













中科大神經網絡和端到端訓練框架,探究教育情境對學生能力的影響
來自中國科學技術大學的研究者提出了一種教育情境感知的認知診斷框架,使用神經網絡以及端到端的訓練框架,自適應學習不同教育情境信息的量化影響,并結合現有認知診斷工作的方法,增強了診斷的結果。
父母的受教育水平是否與學生的學習表現相關?家庭條件、學校資源到底對學生能力產生多大影響?上課氛圍、老師態度與學生的學習效果有怎樣的關系?類似的教育情境信息對學生能力到底有怎樣的影響,一起跟隨中國科學技術大學的劉淇教授智慧教育課題組來一探究竟吧!

- 論文地址:https://doi.org/10.1145/3447548.3467264
- 項目地址:github.com/bigdata-ustc/ECD
- 研究組主頁:base.ustc.edu.cn/
教育情境與認知診斷
學生學習過程相關情境信息(如學習習慣,父母受教育程度,家庭條件等),被稱為教育情境信息;在教育領域中,這些情境信息對理解教育過程以及解決教育問題(如教學安排,教育公平等)都有很重要的意義。
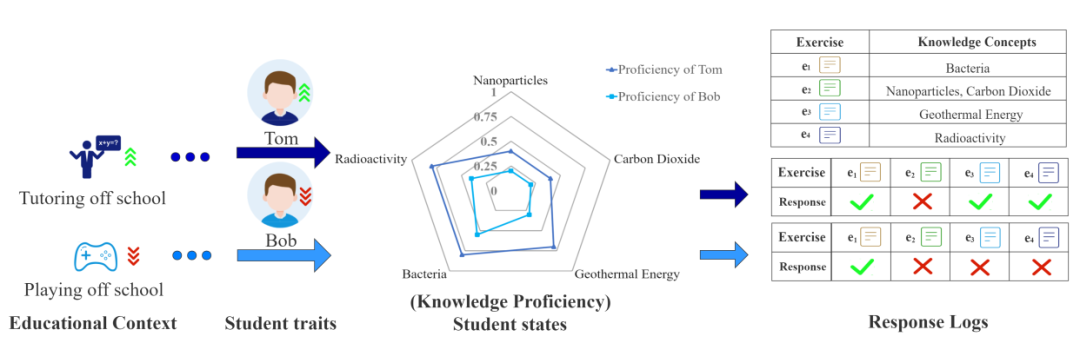
圖表 1:教育情境、學生能力與學生表現
在智慧教育中,認知診斷是一項基礎而必要的任務;它通過收集學生的信息(通常是答題等行為記錄)與試題信息(如試題文本),來推斷學生當前的知識狀態。如圖,學生選擇了一些題目進行練習,得到了對應的答題記錄,每道試題包含特定的知識點;通過認知診斷可以得到該學生在不同知識點上的掌握程度。例如學生答對了試題e_1,而e_1包含「Bacteria」這個知識點,因此診斷得出該學生對于「Bacteria」知識點的掌握程度較高(例如 0.8 等),反映到診斷報告的雷達圖中藍線的靠近外側。認知診斷的結果可以用作教育資源推薦、學生表現預測、學習小組分組等后續智慧教育應用的支撐。
背景
情境信息或者說上下文信息目前在信息檢索相關領域(如推薦系統,web 搜索,廣告等)有著非常廣泛的應用,它們反映著一個心理學的通識:情境信息往往通過影響人的內在特質來影響人的外在表現。如推薦系統中,情境信息通過影響用戶的內在偏好,從而引導用戶的消費行為。而在教育領域,教育情境信息則影響著學生的知識狀態,進而反映在學生的練習作答結果中。
教育情境信息在傳統教育學中討論已久,它們主要延續著實證研究的思路(提出假設 - 收集數據 - 實驗分析 - 得出結論),先獲取學生的得分或者能力作為衡量標準,再使用主成分分析、線性回歸等方法對教育情境信息的作用進行分析。其中學生得分可比要求學生所做練習相同,因此在大規模的情境信息分析中,往往采用基于傳統認知診斷理論得到的學生能力作為衡量的方式。
認知診斷研究可以追溯到教育心理學領域,代表性的工作有項目反映理論(Item Response Theory,IRT)。近年來,隨著人工智能以及智慧教育的興起,作為智慧教育應用的基礎任務之一,基于機器學習、深度學習的認知診斷方法被廣泛研究,其中經典的工作有將項目反映理論拓展的多維項目反映理論(Multidimensional Item Response Theory,MIRT),使用神經網絡學習認知函數的神經認知診斷框架(Neural Cognitive Diagnosis,NeuralCD)。然而,目前認知診斷的工作往往只關注于試題相關信息(如試題知識點矩陣、知識點的關系、試題文本等)的挖掘,對于學生學習過程相關的教育情境信息則關注很少。
此外,雖然使用認知診斷結果一定程度上能解決教育情境信息分析中的可比性問題,但傳統教育領域的研究方式依然存在誤差傳遞、影響難以量化等問題。在這一背景下,該研究提出教育情境感知的認知診斷框架,期望使用神經網絡以及端到端的訓練框架,自適應學習不同教育情境信息的量化影響,并結合現有認知診斷工作的方法,增強診斷的結果。
教育情境感知的認知診斷
1、問題定義
設學習系統中有 N 個學生,T 個情境信息問題以及 M 個練習。學生集合
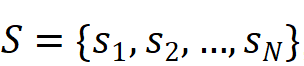
,情境問題集合
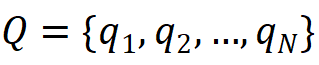
,練習問題集合
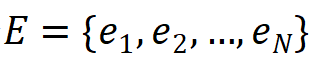
。學生的情境信息記錄表示為三元組
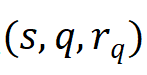
集合R_q;答題記錄表示為
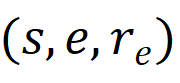
的集合R_e,其中
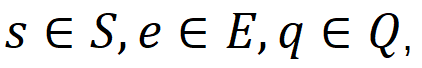
r_q與r_e分別是學生s對情境問題q的回答與在練習e上的得分。
給定學生s的記錄
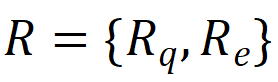
,該研究的目標是通過學生表現預測的過程,獲取學生s的知識點掌握程度。
2、情境感知的認知診斷框架
幾乎所有傳統認知診斷方法都包括學生參數、試題參數、學生與試題交互函數這三個部分,其合理性已被大量工作驗證。總體上,學生作答過程可以形式化為
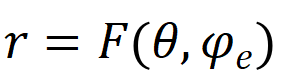
,其中
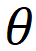
,
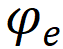
分別代表學生知識狀態、練習相關參數(如難度,知識點),F為認知函數,r為學生表現。學生知識狀態則可以進一步表示為:
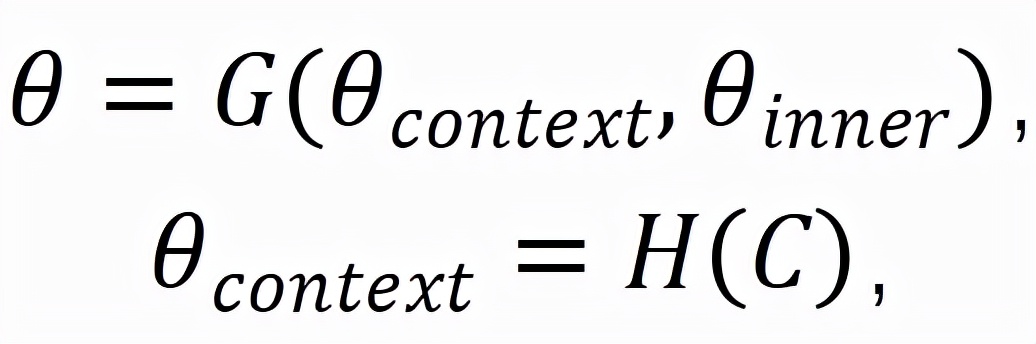
其中C為情境信息輸入,H為情境影響函數,

,
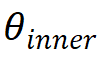
分別代表情境影響的外顯特質與歷史學習情況影響的學生內在特質,G代表學生特質對知識狀態的映射函數。
該研究提出一個兩階段的框架:教育情境建模階段與診斷強化階段。
- 首先,在教育情境建模階段中,該研究提出使用一個分層注意力網絡建模情境輸入對學生知識狀態的外在影響表示 ,即建模情境影響函數H。具體網絡結構在下小節介紹。
- 其次,在診斷強化階段,該研究通過將學生參數(學生知識狀態)形式化為情境信息影響的外顯特質與歷史學習情況影響的內在特質兩部分的調和(映射函數G)。
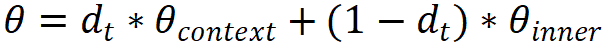
其中,d_t為學生 id 映射的權重參數,由網絡學習。這樣,情境信息表示能夠對現有的認知診斷方法(認知函數F)進行拓展。該研究對認知診斷領域經典的 IRT、MIRT 以及 NeuralCD 方法進行了拓展實現。
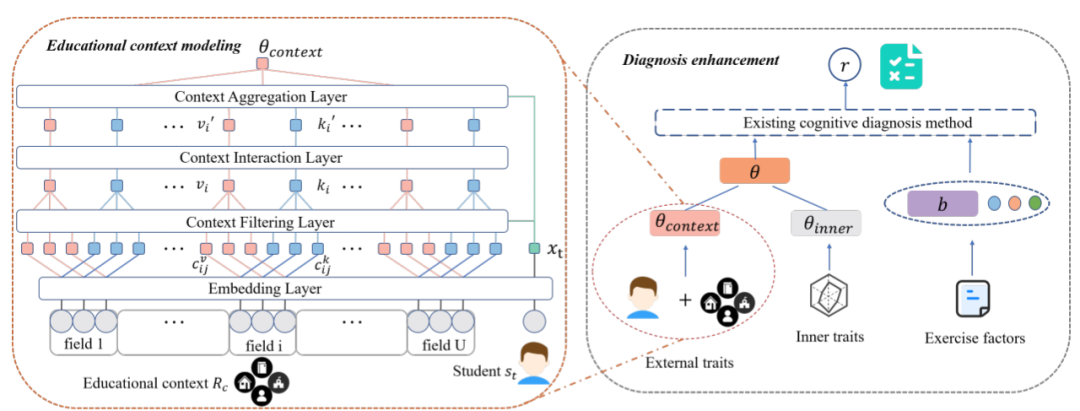
圖表 3:ECD 模型框架
3、情境信息建模
教育情境信息主要包括以下特點:內容復雜性,個體差異性,內在相關性。其中內容復雜性指教育情境信息輸入包含豐富來源的內容。個體差異性則是指同一情境信息對學生的影響也會因人而異。例如情境信息「接受輔導」對于學生的影響雖然總體上是積極的,但是對于勤奮的學生的影響往往要比貪玩的學生更明顯(因為貪玩的學生很可能不會認真學習,從而無法充分利用這一積極條件)。內在相關性則是指不同情境信息之間也可能存在相互影響。比如「家庭條件」也可能影響「接受輔導」的效果。
針對上述特性,該研究首先根據內容將情境信息輸入分成不同的分組,分別建模其影響。其次,該研究使用注意力機制計算學生特性與情境信息之間的相性,從而自適應學習不同情境信息對學生的影響權重。接著,該研究使用自注意力機制模塊來模擬不同輸入之間的相互影響情況。
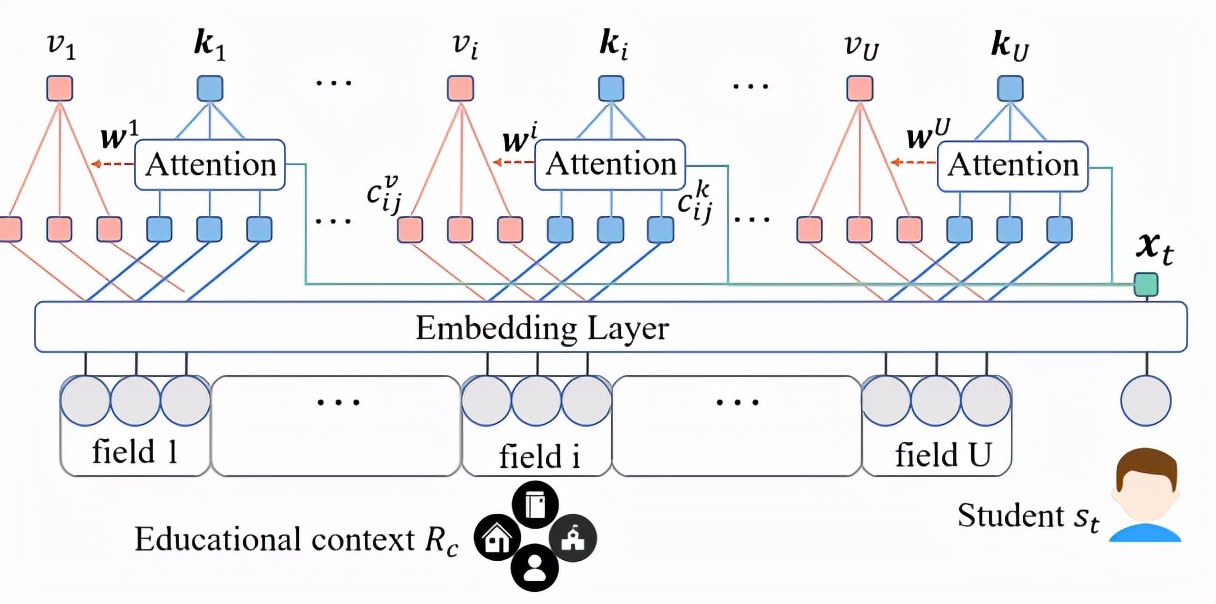
圖表 4:Embedding 層與 Context filtering 層
具體來說,情境建模網絡包含四層網絡結構:嵌入(embedding)層、過濾(context filtering)層、交互(context interaction)層、聚合(context aggregation)層。該研究在嵌入層將每個情境信息輸入r_q映射為情境影響向量c^v與情境特性向量c^k,將學生 id 輸入t映射為個性向量x_t。在過濾層中,對于某一組情境信息的不同輸入,該研究將學生個性表示x_t作為注意力機制中的查詢 query,將情境特性表示c^k與情境影響表示c^v分別作為注意力機制中的鍵 key 與值 value。通過計算學生個性表示x_t與情境特性表示c^k的余弦相似度作為學生與特定情境輸入的相性,進而分配組內不同情境輸入影響c^v,以及該組情境特性c^k的權重,這樣就能得到各組情境輸入的影響表示v與特性表示k。
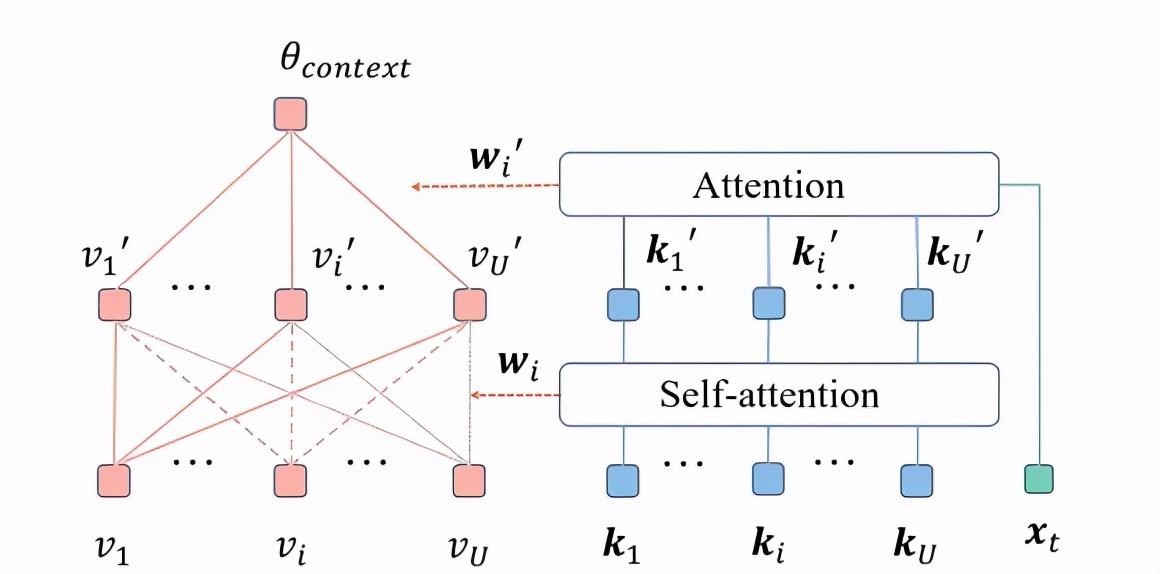
圖表 5:Context interaction 層與 Context aggregation 層
在交互層中,類似的,該研究使用各組情境的影響表示v與特性k表示分別作為自注意力機制中的值 value 與鍵 key,從而得到交互后的各組情境輸入的影響表示v'與特性表示k'。最后,在聚合層中,該研究依然使用個性表示x_t作為注意力機制中的查詢 query,將各組情境輸入的影響表示v'與特性表示k'分別作為自注意力機制中的值 value 與鍵 key,從而聚合各組情境輸入,得到情境輸入對學生的最終的影響表示
。
實驗
實驗使用的數據來自國際學生評估項目(Programme for International Student Assessment,PISA)2015 年的公開數據集(以下簡稱 PISA2015),包含來自 79 個國家與地區的學生的問卷數據與答題數據。PISA 項目是由世界經合組織(OECD)組織的國際學生評估項目,包含專家設計的與教育情境信息相關的學生問卷數據與學生在數學、科學、閱讀等學科的測試作答數據,PISA 2015 的主要測試科目是科學,因此實驗中使用學生在科學測試中的作答數據。該研究根據區域,將 PISA2015 的科學作答數據中抽取了三個數據集,分別是 Asia、Europe 與 America,具體的數據預處理可以參考論文內容,下表是數據集統計情況。
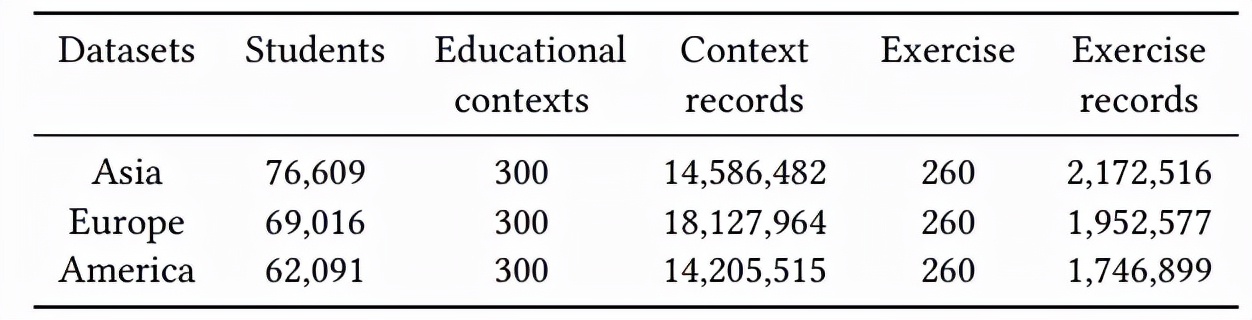
表格 1:數據集統計
1. 學生表現預測
學生真實的知識點熟練度標簽是無法獲取的,因此該研究采用間接衡量診斷結果準確性的方法,即使用學生的診斷結果來預測學生的在非訓練數據中試題的得分,這也是傳統認知診斷模型的常規做法。該研究實驗的 baseline 包括兩類,一類是沒有情境信息強化的傳統認知針對模型(如 NeuralCD,IRT 以及 MIRT),一類是基于該研究的二階段框架,使用傳統的上下文建模網絡(如 Deep FM 與 NeuralFM 網絡)對情境信息影響進行建模的模型。實驗的結果如下表,該研究的 ECD-NeuralCD、ECD-IRT、ECD-MIRT 模型在不同區域的數據集中相較兩類 baseline 取得了較大的提升。此外,隨機模型(random)在不同數據集上 AUC 都在 0.5 左右,驗證了數據集的樣本分布情況是合理的。
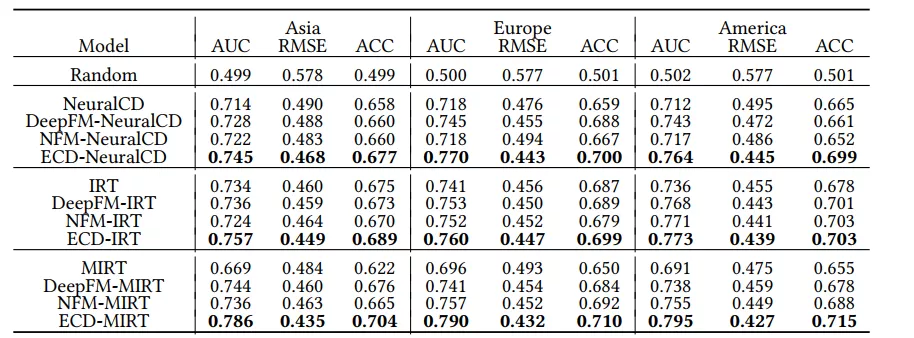
表格 2:學生表現預測
2. 消融實驗
為了證明情境建模網絡結構的合理性,該研究通過使用求和層代替情境建模網絡中的各個網絡層進行了消融實驗,結果如下表。任何一層網絡的取代都會降低最終的實驗效果,并且聚合層的影響最為明顯。
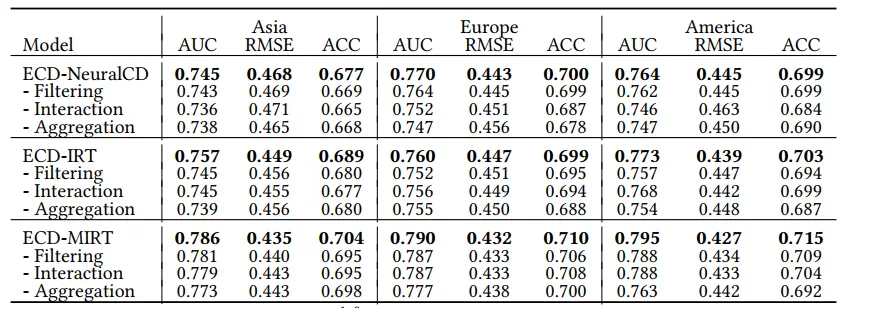
表格 3:消融實驗
3. 參數解釋性實驗
為了進一步說明模型的可解釋性,該研究還做了以下參數解釋性實驗:個性向量的可視化實驗,過濾層的注意力模塊可視化實驗,情境信息影響的外顯特質的權重的統計實驗。
1)個性向量的可視化實驗
該研究首先將學生個性向量使用 t-SNE 進行降維,并可視化為散點;接著對于每個散點,根據該學生在練習上的平均得分率(0~1)進行染色,可視化如圖。可以看到,學習的個性向量的分布與學生的平均得分率之間是存在相關性的,這也與研究者的直覺一致。
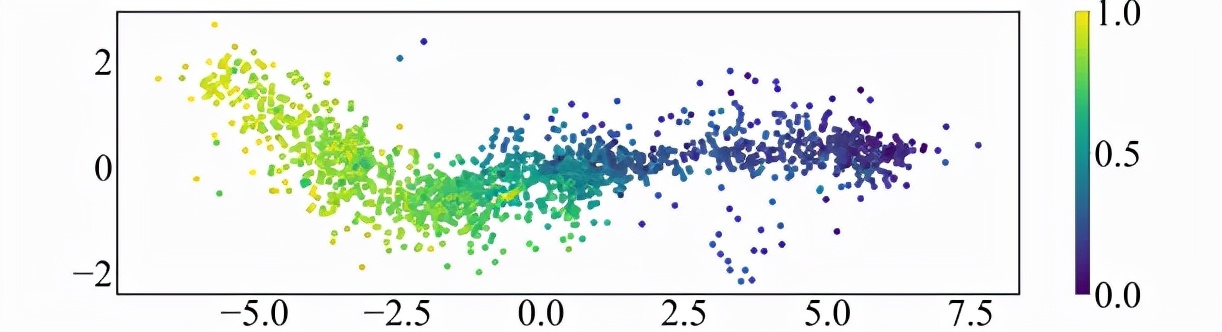
圖表 6:學生個性向量可視化分析
2)過濾層注意力模塊可視化
該研究選取了部分學生的情境輸入的注意力權重進行可視化,其中 NO.0~4 的學生是平均得分率低的學生,NO.5~9 的學生有較高的得分率。研究者將其對應的情境輸入編碼(同一情境信息,編碼越大的輸入代表它對于學生的知識狀態影響越積極)也可視化在圖中。從 “Books” 信息的橫向對比,可以看到低得分率的學生關注于較為消極的輸入,而高得分率的學生則關注較為積極的輸入;從 4、8、9 號學生的縱向對比,也可以得到類似的結論。這說明注意力模塊的確模擬了情境信息與學生個性之間的相性。
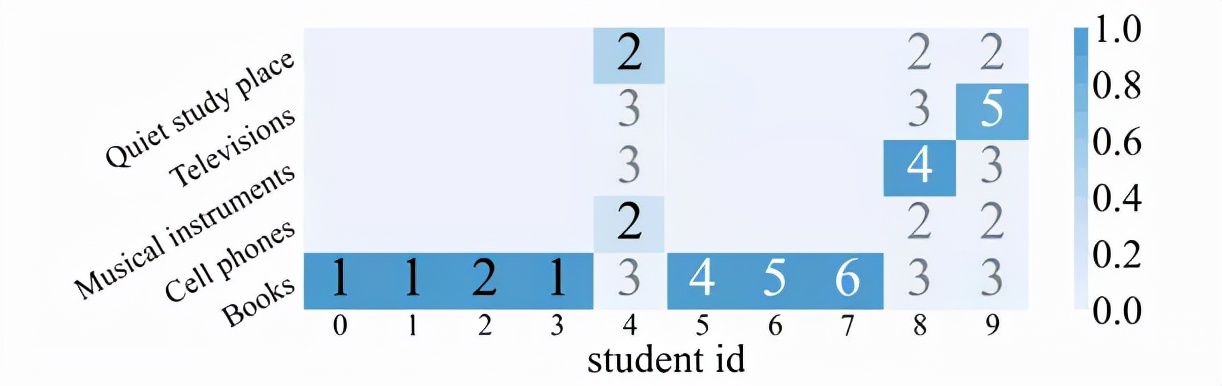
圖表 7:注意力可視化
3)情境影響的權重
該研究統計了不同 ECD 模型實現中,以及 ECD-MIRT 中部分地區的各個學生參數的分布情況,結果絕大多數d_t都在 0.5 左右(0.4~0.6),說明情境信息影響的外顯特質與學生歷史學習情況的內在特質對學生最終的知識狀態都有重要的影響。

圖表 8:情境權重分析
4. 地區對比實驗
最后,該研究也基于聚合(context aggregation)層中不同內容的情境影響的注意力權重,統計了各個學生 top-3 中要的情境信息,并分地區進行統計,結果如下表。其中有一些有意思的發現,教育資源相關情境信息在所有區域都很重要,例如家庭條件(Home ESCS)以及信息通信技術(ICT)相關的情境(PS:United States 區域缺少該部分的情境信息)。中韓地區會關注父母的受教育程度,研究者推測這可能與中韓相似的高考制度與氛圍有關。而歐美地區對于在校學習相關的“School learning“與”Teacher Attitude“會比較關注,而亞洲地區對它們則不那么關注,研究者推測這可能與教學模式與教學目標之間的差異有關。
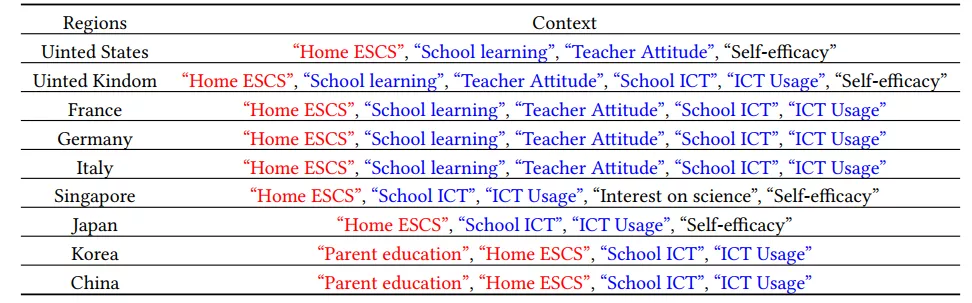
表格 4:不同地區關注的情境信息
隨著智慧教育的興起,認知診斷理論受到廣泛的研究與發展。認知診斷結果能夠為教育情境信息分析提供靈活的衡量指標,然而傳統教育學實證研究的思路由于難以量化、誤差傳遞的缺點,不適應當前的多學科、大數據量的場景。基于端到端的網絡框架,用教育情境信息輔助認知診斷,進而分析教育情境信息作用是一個值得探索的方向。


























