視頻一鍵拆分PS層!DeepMind新模型效果碾壓同級(jí),物體、背景完美分離,還能腦補(bǔ)
視頻數(shù)據(jù)中通常會(huì)包含動(dòng)態(tài)世界中的復(fù)雜信號(hào),比如相機(jī)運(yùn)動(dòng)、關(guān)節(jié)移動(dòng)、復(fù)雜的場(chǎng)景效果以及物體之間的交互。
如果能自動(dòng)化地把視頻分解成一組語(yǔ)義上有意義的、半透明的層,分離前景對(duì)象和背景的話,類(lèi)似PS中的圖片,就可以極大提升視頻的編輯效率和直觀性。
現(xiàn)有方法在推斷對(duì)象及其效果之間復(fù)雜的時(shí)空相關(guān)性時(shí),只能處理靜態(tài)背景或帶有精確相機(jī)和深度估計(jì)數(shù)據(jù)的視頻,并且無(wú)法補(bǔ)全被遮擋區(qū)域,極大限制了可應(yīng)用范圍。

最近,Google DeepMind、馬里蘭大學(xué)帕克分校和魏茨曼科學(xué)研究所的研究人員共同提出了一個(gè)全新的分層視頻分解框架,無(wú)需假設(shè)背景是靜態(tài)的,也不需要相機(jī)姿態(tài)或深度信息,就能生成清晰、完整的圖像層,甚至還能對(duì)被遮擋動(dòng)態(tài)區(qū)域進(jìn)行補(bǔ)全。

論文鏈接:https://arxiv.org/pdf/2411.16683
項(xiàng)目地址:https://gen-omnimatte.github.io/
該框架的其核心思想是訓(xùn)練一個(gè)視頻擴(kuò)散模型,利用其強(qiáng)大生成式先驗(yàn)知識(shí)來(lái)克服之前方法的限制。

1. 模型的內(nèi)部特征可以揭示物體與視頻效果之間的聯(lián)系,類(lèi)似于把視頻擴(kuò)散模型的內(nèi)部特征應(yīng)用于分析任務(wù);

2. 模型可以直接利用先驗(yàn)補(bǔ)全層分解中的被遮擋區(qū)域,包括動(dòng)態(tài)區(qū)域,而之前方法在先驗(yàn)信息有限的情況下無(wú)法實(shí)現(xiàn)。
在實(shí)驗(yàn)階段,研究人員驗(yàn)證了,只需要一個(gè)小型、精心策劃的數(shù)據(jù)集,就能夠處理包含軟陰影、光澤反射、飛濺的水等多種元素的日常拍攝視頻,最終輸出高質(zhì)量的分解和編輯結(jié)果。

最牛「視頻分層」模型
由于真實(shí)的分層視頻數(shù)據(jù)很少,并且預(yù)訓(xùn)練模型已經(jīng)在生成任務(wù)中學(xué)習(xí)到了物體及其效果之間的關(guān)聯(lián),所以希望通過(guò)微調(diào)模型來(lái)發(fā)揮這種能力,使用小型的分層視頻數(shù)據(jù)集進(jìn)行微調(diào)。
基礎(chǔ)視頻擴(kuò)散模型
研究人員基于文本到視頻的生成器Lumiere,開(kāi)發(fā)出了一個(gè)可用于移除物體及其效果的模型Casper
基礎(chǔ)模型Lumiere先從文本提示生成一個(gè)80幀、分辨率為128×128像素的視頻,再利用空間超分辨率(SSR)模型將基礎(chǔ)模型的輸出上采樣到1024×1024像素的分辨率。
Lumiere inpainting模型對(duì)原模型進(jìn)行微調(diào),輸入條件為「遮罩的RGB視頻」和「二進(jìn)制掩碼視頻」,然后使用相同的SSR,以實(shí)現(xiàn)高分辨率質(zhì)量。
Casper基于inpainting模型進(jìn)行微調(diào),對(duì)物體及視頻效果進(jìn)行移除,保持相同的模型架構(gòu)。
使用三元掩碼進(jìn)行物體和效果移除
原始的Lumiere inpainting模型需要輸入一個(gè)二元掩碼來(lái)指示需要修復(fù)(inpaint)的區(qū)域和需要保留的區(qū)域。
Casper還引入了額外的不確定性,即所謂的「保留」區(qū)域并不完全保留,也可能為了擦除陰影而修改目標(biāo)區(qū)域。
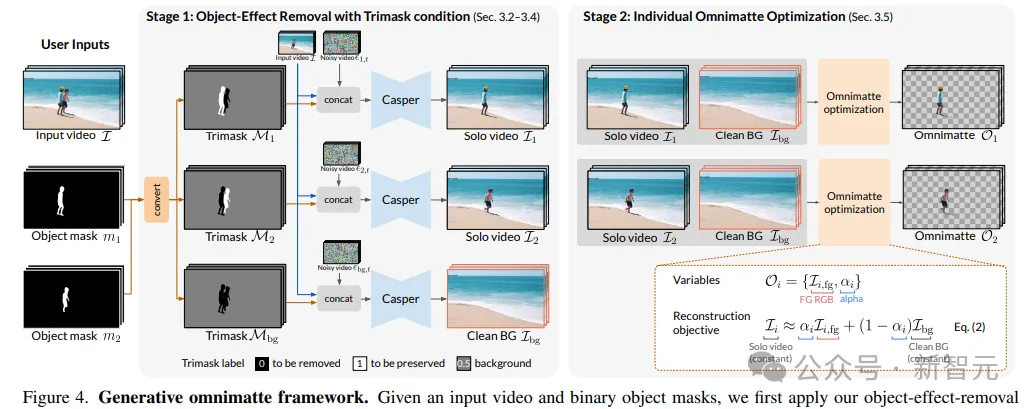
研究人員提出了三元掩碼(Trimask)條件M,區(qū)分出需要移除的對(duì)象(M=0)、需要保留的對(duì)象(M=1)以及可能包含需要移除或保留效果的背景區(qū)域(M=0.5)。
為了獲得干凈的背景視頻,再使用一個(gè)背景三元掩碼,將所有物體都標(biāo)記為需要移除的區(qū)域,背景標(biāo)記為可能需要修改的區(qū)域。
使用SegmentAnything2獲得二進(jìn)制對(duì)象掩碼,然后將單個(gè)物體作為保留區(qū)域,其余物體標(biāo)記為移除區(qū)域。
在推理過(guò)程中,Casper的輸入包括描述目標(biāo)移除場(chǎng)景的文本提示、輸入視頻、三元掩碼和128px分辨率的噪聲視頻的拼接。
模型在沒(méi)有分類(lèi)器自由引導(dǎo)的情況下進(jìn)行256個(gè)DDPM采樣步驟進(jìn)行推理(一個(gè)80幀的視頻大約需要12分鐘),采用時(shí)間多擴(kuò)散技術(shù)來(lái)處理更長(zhǎng)的視頻。
視頻生成器中的效果關(guān)聯(lián)先驗(yàn)
為了探究Lumiere對(duì)對(duì)象效果關(guān)聯(lián)的內(nèi)在理解,研究人員分析了使用SDEdit在給定視頻去噪過(guò)程中的自注意力模式,測(cè)量了與感興趣對(duì)象相關(guān)的查詢(xún)token和鍵token之間的自注意力權(quán)重。

可以觀察到,陰影區(qū)域的查詢(xún)token對(duì)對(duì)象區(qū)域展現(xiàn)出更高的注意力值,表明預(yù)訓(xùn)練模型能夠有效關(guān)聯(lián)對(duì)象及其效果。

訓(xùn)練數(shù)據(jù)構(gòu)造
研究人員從四個(gè)類(lèi)別中構(gòu)造了一個(gè)包含真實(shí)和合成視頻示例的訓(xùn)練數(shù)據(jù)集。

Omnimatte,從現(xiàn)有方法的結(jié)果中收集了31個(gè)場(chǎng)景,形成輸入視頻、輸入三元掩碼和目標(biāo)背景視頻的訓(xùn)練元組。場(chǎng)景大多來(lái)自DAVIS數(shù)據(jù)集,以靜態(tài)背景和單個(gè)對(duì)象為特色,包含現(xiàn)實(shí)世界視頻中陰影和反射。
Tripod,通過(guò)互聯(lián)網(wǎng)補(bǔ)充了15個(gè)視頻,由固定相機(jī)拍攝,包含進(jìn)出場(chǎng)景的對(duì)象、水效果(例如,反射、飛濺、波紋)和環(huán)境背景運(yùn)動(dòng)。然后通過(guò)Ken Burns效果增強(qiáng)視頻,以模擬相機(jī)運(yùn)動(dòng)。
Kubric,包含569個(gè)合成視頻,在Blender中渲染多對(duì)象場(chǎng)景并使對(duì)象透明。此外,研究人員觀察到許多現(xiàn)實(shí)世界場(chǎng)景在一個(gè)場(chǎng)景中會(huì)展示同一類(lèi)型對(duì)象的多個(gè)實(shí)例,例如狗、行人或車(chē)輛,所以還特意生成了包含重復(fù)對(duì)象的場(chǎng)景,以訓(xùn)練模型處理多個(gè)相似對(duì)象。
對(duì)象粘貼(Object-Paste),從YouTube-VOS數(shù)據(jù)集中的真實(shí)視頻合成了1024個(gè)視頻元組,使用SegmentAnything2從隨機(jī)視頻裁剪對(duì)象,并將其粘貼到目標(biāo)視頻上。訓(xùn)練輸入和目標(biāo)分別是合成的視頻和原始視頻,可以加強(qiáng)模型的修復(fù)和背景保留能力。
訓(xùn)練數(shù)據(jù)的文本提示由BLIP-2描述,描述了對(duì)象效果移除模型應(yīng)該學(xué)會(huì)生成的目標(biāo)視頻;通過(guò)空間水平翻轉(zhuǎn)、時(shí)間翻轉(zhuǎn)和隨機(jī)裁剪到128×128像素分辨率來(lái)增強(qiáng)數(shù)據(jù)集。
實(shí)驗(yàn)結(jié)果
定性分析
在下圖「船」(boat)的例子中,現(xiàn)有的方法無(wú)法將船的尾跡從背景層中分離出來(lái),而文中提出的方法可以正確地將其放置在船的層中。

「馬」的例子中,Omnimatte3D和OmnimatteRF因?yàn)?D感知背景表示對(duì)相機(jī)姿態(tài)估計(jì)的質(zhì)量很敏感,所以背景層很模糊,無(wú)法在最后一行中恢復(fù)出被遮擋的馬。
在物體移除方面,視頻修復(fù)模型無(wú)法移除輸入掩碼外的軟陰影和反射;ObjectDrop可以移除cartoon和parkour中的陰影,但獨(dú)立處理每一幀,并且沒(méi)有全局上下文的情況下修復(fù)區(qū)域,會(huì)導(dǎo)致不一致的幻覺(jué)。

定量分析
研究人員采用OmnimatteRF評(píng)估協(xié)議來(lái)評(píng)估十個(gè)合成場(chǎng)景的背景層重建效果,包括5個(gè)電影場(chǎng)景和5個(gè)由Kubric生成的場(chǎng)景,每個(gè)場(chǎng)景都有一個(gè)對(duì)應(yīng)的真實(shí)背景,不包含前景對(duì)象和效果。
使用峰值信噪比(PSNR)和Learned Perceptual Image Patch Similarity(LPIPS)作為評(píng)估指標(biāo)。

結(jié)果顯示,Omnimatte和Layered Neural Atlas使用2D運(yùn)動(dòng)模型,因此難以處理視差;Omnimatte3D在兩個(gè)案例中未能構(gòu)建背景場(chǎng)景模型,并且在電影場(chǎng)景中的靜止前景對(duì)象處理上存在困難。
總體而言,文中的方法在兩個(gè)指標(biāo)上都取得了最佳性能。