













200字帶你看完一本書,GPT-3已經會給長篇小說寫摘要了
本文經AI新媒體量子位(公眾號ID:QbitAI)授權轉載,轉載請聯系出處。
現在,AI能幫你200字看完一段12萬詞的長篇小說了!
比如這樣一段121567詞的《傲慢與偏見》原文:
△圖源OpenAI官網
AI分四個階段來總結:
先把原文總結成276個摘要(24796詞),然后進一步壓縮成25個摘要(3272詞),再到4個摘要(475詞)。
最終得到一段175詞的摘要,長度只有原片段的千分之一:

粗略翻譯下看看,關鍵的幾個情節都點到了:

這理解力,不禁讓人望著某泡面壓留下了淚水。
這就是OpenAI最新推出的能給任意長度書籍寫摘要的模型。
平均10萬詞以上的訓練文本,最終能壓縮到400字以內。
而且這也是源自OpenAI精妙的刀法:沒錯,就是把GPT-3數據集里的書籍/小說部分抽出來進行訓練所得到的模型。
話不多說,一起來看看這個微調版的GPT-3模型。
遞歸任務分解
首先,現將“總結一段文本”這一任務進行算法上的分解。
如果該文本足夠短,就直接進行總結;如果它比較長,就把文本分成小塊,并遞歸地對每一塊進行總結。
這就形成了一棵總結任務樹:
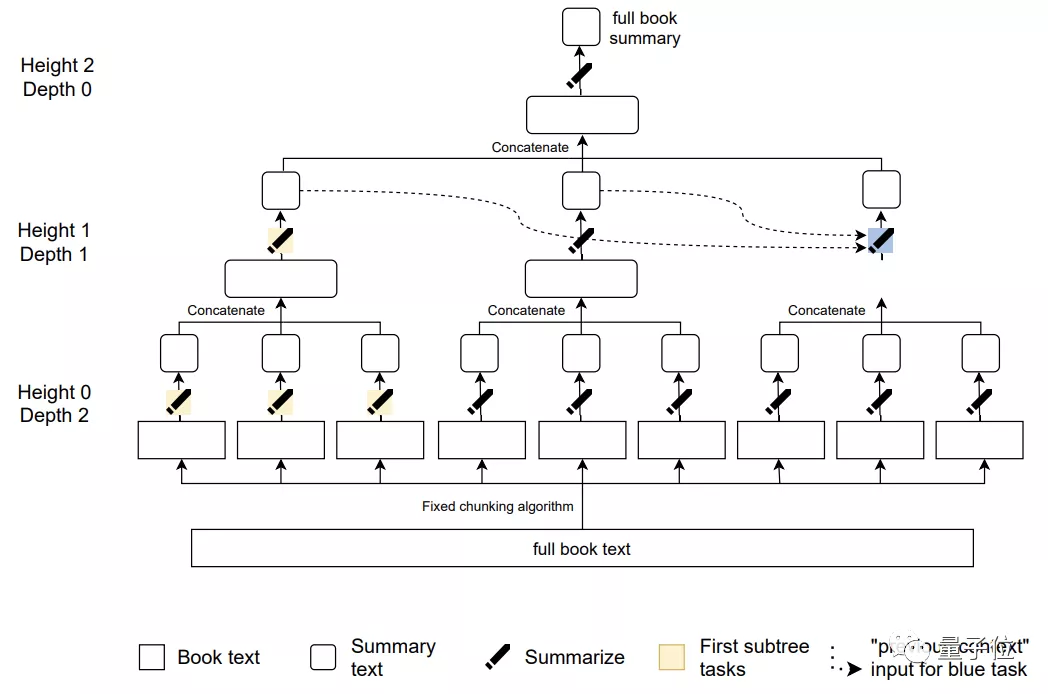
其中只有葉子任務會對書籍中的原始文本進行操作。
并且,已生成的摘要應該放在同一深度,并按照順序串聯起來。
比如上圖中的藍色任務的先前總結輸出就用虛線來表示,這樣,每一個摘要都是自然地從上一層任務(前文)流出,以保證那些相距較遠的段落能夠真正地“聯系上下文”。
接下來開始訓練:
- 根據上述的任務樹將書籍和其子摘要遞歸為任務;
- 從樹上抽出一個節點,對應一個帶訓練的總結任務;
- 獲得訓練數據,給該節點以輸入;
- 使用訓練數據對模型進行微調。
其中,所有訓練數據都來自GPT-3中的書籍部分。
研究人員會跳過非敘事性書籍,盡量選擇小說類(平均包含超過10萬個單詞),因為這些上下文關聯性更強的文本對總結任務來說更難。
這一訓練過程可以使用新的模型、不同的節點采樣策略、不同的訓練數據類型(演示和比較)來迭代。
對于演示用的數據,使用標準的交叉熵損失函數進行行為克隆(BC)。
對于比較數據,則通過強化學習(RL)來對抗一個專為人類偏好而訓練的獎勵模型。
強化學習也有三種變體的抽樣任務:
- 全樹
- 第一棵子樹
- 第一片葉子
訓練完成后進行總結,任務的最終目的是追溯出敘述的時間線和整體主題。
每個摘要子任務的目標是將文本壓縮5到10倍,長度上限為128到384個符號。
優于現有同類模型
實驗階段,研究人員使用了Goodreads 2020榜單上的40本最受歡迎的書籍,其中囊括了幻想、恐怖、愛情、推理等近20個類型。
然后讓兩名人類研究員和模型同時進行總結,要求雙方的摘要質量的一致性接近于80%。
模型規模分為175B和6B兩種,且訓練模式也分為上述的強化學習的三種變體任務。
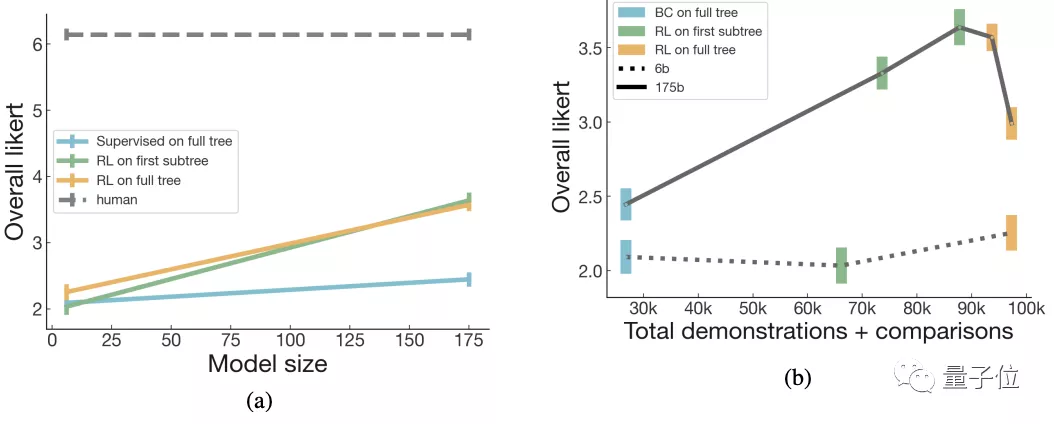
最后結果中,可以看到第一棵子樹RL和全樹RL的總結任務最接近于人類的水平:
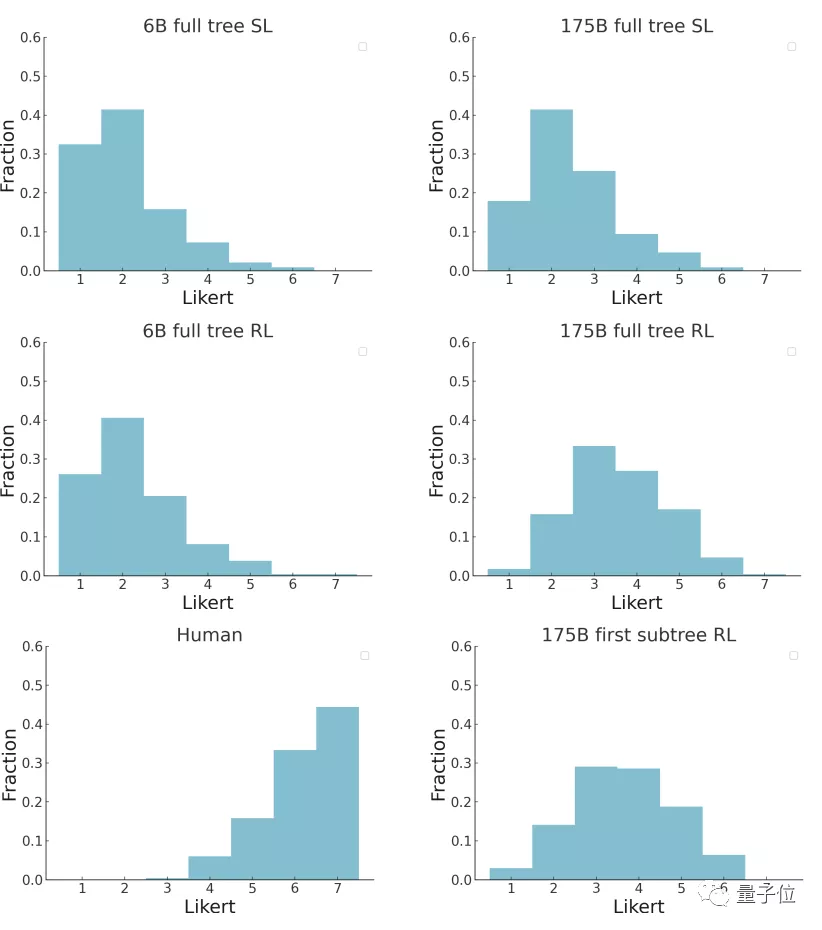
并且,也有超過5%的175B模型的摘要被打到了6分(滿分7分),超過15%的摘要被打到5分:
研究團隊也在最近提出的BookSum數據集上進行了測試,結果比現有的長文本總結模型更好:
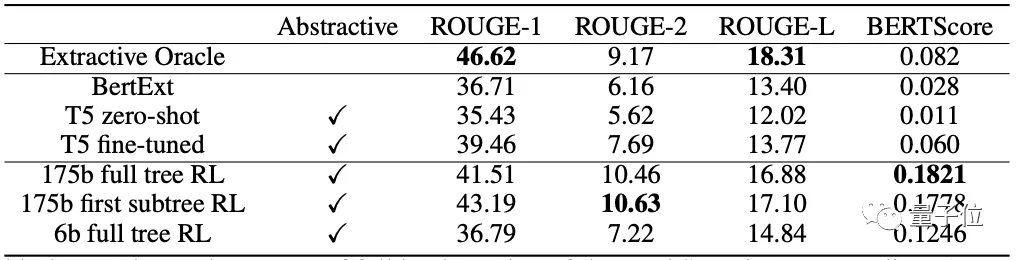
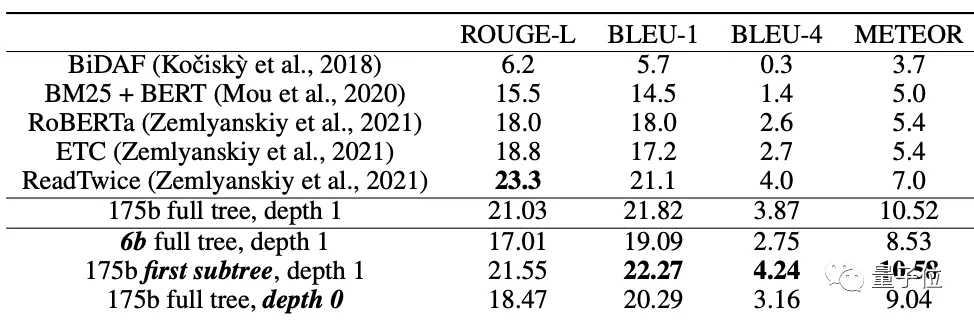
除此之外,摘要是否能用來回答關于原文的問題也是評估方法之一。
因此,團隊將他們的總結模型應用于NarrativeQA問題回答數據集,可以看到,雖然沒有經過明確的問題回答訓練,但在所有的指標上都獲得了最好的結果:
作者介紹
這篇研究出自OpenAI的 OpenAI Alignment team,他們表示,目前沒有開源此模型的計劃。
論文一作Jeff Wu本碩都畢業于麻省理工大學,在加入OpenAI之前有過在谷歌工作的經歷。
共同一作Long Ouyang本科畢業于哈佛大學,博士則畢業于斯坦福大學的認知心理學專業,主要研究領域為認知科學與概率規劃研究。
論文:
https://arxiv.org/abs/2109.10862
OpenAI官網介紹:
https://openai.com/blog/summarizing-books/























