













動圖圖解GC算法-讓垃圾回收動起來!
提到Java中的垃圾回收,我相信很多小伙伴和我一樣,第一反應就是面試必問了,你要是沒背過點GC算法、收集器什么的知識,出門都不敢說自己背過八股文。說起來還真是有點尷尬,工作中實際用到這方面知識的場景真是不多,并且這東西學起來也很枯燥,但是奈何面試官就是愛問,我們能有什么辦法呢?
既然已經卷成了這樣,不學也沒有辦法,Hydra犧牲了周末時間,給大家畫了幾張動圖,希望通過這幾張圖,能夠幫助大家對垃圾收集算法有個更好的理解。廢話不多說,首先還是從基礎問題開始,看看怎么判斷一個對象是否應該被回收。
判斷對象存活
垃圾回收的根本目的是利用一些算法進行內存的管理,從而有效的利用內存空間,在進行垃圾回收前,需要判斷對象的存活情況,在jvm中有兩種判斷對象的存活算法,下面分別進行介紹。
1、引用計數算法
在對象中添加一個引用計數器,每當有一個地方引用它時計數器就加 1,當引用失效時計數器減 1。當計數器為0的時候,表示當前對象可以被回收。
這種方法的原理很簡單,判斷起來也很高效,但是存在兩個問題:
- 堆中對象每一次被引用和引用清除時,都需要進行計數器的加減法操作,會帶來性能損耗
- 當兩個對象相互引用時,計數器永遠不會0。也就是說,即使這兩個對象不再被程序使用,仍然沒有辦法被回收,通過下面的例子看一下循環引用時的計數問題:
- public void reference(){
- A a = new A();
- B b = new B();
- a.instance = b;
- b.instance = a;
- }
引用計數的變化過程如下圖所示:
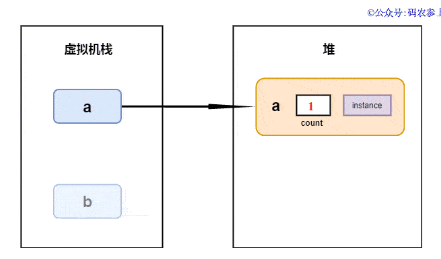
可以看到,在方法執行完成后,棧中的引用被釋放,但是留下了兩個對象在堆內存中循環引用,導致了兩個實例最后的引用計數都不為0,最終這兩個對象的內存將一直得不到釋放,也正是因為這一缺陷,使引用計數算法并沒有被實際應用在gc過程中。
2、可達性分析算法
可達性分析算法是jvm默認使用的尋找垃圾的算法,需要注意的是,雖然說的是尋找垃圾,但實際上可達性分析算法尋找的是仍然存活的對象。至于這樣設計的理由,是因為如果直接尋找沒有被引用的垃圾對象,實現起來相對復雜、耗時也會比較長,反過來標記存活的對象會更加省時。
可達性分析算法的基本思路就是,以一系列被稱為GC Roots的對象作為起始點,從這些節點開始向下搜索,搜索所走過的路徑稱為引用鏈,當一個對象到GC Roots沒有任何引用鏈相連時,證明該對象不再存活,可以作為垃圾被回收。
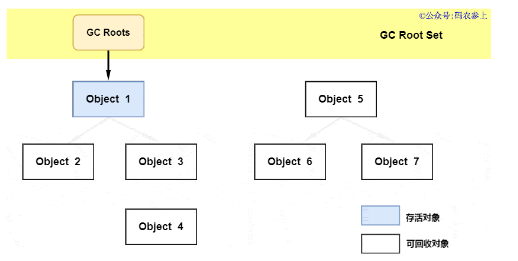
在java中,可作為GC Roots的對象有以下幾種:
- 在虛擬機棧(棧幀的本地變量表)中引用的對象
- 在方法區中靜態屬性引用的對象
- 在方法區中常量引用的對象
- 在本地方法棧中JNI(native方法)引用的對象
- jvm內部的引用,如基本數據類型對應的Class對象、一些常駐異常對象等,及系統類加載器
- 被同步鎖synchronized持有的對象引用
- 反映jvm內部情況的 JMXBean、JVMTI中注冊的回調本地代碼緩存等
- 此外還有一些臨時性的GC Roots,這是因為垃圾收集大多采用分代收集和局部回收,考慮到跨代或跨區域引用的對象時,就需要將這部分關聯的對象也添加到GC Roots中以確保準確性
其中比較重要、同時提到的比較多的還是前面4種,其他的簡單了解一下即可。在了解了jvm是如何尋找垃圾對象之后,我們來看一看不同的垃圾收集算法的執行過程是怎樣的。
垃圾收集算法
1、標記-清除算法
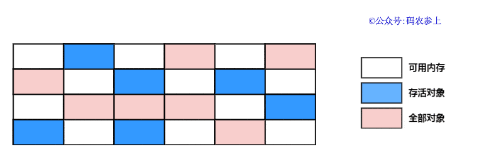
標記清除算法是一種非常基礎的垃圾收集算法,當堆中的有效內存空間耗盡時,會觸發STW(stop the world),然后分標記和清除兩階段來進行垃圾收集工作:
- 標記:從GC Roots的節點開始進行掃描,對所有存活的對象進行標記,將其記錄為可達對象
- 清除:對整個堆內存空間進行掃描,如果發現某個對象未被標記為可達對象,那么將其回收
通過下面的圖,簡單的看一下兩階段的執行過程:
但是這種算法會帶來幾個問題:
- 在進行GC時會產生STW,停止整個應用程序,造成用戶體驗較差
- 標記和清除兩個階段的效率都比較低,標記階段需要從根集合進行掃描,清除階段需要對堆內所有的對象進行遍歷
- 僅對非存活的對象進行處理,清除之后會產生大量不連續的內存碎片。導致之后程序在運行時需要分配較大的對象時,無法找到足夠的連續內存,會再觸發一次新的垃圾收集動作
此外,jvm并不是真正的把垃圾對象進行了遍歷,把內部的數據都刪除了,而是把垃圾對象的首地址和尾地址進行了保存,等到再次分配內存時,直接去地址列表中分配,通過這一措施提高了一些標記清除算法的效率。
2、復制算法
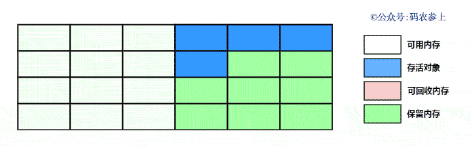
復制算法主要被應用于新生代,它將內存分為大小相同的兩塊,每次只使用其中的一塊。在任意時間點,所有動態分配的對象都只能分配在其中一個內存空間,而另外一個內存空間則是空閑的。復制算法可以分為兩步:
- 當其中一塊內存的有效內存空間耗盡后,jvm會停止應用程序運行,開啟復制算法的gc線程,將還存活的對象復制到另一塊空閑的內存空間。復制后的對象會嚴格按照內存地址依次排列,同時gc線程會更新存活對象的內存引用地址,指向新的內存地址
- 在復制完成后,再把使用過的空間一次性清理掉,這樣就完成了使用的內存空間和空閑內存空間的對調,使每次的內存回收都是對內存空間的一半進行回收
通過下面的圖來看一下復制算法的執行過程:
復制算法的的優點是彌補了標記清除算法中,會出現內存碎片的缺點,但是它也同樣存在一些問題:
只使用了一半的內存,所以內存的利用率較低,造成了浪費
如果對象的存活率很高,那么需要將很多對象復制一遍,并且更新它們的應用地址,這一過程花費的時間會非常的長
從上面的缺點可以看出,如果需要使用復制算法,那么有一個前提就是要求對象的存活率要比較低才可以,因此,復制算法更多的被用于對象“朝生暮死”發生更多的新生代中。
3、標記-整理算法
標記整理算法和標記清除算法非常的類似,主要被應用于老年代中。可分為以下兩步:
標記:和標記清除算法一樣,先進行對象的標記,通過GC Roots節點掃描存活對象進行標記
整理:將所有存活對象往一端空閑空間移動,按照內存地址依次排序,并更新對應引用的指針,然后清理末端內存地址以外的全部內存空間
標記整理算法的執行過程如下圖所示:
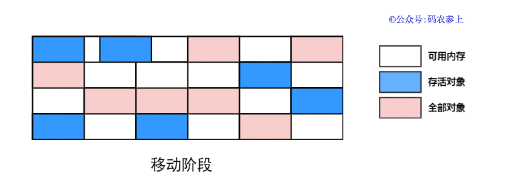
可以看到,標記整理算法對前面的兩種算法進行了改進,一定程度上彌補了它們的缺點:
- 相對于標記清除算法,彌補了出現內存空間碎片的缺點
- 相對于復制算法,彌補了浪費一半內存空間的缺點
但是同樣,標記整理算法也有它的缺點,一方面它要標記所有存活對象,另一方面還添加了對象的移動操作以及更新引用地址的操作,因此標記整理算法具有更高的使用成本。
4、分代收集算法
實際上,java中的垃圾回收器并不是只使用的一種垃圾收集算法,當前大多采用的都是分代收集算法。jvm一般根據對象存活周期的不同,將內存分為幾塊,一般是把堆內存分為新生代和老年代,再根據各個年代的特點選擇最佳的垃圾收集算法。主要思想如下:
新生代中,每次收集都會有大量對象死去,所以可以選擇復制算法,只需要復制少量對象以及更改引用,就可以完成垃圾收集
老年代中,對象存活率比較高,使用復制算法不能很好的提高性能和效率。另外,沒有額外的空間對它進行分配擔保,因此選擇標記清除或標記整理算法進行垃圾收集
通過圖來簡單看一下各種算法的主要應用區域:
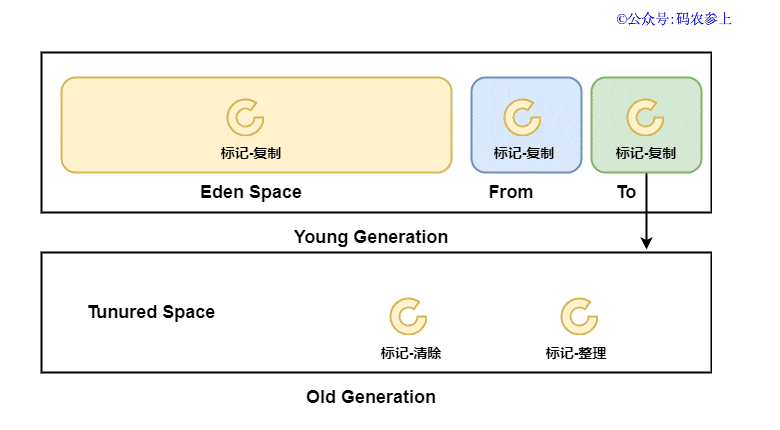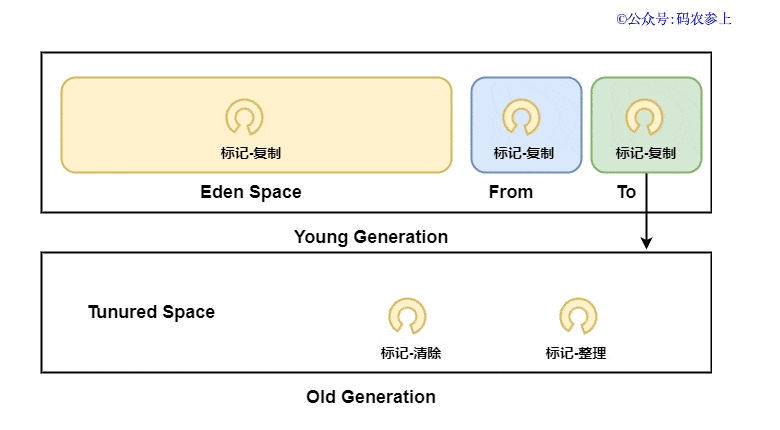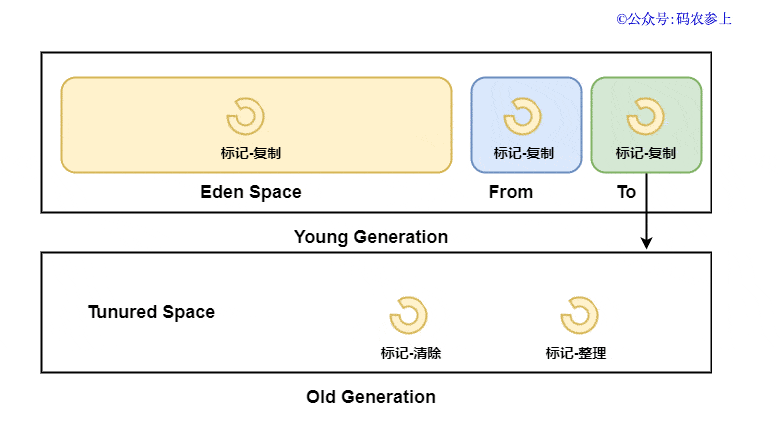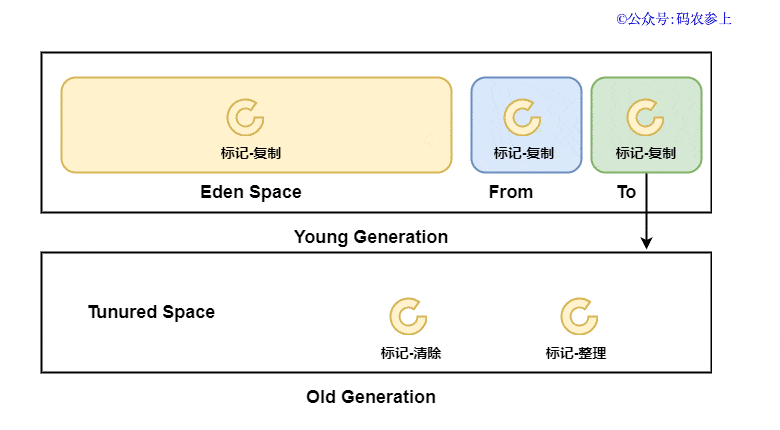
至于為什么在某一區域選擇某種算法,還是和三種算法的特點息息相關的,再從3個維度進行一下對比:
- 執行效率:從算法的時間復雜度來看,復制算法最優,標記清除次之,標記整理最低
- 內存利用率:標記整理算法和標記清除算法較高,復制算法最差
- 內存整齊程度:復制算法和標記整理算法較整齊,標記清除算法最差
盡管具有很多差異,但是除了都需要進行標記外,還有一個相同點,就是在gc線程開始工作時,都需要STW暫停所有工作線程。
總結
本文中,我們先介紹了垃圾收集的基本問題,什么樣的對象可以作為垃圾被回收?jvm中通過可達性分析算法解決了這一關鍵問題,并在它的基礎上衍生出了多種常用的垃圾收集算法,不同算法具有各自的優缺點,根據其特點被應用于各個年代。
雖然這篇文章嘮嘮叨叨了這么多,不過這些都還是基礎的知識,如果想要徹底的掌握jvm中的垃圾收集,后續還有垃圾收集器、內存分配等很多的知識需要理解,不過我們今天就介紹到這里啦,希望通過這一篇圖解,能夠幫助大家更好的理解垃圾收集算法。
本文轉載自微信公眾號「碼農參上」,可以通過以下二維碼關注。轉載本文請聯系碼農參上公眾號。


















