













線上數(shù)據(jù)庫掛了,你該如何排查?
介紹
大家好,我是Leo,目前在常州從事Java后端工程師。上篇文章我們介紹了讀寫分離那些問題,主要從概念,目的,單到多的演變,安全性演變以及六個解決方案為敘述。今天我們聊聊一主多從,如果掛了你會如何快速定位。贈送算法,MySQL書籍,劍指offer
思路
根據(jù)讀者和用戶的反饋,畫了一個寫作思路圖。通過此圖可以更好的分析出當(dāng)前文章的寫作知識點。可以更快的幫助讀者在最短時間內(nèi)判斷是否為有效文章!
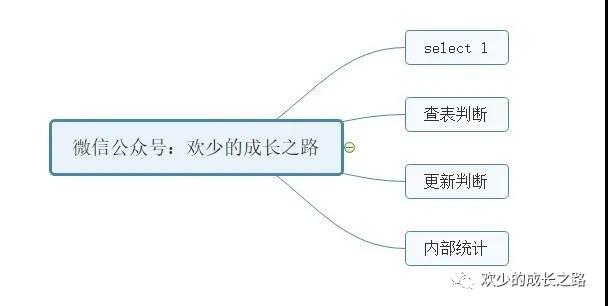
外部統(tǒng)計
select 1
正常情況
這里先來聊一下select 1的用法,這個用法我想大家應(yīng)該都是知道的,因為判斷一個庫是否還活著,只需要執(zhí)行一條SQL語句不就好了嘛
- 如果庫正常沒有問題,那么就會返回1,因為輸出1肯定是要返回1的呀
- 如果庫掛掉了,輸出1肯定是沒有反應(yīng)的,因為MySQL已經(jīng)無法提供服務(wù)了
mysql在執(zhí)行select1的時候,往往是用于單機(jī)服務(wù),我們舉一個很簡單的例子,在一個cmd控制臺上進(jìn)入mysql,并且執(zhí)行SQL語句,只能得知當(dāng)前庫是否正常。無法得知整個數(shù)據(jù)庫的集群是否都正常。所以在單機(jī)狀態(tài)下這種方案是比較常用的,一旦上了一些集群規(guī)模一般不會采用這種方案!
意外情況
首先我們介紹一下配置并發(fā)線程上限的參數(shù) innodb_thread_concurrency 。如果把他設(shè)置 3 一旦并發(fā)線程數(shù)達(dá)到這個值,InnoDB 在接收到新請求的時候,就會進(jìn)入等待狀態(tài),直到有線程退出。
這里我們可以模擬一下最壞的情況,如果這時有三個線程正常訪問數(shù)據(jù)庫執(zhí)行一個大數(shù)據(jù)量的查詢操作。如果這時來一個select 1 是否能執(zhí)行成功呢?
會執(zhí)行成功的 ! 但是如果測驗完之后這個用戶再發(fā)送一條查詢表請求,就會被堵住,因為另外三個線程的用戶也在查詢表操作,那么這幾個線程就會處于等待情況。
問題來了 select 1執(zhí)行成功了,真實的查詢語句出問題了,那么這個方案可行嗎,肯定是不行的。
innodb_thread_concurrency 這個參數(shù)默認(rèn)是0。代表著不限制上限并發(fā)線程。這個肯定是不行,考慮到整體性能的考慮,如果并發(fā)線程過于會影響MySQL的整體性能。所以我們一般建議64~128。
擴(kuò)展 這里的64~128是指并發(fā)查詢的線程,可能有些人會和并發(fā)連接會弄混。
- show processlist
執(zhí)行上述SQL,以下是Command列中的Query是屬于并發(fā)查詢,并發(fā)連接是屬于與數(shù)據(jù)庫發(fā)起連接,但是掛在那個界面不做任何操作。并發(fā)連接只是浪費(fèi)一些內(nèi)存而已,而并發(fā)查詢是浪費(fèi)MySQL限制的并發(fā)線程數(shù)的。
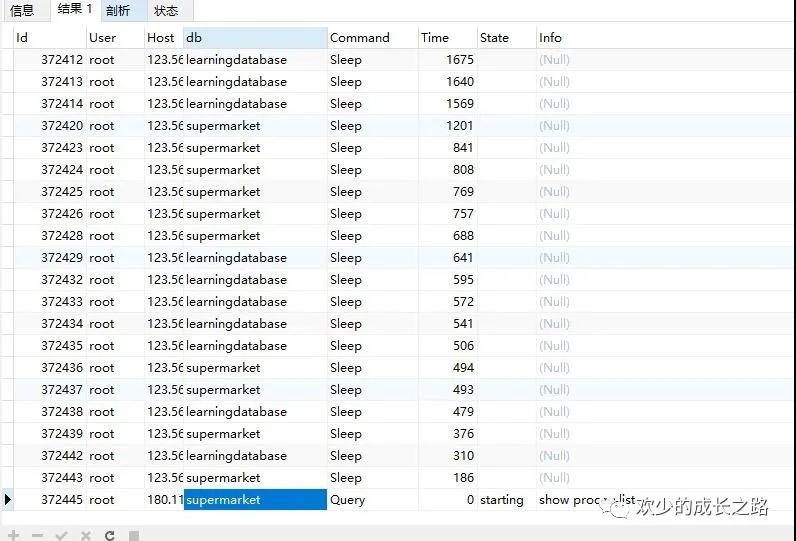
我們介紹一下熱點更新和死鎖檢測的時候吧。如果把 innodb_thread_concurrency設(shè)置為 128 的話,那么出現(xiàn)同一行熱點更新的問題時,是不是很快就把 128 消耗完了,這樣整個系統(tǒng)是不是就掛了呢?
不是的, MySQL肯定不會允許這樣的事情發(fā)生的。所以當(dāng)鎖等待的時候,并發(fā)線程會進(jìn)行減一。也就說鎖等待不會算在線程128中。
特殊情況
一些鎖等待肯定是不算在并發(fā)線程中的,那么如果像我們上述那種消耗時間比較大的查詢,如何處置呢?
如果真的干到了128,再使用select 1 豈不是會出問題嗎,所以下一個方案就誕生了
查表判斷
select 1 的弊端出來了,逐漸演變成查表判斷
- 那么表放在什么地方呢?
- 肯定不能隨便放在一個數(shù)據(jù)庫中吧!
表的位置是在如下圖的那個數(shù)據(jù)庫中建立的,我們可以建立一個health_check,里面只放一行數(shù)據(jù),然后定期執(zhí)行。
- select * from mysql.health_check;
這樣的確可以從innodb這邊解決當(dāng)前的數(shù)據(jù)庫的狀態(tài),那么問題來了,innodb是要寫日志的,也就是寫binlog,所以當(dāng)磁盤空間占用率達(dá)到100%。所有的更新語句和事務(wù)提交的 commit 語句就都會被堵住。但是,系統(tǒng)這時候還是可以正常讀數(shù)據(jù)的。
上面的查詢判斷,顯然是不行的。
更新數(shù)據(jù)也就是記入一個事務(wù)。記入事務(wù)是要寫binlog日志的,磁盤滿了咋寫?
所以執(zhí)行不成功,但是還能提供讀取的數(shù)據(jù)。顯然兩頭不對應(yīng)肯定不可以的。
更新判斷
又pass了一個
既然要更新,就要放個有意義的字段,常見做法是放一個 timestamp 字段,用來表示最后一次執(zhí)行檢測的時間。這條更新語句類似于:
- update mysql.health_check set t_modified=now();
所有主從庫涉及到更新操作的話,肯定是要處理同步問題的
節(jié)點可用性的檢測都應(yīng)該包含主庫和備庫。如果用更新來檢測主庫的話,那么備庫也要進(jìn)行更新檢測。備庫的檢測也是要寫 binlog 的。由于我們一般會把數(shù)據(jù)庫 A 和 B 的主備關(guān)系設(shè)計為雙 M 結(jié)構(gòu),所以在備庫 B 上執(zhí)行的檢測命令,也要發(fā)回給主庫 A。
主庫 A 和備庫 B 都用相同的更新命令,就可能出現(xiàn)行沖突,也就是可能會導(dǎo)致主備同步停止。所以,現(xiàn)在看來 mysql.health_check 這個表就不能只有一行數(shù)據(jù)了。
如果存放多行的話,在一主多從中就要考慮server_id的問題啦
MySQL 規(guī)定了主庫和備庫的 server_id 必須不同(否則創(chuàng)建主備關(guān)系的時候就會報錯),這樣就可以保證主、備庫各自的檢測命令不會發(fā)生沖突。
更新判斷是一個相對比較常用的方案了,不過依然存在一些問題。比如 “判定慢”
根據(jù)我們前幾篇文章的介紹,當(dāng)更新操作出現(xiàn)慢操作或者失敗。就可以主從切換了,為什么還會有判定慢的問題呢?
IO資源分配
首先,所有的檢測邏輯都需要一個超時時間 N。執(zhí)行一條 update 語句,超過 N 秒后還不返回,就認(rèn)為系統(tǒng)不可用。
判定慢是因為IO資源分配的問題,日志盤的 IO 利用率已經(jīng)是 100% 的場景。這時候,整個系統(tǒng)響應(yīng)非常慢,已經(jīng)需要做主備切換了。
IO 利用率 100% 表示系統(tǒng)的 IO 是在工作的,每個請求都有機(jī)會獲得 IO 資源,執(zhí)行自己的任務(wù)。而我們的檢測使用的 update 命令,需要的資源很少,所以可能在拿到 IO 資源的時候就可以提交成功,并且在超時時間 N 秒未到達(dá)之前就返回給了檢測系統(tǒng)。
檢測系統(tǒng)一看,update 命令沒有超時,于是就得到了 系統(tǒng)正常 的結(jié)論。
IO問題,SQL執(zhí)行很慢,但是這個時候系統(tǒng)是正常的肯定是不行的
內(nèi)部統(tǒng)計
外部統(tǒng)計無法判斷滿足真實需求。我們轉(zhuǎn)戰(zhàn)內(nèi)部統(tǒng)計方案。
上一種方案的更細(xì)判斷,會有寫入binlog IO磁盤的問題,那么方案優(yōu)化,如果MySQL可以提供這類數(shù)據(jù)豈不是可靠多了嘛!
從performance_schema 庫,就在 file_summary_by_event_name 表里統(tǒng)計了每次 IO 請求的時間。
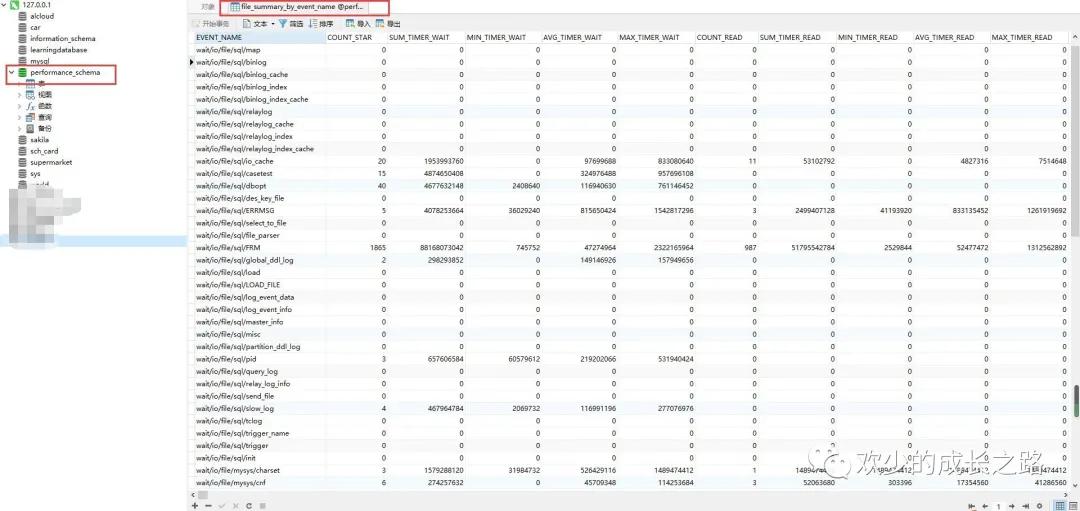
COUNT_STAR:所有 IO 的總次數(shù)
SUM_NUMBER_OF_BYTES_READ :總共從 redo log 里讀了多少個字節(jié)。
對上述表中的字段介紹簡單普及一下最常用的。剩下的用的時候自行搜索。
排查思路
找到這個表之后,我們只需要event_name = "wait/io/file/sql/binlog"這一行就OK了。
我們每一次操作數(shù)據(jù)庫,performance_schema 都需要額外地統(tǒng)計這些信息,所以我們打開這個統(tǒng)計功能是有性能損耗的。
如果要打開 redo log 的時間監(jiān)控,你可以執(zhí)行這個語句:
- update setup_instruments set ENABLED='YES', Timed='YES' where name like '%wait/io/file/innodb/innodb_log_file%';
開啟之后,用于實戰(zhàn)呢
可以通過 MAX_TIMER 的值來判斷數(shù)據(jù)庫是否出問題了。比如,你可以設(shè)定閾值,單次 IO 請求時間超過 200 毫秒屬于異常,然后使用類似下面這條語句作為檢測邏輯。
- select event_name,MAX_TIMER_WAIT FROM performance_schema.file_summary_by_event_name where event_name in ('wait/io/file/innodb/innodb_log_file','wait/io/file/sql/binlog') and MAX_TIMER_WAIT>200*1000000000;
發(fā)現(xiàn)異常后,取到你需要的信息,再通過下面這條語句:
- truncate table performance_schema.file_summary_by_event_name;
把之前的統(tǒng)計信息清空。這樣如果后面的監(jiān)控中,再次出現(xiàn)這個異常,就可以加入監(jiān)控累積值了。
總結(jié)
大概介紹了從最基礎(chǔ)的 select 1 方法開始,這種方法應(yīng)用與單機(jī)MySQL是再好不過了,但是一主多從集群之后就不行了。
于是到了查表判斷,查表判斷涉及到 innodb寫事務(wù)日志的時候,如果磁盤滿了的話,寫事務(wù)寫不了但是可以讀,導(dǎo)致不一致。
再到更新判斷。IO 利用率 100% 表示系統(tǒng)的 IO 是在工作的,每個請求都有機(jī)會獲得 IO 資源。所以update不會超時,系統(tǒng)認(rèn)為是正常情況。所以一邊響應(yīng)不了服務(wù),一邊又判斷正常,導(dǎo)致不一致。
最后到了內(nèi)部統(tǒng)計。采用系統(tǒng)庫的方案。通過 event_name 和 MAX_TIMER 字段進(jìn)行判斷是否出問題


















