億級流量系統(tǒng)架構(gòu)之如何設(shè)計承載百億流量的高性能架構(gòu)
我們面對的是日益增多和復(fù)雜的各種業(yè)務(wù)系統(tǒng),我們面對的是不斷增加的系統(tǒng)用戶,我們面對的是即將迎來每天百億級的高并發(fā)流量。
給大家先說下當(dāng)時的系統(tǒng)部署情況,數(shù)據(jù)庫那塊一共部署了8主8從,也就是16臺數(shù)據(jù)庫服務(wù)器,每個庫都是部署在獨立的數(shù)據(jù)庫服務(wù)器上的,而且全部用的是物理機,機器的配置,如果沒記錯的話,應(yīng)該是32核+128G+SSD固態(tài)硬盤。
為啥要搞這么多物理機,而且全部都是高配置呢?不知道大家發(fā)現(xiàn)沒有,目前為止,我們最大的依賴就是MySQL!
之前給大家解釋過,在當(dāng)時的背景下,我們要對涌入的億級海量數(shù)據(jù),實時的運行數(shù)百個復(fù)雜度為幾百行到上千行的大SQL,幾秒鐘就要出分析結(jié)果。
這個是沒有任何一個開源系統(tǒng)可以做到的,Storm不行,Spark Streaming也不行,因此必須得基于MySQL純自研一套數(shù)據(jù)平臺架構(gòu)出來,支撐這個需求場景。
所以,只有MySQL是可以支撐如此復(fù)雜的SQL語句完美運行的,因此我們在早期必須嚴重依賴于MySQL作為數(shù)據(jù)的存儲和計算,將源源不斷涌入的數(shù)據(jù)放在MySQL中進行存儲,接著基于數(shù)據(jù)分片計算的架構(gòu)來高性能的運行復(fù)雜大SQL基于MySQL來進行計算。
所以大家就知道了,MySQL目前為止是這套系統(tǒng)的命脈。在當(dāng)時的場景下,每臺數(shù)據(jù)庫服務(wù)器都要抗住每秒2000左右的并發(fā)請求,高峰期的CPU負載、IO負載其實都非常高,而且主庫和從庫的延遲在高峰期已經(jīng)有點嚴重,會達到秒級了。
在我們的生產(chǎn)系統(tǒng)的實際線上運行情況下,單臺MySQL數(shù)據(jù)庫服務(wù)器,我們一般是不會讓他的高峰期并發(fā)請求超過2000/s的,因為一旦達到每秒幾千的請求,根據(jù)當(dāng)時線上的資源負載情況來看,很可能MySQL服務(wù)器負載過高會宕機。
所以此時就有一個很尷尬的問題了,假如說每天億級流量的場景下,需要用8主8從這么多高配置的數(shù)據(jù)庫服務(wù)器來抗,那如果是幾十億流量呢?甚至如果是百億流量呢?難道不停的增加更多的高配置機器嗎?
要知道,這種高配置的數(shù)據(jù)庫服務(wù)器,如果是物理機的話,是非常昂貴的!
之前給大家簡單介紹過項目背景,這整套大型系統(tǒng)組成的商業(yè)級平臺,涉及到N多個系統(tǒng),這個數(shù)據(jù)產(chǎn)品只是一個子產(chǎn)品而已,不可能為了這么一個產(chǎn)品,投入大量的預(yù)算通過不停的砸高配置的機器來撐住更高的并發(fā)寫入。
我們必須用技術(shù)的手段來重構(gòu)系統(tǒng)架構(gòu),盡量用有限的機器資源,通過最優(yōu)秀的架構(gòu)來抗住超高的并發(fā)寫入壓力!
計算與存儲分離的架構(gòu)
這個架構(gòu)里的致命問題之一,就是數(shù)據(jù)的存儲和計算混在了一個地方,都在同一個MySQL庫里!
大家想想,在一個單表里放上千萬數(shù)據(jù),然后你每次運行一個復(fù)雜SQL的時候,SQL里都是通過索引定位到表中他要計算的那個數(shù)據(jù)分片。這樣搞合適嗎?
答案顯然是否定的!因為表里的數(shù)據(jù)量很大,但是你每次實際SQL運算只要對其中很小很小的一部分數(shù)據(jù)計算就可以了,實際上我們在生產(chǎn)環(huán)境中實踐過后發(fā)現(xiàn),如果你在一個大表運行一個復(fù)雜SQL,哪怕通過各種索引保證定位到的數(shù)據(jù)量很少,因為表數(shù)據(jù)量過大,也是會導(dǎo)致性能直線下降的。
因此第一件事情,先將數(shù)據(jù)的存儲和計算這兩件事情拆開。
我們當(dāng)時的思路如下:
數(shù)據(jù)直接寫入一個存儲,僅僅只是簡單的寫入即可
然后在計算的時候從數(shù)據(jù)存儲中提取你需要的那個數(shù)據(jù)分片里的可能就一兩千條數(shù)據(jù),寫入另外一個專用于計算的臨時表中,那個臨時表內(nèi)就這一兩千條數(shù)據(jù)
然后運行你的各種復(fù)雜SQL即可。
bingo!一旦將數(shù)據(jù)存儲和計算兩個事情拆開,架構(gòu)里可以發(fā)揮的空間就大多了。
首先你的數(shù)據(jù)存儲只要支撐高并發(fā)的寫入,日百億流量的話,高峰每秒并發(fā)會達到幾十萬,撐住這就可以了。然后支持計算引擎通過簡單的操作從數(shù)據(jù)存儲里提取少量數(shù)據(jù)就OK。
太好了,這個數(shù)據(jù)存儲就可以PASS掉MySQL了,就這點兒需求,你還用MySQL干什么?兄弟!
當(dāng)時我們經(jīng)過充分的技術(shù)調(diào)研和選型之后,選擇了公司自研的分布式KV存儲系統(tǒng),這套KV存儲系統(tǒng)是完全分布式的,高可用,高性能,輕量級,支持海量數(shù)據(jù),而且之前經(jīng)歷過公司線上流量的百億級請求量的考驗,絕對沒問題。主要支持高并發(fā)的寫入數(shù)據(jù)以及簡單的查詢操作,完全符合我們的需求。
這里給大家提一句,其實業(yè)內(nèi)很多類似場景會選擇hbase,所以大家如果沒有公司自研的優(yōu)秀kv存儲的話,可以用選用hbase也是沒問題的,只不過hbase有可能生產(chǎn)環(huán)境會有點坑,需要大家對hbase非常精通,合理避坑和優(yōu)化。
輕量級的分布式kv系統(tǒng),一般設(shè)計理念都是支持一些簡單的kv操作,大量的依托于內(nèi)存緩存熱數(shù)據(jù)來支持高并發(fā)的寫入和讀取,因為不需要支持MySQL里的那些事務(wù)啊、復(fù)雜SQL啊之類的重量級的機制。
因此在同等的機器資源條件下,kv存儲對高并發(fā)的支撐能力至少是MySQL的數(shù)倍甚至數(shù)十倍。
就好比說,大家應(yīng)該都用過Redis,Redis普通配置的單機器撐個每秒幾萬并發(fā)都是ok的,其實就是這個道理,他非常的輕量級,轉(zhuǎn)為高并發(fā)而生。
然后,我們還是可以基于MySQL中的一些臨時表來存放kv存儲中提取出來的數(shù)據(jù)分片,利用MySQL對復(fù)雜SQL語法的支持來進行計算就可以了。也就是說,我們在這個架構(gòu)里,把kv系統(tǒng)作為存儲,把MySQL用做少量數(shù)據(jù)的計算。
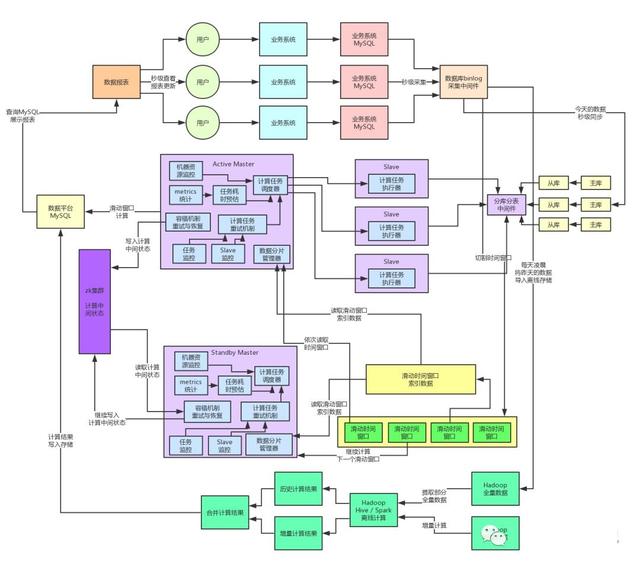
此時我們在系統(tǒng)架構(gòu)中引入了分布式kv系統(tǒng)來作為我們的數(shù)據(jù)存儲,每天的海量數(shù)據(jù)都存放在這里就可以了,然后我們的Slave計算引擎每次計算,都是根據(jù)那個數(shù)據(jù)分片從kv存儲中提取對應(yīng)的數(shù)據(jù)出來放入MySQL內(nèi)的一個臨時表,接著就是對那個臨時表內(nèi)的一兩千條數(shù)據(jù)分片運行各種復(fù)雜SQL進行計算即可。
大家看上面的圖,此時通過這一步計算與存儲架構(gòu)的分離,我們選用了適合支撐高并發(fā)的kv集群來抗住每天百億級的流量寫入。然后基于MySQL作為臨時表放入少量數(shù)據(jù)來進行運算。這一個步驟就直接把高并發(fā)請求可以妥妥的抗住了。
而且分布式kv存儲本來就可以按需擴容,如果并發(fā)越來越高,只要擴容增加機器就可以了。此時,就完成了架構(gòu)的一個關(guān)鍵的重構(gòu)步驟。
自研純內(nèi)存SQL計算引擎
下一步,我們就要對架構(gòu)追求極致!因為此時我們面臨的一個痛點就在于說,其實僅僅只是將MySQL作為一個臨時表來計算了,主要就是用他的復(fù)雜SQL語法的支持。
但是問題是,對MySQL的并發(fā)量雖然大幅度降低了,可是還并不算太低。因為大量的數(shù)據(jù)分片要計算,還是需要頻繁的讀寫MySQL。
此外,每次從kv存儲里提取出來了數(shù)據(jù),還得放到MySQL的臨時表里,還得發(fā)送SQL去MySQL里運算,這還是多了幾個步驟的時間開銷。
因為當(dāng)時面臨的另外一個問題是,每天請求量大,意味著數(shù)據(jù)量大,數(shù)據(jù)量大意味著時間分片的計算任務(wù)負載還是較重。
總是這么依賴MySQL,還要額外維護一大堆的各種臨時表,可能多達幾百個臨時表,你要維護,要注意他的表結(jié)構(gòu)的修改,還有分庫分表的一些運維操作,這一切都讓依賴MySQL這個事兒顯得那么的多余和麻煩。
因此,我們做出決定,為了讓架構(gòu)的維護性更高,而且將性能優(yōu)化到極致,我們要自己研發(fā)純內(nèi)存的SQL計算引擎。
其實如果你要自研一個可以支持MySQL那么復(fù)雜SQL語法的內(nèi)存SQL計算引擎,還是有點難度和麻煩的。但是在我們仔細研究了業(yè)務(wù)需要的那幾百個SQL之后,發(fā)現(xiàn)其實問題沒那么的復(fù)雜。
因為其實一般的數(shù)據(jù)分析類的SQL,主要就是一些常見的功能,沒有那么多的怪、難、偏的SQL語法。
因此我們將線上的SQL都分析過一遍之后,就針對性的研發(fā)出了僅僅支持特定少數(shù)語法的SQL引擎,包括了嵌套查詢組件、多表關(guān)聯(lián)組件、分組聚合組件、多字段排序組件、少數(shù)幾個常用函數(shù),等等。
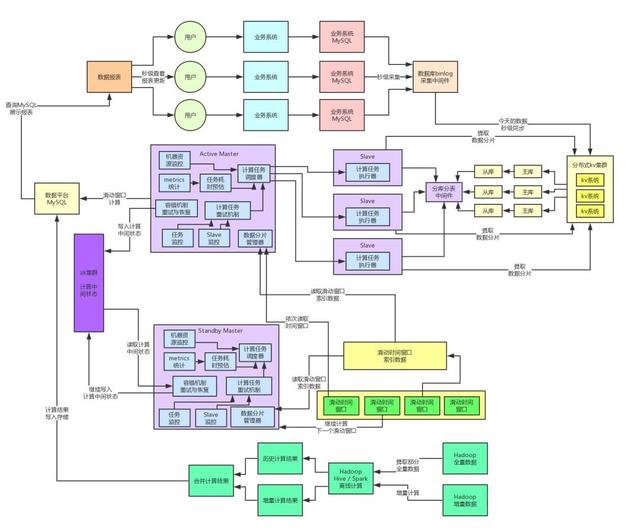
接著就將系統(tǒng)徹底重構(gòu)為不再依賴MySQL,每次從kv存儲中提取一個數(shù)據(jù)分片之后,直接放入內(nèi)存中,然后用我們自研的SQL計算引擎來在純內(nèi)存里針對一個數(shù)據(jù)分片執(zhí)行各種復(fù)雜的SQL。
這個純內(nèi)存操作的性能,那就不用多說了,大家應(yīng)該都能想象到了,基本上純內(nèi)存的SQL執(zhí)行,都是毫秒級的,基本上一個時間分片的運算全部降低到毫秒級了。性能進一步得到了大幅度的提升,而且從此不再依賴MySQL了,不需要維護復(fù)雜的分庫分表等等東西。
這套架構(gòu)上線之后,徹底消除了對MySQL的依賴,理論上,無論多大的流量過來,都可以通過立馬擴容kv集群以及擴容Slave計算集群來解決,不需要依賴MySQL的分庫分表、幾百張臨時表等比較耗費人力、麻煩而且坑爹的方案了。而且這種純內(nèi)存的計算架構(gòu)直接把計算性能提升到了毫秒級。
而且消除對MySQL的依賴有另外一個好處,數(shù)據(jù)庫的機器總是要高配置的,但是Slave機器主要4核8G的普通虛擬機就夠了,分布式系統(tǒng)的本質(zhì)就是盡量利用大量的廉價普通機器就可以完成高效的存儲和計算。
因此在百億流量的負載之下,我們Slave機器部署了幾十臺機器就足夠了,那總比你部署幾十臺昂貴的高配置MySQL物理機來的劃算多了!
MQ削峰以及流量控制
其實如果對高并發(fā)架構(gòu)稍微了解點的同學(xué)都會發(fā)現(xiàn),這個系統(tǒng)的架構(gòu)中,針對高并發(fā)的寫入這塊,還有一個比較關(guān)鍵的組件要加入,就是MQ。
因為我們?nèi)绻麘?yīng)對的是高并發(fā)的非實時響應(yīng)的寫入請求的話,完全可以使用MQ中間件先抗住海量的請求,接著做一個中間的流量分發(fā)系統(tǒng),將流量異步轉(zhuǎn)發(fā)到kv存儲中去,同時這個流量分發(fā)系統(tǒng)可以對高并發(fā)流量進行控制。
比如說如果瞬時高并發(fā)的寫入真的導(dǎo)致后臺系統(tǒng)壓力過大,那么就可以由流量分發(fā)系統(tǒng)自動根據(jù)我們設(shè)定的閾值進行流量控制,避免高并發(fā)的壓力打垮后臺系統(tǒng)。
而且在這個流控系統(tǒng)中,我們其實還做了很多的細節(jié)性的優(yōu)化,比如說數(shù)據(jù)校驗、過濾無效數(shù)據(jù)、切分數(shù)據(jù)分片、數(shù)據(jù)同步的冪等機制、100%保證數(shù)據(jù)落地到kv集群的機制保障,等等。
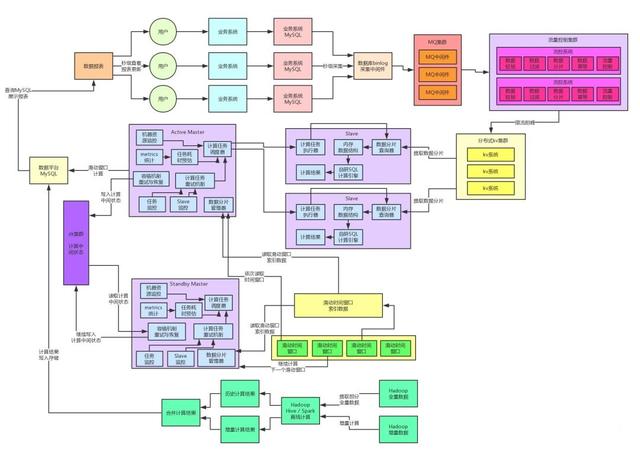
公司的MQ集群天然都支撐過大流量寫入以及高并發(fā)請求,因此MQ集群那個層面抗住高并發(fā)并不是什么問題,再高的并發(fā)按需擴容就可以了,然后我們自己的流控系統(tǒng)也是集群部署的,線上采用的是4核8G的虛擬機,因為這個機器不需要太高的配置。
流控系統(tǒng),基本線上我們一般保持在每臺機器承載每秒小三千左右的并發(fā)請求,百億流量場景下,高峰每秒并發(fā)在每秒小幾十萬的級別,因此這個流控集群部署到幾十臺機器就足夠了。
而公司的kv集群也是天然支撐過大流量高并發(fā)寫入的,因此kv集群按需擴容,抗住高并發(fā)帶流量的寫入也不是什么問題,而且這里其實我們因為在自身架構(gòu)層面做了大量的優(yōu)化(存儲與計算分離的關(guān)鍵點),因此kv集群的定位基本就是online storage,一個在線存儲罷了。
通過合理、巧妙的設(shè)計key以及value的數(shù)據(jù)類型,使得我們對kv集群的讀寫請求都是優(yōu)化成最最簡單的key-value的讀寫操作,天然保證高并發(fā)讀寫是沒問題的。
另外稍微給大家一點點的劇透,后面講到全鏈路99.99%高可用架構(gòu)的時候,這個流控集群會發(fā)揮巨大的作用,他是承上啟下的一個效果,前置的MQ集群故障的高可用保障,以及后置的KV集群故障的高可用保障,都是依靠流控集群來實現(xiàn)的。
數(shù)據(jù)的動靜分離架構(gòu)
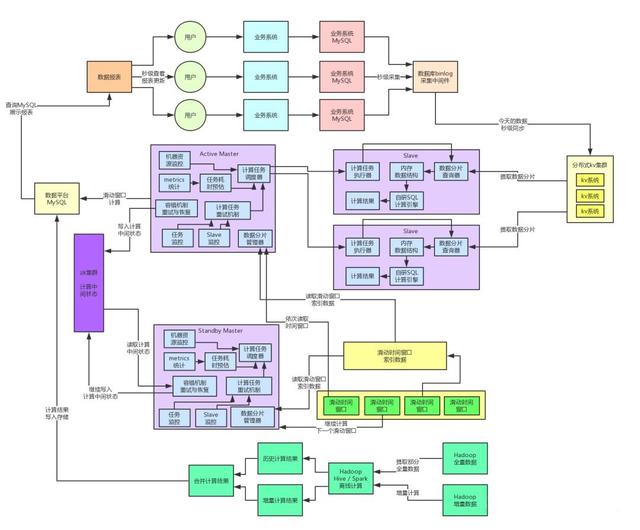
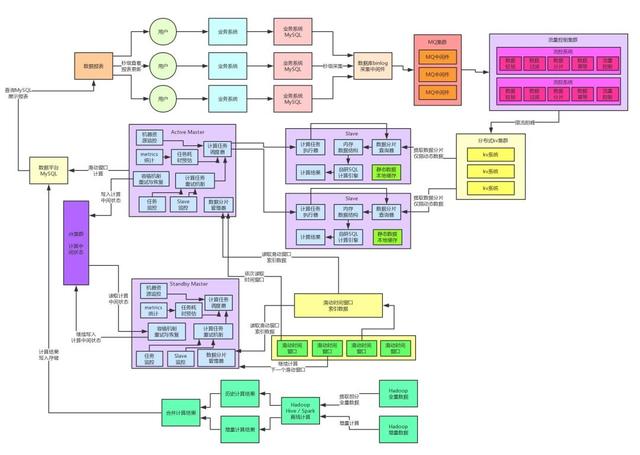
在完成上述重構(gòu)之后,我們又對核心的自研內(nèi)存SQL計算引擎做了進一步的優(yōu)化。因為實際生產(chǎn)環(huán)境運行過程中,我們發(fā)現(xiàn)了一個問題:就是每次如果Slave節(jié)點都是對一個數(shù)據(jù)分片提取相關(guān)聯(lián)的各種數(shù)據(jù)出來然后進行計算,其實是沒必要的!
給大家舉個例子,如果你的SQL要對一些表進行關(guān)聯(lián)計算,里面涉及到了一些大部分時候靜態(tài)不變的數(shù)據(jù),那些表的數(shù)據(jù)一般很少改變,因此沒必要每次都走網(wǎng)絡(luò)請求從kv存儲里提取那部分數(shù)據(jù)。
我們其實完全可以在Slave節(jié)點對這種靜態(tài)數(shù)據(jù)做個輕量級的cache,然后只有數(shù)據(jù)分片里對應(yīng)的動態(tài)改變的數(shù)據(jù)才從kv存儲來提取數(shù)據(jù)。
通過這個數(shù)據(jù)的動靜分離架構(gòu),我們基本上把Slave節(jié)點對kv集群的網(wǎng)絡(luò)請求降低到了最少,性能提升到了最高。大家看下面的圖。
階段性總結(jié)
這套架構(gòu)到此為止,基本上就演進的比較不錯了,因為超高并發(fā)寫入、極速高性能計算、按需任意擴容,等各種特性都可以支持到了,基本上從寫入到計算,這兩個步驟,是沒什么太大的瓶頸了。
而且通過自研內(nèi)存SQL計算引擎的方案,將我們的實時計算性能提升到了毫秒級的標準,基本已經(jīng)達到極致。
下一步展望
下一步,我們就要看看這個架構(gòu)中的左側(cè),還有一個MySQL呢!
首先是實時計算鏈路和離線計算鏈路,都會導(dǎo)入大量的計算結(jié)果到那個MySQL中。
其次面向數(shù)十萬甚至上百萬的B端商家時,如果是實時展示數(shù)據(jù)分析結(jié)果的話,一般頁面上會有定時的JS腳本,每隔幾秒鐘就會發(fā)送請求過來加載最新的數(shù)據(jù)計算結(jié)果。
因此實際上那個專門面向終端用戶的MySQL也會承受極大的數(shù)據(jù)量的壓力,高并發(fā)寫入的壓力以及高并發(fā)查詢的壓力。