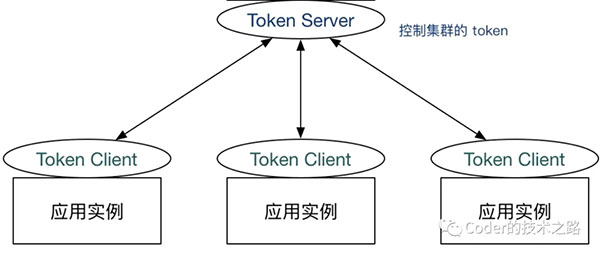
摘自:Sentinel
我將其稱為前置限流,預先確定分配好可用的token,省去了匯總和反饋的處理機制,相比而言,這種控制方式要相對精準和優雅。
1.3同步轉異步
合作方雖然能力有限,但態度很好,加班加點的處理;而我們的客戶也很友好,同意多等等
一個非常經典的例子,就是第三方支付平臺的還款業務,用過的同學應該都有體會,一般都是支付完成之后等一會才會收到銷賬的通知。
這個時延的底層邏輯是什么呢?
一般的,金融機構的服務接口,因為其數據一致性和系統穩定性的要求,性能方面可能不如互聯網公司的系統。
那么,當到了月初月末的還款高峰,如果把支持成功用戶的銷賬請求一股腦的都壓給機構,后果可想而知。
但是,對于用戶來說,整個流程是可以被拆分的,用戶側只要完成支付操作就可以了。至于最終結果,可以允許延后被通知。
因此,基本上,金融網關在處理機構銷賬都是異步的,即先將各業務的銷賬請求落地,然后異步的限速輪詢待處理的單據,再和機構交互。
其實,不僅僅是在金融領域,只要我們的業務處理速度存在差異,且流程可以被拆分,即可考慮這種架構思路,來緩解系統壓力,保障業務可用性。
Part2降級 - 丟車保帥
事發突然,能力有限,我只能緊著幾個重要客戶服務!
那么,什么情況需要降級,什么鏈路可以被降級呢?
當整個業務處于高峰期,或活動脈沖期,當服務的負載很高,逼近了服務承載閾值,即可以考慮服務降級來保障主功能可用。
可以降級的一定是非核心的鏈路,比如網購場景下的積分抵扣,如果降級積分抵扣鏈路,其實不影響大部分的支付功能。
那么,在系統中我們一般采用的降級方案有哪些呢?
1、頁面降級:即從用戶操作頁面進行操作,直接限制和截斷某功能的入口:
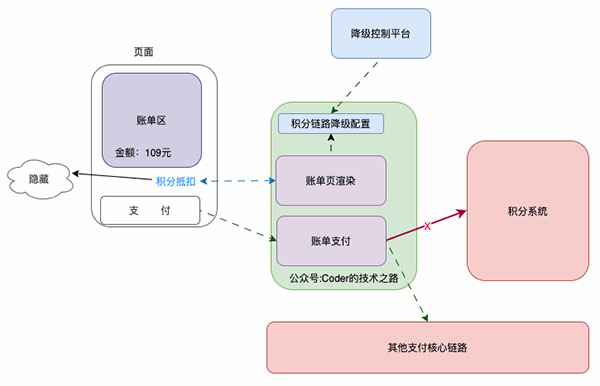
從頁面入口對積分鏈路降級
如上圖所示,該業務場景下,是否使用積分,是在頁面渲染階段決定并返回給前段進行頁面拼接的。
當我們需要對其進行降級時,會通過控制平臺進行降級開關切換,系統讀到降級開啟后,會返回前段積分降級的標識,前端將不再顯示積分抵扣入口。即從入口處截斷積分鏈路的執行,達到降級的目的。
2、存儲降級:使用緩存方式來降級頻繁操作的存儲
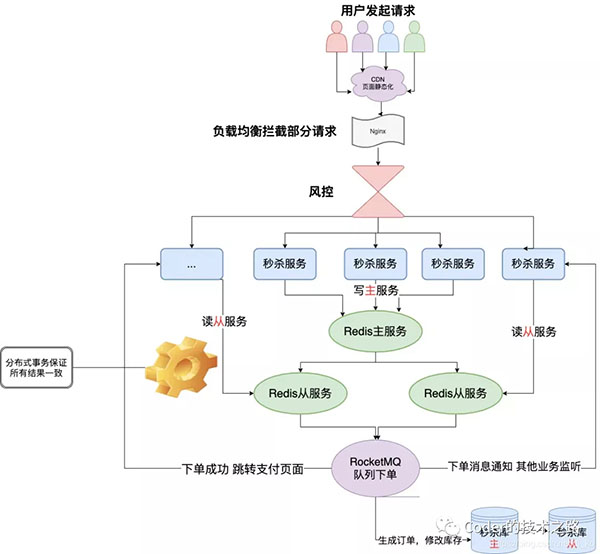
https://blog.csdn.net/di_ko/article/details/118058080
對于秒殺業務這種寫多讀少的場景,對DB的壓力是非常大的,一般的,我們會采用上圖所示的緩存架構,用緩存操作代替DB操作,用異步MQ代替同步接口,也屬于一種存儲的降級行為。
3、讀降級:對于非核心信息的讀請求禁用
微信的搶紅包場景,紅包列表的展示屬于搶紅包的非核心鏈路,因此,對于列表展示,在業務壓力較大的情況下,對頭像等信息的讀,可以直接禁用。
4、寫降級:直接禁止相關寫操作的服務請求
總結,一句話概括降級的核心--丟車保帥。以損失部分體驗的代價,來換取整個業務鏈路的穩定性和持續可用。
Part3熔斷- 大局觀
合作方遇到困難了,不能為了自己把人家逼上絕路,別把自己也拖垮!出于人道主義,還得時不時問詢下,Are you ok ?
熔斷機制之所以被我賦予大局觀的美稱,是因為其所要解決的問題是級聯故障和服務雪崩!
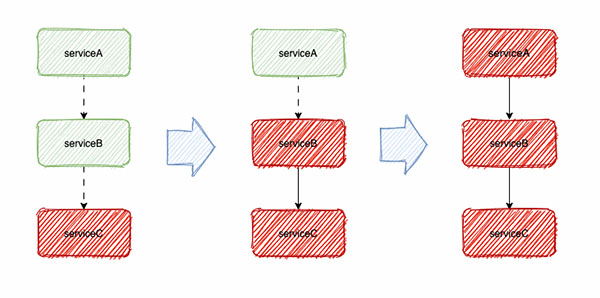
在分布式的環境下,異常是常態。如上圖所示,當服務C出現調用異常時,會在服務B中出現大量的請求超時和調用延遲。
這些調用也是需要占用系統資源的,當大量請求積壓,服務B的線程池等資源也會隨之耗盡,最終導致整個服務鏈路的雪崩都是有可能的。
因此,當服務C出現異常時,對服務C的調用適當暫停,同時不斷監測其接口是否恢復,對于整個鏈路的健康非常有必要的,上述針對C的處理過程就是熔斷。
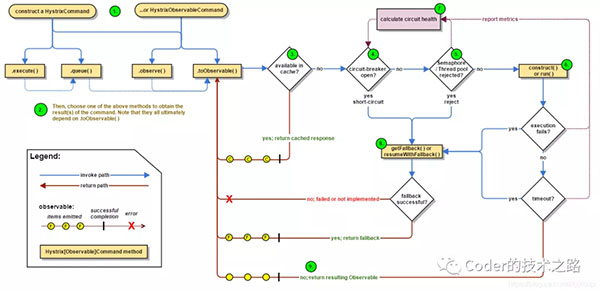
Hystrix官方熔斷流程[2]
從上圖可以看到,熔斷操作的三個關鍵點:
- 熔斷算法,即什么情況即會被判定為需要熔斷
- 熔斷后處理,即當前系統不進行遠程調用,但調用結果需要有替代邏輯
- 熔斷恢復,適當的檢測機制,用于結束熔斷,恢復正常服務調用。
之前在《在所依賴存儲不授信的場景下實現柔性事務降級》一文中提到過,我們的分布式事務,會依賴底層存儲做元數據存儲和一致性校驗。
但是底層存儲的穩定性稍有不足,這里就涉及到了服務熔斷的處理:
- 當我們通過關鍵字監控,檢測到底層存儲的操作異常操作某閾值時,就會通過腳本觸發一個開關切換的操作。
- 此開關打開的作用是,棄用底層存儲,直接走兜底消息隊列,以保障絕大部分請求得以正常進行。
- 在開發開啟的時間段內,用試探線程去試探底層存儲是否恢復,當探測到存儲恢復正常時,切換開關恢復到正常鏈路。(這一步目前還未實現,用人工代替了)














