科普文:常見垃圾回收算法與 JS GC 原理
一、前言
在程序運行過程中,幾乎每時每刻都在為進程分配新的內存,但計算機的內存空間總是有限的,內存空間總有被占滿的時候,所以我們需要進行 「垃圾數據回收」 ,以釋放內存空間。
不同的編程語言會有著不一樣的垃圾回收策略,通常情況下,可以分為 「手動回收」 和 「自動回收」 兩種。
比如,C/C++ 就是使用 「手動回收」 策略,內存空間的分配、銷毀等操作都由開發人員自行通過代碼控制。若數據使用完后,沒有主動釋放的無用內存,就會隨著程序運行時間的增加,內存逐漸被占滿,這種情況被稱為 「內存泄漏」 。
而 JavaScript/Java/Python 等使用自動回收策略,產生的垃圾數據由 「垃圾回收器」 主動釋放,工程師無需手動通過代碼釋放內存。不過雖然是自動回收,但工程師若完全不關心內存管理,還是很容易產生內存泄漏的。接下來,讓我們看看自動垃圾回收的基本原理。
二、自動垃圾回收算法
隨著時間的演進,垃圾回收算法也在不斷地完善,說是完善其實不算準確,應該說是根據不同的需求而有了不同的取舍,從而產生了不同的算法。其實不論哪個垃圾回收算法,都有一套共同的流程:
標記內存空間中的活動對象(在使用中的對象)和非活動對象(可以回收的對象)。
刪除非活動對象,釋放內存空間。
整理內存空間,避免頻繁回收后產生的大量內存碎片(不連續內存空間)。
2.1 標記-清除法
標記-清除法由 John McCarthy 于 1960 年發表的一篇論文提出,其主要分兩個階段:
第一階段是標記,從一個 GC root 集合出發,沿著「指針」找到所有對象,將其標記為活動對象。
第二階段是清除,將內存中未被標記的對象刪除,釋放內存空間。
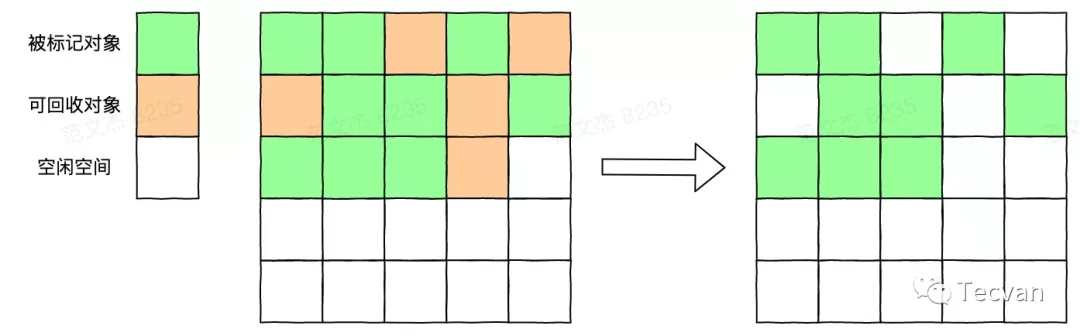
從上面的描述來看,標記-清除算法可以說是非常簡單的,現在的各類垃圾回收算法也都是它的思想的延續。
雖然簡單,但其也有著很明顯的缺點,即在多次回收操作后,會產生大量的內存碎片,由于算法沒有再整理內存空間,內存空間將變得很碎,此時如果需要申請一個較大的內存空間,即使剩余內存總大小足夠,也很容易因為沒有足夠的連續內存而分配失敗。
2.2 復制算法
為了解決以上問題,Marvin L. Minsky 在 1963 年提出了著名的 「復制算法」 :
將整個空間平均分成 from 和 to 兩部分。
先在 from 空間進行內存分配,當空間被占滿時,標記活動對象,并將其復制到 to 空間。
復制完成后,將 from 和 to 空間互換。
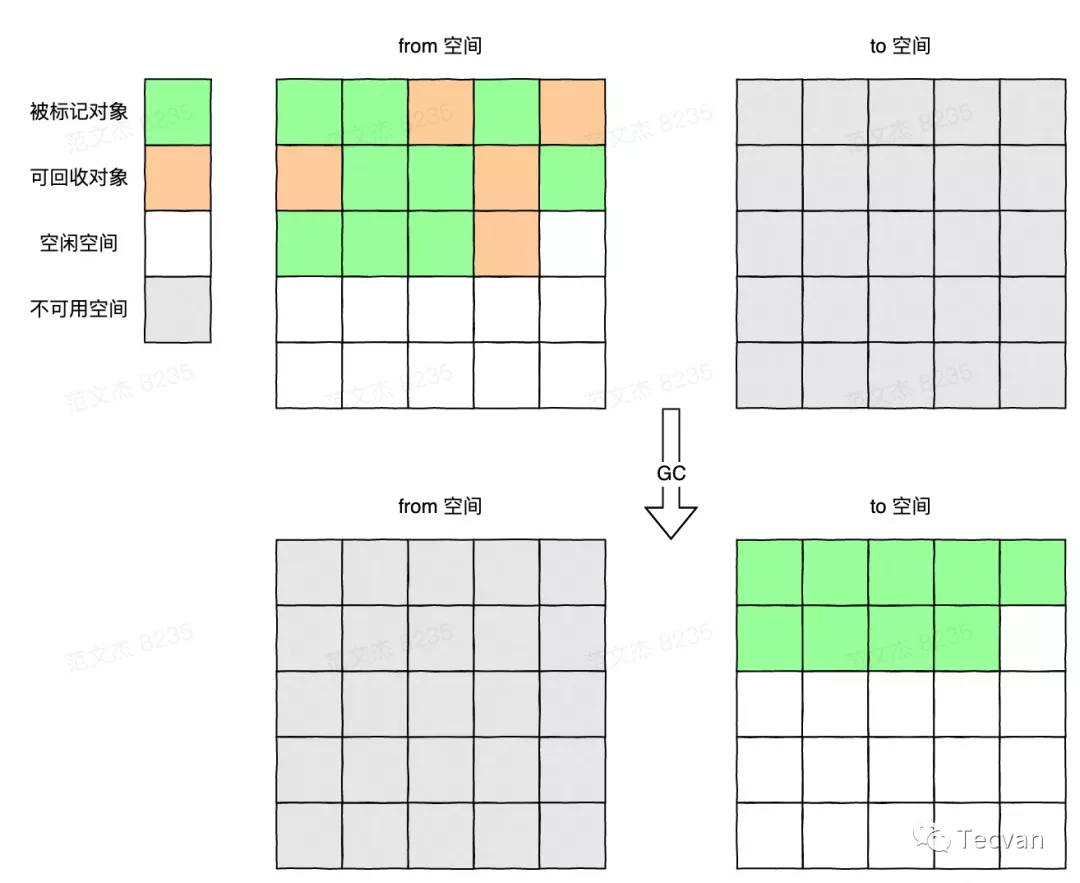
由于直接將活動對象復制到另一半空間,沒有了清除階段的開銷,所以能在較短時間內完成回收操作,并且每次復制的時候,對象都會集中到一起,相當于同時做了整理操作,避免了內存碎片的產生。
雖然復制算法有吞吐量高、沒有碎片的優點,但其缺點也非常明顯。首先,復制操作也是需要時間成本的,若堆空間很大且活動對象很多,則每次清理時間會很久。其次,將空間二等分的操作,讓可用的內存空間直接減少了一半。
2.3 引用計數
該算法由 George E. Collins 于 1960 年提出,主要操作為:
實時統計指向對象的引用數(指針數量)。
當引用數為 0 時,實時回收對象。
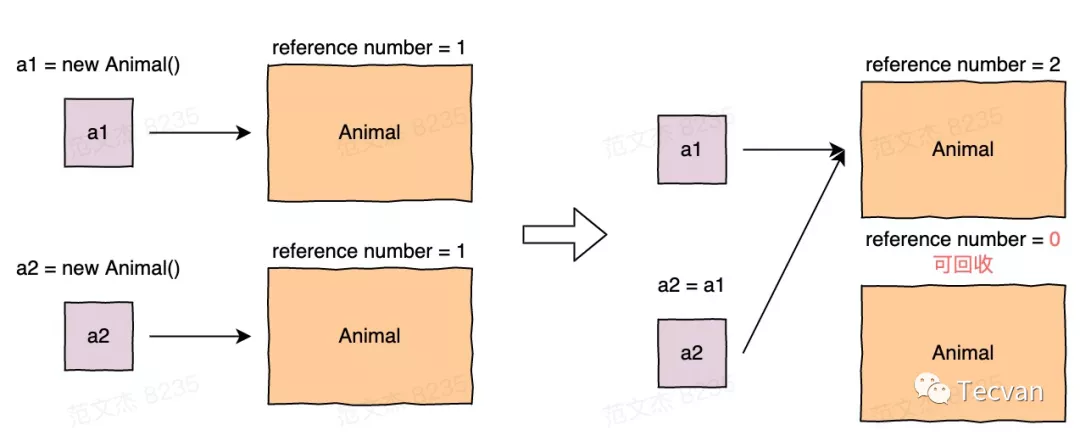
該算法可以即時回收垃圾數據,對程序的影響時間很短,效率很高。高性能、實時回收,看似完美的方案其實也有個問題,當對象中存在循環引用時,由于引用數不會降到 0,所以對象不會被回收。
上面三大算法的出現,基本奠定了垃圾回收的根本性內容,后續出現的垃圾回收算法,基本都是基于上面三個算法的取舍和組合。
2.4 標記-壓縮算法
該算法于 1970 年出現,其結合了標記-清除法和復制算法的優點,主要操作如下:
從一個 GC root 集合出發,標記所有活動對象。
將所有活動對象移到內存的一端,集中到一起。
直接清理掉邊界以外的內存,釋放連續空間。
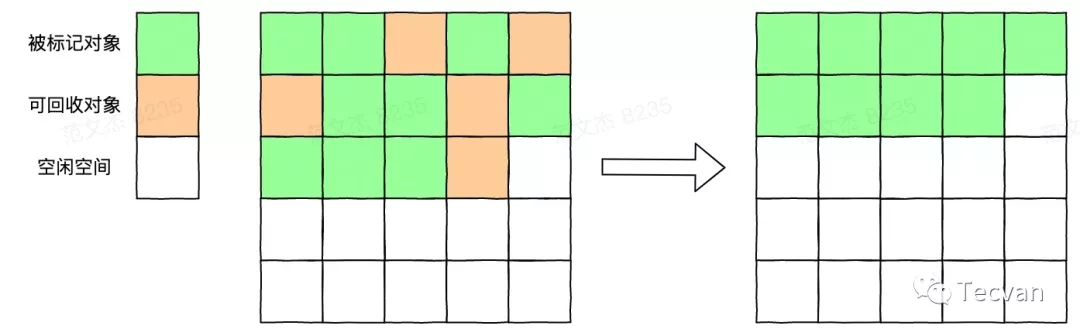
可以發現,該算法既避免了標記-清除法產生內存碎片的問題,又避免了復制算法導致可用內存空間減少的問題。當然,該算法也不是沒有缺點的,由于其清除和整理的操作很麻煩,甚至需要對整個堆做多次搜索,故而堆越大,耗時越多。
2.5 代際假設和分代收集
「代際假說」:
It has been empirically observed that in many programs, the most recently created objects are also those most likely to become unreachable quickly.
經過調查發現,大多數應用程序內的數據有以下兩個特點:
- 大多數對象的生命周期很短,很快就不再被需要了
- 那些一直存活的對象通常會存在很久
簡單講就是對象的生存時間有點兩極化的情況:

「分代收集:」 所以可以將對象進行分代,從而對不同分代實施不同的垃圾回收算法,以達到更高的效率(如 Java GC: https://plumbr.io/handbook/garbage-collection-in-java/generational-hypothesis)。
三、JavaScript 垃圾回收
JavaScript 的原始數據類型存在棧中,引用數據類型存在堆中,所以討論 JavaScript 的垃圾回收即討論其棧中數據的回收以及堆中數據的回收。
3.1 棧中垃圾回收
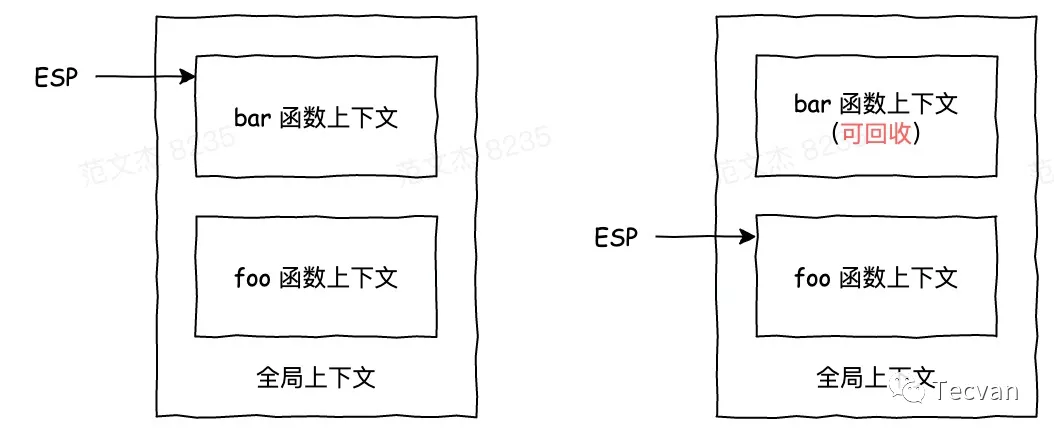
ESP(Extended Stack Pointer): 擴展棧指針寄存器,用于存放函數棧頂指針。
JavaScript 在執行函數時,會將其上下文壓入棧中,ESP 上移,而當函數執行完成后,其執行上下文可以銷毀了,此時僅需將 ESP下移到下一個函數執行上下文即可,當下一個函數入棧時,會將 ESP 以上的空間直接覆蓋。
所以 JavaScript 引擎是通過下移 ESP 來完成棧的垃圾回收的。
3.2 堆中垃圾回收
不同于棧中的垃圾回收,堆中的垃圾數據回收需要用到 JavaScript 的垃圾回收器。
JavaScript 堆中垃圾數據回收就使用到了分代收集的思想,引擎將堆空間分為 「新生代(young-space)」 和 「老生代(old-space)」 ,并且對兩個區域實施不同的垃圾回收策略。
「新生代:」 新生代用于存放生存時間短的對象,大多數新創建的小的對象都會被分配到該區域,該區域的垃圾回收會比較頻繁。
在新生代中,引擎使用 Scavenge 算法(https://v8.dev/blog/trash-talk) 進行垃圾回收,即上面提到的復制算法。
其將新生代空間對半分為 from-space 和 to-space 兩個區域。新創建的對象都被存放到 from-space,當空間快被寫滿時觸發垃圾回收。先對 from-space 中的對象進行標記,完成后將標記對象復制到 to-space 的一端,然后將兩個區域角色反轉,就完成了回收操作。
由于每次執行清理操作都需要復制對象,而復制對象需要時間成本,所以新生代空間會設置得比較小(1~8M)。
「老生代:」 老生代被用于存放生存時間長的對象和大的對象:
- 即一些大的對象會被直接分配到老生代空間
- 新生代中經過兩次垃圾回收后仍然存活的對象,會晉升到老生代空間
引擎在該空間主要使用上面提到的 「標記-壓縮算法」 。首先對活動對象進行標記,標記完成后,將所有存活對象移到內存的一段,然后清理掉邊界外的內存。
由于 JavaScript 是單線程運行的,意味著垃圾回收算法和腳本任務在同一線程內運行,在執行垃圾回收邏輯時,后續的腳本任務需要等垃圾回收完成后才能繼續執行。若堆中的數據量非常大,一次完整垃圾回收的時間會非常長,將導致應用的性能和響應能力都直線下降。
為了避免垃圾回收影響應用的性能,V8 將標記的過程拆分成多個子標記,讓垃圾回收標記和應用邏輯交替執行,避免腳本任務等待較長時間。