













視覺Transformer BERT預(yù)訓(xùn)練新方式:中科大、MSRA等提出PeCo
基于大型語料庫訓(xùn)練的 Transformer 模型在自然語言處理中取得了巨大的成功,作為 Transformer 構(gòu)建塊,self-attention 極大地改變了計(jì)算機(jī)視覺任務(wù)。NLP 的成功不僅依賴于 Transformer 的計(jì)算效率和可擴(kuò)展性,還依賴于對大量文本進(jìn)行自監(jiān)督學(xué)習(xí)。目前 NLP 領(lǐng)域存在兩種主流的學(xué)習(xí)范式:基于自回歸語言建模的 GPT 和基于掩碼語言建模的 BERT,這兩者在計(jì)算機(jī)視覺領(lǐng)域中也被重新設(shè)計(jì),以便充分利用海量的網(wǎng)絡(luò)圖像。
然而,在視覺任務(wù)上設(shè)計(jì)具有相似風(fēng)格的目標(biāo)是具有挑戰(zhàn)性的,因?yàn)閳D像作為一種高維和冗余的模態(tài),在兩個(gè)方面與文本不同:首先,文本由離散字符組成,而圖像在顏色空間中呈現(xiàn)連續(xù)值;其次,文本中的離散 token 包含高級語義含義,而離散化的圖像在像素級和 patch 級包含大量冗余 token。
因此,我們不禁會(huì)問是否有一種方法可以學(xué)習(xí)感知離散視覺 token,這將有助于圖像預(yù)訓(xùn)練。
基于上述觀察,來自中國科學(xué)技術(shù)大學(xué)、微軟亞研等機(jī)構(gòu)的研究者提出了學(xué)習(xí)感知 codebook( perceptual codebook ,PeCo),用于視覺 transformer 的 BERT 預(yù)訓(xùn)練。目前,BEiT 成功地將 BERT 預(yù)訓(xùn)練從 NLP 領(lǐng)域遷移到了視覺領(lǐng)域。BEiT 模型直接采用簡單的離散 VAE 作為視覺 tokenizer,但沒有考慮視覺 token 語義層面。相比之下,NLP 領(lǐng)域中的離散 token 是高度語義化的。這種差異促使研究者開始學(xué)習(xí)感知 codebook,他們發(fā)現(xiàn)了一個(gè)簡單而有效的方法,即在 dVAE 訓(xùn)練期間強(qiáng)制執(zhí)行感知相似性。
該研究證明 PeCo 生成的視覺 token 能夠表現(xiàn)出更好的語義,幫助預(yù)訓(xùn)練模型在各種下游任務(wù)中實(shí)現(xiàn)較好的遷移性能。例如,該研究使用 ViT-B 主干在 ImageNet-1K 上實(shí)現(xiàn)了 84.5% 的 Top-1 準(zhǔn)確率,在相同的預(yù)訓(xùn)練 epoch 下比 BEiT 高 1.3。此外,該方法還可以將 COCO val 上的目標(biāo)檢測和分割任務(wù)性能分別提高 +1.3 box AP 和 +1.0 mask AP,并且將 ADE20k 上的語義分割任務(wù)提高 +1.0 mIoU。

論文地址:https://arxiv.org/pdf/2111.12710v1.pdf
方法
在自然語言中,詞是包含高級語義信息的離散 token。相比之下,視覺信號是連續(xù)的,具有冗余的低級信息。在本節(jié)中,該研究首先簡要描述了 VQ-VAE 的離散表示學(xué)習(xí),然后介紹如何學(xué)習(xí)感知 codebook 的過程,最后對學(xué)習(xí)感知視覺 token 進(jìn)行 BERT 預(yù)訓(xùn)練。
學(xué)習(xí)用于可視化內(nèi)容的離散 Codebook
該研究利用 VQ-VAE 將連續(xù)圖像內(nèi)容轉(zhuǎn)換為離散 token 形式。圖像表示為 x∈ R^H×W×3,VQ-VAE 用離散視覺 Codebook 來表示圖像,即
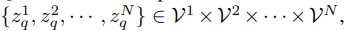
其中,VQ-VAE 包含三個(gè)主要部分:編碼器、量化器和解碼器。編碼器負(fù)責(zé)將輸入圖像映射到中間潛在向量 z = Enc(x);量化器根據(jù)最近鄰分配原則負(fù)責(zé)將位置 (i, j) 處的向量量化為來自 Codebook 對應(yīng)的碼字(codewords):
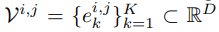
然后得到如下公式:

其中 q 是量化編碼器,可以將向量映射到 codebook 索引,r 是量化解碼器,可以從索引重構(gòu)向量。基于量化的碼字為 z_q,解碼器旨在重構(gòu)輸入圖像 x。VQ-VAE 的訓(xùn)練目標(biāo)定義為:
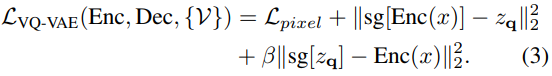
學(xué)習(xí)用于視覺內(nèi)容的 PeCo
該研究提出,在不包含像素?fù)p失的情況下,對模型強(qiáng)制執(zhí)行原始圖像和重構(gòu)圖像之間的感知相似性。感知相似性不是基于像素之間的差異得到的,而是基于從預(yù)訓(xùn)練深度神經(jīng)網(wǎng)絡(luò)中提取的高級圖像特征表示之間的差異而得到。該研究希望這種基于 feature-wise 的損失能夠更好地捕捉感知差異并提供對低級變化的不變性。下圖從圖像重構(gòu)的角度展示了模型使用不同損失的比較,結(jié)果表明圖像在較低的 pixel-wise 損失下可能不會(huì)出現(xiàn)感知相似:

圖 1. 不同損失下的圖像重構(gòu)比較。每個(gè)示例包含三個(gè)圖像,輸入(左)、使用 pixel-wise 損失重構(gòu)圖像(中)、使用 pixel-wise 損失和 feature-wise 損失重構(gòu)圖像(右)。與中間圖像相比,右側(cè)圖像在感知上與輸入更相似。
在形式上,假設(shè)輸入圖像 x 和重構(gòu)圖像
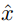
的感知度量可以表示為:
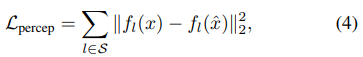
其中 S 表示提取特征的層數(shù),總的目標(biāo)函數(shù)為:
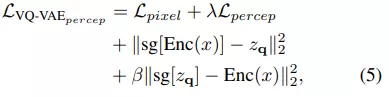
BERT objective 執(zhí)行掩碼圖像建模
該研究采用 BERT objective 在離散視覺 token 上執(zhí)行掩碼圖像建模任務(wù),如 BEiT。對于給定的圖像 x,輸入 token 為不重疊的圖像 patch,輸出 token 是通過學(xué)習(xí)方程 (5) 獲得的離散感知視覺單詞。設(shè)輸入為 {x_1 , x_2 , · · · , x_N },并且真值輸出為
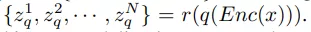
。 掩碼圖像建模的目標(biāo)是從掩碼輸入中恢復(fù)相應(yīng)的視覺 token,其中一部分輸入 token 已被掩碼掉。準(zhǔn)確地說,令 M 為掩碼索引集合,掩碼輸入
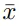
表示為:
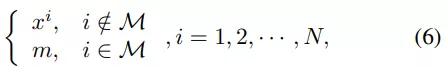
其中,m 是與非掩碼 token 相同維度的可學(xué)習(xí)掩碼 token。掩碼(masked)輸入 token 被送入 L 層視覺 Transformer,最后一層的隱藏輸出表示為 {h^1 , h^2 , · · · , h^N }。
實(shí)驗(yàn)
該研究將預(yù)訓(xùn)練模型應(yīng)用于各種下游任務(wù),包括 ImageNet-1K 分類、COCO 目標(biāo)檢測和 ADE20k 分割。
與 SOTA 模型比較
首先該研究將 PeCo 與 SOTA 研究進(jìn)行比較。研究者使用 ViT-B 作為主干并在 ImageNet-1K 上進(jìn)行預(yù)訓(xùn)練,epoch 為 300 。
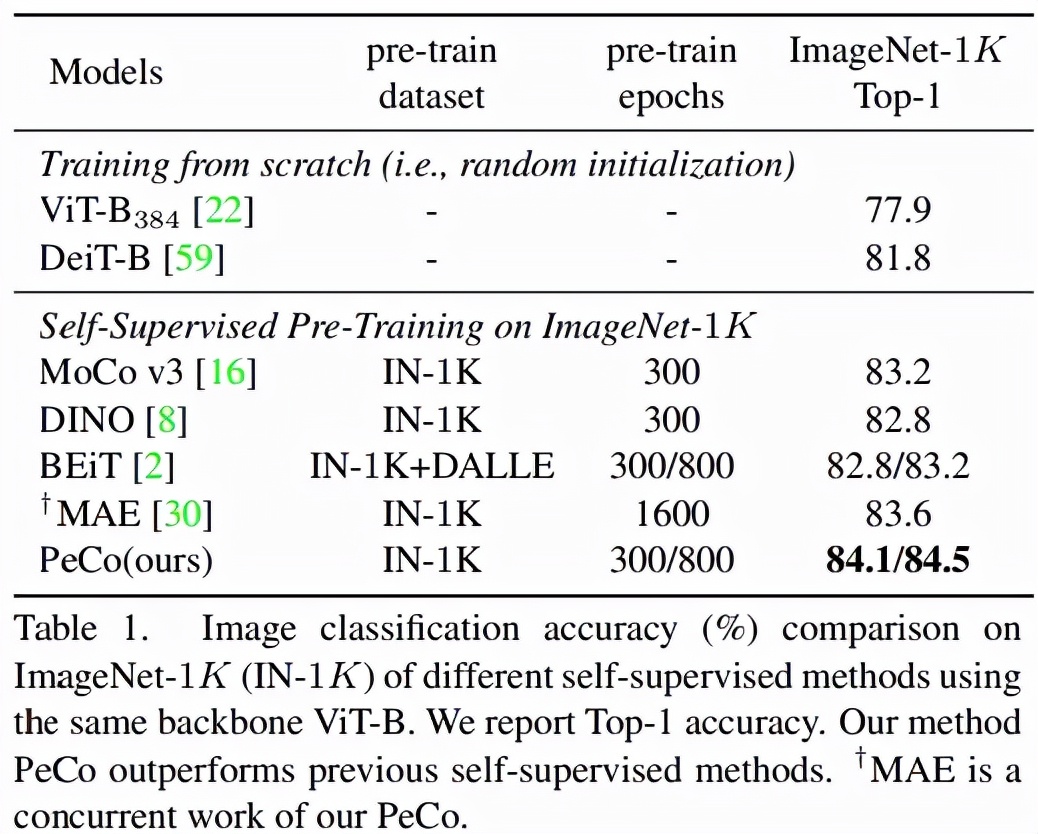
圖像分類任務(wù):在 ImageNet 1K 上進(jìn)行分類任務(wù)的 Top-1 準(zhǔn)確率如表 1 所示。可以看出,與從頭開始訓(xùn)練的模型相比,PeCo 顯著提高了性能,這表明預(yù)訓(xùn)練的有效性。更重要的是,與之前自監(jiān)督預(yù)訓(xùn)練模型相比,PeCo 模型實(shí)現(xiàn)了最佳性能。值得一提的是,與采用 800 epoch 的 BEiT 預(yù)訓(xùn)練相比,PeCo 僅用 300 epoch 就實(shí)現(xiàn)了 0.9% 的提高,并比 MAE 采用 1600 epoch 預(yù)訓(xùn)練性能提高 0.5%。這驗(yàn)證了 PeCo 確實(shí)有利于預(yù)訓(xùn)練。
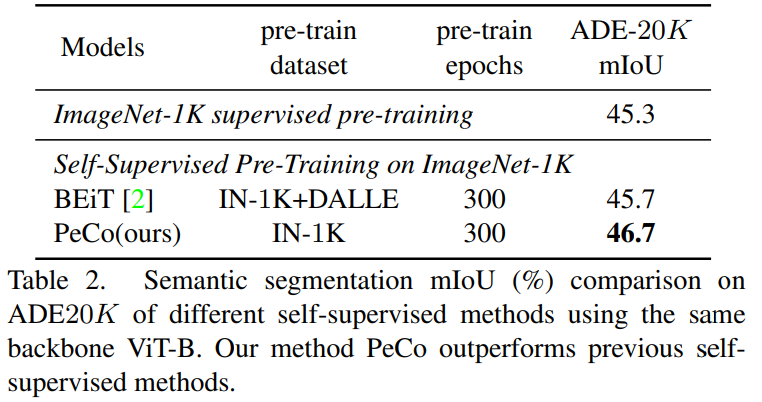
語義分割任務(wù):該研究將 PeCo 與 1)在 ImageNet-1K 上進(jìn)行監(jiān)督預(yù)訓(xùn)練和 2)BEiT(SOTA 性能自監(jiān)督學(xué)習(xí)模型)進(jìn)行比較,評估指標(biāo)是 mIoU,結(jié)果如表 2 所示。由結(jié)果可得,PeCo 在預(yù)訓(xùn)練期間不涉及任何標(biāo)簽信息,卻取得了比監(jiān)督預(yù)訓(xùn)練更好的性能。此外,與自監(jiān)督 BEiT 相比,PeCo 模型也獲得了較好的性能,這進(jìn)一步驗(yàn)證了 PeCo 的有效性。
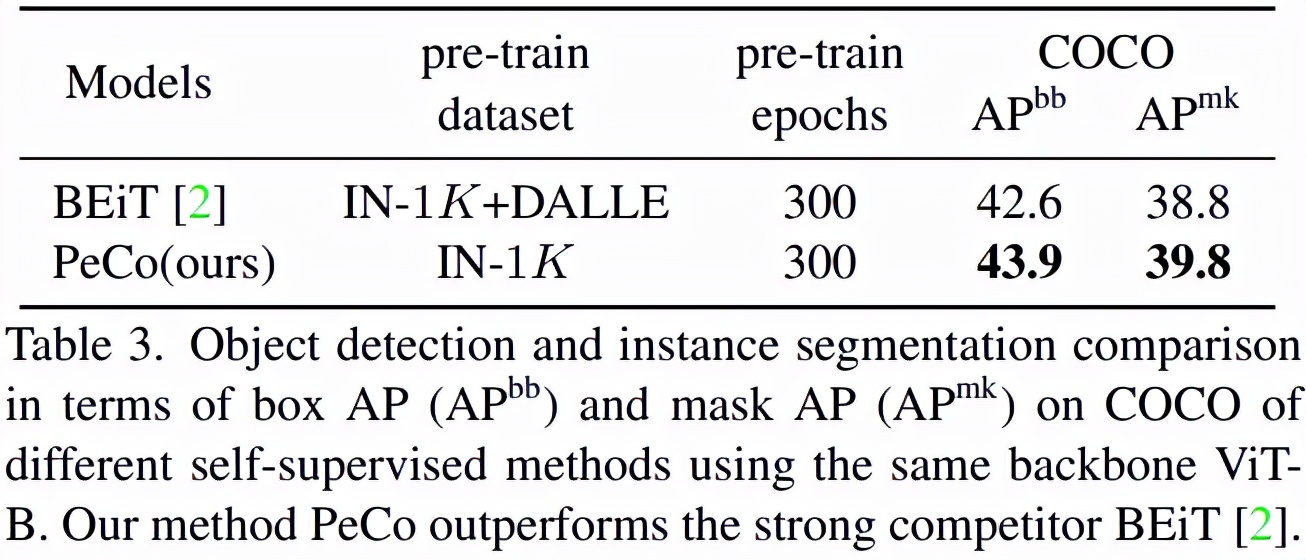
目標(biāo)檢測與分割:如表 3 所示,在這一任務(wù)上,PeCo 獲得了最好的性能:
感知 Codebook 分析
碼字語義:學(xué)習(xí)的感知碼字是否具有(更多)語義含義?為了回答這個(gè)問題,該研究設(shè)計(jì)實(shí)驗(yàn)以提供視覺和定量結(jié)果。
首先,該研究將對應(yīng)于相同碼字的圖像 patch 進(jìn)行可視化,并與兩個(gè)基線進(jìn)行比較:在 2.5 億私有數(shù)據(jù)上訓(xùn)練而成的 DALL-E codebook;不使用感知相似性的 PeCo 模型的一個(gè)變體。結(jié)果如圖 3 所示,我們可以看到該研究碼字與語義高度相關(guān),如圖中所示的輪子,來自基線的碼字通常與低級信息(如紋理、顏色、邊緣)相關(guān)。

此外,該研究還與不使用感知相似性的變體進(jìn)行了比較。如表 4 所示, 我們可以發(fā)現(xiàn)感知碼字在線性評估和重構(gòu)圖像分類方面獲得了更高的準(zhǔn)確率。這表明感知 codebook 具有更多的語義意義,有利于圖像重構(gòu)過程。

下圖為使用 BEiT 和 PeCo 在 ImageNet-1k 上重構(gòu)任務(wù)的示例。對于每個(gè)樣本,第一張是原始圖像,第二張是對應(yīng)的掩碼圖像,第三張是 BEiT 重構(gòu)圖像,最后一張是從感知 codebook(PeCo)重構(gòu)的圖像。PeCo 在感知 codebook 的幫助下,能夠?qū)ρ诖a區(qū)域進(jìn)行更語義化的預(yù)測。




























