字節(jié)博士搞的AI火了,一鍵完美分離人聲和伴奏
本文經(jīng)AI新媒體量子位(公眾號ID:QbitAI)授權(quán)轉(zhuǎn)載,轉(zhuǎn)載請聯(lián)系出處。
寫歌填詞、改換風(fēng)格、續(xù)寫音樂的AI,今天又來做編曲人了!
上傳一段《Stay》,一鍵按下:
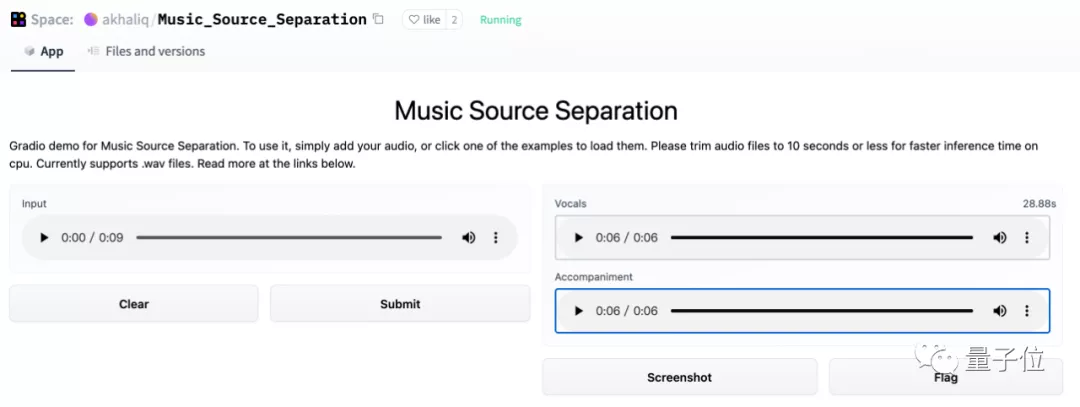
伴奏和人聲就輕松分離:
https://mp.weixin.qq.com/s?__biz=MzIzNjc1NzUzMw==&mid=2247594465&idx=3&sn=83a18be3019dbecd6040031618d112dc&chksm=e8d1c693dfa64f85e7db0f5157d533361da6c8b71a9ceacdfc29a28399bd6d0bade7a046014f&token=497180065&lang=zh_CN#rd
人聲頗有種在空曠地帶清唱的清晰感,背景樂都能直接拿去做混剪了!
這樣驚人的效果也引發(fā)了Reddit熱議:

這項研究的主要負責(zé)人孔秋強來自字節(jié)跳動,全球最大的古典鋼琴數(shù)據(jù)集GiantMIDI-Piano,也是由他在去年牽頭發(fā)布的。
那么今天,他又帶來了怎樣的一個AI音樂家呢?
一起來看看。
基于深度殘差網(wǎng)絡(luò)的音源分離
這是一個包含了相位估計的音樂源分離(MSS)系統(tǒng)。
首先,將幅值(Magnitude)與相位(Phase)解耦,用以估計復(fù)數(shù)理想比例掩碼(cIRM)。
其次,為了實現(xiàn)更靈活的幅值估計,將有界掩碼估計和直接幅值預(yù)測結(jié)合起來。
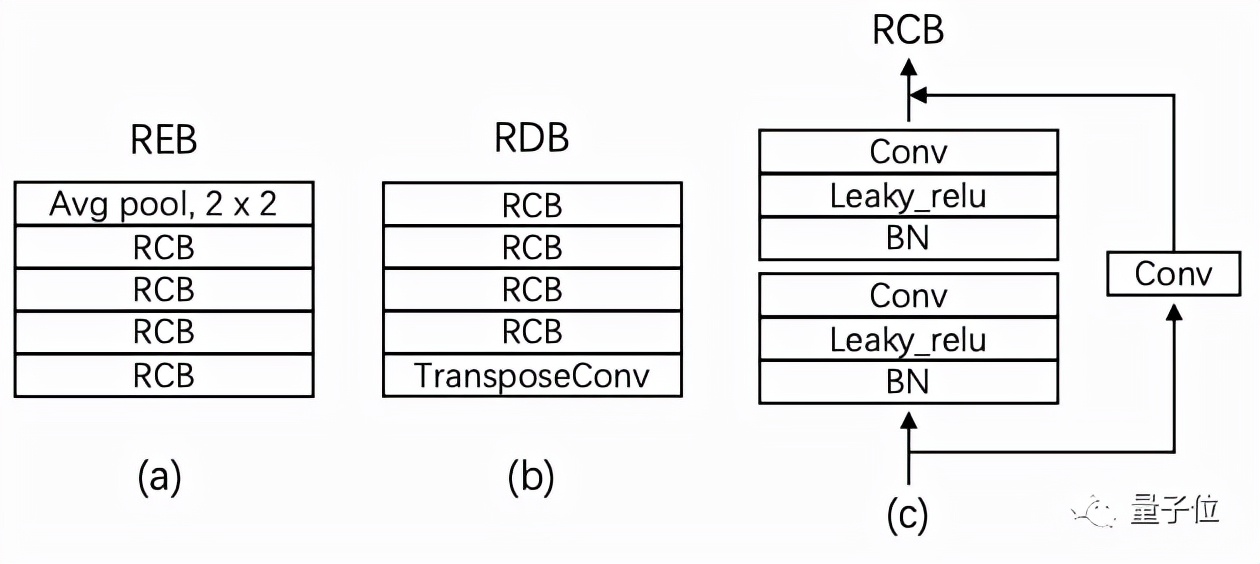
最后,為MSS系統(tǒng)引入一個143層的深度殘差網(wǎng)絡(luò)(Deep Residual UNets),利用殘差編碼塊(REB)和殘差解碼塊(RDB)來增加其深度:
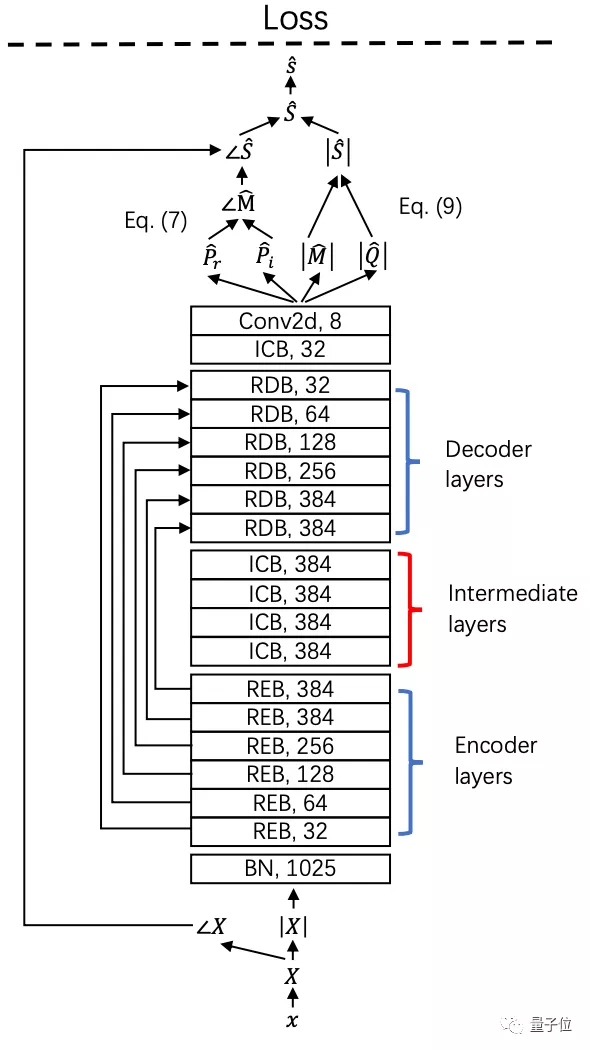
殘差編碼塊和殘差卷積塊中間還引入了中間卷積塊(ICB),以提高殘差網(wǎng)絡(luò)的表達能力。
其中每個殘差編碼塊由4個殘差卷積塊(RCB)組成,殘差卷積塊又由兩個核大小為3×3的卷積層組成。
每個殘差解碼塊由8個卷積層和1個反卷積層組成。
實驗結(jié)果
接下來,將這一系統(tǒng)在MUSDB18數(shù)據(jù)集上進行實驗。
MUSDB18中的訓(xùn)練/驗證集分別包含100/50個完整的立體聲音軌,包括獨立的人聲、伴奏、低音、鼓和其他樂器。
在訓(xùn)練時,利用上述系統(tǒng)進行并行的混合音頻數(shù)據(jù)增強,隨機混合來自同一來源的兩個3秒片段,然后作為一個新的3秒片段進行訓(xùn)練。
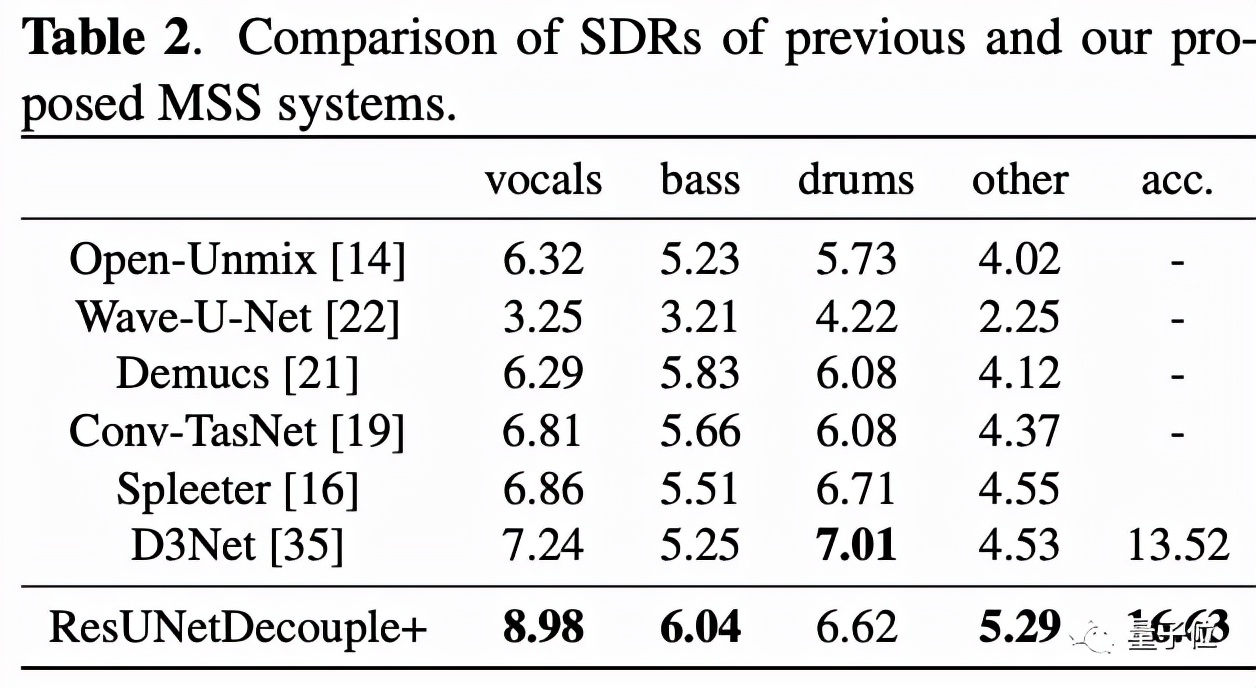
以信號失真率(SDR)作為評判標準,可以看到ResUNetDecouple系統(tǒng)在分離人聲、低音、其他和伴奏方面明顯優(yōu)于以前的方法:
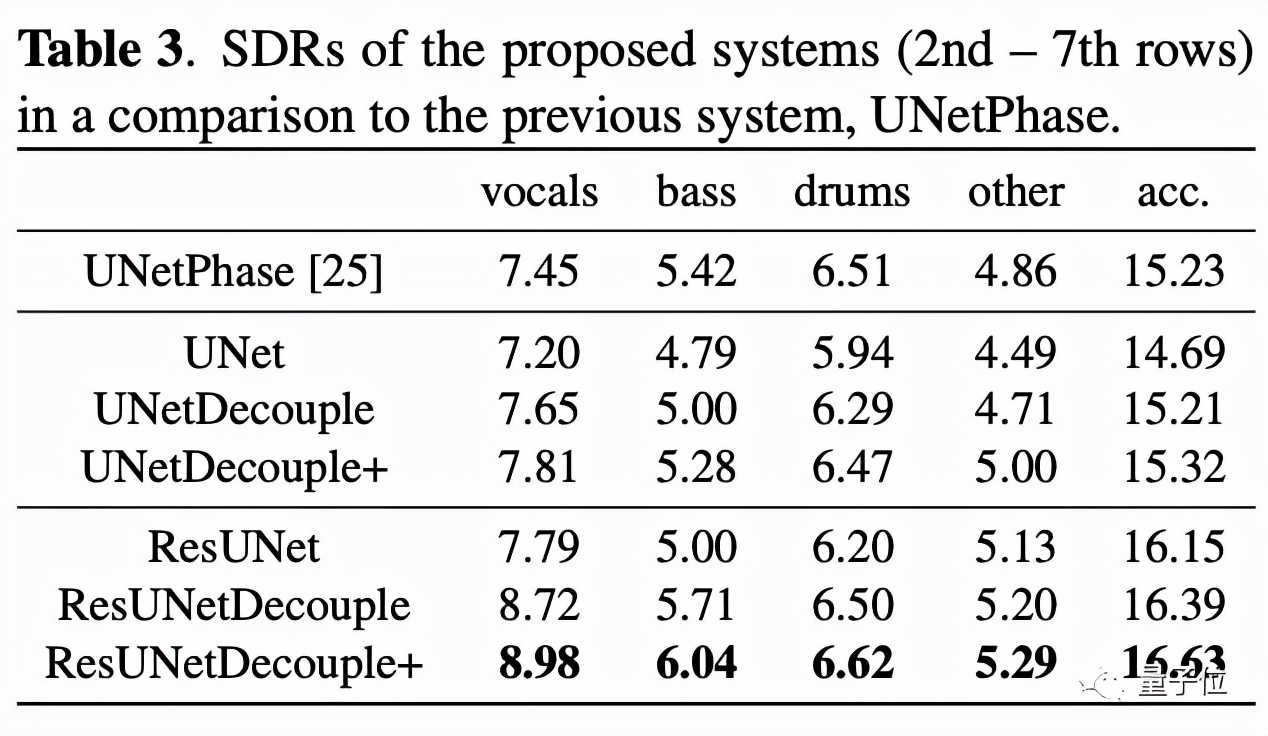
在消融實驗中,143層殘差網(wǎng)絡(luò)的表現(xiàn)也證實了,結(jié)合有界掩碼估計和直接幅值預(yù)測確實能夠改善聲音源分離系統(tǒng)的性能。
作者介紹
這項研究的論文一作為孔秋強,本碩都畢業(yè)于華南理工大學(xué),博士則畢業(yè)于英國薩里大學(xué)的電子信息工程專業(yè)。
他在2019年加入字節(jié)跳動的Speech, Audio and Music Intelligence研究小組,主要負責(zé)音頻信號處理和聲音事件檢測等領(lǐng)域的研究。
論文:
https://arxiv.org/abs/2109.05418
試玩:
https://huggingface.co/spaces/akhaliq/Music_Source_Separation
開源地址:
https://github.com/bytedance/music_source_separation
參考鏈接:
https://www.reddit.com/r/MachineLearning/comments/pqpl7m/r_decoupling_magnitude_and_phase_estimation_with/