加州大學17歲博士生“直言”:解決機器學習“新”問題,需要系統研究“老”方法
本文轉自雷鋒網,如需轉載請至雷鋒網官網申請授權。
過去十年中,機器學習(ML)已經讓無數應用和服務發生了天翻地覆的變化。隨著其在實際應用中的重要性日益增強,這使人們意識到需要從機器學習系統(MLOps)視角考察機器學習遇到的新挑戰。
那么這些新挑戰是什么呢?
近日,加州大學一位年僅17歲的博士生,在一篇博文中指出:
機器學習系統是ML在實踐中的新領域,該領域在計算機系統和機器學習之間發揮著橋梁性的作用。所以,應從傳統系統的思維中考察數據收集、驗證以及模型訓練等環節的“新情況”。
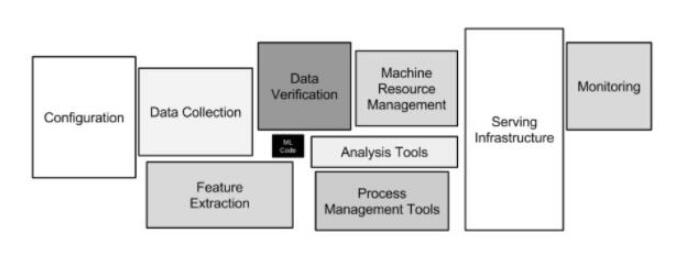
圖注:機器學習系統架構
以下是原文,AI科技科技評論做了不改變愿意的編譯和刪減
1、數據收集
雖然研究人員偏向于使用現成的數據集,例如CIFAR或SQuAD,但從模型訓練的角度來看,從業者往往需要手動標記和生成自定義數據集。但是,創建這樣的數據集非常昂貴,尤其是在需要領域專業知識的情況下。
因此,數據收集是對系統開發者來說是機器學習中的一項主要挑戰。
當前,對這個挑戰最成功的解決方案之一借用了系統和機器學習的研究。例如SnorkelAI采用了 "弱監督數據編程 "(weakly-supervised data programming)的方法,將數據管理技術與自我監督學習的工作結合了起來。
具體操作是:SnorkelAI將數據集的創建重新構想為編程問題,用戶可以指定弱監督標簽的函數,然后將其合并和加權以生成高質量的標簽。專家標記的數據(高質量)和自動標記的數據(低質量)可以被合并和跟蹤,這樣能夠考慮到不同水平的標簽質量,以確保模型訓練被準確加權。
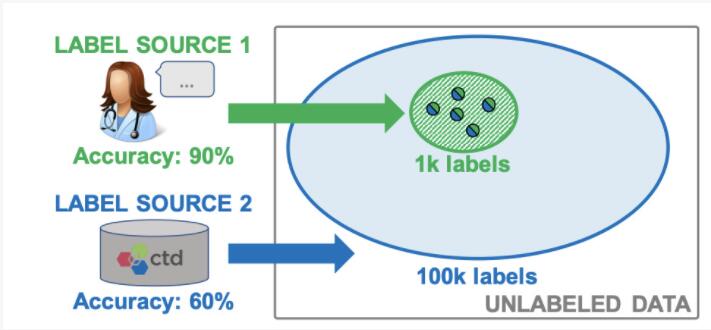
圖注:SnorkelAI結合了不同來源的標簽,使模型能夠大限度聚集和改進混合質量的標簽。
這一技術讓人聯想到數據庫管理系統中的數據融合,通過識別系統和ML的共同問題(組合數據來源),我們可以將傳統的系統技術應用于機器學習。
2、Data Verification數據驗證
數據驗證是數據收集的后續工作。數據質量是機器學習的關鍵問題,用一句俗話來說,就是 "垃圾進,垃圾出(garbage in, garbage out)"。因此,要想系統產生高質量的模型,必須確保輸入的數據也是高質量的。
解決這個問題,所需要的不僅是調整機器學習方法,更需要有調整系統的思維。幸運的是,雖然對ML來說數據驗證是一個新問題,但數據驗證在業界早已有討論:
引用TensorFlow數據驗證(TFDV)的論文:
基于游戲開“Data validation is neither a new problem nor unique to ML, and so we borrow solutions from related fields (e.g., database systems). However, we argue that the problem acquires unique challenges in the context of ML and hence we need to rethink existing solutions”
"數據驗證既不是一個新問題,也不是ML獨有的問題,因此可以我們借鑒相關領域(如數據庫系統)的解決方案。然而,我們認為,在ML的背景下,這個問題具有特殊的挑戰,因此我們需要重新思考現有的解決方案"
TFDV的解決方案采用來自數據管理系統的 "戰斗考驗 (battle-tested)"解決方案——模式化。數據庫強制執行屬性,以確保數據輸入和更新符合特定的格式。同樣,TFDV的數據模式也對輸入到模型中的數據執行規則。
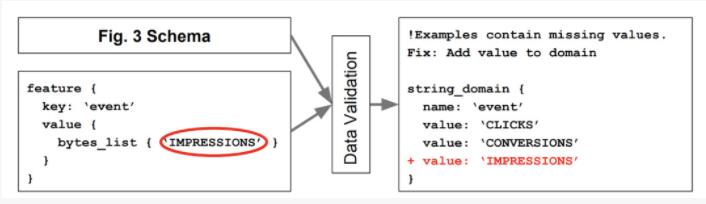
圖注:TensorFlow數據驗證的基于模式的ML數據驗證系統使用戶能夠防止生產系統中的數據輸入出現異常。
當然,也有一些差異,反映了機器學習系統與傳統模式的不同。考慮到數據分布的變化,ML模式需要隨著時間的推移而演變和調整,還需要考慮在系統的生命周期內可能對模型本身做出的改變。
很明顯,機器學習帶來了一種新型的系統挑戰。但是,這些系統帶來了很多舊東西的同時也帶來了新的東西。在我們尋求重塑車輪之前,我們應該利用已有的東西。
3、模型訓練
ML從業者可能會驚訝于將模型訓練作為系統優化的一個領域。畢竟,如果說機器學習應用中有一個領域真正依賴于ML技術,那就是訓練。但即便是這樣,系統研究也要發揮作用。
以模型并行化為例。隨著Transformers的興起,ML模型的規模都有了極大的增加。幾年前,BERT-Large僅僅只超過了345M的參數,而現在Megatron-LM擁有超過萬億的參數。
這些模型的絕對內存成本可以達到數百GB,且單一的GPU已經承受不住。傳統的解決方案,即模型并行化,采取了一個相對簡單的方法:為了分配內存成本,將模型劃分到不同的設備。
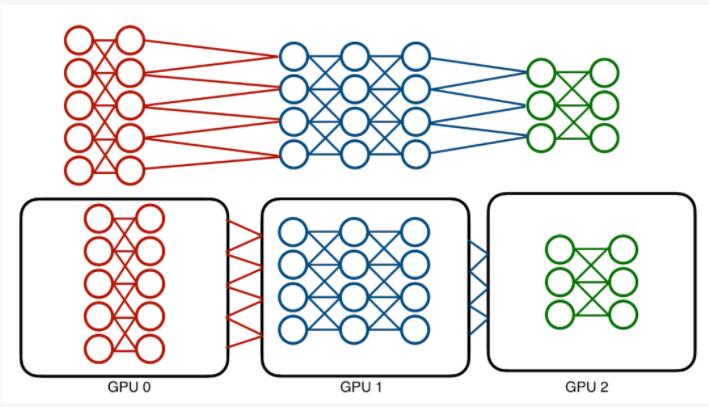
傳統的模型并行化會受到神經網絡架構順序的影響。高效并行計算的機會是有限的。
但這種技術是有問題的:模型本質是順序的,訓練它需要在各層中前后傳遞數據。一次只能使用一個層,也只能使用一個設備。這意味著會導致設備利用率不足。
系統研究如何提供幫助?
考慮一個深度神經網絡。將其分解為最基本的組件,可以將它看作一系列轉換數據的運算器。訓練僅指我們通過運算器傳遞數據,產生梯度,并通過運算器反饋梯度,然后不斷更新的過程。
在這一級別上,該模型開始進行類似于其他階段的操作——例如,CPU的指令流水線(instruction pipeline)。有兩個系統,GPipe和Hydra,試圖利用這種并行的方式來應用系統優化的可擴展性和并行性。
GPipe采用CPU指令并行的方式,將模型訓練變成一個流水線問題。模型的每個分區都被認為是流水線的不同階段,分階段進行小型批次通過分區,以最大限度地提高利用率。
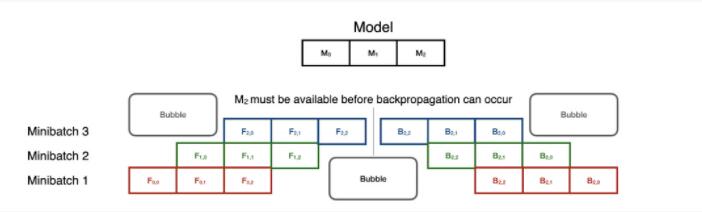
流水線并行是順序模型并行中最先進的技術,它使訓練在小型批次中并行。但同步開銷可能很昂貴,特別是在前向和后向的轉換中。
然而,請注意,在反向傳播中,階段是以相反的順序重復使用的。這意味著,在前向流水線完全暢通之前,反向傳播不能開始。盡管如此,這種技術可以在很大程度上加快模型的并行訓練:8個GPU可以加速5倍!
Hydra采取了另一種方法,將可擴展性和并行性分離成兩個不同的步驟。數據庫管理系統中的一個常見概念是 "溢出",即將多余的數據發送到內存層次的較低的級別。Hydra利用了模型并行中的順序計算,并提出不活躍的模型分區不需要在GPU上。相反,它將不需要的數據交給DRAM,將模型分區在GPU上交換,從而模擬傳統模型并執行。
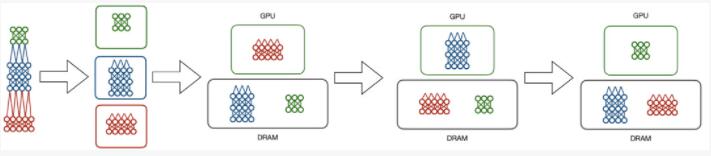
Hydra的模型溢出技術(Hydra’s model spilling technique )將深度學習訓練的成本分給DRAM而不是GPU內存,同時保持了GPU執行的加速優勢。
這使我們可以一次只使用一個GPU進行訓練模型。那么,在此基礎上引入一定程度的任務并行性是微不足道的。每個模型,無論其大小,一次只需要一個GPU,所以系統可以同時充分利用每個GPU。其結果是在8個GPU的情況下,速度提高了7.4倍以上,接近最佳狀態。
但模型并行化只是系統研究幫助模型訓練的開始。其他有前景的貢獻包括數據并行(如PyTorch DDP)、模型選擇(如Cerebro或模型選擇管理系統)、分布式框架(Spark或Ray)等等。因此,模型訓練是一個可以通過系統研究進行優化的領域。
4、Model Serving模型服務
說到底,構建機器學習模型是為了使用。模型服務和預測是機器學習實踐中最關鍵的方面之一,也是系統研究影響最大的空間之一。
預測分為兩個主要設定:離線部署和在線部署。離線部署相對簡單,它涉及不定期運行單一且大批量預測工作。常見的設定包括商業智能、保險評估和醫療保健分析。在線部署屬于網絡應用,在這種應用中,需要快速、低延遲的預測,以滿足用戶查詢的快速響應。
這兩種設定都有各自的需求和要求。一般來說,離線部署需要高吞吐量的訓練程序來快速處理大量樣本。另一方面,在線部署一般需要在單個預測上有極快的周轉時間,而不是同時有許多預測。
系統研究改變了我們處理這兩項任務的方式。以Krypton為例,它把視頻分析重新想象為 "多查詢優化"(MQO)任務的工具。
MQO并不是一個新領域——幾十年來它一直是關系型數據庫設計的一部分。總體思路很簡單:不同的查詢可以共享相關的組件,然后這些組件可以被保存和重復使用。Krypton指出,CNN的推論通常是在成批量的相關圖像上進行的,例如視頻分析。
通常情況下,視頻的特征是高幀率,這意味著連續幀往往是比較相似的。幀1中的大部分信息在幀2中仍然存在。這里與MQO有一個明顯的平行關系:我們有一系列任務,它們之間有共享的信息。
Krypton在第1幀上運行一個常規推理,然后將CNN在預測時產生的中間數據具體化,或保存起來。隨后的圖像與第1幀進行比較,以確定圖像的哪些地方發生了大的變化,哪些需要重新計算。一旦確定了補丁程序,Krypton就會通過CNN計算補丁的 "變化域",從而確定在模型的整個狀態下,哪些神經元輸出發生了變化。這些神經元會隨著變化后的數據重新運行。其余的數據則只從基本幀中重復使用!
結果是:端到端訓練提速超過4倍,數據滯后造成的精度損失很小。這種運行時間的改進對于需要長期運行的流媒體應用至關重要。
Krypton在關注模型推理方面并不是唯一的。其他作品,如Clipper和TensorFlow Extended,通過利用系統優化和模型管理技術,提供高效和健全的預測,解決了同樣的高效預測服務問題。
5、結論
機器學習已經徹底改變了我們使用數據和與數據互動的方式。它提高了企業的效率,從根本上改變了某些行業的前景。但是,為了使機器學習繼續擴大其影響范圍,某些流程必須得到改善。系統研究通過將數據庫系統、分布式計算和應用部署領域的數十年工作引入機器學習領域,能夠提高機器學習的表現。
雖然機器學習非常新穎和令人興奮,但它的許多問題卻不是。通過識別相似之處和改善舊的解決方案,我們可以使用系統來重新設計ML。
作者簡介
Kabir Nagrecha是加州大學圣地亞哥分校的博士生,由Arun Kumar指導。
13歲時,通過提前入學計劃進入大學。從那時起,就一直在工業界和學術界從事機器學習領域的研究。
曾獲得加州大學圣地亞哥分校卓越研究獎、CRA杰出本科生研究員等榮譽。目前正在蘋果的Siri小組實習。他的研究側重于通過使用系統技術實現深度學習的可擴展性。