2021最新對比學(xué)習(xí)(Contrastive Learning)在各大頂會上的經(jīng)典必讀論文解讀
大家好,我是對白。
由于最近對比學(xué)習(xí)實(shí)在太火了,在ICLR2020上深度學(xué)習(xí)三巨頭 Bengio 、 LeCun和Hinton就一致認(rèn)定自監(jiān)督學(xué)習(xí)(Self-Supervised Learning)是AI的未來,此外,在各大互聯(lián)網(wǎng)公司中的業(yè)務(wù)落地也越來越多,且效果還非常不錯(cuò)(公司里親身實(shí)踐),于是寫了兩篇有關(guān)對比學(xué)習(xí)的文章:
一篇是對比學(xué)習(xí)在CV與NLP領(lǐng)域中的研究進(jìn)展,寫得比較系統(tǒng)與全面,里面介紹了對比學(xué)習(xí)是什么,以及該技術(shù)如何應(yīng)用在各個(gè)領(lǐng)域中,包括MoCo、SimCLR、BYOL、SwAV、SimCSE等;
另一篇?jiǎng)t梳理了ICLR2021上對比學(xué)習(xí)在NLP領(lǐng)域六大方向中的應(yīng)用,均收獲了很多小伙伴們的私信,感興趣的同學(xué)也可以看一看:
1.對比學(xué)習(xí)(Contrastive Learning)在CV與NLP領(lǐng)域中的研究進(jìn)展
2.ICLR2021對比學(xué)習(xí)(Contrastive Learning)NLP領(lǐng)域論文進(jìn)展梳理
本篇文章則梳理了對比學(xué)習(xí)在ICLR2021、ICLR2020和NIPS2020中非常值得大家一讀的一些經(jīng)典論文,構(gòu)思非常巧妙,涵蓋了CV和NLP領(lǐng)域,且與之前兩篇文章中介紹的模型均不重疊。后續(xù)等NIPS2021論文公開后,也會持續(xù)更新并分享給大家,話不多說,開始進(jìn)入正題叭。
對比學(xué)習(xí)(ICLR2021/2020)
值得一讀的八篇論文
1.PCL

論文標(biāo)題:Prototypical Contrastive Learning of Unsupervised Representations
論文方向:圖像領(lǐng)域,提出原型對比學(xué)習(xí),效果遠(yuǎn)超MoCo和SimCLR
論文來源:ICLR2021
論文鏈接:https://arxiv.org/abs/2005.04966
論文代碼:https://github.com/salesforce/PCL
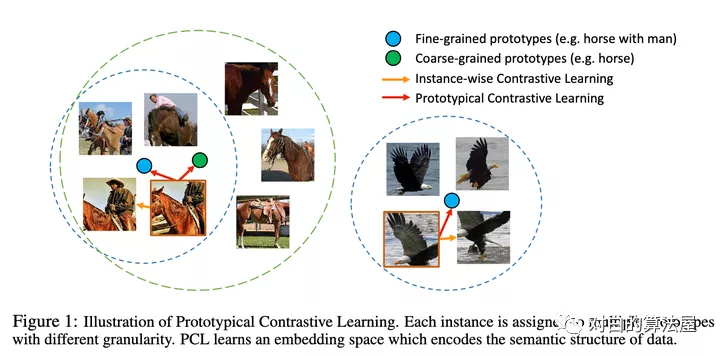
作者提出了原型對比學(xué)習(xí)(PCL),它是無監(jiān)督表示學(xué)習(xí)的一種新方法,綜合了對比學(xué)習(xí)和聚類學(xué)習(xí)的優(yōu)點(diǎn)。
在 PCL 中,作者引入了一個(gè)「原型」作為由相似圖像形成的簇的質(zhì)心。將每個(gè)圖像分配給不同粒度的多個(gè)原型。訓(xùn)練的目標(biāo)是使每個(gè)圖像嵌入更接近其相關(guān)原型,這是通過最小化一個(gè) ProtoNCE 損失函數(shù)來實(shí)現(xiàn)的。
在高層次上,PCL 的目標(biāo)是找到給定觀測圖像的最大似然估計(jì)(MLE)模型參數(shù):
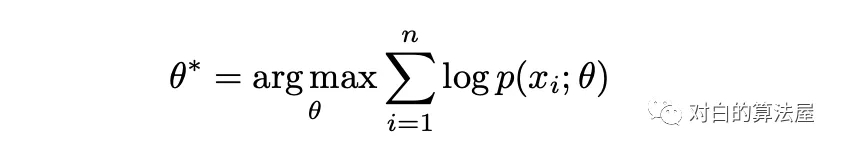
作者引入原型 c 作為與觀測數(shù)據(jù)相關(guān)的潛在變量,提出了一種EM算法來求解最大似然估計(jì)。在 E-step 中,通過執(zhí)行 K 平均算法估計(jì)原型的概率。在M步中,通過訓(xùn)練模型來最大化似然估計(jì),從而最小化一個(gè) ProtoNCE 損失:
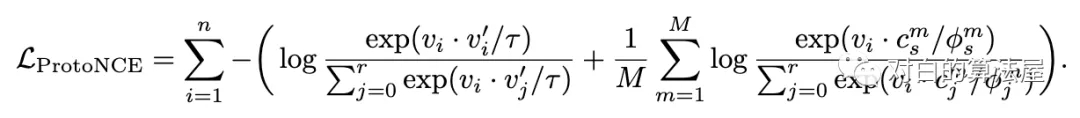
在期望最大化框架下,作者證明以前的對比學(xué)習(xí)方法是 PCL 的一個(gè)特例。
此外,作者在少樣本遷移學(xué)習(xí)、半監(jiān)督學(xué)習(xí)和目標(biāo)檢測三個(gè)任務(wù)上對 PCL 進(jìn)行評估,在所有情況下都達(dá)到了SOTA的性能。
作者希望 PCL 可以擴(kuò)展到視頻,文本,語音等領(lǐng)域,讓 PCL 激勵(lì)更多有前途的非監(jiān)督式學(xué)習(xí)領(lǐng)域的研究,推動未來人工智能的發(fā)展,使人工標(biāo)注不再是模型訓(xùn)練的必要組成部分。
2.BalFeat

論文標(biāo)題:Exploring Balanced Feature Spaces for Representation Learning
論文方向:圖像領(lǐng)域,主要解決類別分布不均勻的問題
論文來源:ICLR2021
論文鏈接:https://openreview.net/forum?id=OqtLIabPTit
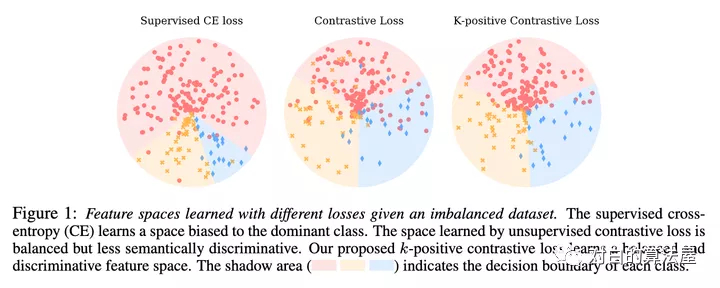
現(xiàn)有的自監(jiān)督學(xué)習(xí)(SSL)方法主要用于訓(xùn)練來自人工平衡數(shù)據(jù)集(如ImageNet)的表示模型。目前還不清楚它們在實(shí)際情況下的表現(xiàn)如何,在實(shí)際情況下,數(shù)據(jù)集經(jīng)常是不平衡的。基于這個(gè)問題,作者在訓(xùn)練實(shí)例分布從均勻分布到長尾分布的多個(gè)數(shù)據(jù)集上,對自監(jiān)督對比學(xué)習(xí)和監(jiān)督學(xué)習(xí)方法的性能進(jìn)行了一系列的研究。作者發(fā)現(xiàn)與具有較大性能下降的監(jiān)督學(xué)習(xí)方法不同的是,自監(jiān)督對比學(xué)習(xí)方法即使在數(shù)據(jù)集嚴(yán)重不平衡的情況下也能保持穩(wěn)定的學(xué)習(xí)性能。
這促使作者探索通過對比學(xué)習(xí)獲得的平衡特征空間,其中特征表示在所有類中都具有相似的線性可分性。作者的實(shí)驗(yàn)表明,在多個(gè)條件下,生成平衡特征空間的表征模型比生成不平衡特征空間的表征模型具有更好的泛化能力。基于此,作者提出了k-positive對比學(xué)習(xí),它有效地結(jié)合了監(jiān)督學(xué)習(xí)方法和對比學(xué)習(xí)方法的優(yōu)點(diǎn)來學(xué)習(xí)具有區(qū)別性和均衡性的表示。大量實(shí)驗(yàn)表明,該算法在長尾識別和正常平衡識別等多種識別任務(wù)中都具有優(yōu)越性。
3.MiCE

論文標(biāo)題:MiCE: Mixture of Contrastive Experts for Unsupervised Image Clustering
論文方向:圖像領(lǐng)域,對比學(xué)習(xí)結(jié)合混合專家模型MoE,無需正則化
論文來源:ICLR2021
論文鏈接:https://arxiv.org/abs/2105.01899
論文代碼:https://github.com/TsungWeiTsai/MiCE
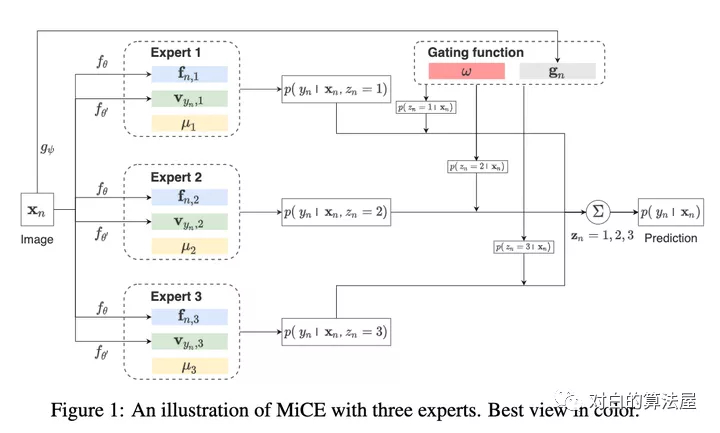
目前深度聚類方法都是使用two-stage進(jìn)行構(gòu)建,即首先利用pre-trained模型進(jìn)行表示學(xué)習(xí),之后再使用聚類算法完成聚類,但是由于這兩個(gè)stage相互獨(dú)立且現(xiàn)有的baseline在表示學(xué)習(xí)中并沒有很好的建模語義信息,導(dǎo)致后面無法得到很好的聚類。
作者提出一個(gè)統(tǒng)一概率聚類模型Mixture of Contrastive Experts (MiCE),其同時(shí)利用了對比學(xué)習(xí)學(xué)習(xí)到的判別性表示(discriminative representation)和潛在混合模型獲取的語義結(jié)構(gòu)(semantic structures)。受多專家模型(mixture of experts ,MoE)啟發(fā),通過引入潛變量來表示圖像的聚類標(biāo)簽,從而形成一種混合條件模型,每個(gè)條件模型(也稱為expert)學(xué)習(xí)區(qū)分實(shí)例的子集,同時(shí)該模型采用門控函數(shù)(gating function)通過在專家之間分配權(quán)重,將數(shù)據(jù)集根據(jù)語義信息劃分為子集。進(jìn)一步,為了解決潛在變量引起的非簡單推斷(nontrivial inference)和其他訓(xùn)練問題,作者進(jìn)一步構(gòu)建了可擴(kuò)展的EM算法,并給出了收斂性證明。其中E步,根據(jù)觀測數(shù)據(jù)得到潛在變量后驗(yàn)分布的估計(jì),M步最大化關(guān)于所有變量的對數(shù)條件似然。
MICE具有以下優(yōu)點(diǎn):
方法論上的統(tǒng)一:MICE結(jié)合了通過對比學(xué)習(xí)得到的判別性表示和通過統(tǒng)一概率框架內(nèi)的潛在混合模型得到的語義結(jié)構(gòu)的優(yōu)點(diǎn)。
無需正則化:MICE僅通過EM進(jìn)行優(yōu)化,不需要任何其他的輔助loss和正則化loss。
Preliminary

Gate Function

Experts

在(5)式中,第一個(gè)instance-wise點(diǎn)積計(jì)算實(shí)例層次(instance-level)信息,以在每個(gè)expert中產(chǎn)生具有判別性的表示(discriminative representation),第二個(gè)instance-prototype點(diǎn)積將類別層次(class-level)信息整合到表示學(xué)習(xí)中,使之能夠圍繞prototype形成清晰的集群結(jié)構(gòu),因此產(chǎn)生的embedding具有語意結(jié)構(gòu)同時(shí)有足夠的判別性來表示不同實(shí)例
該式子基于MoCo和EMA構(gòu)造,更多細(xì)節(jié)查看原文附錄D。
4.i-Mix

論文標(biāo)題:i-Mix: A Strategy for Regularizing Contrastive Representation Learning
論文方向:圖像領(lǐng)域,少樣本+MixUp策略來提升對比學(xué)習(xí)效果
論文來源:ICLR2021
論文鏈接:https://arxiv.org/abs/2010.08887
論文代碼:https://github.com/kibok90/imix

對比表示學(xué)習(xí)已經(jīng)證明了從未標(biāo)記數(shù)據(jù)中學(xué)習(xí)表示是有效的。然而,利用領(lǐng)域知識精心設(shè)計(jì)的數(shù)據(jù)增強(qiáng)技術(shù)已經(jīng)在視覺領(lǐng)域取得了很大進(jìn)展。
作者提出了i-Mix,一個(gè)簡單而有效的領(lǐng)域未知正則化策略,以改善對比表示學(xué)習(xí)。作者將 MixUp 技巧用在了無監(jiān)督對比學(xué)習(xí)上,可有效提升現(xiàn)有的對比學(xué)習(xí)方法(尤其是在小數(shù)據(jù)集上):給每個(gè)樣本引入虛擬標(biāo)簽,然后插值樣本空間和 label 空間進(jìn)行數(shù)據(jù)增強(qiáng)。實(shí)驗(yàn)結(jié)果證明了i-Mix在圖像、語音和表格數(shù)據(jù)等領(lǐng)域不斷提高表示學(xué)習(xí)的質(zhì)量。
5.Contrastive Learning with Hard Negative Samples

論文標(biāo)題:Contrastive Learning with Hard Negative Samples
論文方向:圖像&文本領(lǐng)域,研究如何采樣優(yōu)質(zhì)的難負(fù)樣本
論文來源:ICLR2021
論文鏈接:https://arxiv.org/abs/2010.04592
論文代碼:https://github.com/joshr17/HCL
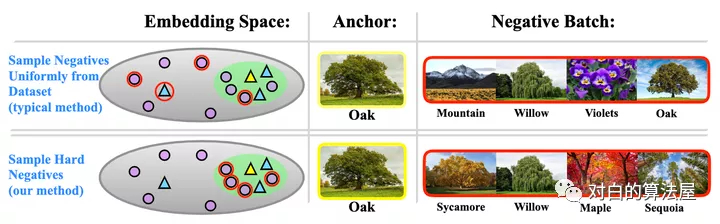
對比學(xué)習(xí)在無監(jiān)督表征學(xué)習(xí)領(lǐng)域的潛力無需多言,已經(jīng)有非常多的例子證明其效果,目前比較多的針對對比學(xué)習(xí)的改進(jìn)包括損失函數(shù)、抽樣策略、數(shù)據(jù)增強(qiáng)方法等多方面,但是針對負(fù)對的研究相對而言更少一些,一般在構(gòu)造正負(fù)對時(shí),大部分模型都簡單的把單張圖像及其增強(qiáng)副本作為正對,其余樣本均視為負(fù)對。這一策略可能會導(dǎo)致的問題是模型把相距很遠(yuǎn)的樣本分得很開,而距離較近的負(fù)樣本對之間可能比較難被區(qū)分。
基于此,本文構(gòu)造了一個(gè)難負(fù)對的思想,主要目的在于,把離樣本點(diǎn)距離很近但是又確實(shí)不屬于同一類的樣本作為負(fù)樣本,加大了負(fù)樣本的難度,從而使得類與類之間分的更開,來提升對比學(xué)習(xí)模型的表現(xiàn)。
好的難負(fù)樣本有兩點(diǎn)原則:1)與原始樣本的標(biāo)簽不同;2)與原始樣本盡量相似。
這一點(diǎn)就與之前的對比學(xué)習(xí)有比較明顯的差異了,因?yàn)閷Ρ葘W(xué)習(xí)一般來說并不使用監(jiān)督信息,因此除了錨點(diǎn)之外的其他樣本,不管標(biāo)簽如何,都被認(rèn)為是負(fù)對,所以問題的一個(gè)關(guān)鍵在于“用無監(jiān)督的方法篩出不屬于同一個(gè)標(biāo)簽的樣本”。不僅如此,這里還有一個(gè)沖突的地方,既要與錨點(diǎn)盡可能相似,又得不屬于同一類,這對于一個(gè)無監(jiān)督模型來說是有難度的,因此本文在實(shí)際實(shí)現(xiàn)過程中進(jìn)行了一個(gè)權(quán)衡,假如對樣本的難度要求不是那么高的時(shí)候,就只滿足原則1,而忽略原則2。同時(shí),這種方法應(yīng)該盡量不增加額外的訓(xùn)練成本。
6.LooC

論文標(biāo)題:What Should Not Be Contrastive in Contrastive Learning
論文方向:圖像領(lǐng)域,探討對比學(xué)習(xí)可能會引入偏差
論文來源:ICLR2021
論文鏈接:https://arxiv.org/abs/2008.05659
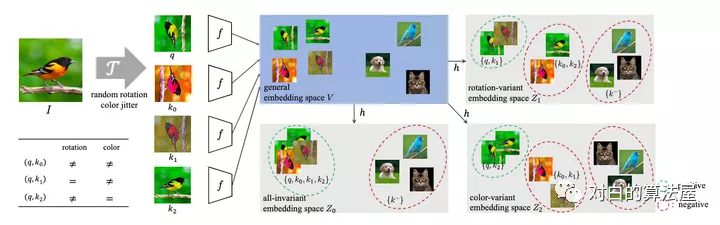
當(dāng)前對比學(xué)習(xí)的框架大多采用固定的數(shù)據(jù)增強(qiáng)方式,但是對于不同的下游任務(wù),不同的數(shù)據(jù)增強(qiáng)肯定會有不一樣的效果,例如在數(shù)據(jù)增強(qiáng)中加入旋轉(zhuǎn),那么下游任務(wù)就會難以辨別方向,本文針對該問題進(jìn)行研究。
如果要應(yīng)用一個(gè)數(shù)據(jù)增強(qiáng)集合
到模型中,傳統(tǒng)模型的做法是將圖片數(shù)據(jù)進(jìn)行兩次獨(dú)立的數(shù)據(jù)增強(qiáng)(數(shù)據(jù)增強(qiáng)參數(shù)具有一定隨機(jī)性)。作者提出LooC,方法是執(zhí)行 種數(shù)據(jù)增強(qiáng),第一種是將圖片數(shù)據(jù)進(jìn)行兩次獨(dú)立的數(shù)據(jù)增強(qiáng),也即是對所有數(shù)據(jù)增強(qiáng)方式全應(yīng)用;剩下N種是將 參數(shù)固定,這樣就保證了最終訓(xùn)練出來的模型會對
這種變換敏感,這n+1種數(shù)據(jù)增強(qiáng)方式最終會生成n+1種嵌入空間。最終loss如下:


作者發(fā)現(xiàn)原來的對比學(xué)習(xí)都是映射到同一空間,但是這樣會有害學(xué)習(xí)其他的特征,所以作者把每個(gè)特征都映射到單獨(dú)的特征空間,這個(gè)空間里都只有經(jīng)過這一種數(shù)據(jù)增強(qiáng)的數(shù)據(jù)。
總而言之,數(shù)據(jù)增強(qiáng)是要根據(jù)下游任務(wù)來說的,分成不同的Embedding空間來適合多種不同的下游任務(wù),但是對需要兩種以上特征的下游任務(wù)效果可能就不好了。比如不僅僅需要結(jié)構(gòu)信息,還需要位置。
7.CALM

論文標(biāo)題:Pre-training Text-to-Text Transformers for Concept-centric Common Sense
論文方向:文本領(lǐng)域,利用對比學(xué)習(xí)和自監(jiān)督損失,在預(yù)訓(xùn)練語言模型中引入常識信息
論文來源:ICLR2021
論文鏈接:https://openreview.net/forum?id=3k20LAiHYL2
論文代碼:https://github.com/INK-USC/CALM
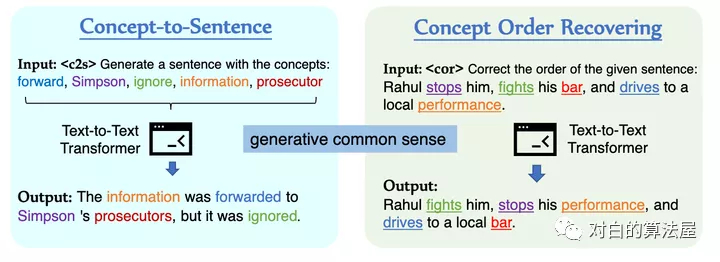
預(yù)訓(xùn)練語言模型 在一系列自然語言理解和生成任務(wù)中取得了令人矚目的成果。然而,當(dāng)前的預(yù)訓(xùn)練目標(biāo),例如Masked預(yù)測和Masked跨度填充并沒有明確地對關(guān)于日常概念的關(guān)系常識進(jìn)行建模,對于許多需要常識來理解或生成的下游任務(wù)是至關(guān)重要的。
為了用以概念為中心的常識來增強(qiáng)預(yù)訓(xùn)練語言模型,在本文中,作者提出了從文本中學(xué)習(xí)常識的生成目標(biāo)和對比目標(biāo),并將它們用作中間自監(jiān)督學(xué)習(xí)任務(wù),用于增量預(yù)訓(xùn)練語言模型(在特定任務(wù)之前下游微調(diào)數(shù)據(jù)集)。此外,作者開發(fā)了一個(gè)聯(lián)合預(yù)訓(xùn)練框架來統(tǒng)一生成和對比目標(biāo),以便它們可以相互加強(qiáng)。
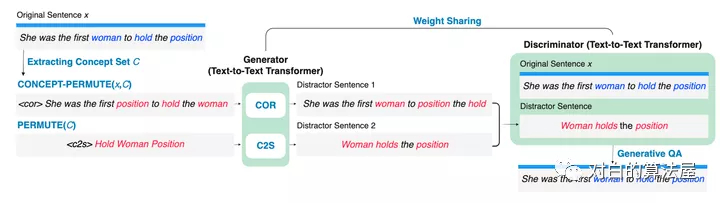
大量的實(shí)驗(yàn)結(jié)果表明,CALM可以在不依賴外部知識的情況下,將更多常識打包到預(yù)訓(xùn)練的文本到文本Transformer的參數(shù)中,在NLU和NLG 任務(wù)上都取得了更好的性能。作者表明,雖然僅在相對較小的語料庫上進(jìn)行了幾步的增量預(yù)訓(xùn)練,但 CALM 以一致的幅度優(yōu)于baseline,甚至可以與一些較大的 預(yù)訓(xùn)練語言模型相媲美,這表明 CALM 可以作為通用的“即插即用” 方法,用于提高預(yù)訓(xùn)練語言模型的常識推理能力。
8.Support-set bottlenecks for video-text representation learning

論文標(biāo)題:Support-set bottlenecks for video-text representation learning
論文方向:多模態(tài)領(lǐng)域(文本+視頻),提出了cross-captioning目標(biāo)
論文來源:ICLR2021
論文鏈接:https://arxiv.org/abs/2010.02824
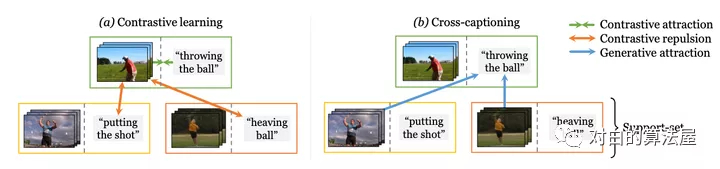
學(xué)習(xí)視頻-文本表示的主流典范——噪聲對比學(xué)習(xí)——增加了已知相關(guān)樣本對的表示的相似性,例如來自同一樣本的文本和視頻,但將所有樣本對都認(rèn)為是負(fù)例。作者認(rèn)為最后一個(gè)行為過于嚴(yán)格,即使對于語義相關(guān)的樣本也強(qiáng)制執(zhí)行不同的表示——例如,視覺上相似的視頻或共享相同描述動作的視頻。
在本文中,作者提出了一種新方法,通過利用生成模型將這些相關(guān)樣本自然地推到一起來緩解這種情況:每個(gè)樣本的標(biāo)題必須重建為其他支持樣本的視覺表示的加權(quán)組合。這個(gè)簡單的想法確保表示不會過度專門用于單個(gè)樣本,可以在整個(gè)數(shù)據(jù)集中重復(fù)使用,并產(chǎn)生明確編碼樣本之間共享語義的表示,這與噪聲對比學(xué)習(xí)不同。作者提出的方法在 MSR-VTT、VATEX、ActivityNet 和 MSVD 的視頻到文本和文本到視頻檢索方面明顯優(yōu)于其他方法。
Cross-modal discrimination和cross-captioning:作者的模型從兩個(gè)互補(bǔ)的損失中學(xué)習(xí):(a)Cross-modal 對比學(xué)習(xí)學(xué)習(xí)強(qiáng)大的聯(lián)合視頻文本的Embedding,但所有其他樣本都被認(rèn)為是負(fù)例,甚至推開語義相關(guān)的標(biāo)題(橙色箭頭)。(b) 我們引入了cross-captioning的生成任務(wù),通過學(xué)習(xí)將樣本的文本表示重構(gòu)為支持集的加權(quán)組合,由其他樣本的視頻表示組成,從而緩解了這一問題。
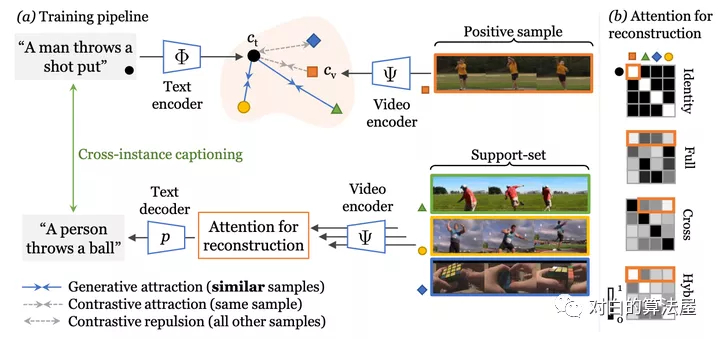
作者的cross-modal框架具有判別(對比)目標(biāo)和生成目標(biāo)。該模型學(xué)習(xí)將公共Embedding空間中的視頻-文本對與文本和視頻編碼器(頂部)相關(guān)聯(lián)。同時(shí),文本還必須重建為來自支持集的視頻Embedding的加權(quán)組合,通過Attention選擇,這會強(qiáng)制不同樣本之間的Embedding共享。
對比學(xué)習(xí)(NIPS2020)
非常經(jīng)典的九篇論文
1.SpCL

論文標(biāo)題:Self-paced Contrastive Learning with Hybrid Memory for Domain Adaptive Object Re-ID
論文方向:目標(biāo)重識別,提出自步對比學(xué)習(xí),在無監(jiān)督目標(biāo)重識別任務(wù)上顯著地超越最先進(jìn)模型高達(dá)16.7%
論文來源:NIPS2020
論文鏈接:https://arxiv.org/abs/2006.02713
論文代碼:https://github.com/yxgeee/SpCL
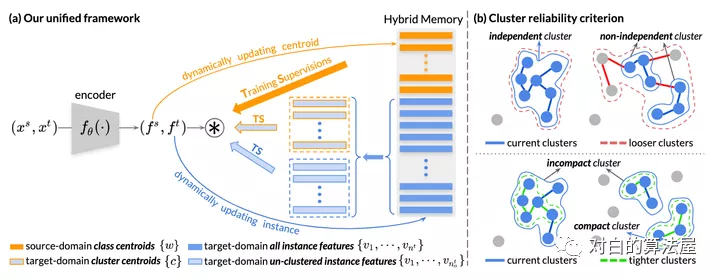
本文提出自步對比學(xué)習(xí)(Self-paced Contrastive Learning)框架,包括一個(gè)圖像特征編碼器(Encoder)和一個(gè)混合記憶模型(Hybrid Memory)。核心是混合記憶模型在動態(tài)變化的類別下所提供的連續(xù)有效的監(jiān)督,以統(tǒng)一對比損失函數(shù)(Unified Contrastive Loss)的形式監(jiān)督網(wǎng)絡(luò)更新,實(shí)現(xiàn)起來非常容易,且即插即用。
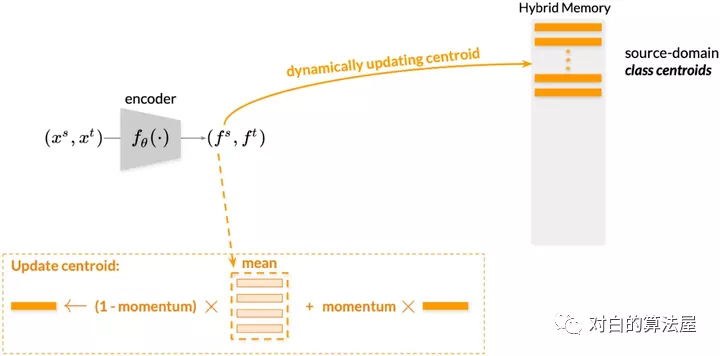
上文中提到混合記憶模型(Hybrid Memory)實(shí)時(shí)提供三種不同的類別原型,作者提出了使用動量更新(Momentum Update),想必這個(gè)詞對大家來說并不陌生,在MoCo、Mean-teacher等模型中常有見到,簡單來說,就是以“參數(shù)= (1-動量)x新參數(shù)+動量x參數(shù)”的形式更新。這里針對源域和目標(biāo)域采取不同的動量更新算法,以適應(yīng)其不同的特性。
對于源域的數(shù)據(jù)而言,由于具有真實(shí)的類別,作者提出以類為單位進(jìn)行存儲。這樣的操作一方面節(jié)省空間,一方面在實(shí)驗(yàn)中也取得了較好的結(jié)果。將當(dāng)前mini-batch內(nèi)的源域特征根據(jù)類別算均值,然后以動量的方式累計(jì)到混合記憶模型中對應(yīng)的類質(zhì)心上去。對于目標(biāo)域的數(shù)據(jù)而言,作者提出全部以實(shí)例為單位進(jìn)行特征存儲,這是為了讓目標(biāo)域樣本即使在聚類和非聚類離群值不斷變化的情況下,仍然能夠在混合記憶模型中持續(xù)更新(Continuously Update)。具體而言,將當(dāng)前mini-batch內(nèi)的目標(biāo)域特征根據(jù)實(shí)例的index累計(jì)到混合記憶模型對應(yīng)的實(shí)例特征上去。
2.SimCLR V2(Hinton又一巨作)

論文標(biāo)題:Big Self-Supervised Models are Strong Semi-Supervised Learners
論文方向:圖像領(lǐng)域(Google出品)
論文來源:NIPS2020
論文鏈接:Big Self-Supervised Models are Strong Semi-Supervised Learners
論文代碼:https://github.com/google-research/simclr
本文針對深度學(xué)習(xí)中數(shù)據(jù)集標(biāo)簽不平衡的問題,即大量的未標(biāo)注數(shù)據(jù)和少量標(biāo)注數(shù)據(jù),作者提出了一種弱監(jiān)督的模型SimCLRv2(基于SimCLRv1)。作者認(rèn)為這種龐大的、極深的網(wǎng)絡(luò)更能夠在自監(jiān)督的學(xué)習(xí)中獲得提升。論文中的思想可以總結(jié)為一下三步:
1. 使用ResNet作為backbone搭建大型的SimCLRv2,進(jìn)行無監(jiān)督的預(yù)訓(xùn)練;
2. 然后在少量有標(biāo)注的數(shù)據(jù)上進(jìn)行有監(jiān)督的finetune;
3. 再通過未標(biāo)注的數(shù)據(jù)對模型進(jìn)行壓縮并遷移到特定任務(wù)上;
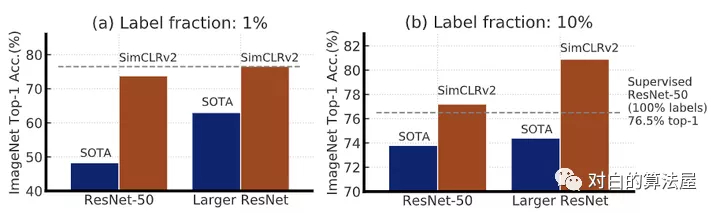
實(shí)驗(yàn)結(jié)果表明他們的模型對比SOTA是有很大的提升的:
作者采用SimCLR中的對比訓(xùn)練方法,即,最大化圖片與其增強(qiáng)后(旋轉(zhuǎn)、放縮、顏色變換等)之間的關(guān)聯(lián)程度,通過優(yōu)化在其隱空間上的對比損失,其公式如下:
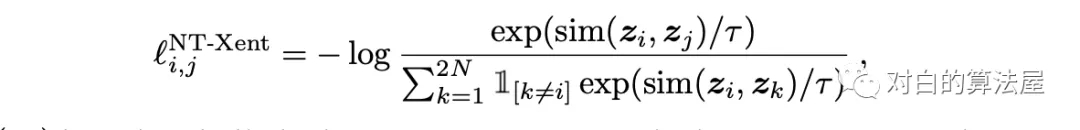
SimCLR V2的網(wǎng)絡(luò)結(jié)構(gòu)如下所示:
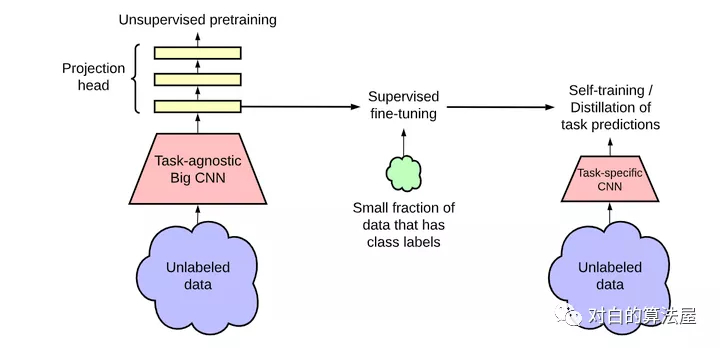
在SimCLR V2中,相比V1有一下幾點(diǎn)改進(jìn):
V2大大加深了網(wǎng)絡(luò)的規(guī)模,最大的規(guī)模達(dá)到了152層的ResNet,3倍大小的通道數(shù)以及加入了SK模塊(Selective Kernels),據(jù)說在1%標(biāo)注數(shù)據(jù)的finetune下可以達(dá)到29%的性能提升;
首先V2使用了更深的projection head;其次,相比于v1在預(yù)訓(xùn)練完成后直接拋棄projection head,V2保留了幾層用于finetune,這也是保留了一些在預(yù)訓(xùn)練中提取到的特征;
使用了一種記憶機(jī)制(參考了這篇論文),設(shè)計(jì)一個(gè)記憶網(wǎng)絡(luò),其輸出作為負(fù)樣本緩存下來用以訓(xùn)練。
3.Hard Negative Mixing for Contrastive Learning

論文標(biāo)題:Hard Negative Mixing for Contrastive Learning
論文方向:圖像和文本領(lǐng)域,通過在特征空間進(jìn)行 Mixup 的方式產(chǎn)生更難的負(fù)樣本
論文來源:NIPS2020
論文鏈接:https://arxiv.org/abs/2010.01028
難樣本一直是對比學(xué)習(xí)的主要研究部分,擴(kuò)大 batch size,使用 memory bank 都是為了得到更多的難樣本,然而,增加內(nèi)存或batch size并不能使得性能一直快速提升,因?yàn)楦嗟呢?fù)樣本并不一定意味著帶來更難的負(fù)樣本。于是,作者通過Mixup的方式來產(chǎn)生更難的負(fù)樣本。該文章對這類問題做了詳盡的實(shí)驗(yàn),感興趣的可以閱讀原論文。
4.Supervised Contrastive Learning

論文標(biāo)題:Supervised Contrastive Learning
論文方向:提出了監(jiān)督對比損失(Google出品,必屬精品)
論文來源:NIPS2020
論文鏈接:https://arxiv.org/abs/2004.11362
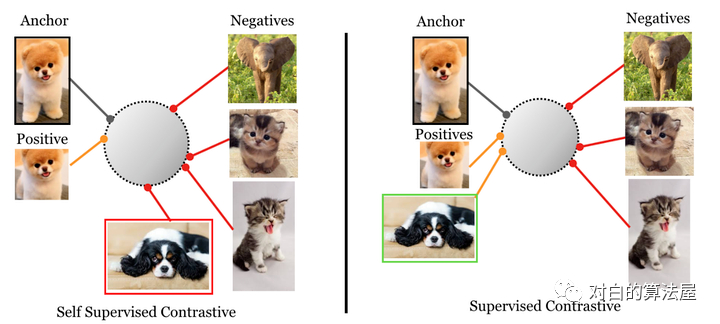
有監(jiān)督方法vs自監(jiān)督方法的對比損失:
supervised contrastive loss(左),將一類的positive與其他類的negative進(jìn)行對比(因?yàn)樘峁┝藰?biāo)簽), 來自同一類別的圖像被映射到低維超球面中的附近點(diǎn)。
self-supervised contrastive loss(右),未提供標(biāo)簽。因此,positive是通過作為給定樣本的數(shù)據(jù)增強(qiáng)生成的,negative是batch中隨機(jī)采樣的。這可能會導(dǎo)致false negative(如右下所示),可能無法正確映射,導(dǎo)致學(xué)習(xí)到的映射效果更差。
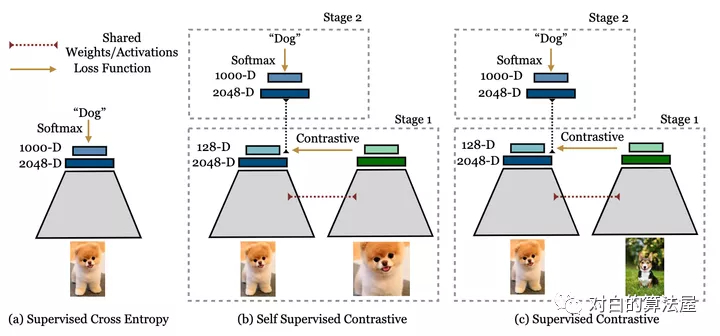
論文核心點(diǎn):
其基于目前常用的contrastive loss提出的新的loss,(但是這實(shí)際上并不是新的loss,不是取代cross entropy的新loss,更準(zhǔn)確地說是一個(gè)新的訓(xùn)練方式)contrastive loss包括兩個(gè)方面:一是positive pair, 來自同一個(gè)訓(xùn)練樣本 通過數(shù)據(jù)增強(qiáng)等操作 得到的兩個(gè)feature構(gòu)成, 這兩個(gè)feature會越來越接近;二是negative pair, 來自不同訓(xùn)練樣本的 兩個(gè)feature 構(gòu)成, 這兩個(gè)feature 會越來越遠(yuǎn)離。本文不同之處在于對一個(gè)訓(xùn)練樣本(文中的anchor)考慮了多對positive pair,原來的contrastive learning 只考慮一個(gè)。
其核心方法是兩階段的訓(xùn)練。如上圖所示。從左向右分別是監(jiān)督學(xué)習(xí),自監(jiān)督對比學(xué)習(xí),和本文的監(jiān)督對比學(xué)習(xí)。其第一階段:通過已知的label來構(gòu)建contrastive loss中的positive 和negative pair。因?yàn)橛衛(wèi)abel,所以negative pair 不會有false negative(見圖1解釋)。其第二階段:凍結(jié)主干網(wǎng)絡(luò),只用正常的監(jiān)督學(xué)習(xí)方法,也就是cross entropy 訓(xùn)練最后的分類層FC layer。
實(shí)驗(yàn)方面,主要在ImageNet上進(jìn)行了實(shí)驗(yàn),通過accuracy驗(yàn)證其分類性能,通過common image corruption 驗(yàn)證其魯棒性。
5.Contrastive Learning with Adversarial Examples

論文標(biāo)題:Contrastive Learning with Adversarial Examples
論文方向:對抗樣本+對比學(xué)習(xí)
論文來源:NIPS2020
論文鏈接:https://arxiv.org/abs/2010.12050
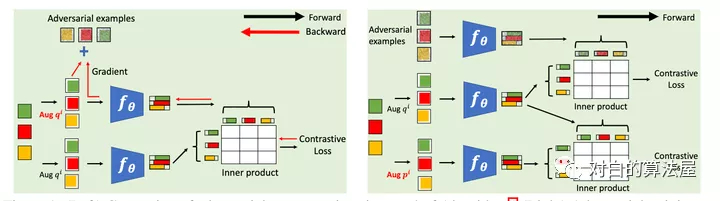
本文在標(biāo)準(zhǔn)對比學(xué)習(xí)的框架中,引入了對抗樣本作為一種數(shù)據(jù)增強(qiáng)的手段,具體做法為在標(biāo)準(zhǔn)對比損失函數(shù)基礎(chǔ)上,額外添加了對抗對比損失作為正則項(xiàng),從而提升了對比學(xué)習(xí)基線的性能。簡單來說,給定數(shù)據(jù)增強(qiáng)后的樣本,根據(jù)對比損失計(jì)算對該樣本的梯度,然后利用 FGSM (Fast Gradient Sign Method)生成相應(yīng)的對抗樣本,最后的對比損失由兩個(gè)項(xiàng)構(gòu)成,第一項(xiàng)為標(biāo)準(zhǔn)對比損失(兩組隨機(jī)增強(qiáng)的樣本對),第二項(xiàng)為對抗對比損失(一組隨機(jī)增強(qiáng)的樣本以及它們的對抗樣本),兩項(xiàng)的重要性可指定超參數(shù)進(jìn)行調(diào)節(jié)。
6.LoCo

論文標(biāo)題:LoCo: Local Contrastive Representation Learning
論文方向:利用對比學(xué)習(xí)對網(wǎng)絡(luò)進(jìn)行各層訓(xùn)練
論文來源:NIPS2020
論文鏈接:https://arxiv.org/abs/2008.01342
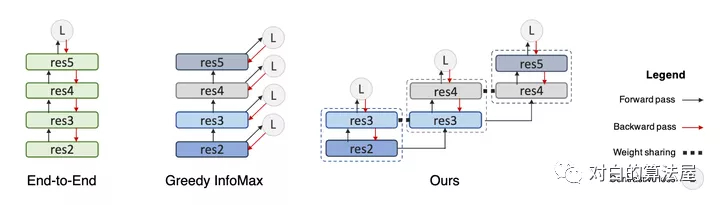
上圖左邊,展示了一個(gè)使用反向傳播的常規(guī)端到端網(wǎng)絡(luò),其中每個(gè)矩形表示一個(gè)下采樣階段。在中間,是一個(gè)GIM,其中在每個(gè)階級的末尾加上一個(gè)infoNCE損失,但是梯度不會從上一級流回到下一級。編碼器早期的感受野可能太小,無法有效解決對比學(xué)習(xí)問題。由于相同的infoNCE損失被應(yīng)用于所有的局部學(xué)習(xí)塊(包括早期和晚期),早期階段的解碼器由于感受野有限,很難得到表征進(jìn)行正確的區(qū)分正樣本。例如,在第一階段,我們需要在特征圖上使用
的核執(zhí)行全局平均池化,然后將其發(fā)送到解碼器(非線性全連接)進(jìn)行分類。
我們可以在解碼器中加入卷積層來擴(kuò)大感受野。然而,這種增加并沒有對端到端的simclr產(chǎn)生影響,因?yàn)樽詈箅A段的感受野足夠很大。其實(shí),通過在局部階段之間共享重疊級,就我們可以有效地使解碼器的感受野變大,而不會在前向傳遞中引入額外的成本,同時(shí)解決了文中描述的兩個(gè)問題。
7.What Makes for Good Views for Contrastive Learning?

論文標(biāo)題:What Makes for Good Views for Contrastive Learning?
論文方向:提出InfoMin假設(shè),探究對比學(xué)習(xí)有效的原因(Google出品,必屬精品)
論文來源:NIPS2020
論文鏈接:https://arxiv.org/abs/2005.10243
首先作者提出了三個(gè)假設(shè):
- Sufficient Encoder
- Minimal Sufficient Encoder
- Optimal Representation of a Task其次,作者舉了一個(gè)非常有趣的例子,如下圖所示:
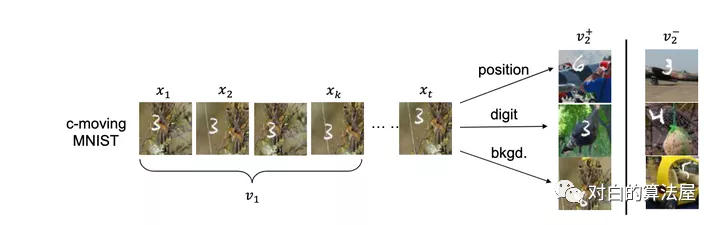
數(shù)字, 在某個(gè)隨機(jī)背景上以一定速度移動, 這個(gè)數(shù)據(jù)集有三個(gè)要素:
- 數(shù)字
- 數(shù)字的位置
- 背景
左邊的v1即為普通的view, 右邊v2+是對應(yīng)的正樣本, 所構(gòu)成的三組正樣本對分別共享了數(shù)字、數(shù)字的位置和背景三個(gè)信息,其余兩個(gè)要素均是隨機(jī)選擇,故正樣本也僅共享了對應(yīng)要素的信息. 負(fù)樣本對的各要素均是隨機(jī)選擇的。
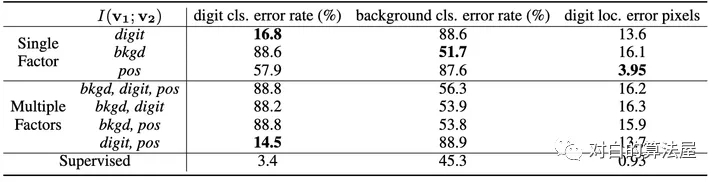
實(shí)驗(yàn)結(jié)果如上表,如果像文中所表述的,正樣本對僅關(guān)注某一個(gè)要素, 則用于下游任務(wù)(即判別對應(yīng)的元素,如判別出數(shù)字,判別出背景, 判別出數(shù)字的位置),當(dāng)我們關(guān)注哪個(gè)要素的時(shí)候, 哪個(gè)要素的下游任務(wù)的效果就能有明顯提升(注意數(shù)字越小越好)。
本文又額外做了同時(shí)關(guān)注多個(gè)要素的實(shí)驗(yàn), 實(shí)驗(yàn)效果卻并不理想, 往往是背景這種更為明顯,更占據(jù)主導(dǎo)的地位的共享信息會被對比損失所關(guān)注。
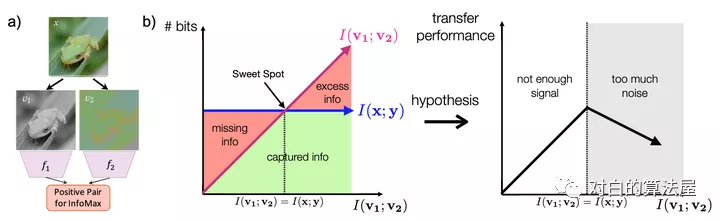
作者緊接著, 提出了一些構(gòu)造 novel views 的辦法。正如前面已經(jīng)提到過的, novel views v1,v2應(yīng)當(dāng)是二者僅共享一些與下游任務(wù)有關(guān)的信息, 抓住這個(gè)核心。這樣會形成一個(gè)U型,最高點(diǎn)定義為甜點(diǎn),我們的目標(biāo)就是讓兩個(gè)視圖的信息能夠剛好達(dá)到甜點(diǎn),不多不少,只學(xué)到特定的特征。
8.GraphCL

論文標(biāo)題:Graph Contrastive Learning with Augmentations
論文方向:圖+對比學(xué)習(xí)
論文來源:NIPS2020
論文鏈接:https://arxiv.org/abs/2010.13902
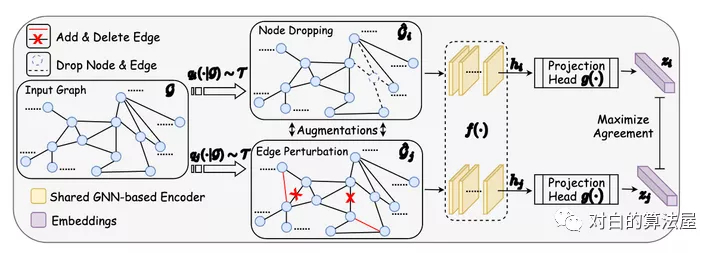
如上圖所示,通過潛在空間中的對比損失來最大化同一圖的兩個(gè)擴(kuò)充view之間的一致性,來進(jìn)行預(yù)訓(xùn)練。
在本文中,作者針對GNN預(yù)訓(xùn)練開發(fā)了具有增強(qiáng)功能的對比學(xué)習(xí),以解決圖數(shù)據(jù)的異質(zhì)性問題。
由于數(shù)據(jù)增強(qiáng)是進(jìn)行對比學(xué)習(xí)的前提,但在圖數(shù)據(jù)中卻未得到充分研究,因此本文首先設(shè)計(jì)四種類型的圖數(shù)據(jù)增強(qiáng),每種類型都強(qiáng)加了一定的先于圖數(shù)據(jù),并針對程度和范圍進(jìn)行了參數(shù)化;
利用不同的增強(qiáng)手段獲得相關(guān)view,提出了一種用于GNN預(yù)訓(xùn)練的新穎的圖對比學(xué)習(xí)框架(GraphCL),以便可以針對各種圖結(jié)構(gòu)數(shù)據(jù)學(xué)習(xí)不依賴于擾動的表示形式;
證明了GraphCL實(shí)際上執(zhí)行了互信息最大化,并且在GraphCL和最近提出的對比學(xué)習(xí)方法之間建立了聯(lián)系;
證明了GraphCL可以被重寫為一個(gè)通用框架,從而統(tǒng)一了一系列基于圖結(jié)構(gòu)數(shù)據(jù)的對比學(xué)習(xí)方法;
評估在各種類型的數(shù)據(jù)集上對比不同擴(kuò)充的性能,揭示性能的基本原理,并為采用特定數(shù)據(jù)集的框架提供指導(dǎo);
GraphCL在半監(jiān)督學(xué)習(xí),無監(jiān)督表示學(xué)習(xí)和遷移學(xué)習(xí)的設(shè)置中達(dá)到了最佳的性能,此外還增強(qiáng)了抵抗常見對抗攻擊的魯棒性。
9.ContraGAN

論文標(biāo)題:ContraGAN: Contrastive Learning for Conditional Image Generation
論文方向:條件圖像生成領(lǐng)域
論文來源:NIPS2020
論文鏈接:https://arxiv.org/abs/2006.12681
論文代碼:https://github.com/POSTECH-CVLab/PyTorch-StudioGAN
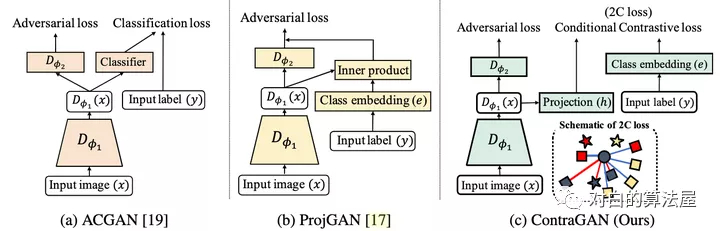
本文的方法是:判別器的大致結(jié)構(gòu)和projGAN類似,首先輸入圖片x經(jīng)過特征提取器D,得到特征向量;然后分兩個(gè)分支,一個(gè)用于對抗損失判斷圖片是否真實(shí),一個(gè)用于將特征經(jīng)過一個(gè)projection head h 變成一個(gè)維度為k的向量(這個(gè)D+h的過程稱為)。對于圖片的類別,經(jīng)過一個(gè)類別emmbedding變成一個(gè)也是維度為k的向量。
損失函數(shù)也是infoNCE loss 只不過使用類標(biāo)簽的嵌入作為相似,而不是使用數(shù)據(jù)擴(kuò)充。
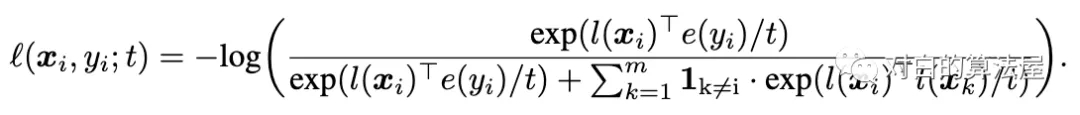
上面的損害將參考樣本xi拉到更靠近嵌入e(yi)的類別,并將其他樣本推開。但是這個(gè)loss可以推開具有與yi相同標(biāo)簽的被認(rèn)為是負(fù)樣本。因此,我們還要拉近具有相似類別的圖片的距離:
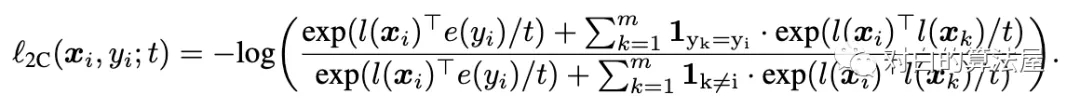
這樣,就拉近圖片和其類別的距離,同時(shí)拉近相同類別的圖片的距離。
總結(jié)
對比學(xué)習(xí)已廣泛應(yīng)用在AI各個(gè)領(lǐng)域中,且作為自監(jiān)督學(xué)習(xí)中的代表,效果甚至已經(jīng)超越了很多有監(jiān)督學(xué)習(xí)任務(wù)。很多互聯(lián)網(wǎng)公司內(nèi)部其實(shí)都有許許多多這樣的業(yè)務(wù)需要大量人力進(jìn)行標(biāo)注,AI才能進(jìn)行訓(xùn)練,從而得到一個(gè)不錯(cuò)的效果(無監(jiān)督一般不敢上),而有了對比學(xué)習(xí)這個(gè)思想后,既能降本又能增效,AI煉丹師們終于可以開心的得到一個(gè)更好的效果,實(shí)現(xiàn)”技術(shù)有深度,業(yè)務(wù)有產(chǎn)出“這樣的目標(biāo)。期待對比學(xué)習(xí)這個(gè)領(lǐng)域誕生出更多好的作品,在各個(gè)應(yīng)用方向開花結(jié)果,也期待NIPS2021的優(yōu)秀論文們!