













用AI打破編解碼器內(nèi)卷,高通最新幾篇頂會論文腦洞有點大
本文經(jīng)AI新媒體量子位(公眾號ID:QbitAI)授權(quán)轉(zhuǎn)載,轉(zhuǎn)載請聯(lián)系出處。
用AI搞視頻編解碼器,現(xiàn)在路子有點“野”。
插幀、過擬合、語義感知、GAN……你想過這些“腦洞”或AI算法,也能被用到編解碼器上面嗎?
例如,原本的算法每幀壓縮到16.4KB后,樹林開始變得無比模糊:

但在用上GAN后,不僅畫面更清晰,每幀圖像還更小了,只需要14.5KB就能搞定!

又例如,用插幀的思路結(jié)合神經(jīng)編解碼器,能讓最新壓縮算法效果更好……
這一系列算法的思路,背后究竟是什么原理,用AI搞編解碼器,潛力究竟有多大?
我們采訪了高通工程技術(shù)副總裁、高通AI研究方向負(fù)責(zé)人侯紀(jì)磊博士,了解了高通一些AI編解碼器中的算法細(xì)節(jié)和原理。
編解碼器標(biāo)準(zhǔn)逐漸“內(nèi)卷”
當(dāng)然,在了解AI算法的原理之前,需要先了解視頻到底是怎么壓縮的。
如果不壓縮,1秒30幀、8bit單通道色深的480p視頻,每秒就要傳輸80+Mbps數(shù)據(jù),想在網(wǎng)上實時看高清視頻的話,幾乎是不可能的事情。
目前,主要有色度子采樣、幀內(nèi)預(yù)測(空間冗余)和幀間預(yù)測(時間冗余)幾個維度的壓縮方法。
色度子采樣,主要是基于我們眼睛對亮度比對顏色更敏感的原理,壓縮圖像的色彩數(shù)據(jù),但視覺上仍然能保持與原圖接近的效果。
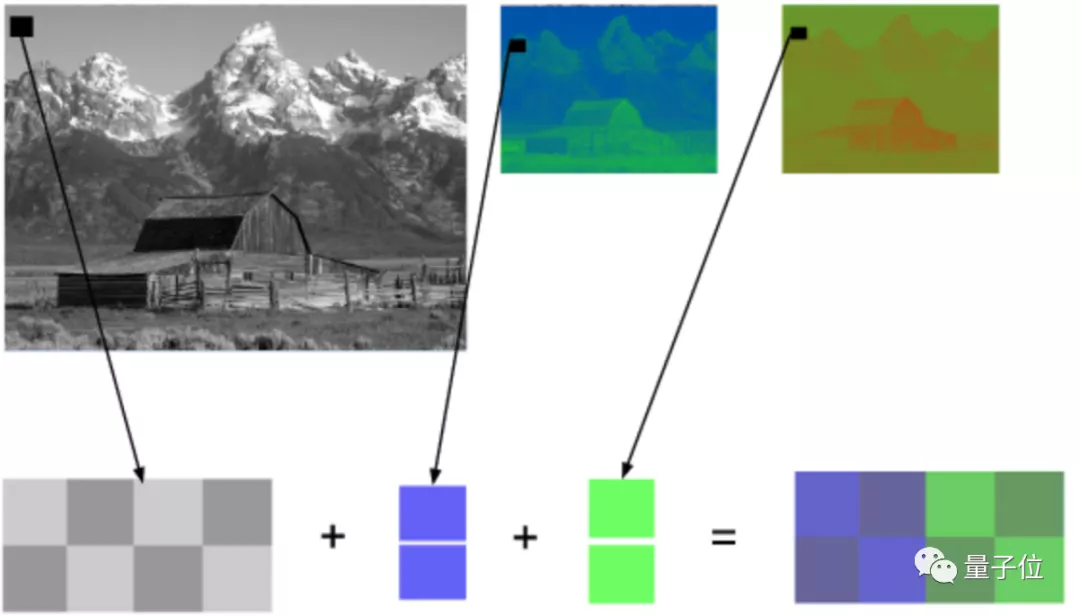
幀內(nèi)預(yù)測,利用同一幀中的大片相同色塊(下圖地板等),預(yù)測圖像內(nèi)相鄰像素的值,得出的結(jié)果比原始數(shù)據(jù)更容易壓縮。
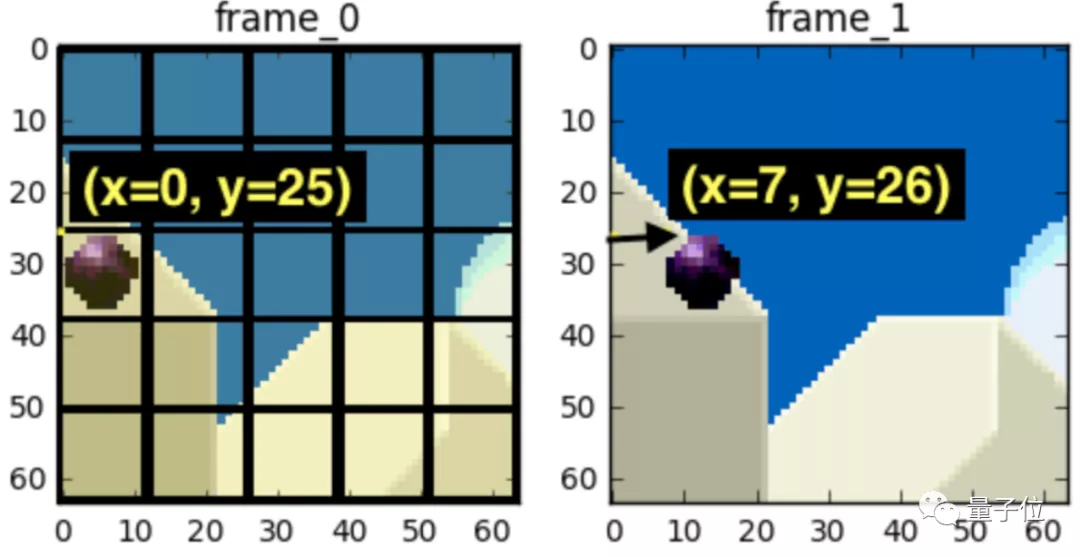
幀間預(yù)測,用來消除相鄰幀之間大量重復(fù)數(shù)據(jù)(下圖的背景)的方法。利用一種名叫運動補(bǔ)償的方法,用運動向量(motion vector)和預(yù)測值計算兩幀之間像素差:
這些視頻壓縮的方法,具體到視頻編解碼器上,又有不少壓縮工作可以進(jìn)行,包括分區(qū)、量化、熵編碼等。
然而,據(jù)侯紀(jì)磊博士介紹,從H.265到H.266,壓縮性能雖然提升了30%左右,但這是伴隨著編碼復(fù)雜度提高30倍、解碼復(fù)雜度提高2倍達(dá)成的。
這意味著編解碼器標(biāo)準(zhǔn)逐漸進(jìn)入了一個“內(nèi)卷”的狀態(tài),提升的壓縮效果,本質(zhì)上是用編解碼器復(fù)雜度來交換的,并不算真正完成了創(chuàng)新。
因此,高通從已有壓縮方法本身的原理、以及編解碼器的構(gòu)造入手,搞出了幾種有意思的AI視頻編解碼方法。
3個方向提升壓縮性能
具體來說,目前的AI研究包括幀間預(yù)測方法、降低解碼復(fù)雜度和提高壓縮質(zhì)量三個方向。
“預(yù)判了B幀的預(yù)判”
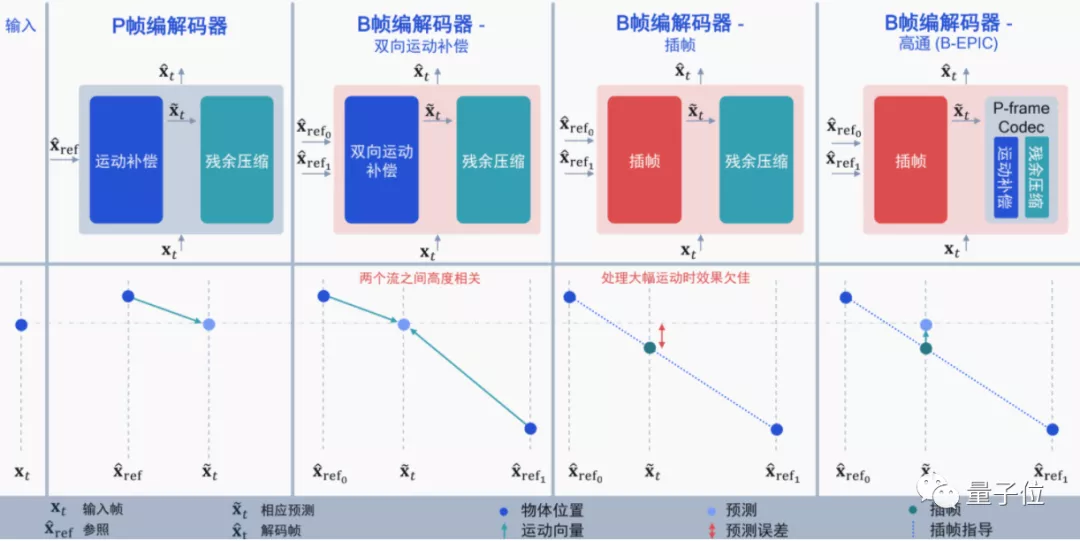
從幀間預(yù)測來看,高通針對B幀編解碼提出了一種新思路,論文已經(jīng)登上ICCV 2021。
I幀:幀內(nèi)編碼幀(intra picture)、P幀:前向預(yù)測編碼幀(predictive-frame)、B幀:雙向預(yù)測內(nèi)插編碼幀(bi-directional interpolated prediction frame)

目前的編解碼大多集中在I幀(幀內(nèi)預(yù)測)和P幀上,而B幀則是同時利用I幀和P幀的雙向運動補(bǔ)償來提升壓縮的性能,在H.265中正式支持(H.264沒有)。
雖然用上B幀后,視頻壓縮性能更好,但還是有兩個問題:
一個是視頻需要提前加載(必須提前編碼后面的P幀,才能得到B幀);另一個是仍然會存在冗余,如果I幀和P幀高度相關(guān),那么再用雙向運動補(bǔ)償就顯得很浪費。
打個比方,如果從I幀→B幀→P幀,視頻中只有一個球直線運動了一段距離,那么再用雙向運動補(bǔ)償?shù)脑挘蜁芾速M:

這種情況下,用插幀似乎更好,直接通過時間戳就能預(yù)測出物體運動的狀態(tài),編碼計算量也更低。
但這又會出現(xiàn)新的問題:如果I幀和P幀之間有個非常大的突變,例如球突然在B幀彈起來了,這時候用插幀的效果就很差了(相當(dāng)于直接忽略了B幀的彈跳)。
因此,高通選擇將兩者結(jié)合起來,將基于神經(jīng)網(wǎng)絡(luò)的P幀壓縮和插幀補(bǔ)償結(jié)合起來,利用AI預(yù)測插幀后需要進(jìn)行的運動補(bǔ)償:
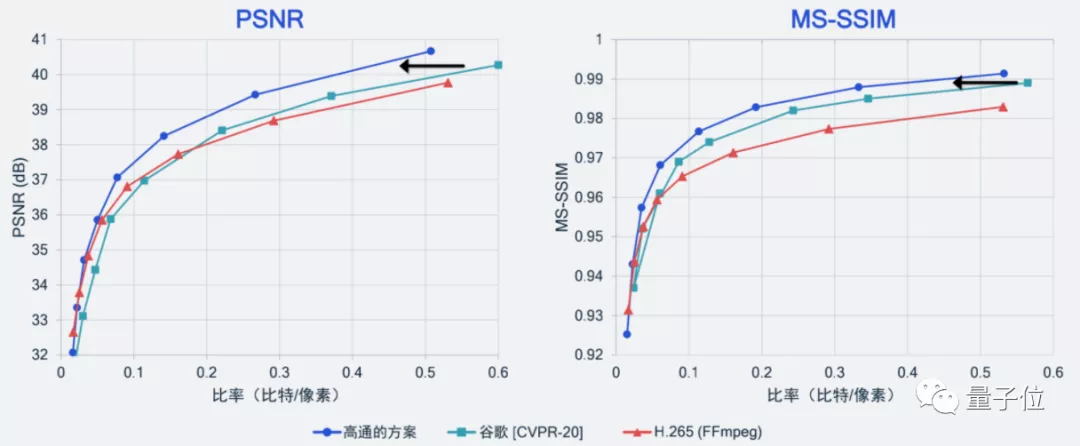
別說,效果還確實不錯,比谷歌之前在CVPR 2020上保持的SOTA紀(jì)錄更好,也要好于當(dāng)前基于H.265標(biāo)準(zhǔn)實現(xiàn)開源編解碼器的壓縮性能。
除此之外,高通也嘗試了一些其他的AI算法。
用“過擬合”降低解碼復(fù)雜度
針對編解碼器標(biāo)準(zhǔn)內(nèi)卷的情況,高通也想到了用AI做自適應(yīng)算法,來像“過擬合”一樣根據(jù)視頻比特流更新一個模型的權(quán)重增量,已經(jīng)有相關(guān)論文登上ICLR 2021。
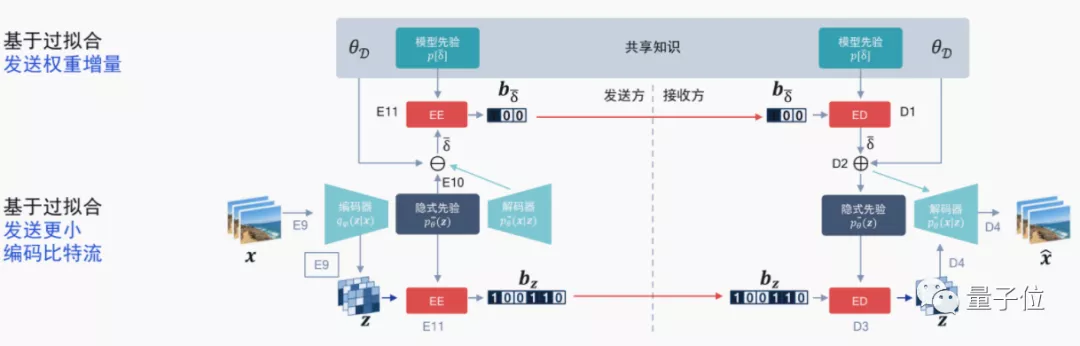
這種方法意味著針對單個模型進(jìn)行“過擬合”,對比特流中的權(quán)重增量進(jìn)行編碼,再與原來的比特流進(jìn)行一個比較。如果效果更好的話,就采用這種傳輸方式。
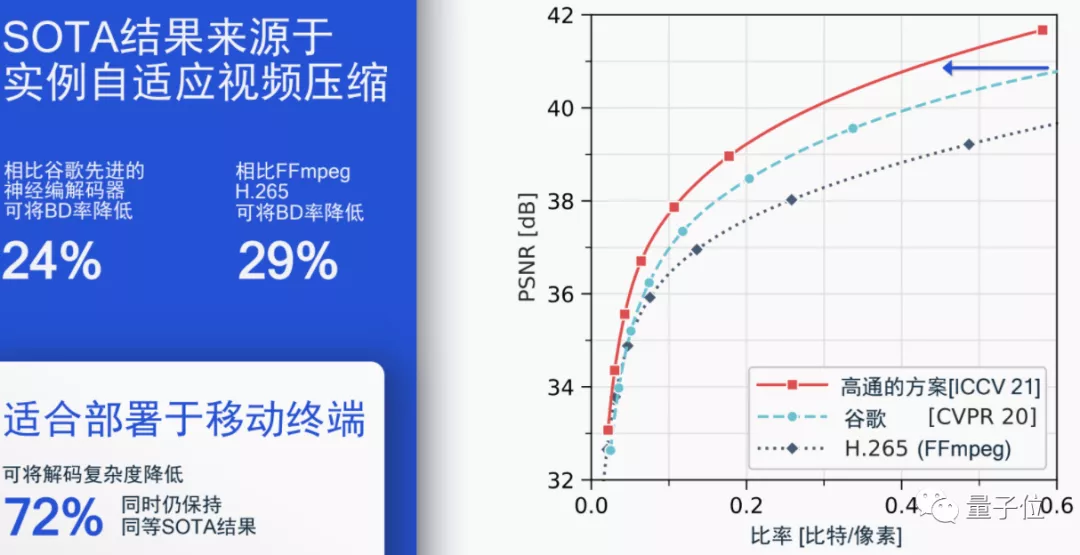
事實證明,在不降低壓縮性能的情況下,這種方法能將解碼復(fù)雜度降低72%,同時仍然保持之前B幀模型達(dá)到的SOTA結(jié)果。
當(dāng)然,除了視頻壓縮性能以外,單幀圖像被壓縮的質(zhì)量也需要考慮,畢竟視覺效果也是視頻壓縮追求的標(biāo)準(zhǔn)之一。
用語義感知和GAN提高壓縮質(zhì)量
用語義感知和GAN的思路就比較簡單了。
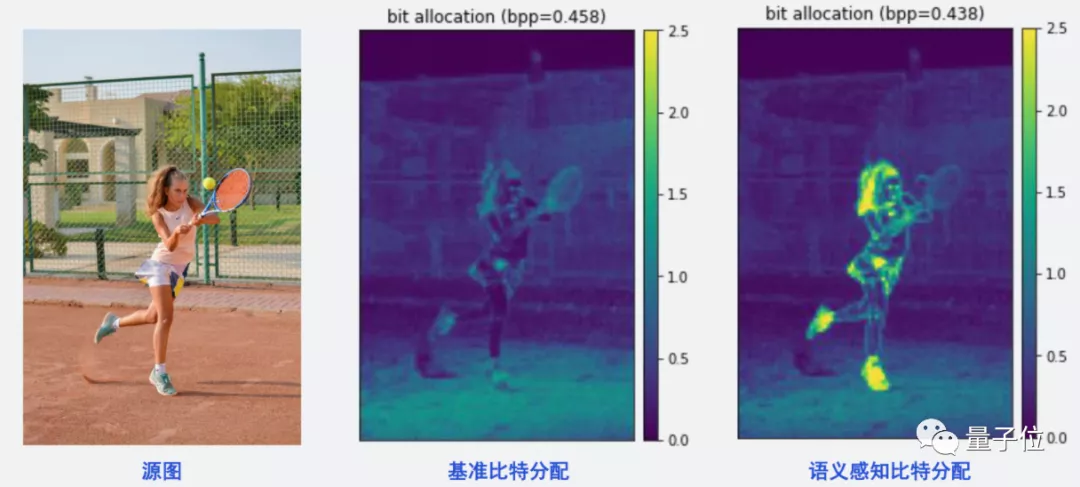
語義感知就是讓AI基于人的視覺來考慮,選出你在看視頻時最關(guān)注的地方,并著重那部分的比特分配情況。
例如你在看網(wǎng)球比賽時,往往并不會關(guān)注比賽旁邊的觀眾長什么樣、風(fēng)景如何,而是更關(guān)注球員本身的動作、擊球方法等。
那么,就訓(xùn)練AI,將更多的比特放到目標(biāo)人物身上就行,像這樣:
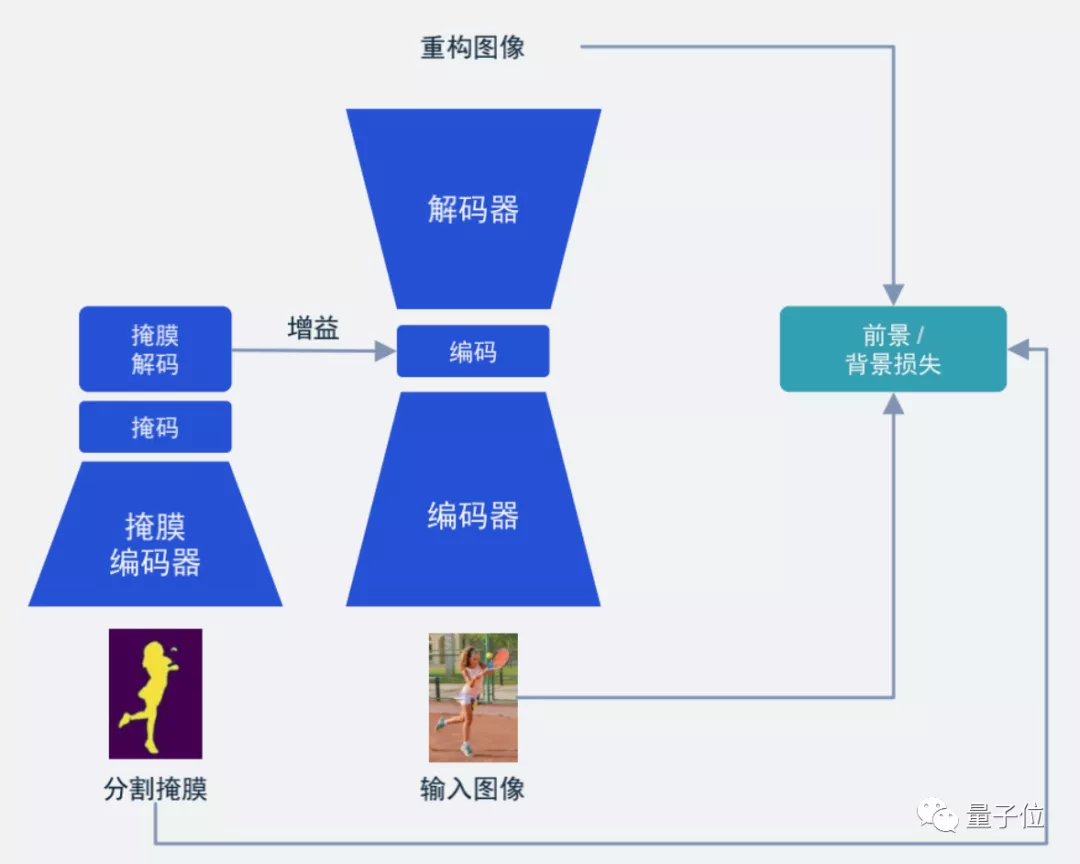
從結(jié)構(gòu)上來講也比較簡單,也就是我們常見的語義分割Mask(掩膜):
這種方法能很好地將受關(guān)注的局部區(qū)域幀質(zhì)量提升,讓我們有更好的觀看效果,而不是在視頻被壓縮時,看到的整幅圖像都是“打上馬賽克”的樣子。
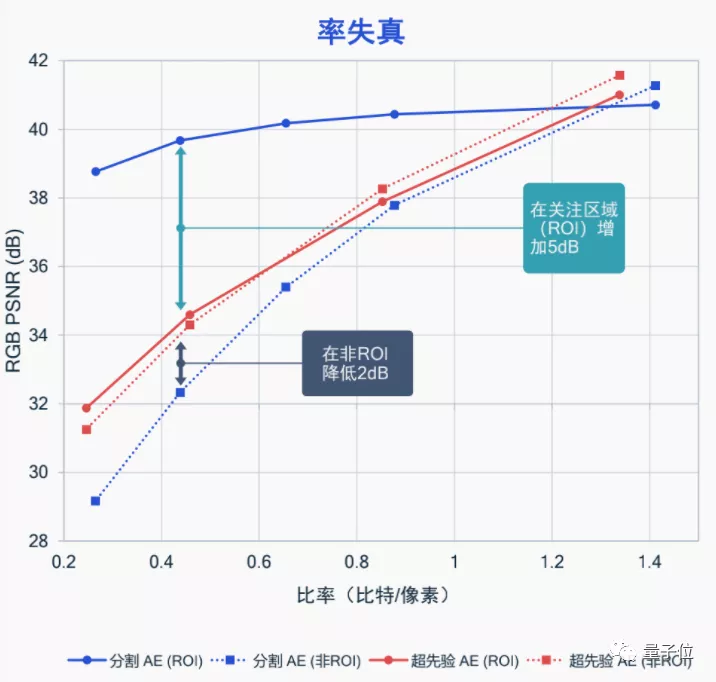
據(jù)高通表示,這種語義感知的圖像壓縮,目前已經(jīng)在擴(kuò)展到視頻壓縮上了,同樣是關(guān)注局部的方法,效果也非常不錯。
而基于GAN的方法,則更加致力于用更少的比特數(shù)生成視覺效果同樣好的圖像質(zhì)量:

據(jù)高通表示,數(shù)據(jù)集來自CVPR中一個針對圖像壓縮的Workshop CLIC,提供了大約1600張的高清圖片,利用自研的模型,能在上面訓(xùn)練出很好的效果:
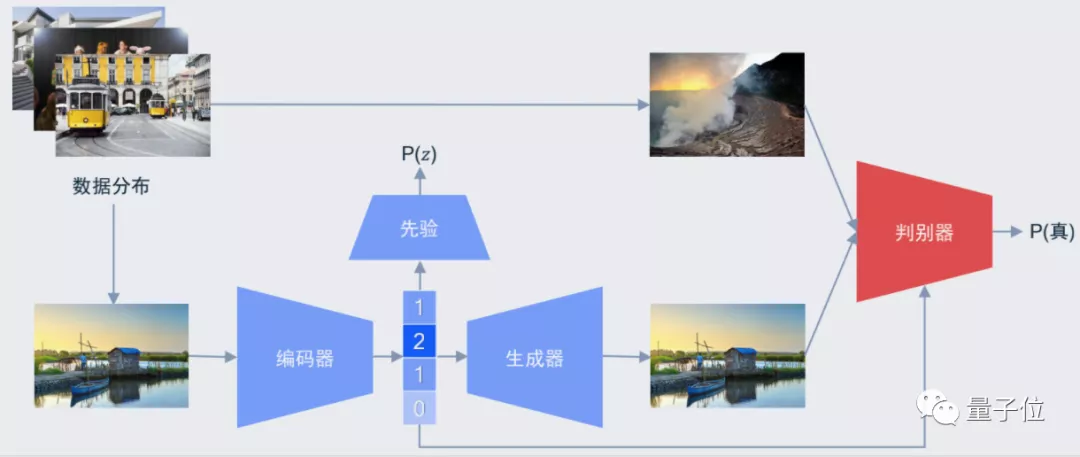
也就是開頭的圖片效果,即使在大小被壓縮后,基于GAN的圖像還是能取得更好的視覺質(zhì)量:

期待這些技術(shù)能馬上應(yīng)用到手機(jī)等設(shè)備上,讓我們看視頻的時候真正變得不卡。
相關(guān)論文:
[1]https://arxiv.org/abs/2104.00531
[2]https://arxiv.org/abs/2101.08687





















