中科大&vivo最新深度估計DepthMaster:泛化能力、細(xì)節(jié)保留超越其他基于擴(kuò)散方法
本文經(jīng)3D視覺之心公眾號授權(quán)轉(zhuǎn)載,轉(zhuǎn)載請聯(lián)系出處。
單目深度估計的瓶頸
單目深度估計(Monocular Depth Estimation, MDE)因其簡單、低成本和易于部署的特點,受到了廣泛關(guān)注。與傳統(tǒng)的深度傳感技術(shù)(如LiDAR或立體視覺)不同,MDE僅需要一張RGB圖像作為輸入,因此在自動駕駛、虛擬現(xiàn)實和圖像合成等多個應(yīng)用領(lǐng)域中具有很高的吸引力。然而,這也帶來了一個顯著的挑戰(zhàn):如何在廣泛的應(yīng)用場景中實現(xiàn)卓越的泛化能力,以有效應(yīng)對場景布局、深度分布、光照條件等因素的多樣性和復(fù)雜性。這項任務(wù)并非易事,因為不同的場景和條件往往帶來非常大的變化。
近年來,零-shot單目深度估計主要發(fā)展為兩大類方法:基于數(shù)據(jù)的方法和基于模型的方法。基于數(shù)據(jù)的方法:依賴于大量的圖像-深度對,通過訓(xùn)練得到圖像與深度之間的映射。然而,這一過程非常耗時且需要巨大的計算資源。與之相對,基于模型的方法則通過利用預(yù)訓(xùn)練的骨干網(wǎng)絡(luò),尤其是在穩(wěn)定擴(kuò)散模型(Stable Diffusion)上下文中,展現(xiàn)了較為高效的性能。例如,Marigold通過將深度估計重構(gòu)為擴(kuò)散去噪過程,在泛化和細(xì)節(jié)保留方面取得了令人印象深刻的成果。然而,迭代去噪過程導(dǎo)致了較低的推理速度。
盡管擴(kuò)散模型在單目深度估計中的應(yīng)用取得了顯著的進(jìn)展,但很少有研究深入探討如何最有效地將生成特征適應(yīng)于判別性任務(wù)。因此,本文將重點分析擴(kuò)散模型中的特征表示,特別是在如何優(yōu)化去噪網(wǎng)絡(luò)的特征表示能力上。通常,擴(kuò)散模型由圖像到潛在空間的編碼解碼器和去噪網(wǎng)絡(luò)組成。前者將圖像壓縮到潛在空間并重建,而后者則負(fù)責(zé)對場景進(jìn)行感知與推理。通過實驗發(fā)現(xiàn),主要的瓶頸在于去噪網(wǎng)絡(luò)的特征表示能力。事實上,用于預(yù)訓(xùn)練去噪網(wǎng)絡(luò)的重建任務(wù)使得模型過于關(guān)注紋理細(xì)節(jié),導(dǎo)致深度預(yù)測中的紋理不真實。因此,如何增強(qiáng)去噪網(wǎng)絡(luò)的特征表示能力并減少對無關(guān)細(xì)節(jié)的依賴,是將擴(kuò)散模型應(yīng)用于深度估計任務(wù)的關(guān)鍵問題。

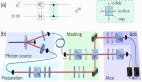
DepthMaster【1】是一個定制的單步擴(kuò)散模型,旨在提升深度估計模型的泛化能力和細(xì)節(jié)保留能力。
- 首先,我們引入了特征對齊模塊(Feature Alignment),通過高質(zhì)量的外部視覺表示來提升去噪網(wǎng)絡(luò)的特征表示能力,并減少對紋理細(xì)節(jié)的過擬合。
- 其次,為了解決單步框架中缺乏細(xì)粒度細(xì)節(jié)的問題,我們提出了傅里葉增強(qiáng)模塊(Fourier Enhancement),在頻域內(nèi)自適應(yīng)平衡低頻結(jié)構(gòu)特征和高頻細(xì)節(jié)特征,從而有效模擬擴(kuò)散模型中多步去噪過程的學(xué)習(xí)。
通過這些優(yōu)化,我們的方法在多種數(shù)據(jù)集上超越了其他基于擴(kuò)散的深度估計方法,取得了最新的性能。
主要貢獻(xiàn):
- 提出了DepthMaster,一種定制生成特征的創(chuàng)新方法,旨在將擴(kuò)散模型適應(yīng)于判別性深度估計任務(wù)。
- 引入了特征對齊模塊,以高質(zhì)量的外部特征緩解對紋理細(xì)節(jié)的過擬合,并提出了傅里葉增強(qiáng)模塊,以在頻域內(nèi)細(xì)化細(xì)粒度細(xì)節(jié)。
- 方法展現(xiàn)了最新的零樣本性能和卓越的細(xì)節(jié)保留能力,超越了其他基于擴(kuò)散的算法,并在多個數(shù)據(jù)集上表現(xiàn)出色。
項目鏈接:https://indu1ge.github.io/DepthMaster_page/
具體方法

確定性范式

特征對齊模塊
穩(wěn)定擴(kuò)散v2由兩個主要組件組成:I2L編碼器-解碼器和去噪U-Net。I2L編碼器-解碼器負(fù)責(zé)特征壓縮,旨在減少推理時間和訓(xùn)練成本。通過圖像重建訓(xùn)練,它主要捕捉低層特征。與此不同,U-Net負(fù)責(zé)從噪聲圖像中恢復(fù)圖像,從而使其具備場景感知與推理能力。然而,由于U-Net是通過重建任務(wù)進(jìn)行訓(xùn)練的,它往往過度強(qiáng)調(diào)細(xì)節(jié)紋理,從而導(dǎo)致深度預(yù)測中的偽紋理問題(如圖1所示)。因此,我們引入語義正則化來增強(qiáng)U-Net的場景表示能力,并防止過度擬合低級的顏色信息。

傅里葉增強(qiáng)模塊
單步范式通過避免多步迭代過程和多次運行集成,有效地加速了推理過程。然而,擴(kuò)散模型輸出的細(xì)粒度特征通常來自于迭代細(xì)化過程。因此,單步模型在處理時會出現(xiàn)模糊的預(yù)測(如圖1所示)。為了緩解這一問題,我們提出了傅里葉增強(qiáng)模塊,在頻域中進(jìn)行操作,以增強(qiáng)高頻細(xì)節(jié),從而有效模擬多步去噪過程中的學(xué)習(xí)。

加權(quán)多方向梯度損失

兩階段訓(xùn)練策略
由于I2L編碼器-解碼器的深度重建精度已經(jīng)足夠高,我們將重點微調(diào)U-Net。實驗表明,潛在空間的監(jiān)督有助于模型更好地捕捉全局場景結(jié)構(gòu),而像素級的監(jiān)督則有助于捕捉細(xì)粒度的細(xì)節(jié),但也會引入全局結(jié)構(gòu)的失真。基于這些觀察,我們提出了一個兩階段的訓(xùn)練策略。

實驗效果







總結(jié)一下
DepthMaster是用于定制擴(kuò)散模型以適應(yīng)深度估計任務(wù)。通過引入特征對齊模塊,有效地緩解了對紋理細(xì)節(jié)的過擬合問題。此外,通過傅里葉增強(qiáng)模塊在頻域中操作,顯著增強(qiáng)了細(xì)粒度細(xì)節(jié)的保留能力。得益于這些精心設(shè)計,DepthMaster在零樣本性能和推理效率方面實現(xiàn)了顯著提升。廣泛的實驗驗證了我們方法的有效性,在泛化能力和細(xì)節(jié)保留方面達(dá)到了最新的水平,超越了其他基于擴(kuò)散模型的方法,并在各種數(shù)據(jù)集上表現(xiàn)優(yōu)異。