億級流量架構演進實戰:從零構建億級流量 API 網關
這不是一個講概念的專欄,而且我也不擅長講概念,每一篇文章都是一個故事,我希望你可以通過這些故事了解我當時在實際工作中遇到問題和背后的思考,架構設計是種經驗,我有幸參與到多個億級系統的架構設計中,有所收獲的同時也希望把這些收獲分享與大家。
2013年,我在做 APP 服務端的平臺化轉型,故事就從這里開始。
在最開始做網關時,我并沒有一開始就明確說要做個 API 網關,而是做著做著發現這是個網關。因為當時我是在做服務端的平臺化轉型,最開始時只是提供了客戶端登錄、獲取插件列表、插件啟動授權幾個簡單的 API,其中客戶端登錄是通過 RSA 和 AES 非對稱加密算法來實現,登錄之后平臺頒發 token 給客戶端,有了 token 之后,客戶端就通過 OAuth 2.0 協議來調用獲取插件列表、插件啟動授權等 API,不過由于最開始沒想清楚,提供出去的 API 接口定義和格式不統一,雖然都是 json 格式,但幾乎每個 API 都有自己的的格式定義,即每個 method 在服務端都實現了一個 Servlet 服務,客戶端天天是要這接口要那接口,搞了上百個接口還是被客戶端碾著走,更糟糕的是代碼越來越臃腫還老出問題。
后來就想為何不把接口定義和格式統一了,就只提供一個 Serlvet 服務,通過解析 API 接口參數在后端進行服務的分發,這樣至少可以減少每個 API 都寫一遍 Servlet 的工作,當時的這個架構是 C/S 的架構,客戶端通過公網訪問彈內的服務器,這個功能上線其實是上線了一個新的 API,之后客戶端的新功能都必須使用新的 API,老的 API 在客戶端線上的版本逐步下線后,服務端再對老的 API 進行清理,當整個架構逐漸形成之后,服務端的開發效率得到了顯著的提升,也是這時,我覺得這其實是個網關的雛形,所以整個平臺演進的過程,在這一階段我總結為:統一服務接口。
1. 什么是網關?
現在來談談 API 網關,關于 API 網關的定義,有很多的說法,其字面意思就是系統的統一 API 入口。說白了, 就是將客戶端的所有請求統一通過 API 網關接入服務端,并完成認證、授權、安全、流控、熔斷、調度、轉發、監 控等處理過程。API 網關的價值,就是為實現更加安全、高效和穩定的 API 調用提供服務保障。
就我當時負責的平臺而言,統一了服務接口還不能說是做了一個網關,因為這僅僅是實現了網關統一接入組件的一個點,那網關的統一接入組件又是什么?下面我們先聊下網關的每一個組件,以及每一個組件的職責。
API 網關的核心組件
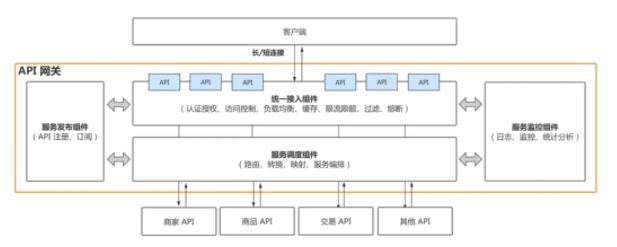
從 API 調用的過程來看,我把 API 網關劃分為四個組件:
-
統一接入組件,管理所有的請求接入,負責認證鑒權、安全、校驗、限流、降級和熔斷等,它就像 API 網關的護城河;
-
服務調度組件,管理請求的路由和調度,負責協議解析、路由、轉換、映射和服務編排等,它是外部請求調度后端服務的中間樞紐,也是 API 網關的大腦(只有大腦才知道哪個 API 應去哪里調度);
-
服務發布組件,管理 API 的注冊和訂閱,負責服務發現、服務訂閱和服務更新等,它是 API 網關的心臟(心臟會不斷的把 API 信息同步給網關);
-
服務監控組件,是對所有 API 請求的統一監控,負責日志、監控、告警和統計分析等,它是 API 網關的守衛。
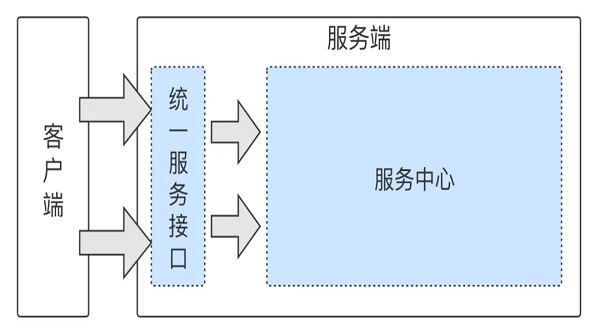
這里我畫了一張 API 網關的架構示意圖。
統一接入組件
當時,統一了服務接口的確實現了 API 的統一接入點,但很快也暴露出了新的問題 —— 這個接入點很快就過熱了,之前的登錄 API 和插件 API 都是分開的,現在統一后,有些 API 出故障后影響面很大,印象非常深刻的一次是客戶端上線了一個定時查詢待出庫訂單數的功能,結果整個服務端全面打爆,服務重啟很快又被打爆,這其實是統一之后服務端沒有及時跟上必要的限流、熔斷等防御手段。
所以,那次之后,服務端進行了第一次的系統拆分 —— 網關和服務中心。
2. 分層架構
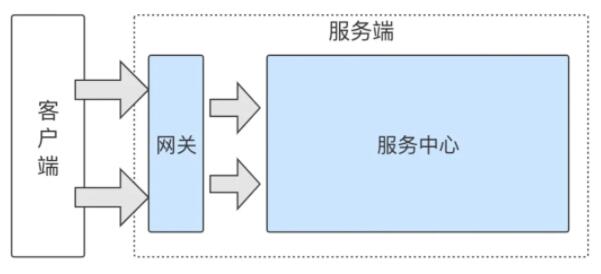
平臺提供的所有端能力進行服務下沉,搭建服務中心新系統,原系統作為網關將重點負責 API 接入、安全、流控、熔斷、路由、分發、調度、監控等功能。除了垂直拆分,還做了水平拆分,即對平臺 API 和業務 API 進行了隔離,簡單說,就是提供了兩個 Servlet。當時,還沒有微服務化的概念,只是想著隔離平臺調用與業務調用的相互影響,能解決當時的問題。后來,在認識了微服務之后,有一種后知后覺的感覺,這次系統的拆分使得平臺整體的穩定性得到很大的提升,不過后來玩微服務有點玩壞了,而這就是后話了。
重構之后的網關架構比較整潔,在實現上,統一接入組件采用的是類似于責任鏈的方式,由于這時期的 API 調用主要是 HTTP 請求,所以網關是基于 Servlet 來提供 API 服務的,通過攔截器進行安全、流控、熔斷等功能的實現。
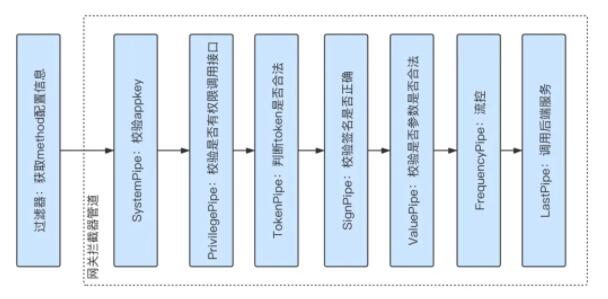
其中 FrequencyPipe 是負責流控和熔斷的攔截器,這里必須得說一下,畢竟是這里栽了跟頭。常見的限流算法有漏斗算法和令牌桶算法,我的理解,令牌桶常用于控制并發,無論何時,令牌的總數是固定的,每次調用開始都需要申請,調用結束都需要釋放;漏桶適用于控制 QPS,漏桶可以在每秒生成 m 個令牌,每次調用開始都需要申請,但調用結束不需要釋放,不過問題就是如果上一秒的調用沒有結束,實際調用會大于當前生成的 m 個令牌控制的調用量。
在實現上,當時了解 Guava 的 RateLimiter 與 Semaphore 都可以實現,通過對比,網關使用的是 Guava 的 Semaphore 令牌桶策略來控制并發數,不過,遇到的問題就是每次重啟都會有瞬時的流量超過并發數。而在后來隨著微服務與網關越來越火,又有 Hystrix 或 Sentinel 提供了更強大的功能,比如 Hystrix 的線程熔斷和 Sentinel 的異常熔斷等等。
3. 高可用架構
日志的作用不言而言,網關的調用日志是必不可少的。而且下定決心要做全鏈路的日志,是已經被各種查問題逼的不勝其煩的情況下了,你能想象到的,尤其是莫名被拉到一個群里,被@有個問題要查網關一次調用的一個參數對不對或有沒有,沒有個日志服務平臺,不僅要親自操刀上陣,更悲催的是還只能去每臺服務器上去找日志。
服務端在拆分了網關和服務中心之后,系統都開始往微服務架構的方向演進,一次 API 調用就需要有全局唯一的標識進行串聯,網關采用的是 UUID,在 API 每次調用時都會生成一個 UUID 傳遞給上游并返回給客戶端,這樣當有問題需要查詢時,就可以通過 UID 準確查找相關日志了。
怎么進行日志的采集、查詢、統計,以及如何基于日志實現監控告警?
通常來講,大多數系統打印日志采用的是 Log4j,網關也是,再通過集團提供的日志服務系統,比如 Scribe、Flume 等進行日志采集,然后就可以在日志系統或監控系統里看到數據了。
不過,日志采集看著簡單,做起來還是個技術活,網關的調用量本身是很大的,先不看記錄網關日志會有多大的存儲量,關鍵點是看打印日志會對網關性能有多大的影響。
首先談一下 Log4j,我們知道 Log4j 1.x 會引發線程 BLOCKED,所以 Log4j 1.x 不適合高并發的場景,解決方法一種是升級到 log4j2 或者更換為 logback,另一種是通過設置 BufferedIO 或者使用 AsyncAppender 來緩解出現 BLOCKED 的概率。遺憾的是,網關采用的是后者,這主要是依賴沖突導致的,不過這只是做日志采集里的一個小點。
基于 MMap、Kafka、Storm、ElasticSearch 實現日志服務平臺
除此之外,網關自己還實現了一套日志服務系統,這主要是開放給平臺用戶的,當時集團的日志系統還不對外開發,所以自己就又搞了一套。
當時技術選型沒有選擇 Scribe、Flume,而是自己基于 MMap 技術來實現,這也受限于服務器 agent 權限,所以,基本思路是通過 Kafka 進行日志收集,然后 Storm 接收后寫到 ElasticSearch 提供服務查詢,這里有個技術點,最開始寫日志是直接發 Kafka,不過線上發現網絡的抖動會影響寫 Kafka 的 RT,后來,我們嘗試了2種方案,第一種是采用線程池異步寫,另一種是基于 MMap 技術將日志先落盤,然后再異步的讀文件發 Kafka,相比之下,第二種方案更不會丟數據。
日志打不好,找問題不僅抓瞎,弄不好系統還要撲街?
說到最后,也談談打日志出的問題。
第一,throw Exception,這點尤其注意,微服務架構里,如果服務提供方服務異常,一定不要將異常堆棧也傳給服務調用方,雖然通過異常信息可以快速定位問題,但異常信息會占用大量的網絡資源,嚴重的就變成服務不可用了,這里,我是有血的教訓的,所以,我推薦的方式是定義返回結果對象里的返回值和錯誤碼。
基于多維度的限流熔斷策略,構建實時 API 成功率監控能力
上文說了全鏈路日志和實時監控,本文就說下限流降級,這里都是故事。網關系統,需要對調用 API 進行實時的性能監控和錯誤碼監控,由于是實時計算,所以采用了 NoSQL 來緩存數據,因為是對 API 進行監控,所以將 API 接口名作為緩存 Key,可當 API 調用異常猛增時,緩存熱定問題就出現了,很快就出現了 failover,然后服務不可用。所以,在處理數據時一定要考慮好數據熱點問題,無論是 NoSQL 還是 MySQL。
4. 總結
言而總之,本篇文章重點講述了API網關的統一接入、分層架構、高可用架構。下篇文章,我將繼續介紹流量調度的配置中心、泛化調用。如果你覺得有收獲,歡迎你把今天的內容分享給更多的朋友。