













當世界模型被用于sim2real:機器人通過視覺想象和交互嘗試來學習
本文轉自雷鋒網,如需轉載請至雷鋒網官網申請授權。
人類是如何掌握這么多技能的呢?好吧,最初我們并非如此,但從嬰兒時期開始,我們通過自監督發覺并練習越來越復雜的技能。但這種自監督并不是隨機的——兒童發展文獻表明,嬰兒利用他們先前的經驗,通過互動和感官反饋,對移動性、吸吮性、抓握性和消化性等可供性(affordance,也譯作功能可供性、承擔特質、直觀功能、預設用途、可操作暗示、示能性等,指事物能夠提示其可以幫助人們做什么的一種屬性或特征)進行定向探索。這種類型的定向探索允許嬰兒在既定環境中學習可以做什么以及如何做。那么,在機器人學習系統中,我們是否也可以實例一個類似于可供性定向探索的策略?
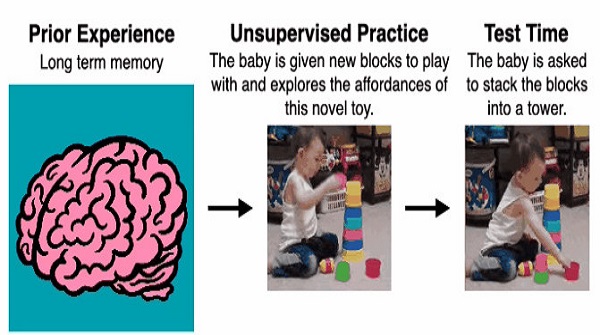
如下圖所示。在左側,我們先收集了由機器人完成各種任務的視頻,比如打開和關閉抽屜、抓取和移動物體。在右側,我們放置了一個機器人從未見過的蓋子。機器人被給予一小段時間來熟悉這個新物體,之后它將獲得一個目標圖像,并負責使場景匹配這個圖像。機器人如何在沒有任何外部監督的情況下迅速學會操控環境并抓住蓋子?

為此,我們面臨幾項挑戰。當機器人被置于一個新環境時,它必須能夠利用其先前的知識來思考環境可能提供的潛在有用行為。然后,機器人必須能夠實際地練習這些行為。為了在新的環境中改進自己,機器人必須能夠在沒有外部獎勵的情況下以某種方式評估自己的成功。
如果我們能可靠地戰勝這些挑戰,就能為一個強有力的循環打開大門。在這個循環中,我們的智能體使用先前的經驗來收集高質量的交互數據,然后進一步增長它們以往的經驗,不斷提高它們的潛在效用!
1、VAL:視覺運動可供性學習
我們的方法,視覺運動可供性學習(Visuomotor Affordance Learning,簡稱VAL),解決了這些挑戰。在VAL中,我們首先假設可以獲得機器人在各種環境中展示可供性的先驗數據集。至此,VAL進入了一個離線階段,該階段使用這些信息學習 1)想象新環境中有用的可供性生成模型,2) 用于有效探索這些可供性的強大離線策略,以及 3) 改進該策略的自我評估度量。最后,VAL已準備好進入在線階段。智能體被放置在一個新的環境中,現在可以使用這些學到的功能來進行自監督的微調。整個框架如下圖所示。隨后,我們將深入探討離線和在線階段的技術細節。

2、VAL:離線階段
給定一個展示各種環境可供性的先驗數據集,VAL在三個離線步驟中消化這些信息:用于處理高維真實世界數據的表示學習,在未知環境中實現自監督練習的可供性學習,用于獲得高性能的初始策略以加快在線學習效率的行為學習。
首先,VAL使用矢量量化變分自動編碼器(VQVAE)學習該數據的低維表示。這個過程將我們的48x48x3圖像壓縮到144維的潛在空間。
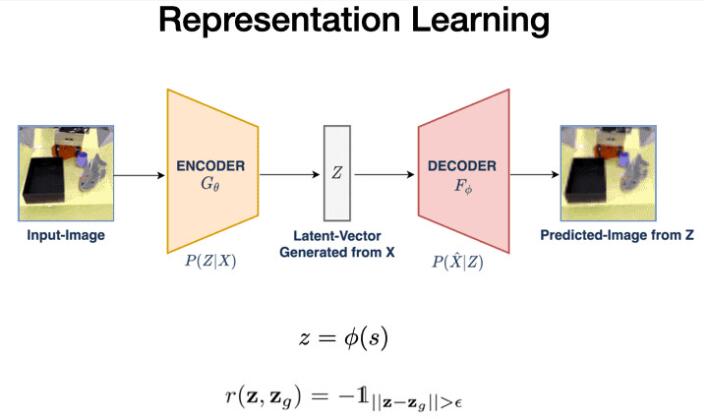
在這個潛在空間的距離是有意義的,為我們自我評價成功的關鍵機制鋪平了道路。給定當前圖像s和目標圖像g,我們將它們編碼進潛在空間,并設定它們可以獲得獎勵的距離閾值。
隨后,我們還將使用這個表示作為我們潛在空間的策略和Q函數。
接下來,VAL 通過在潛在空間中訓練 PixelCNN 來學習可供性模型,以學習以環境圖像為條件的可達狀態分布。這是通過最大化數據的似然 p(sn|s0) 來完成的。我們使用這種可供性模型進行定向探索和重新標記目標。
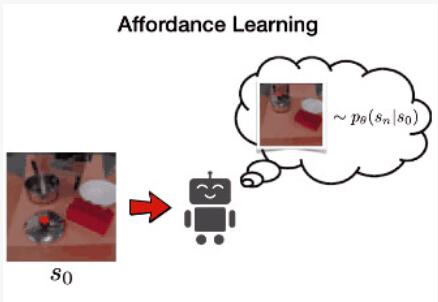
可供性模型如右圖所示。在該圖的左下方,我們看到條件圖像包含一個罐子,右上方解碼的潛在目標顯示了不同位置的蓋子。這些連貫的目標將允許機器人進行連貫的探索。
最后在離線階段,VAL必須從離線數據中學習行為,然后可以通過額外的在線交互式數據收集進行改進。
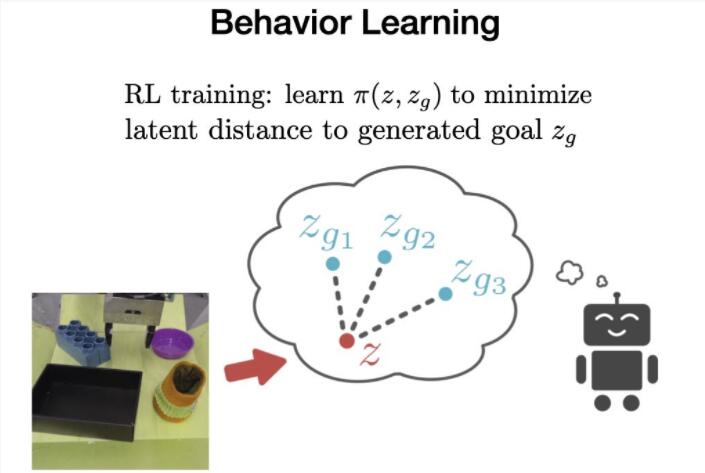
為了實現這一點,我們使用加權強化學習算法(Advantage Weighted Actor Critic)在先驗數據集上訓練目標條件策略,這是一種專為離線訓練和在線微調而設計的算法。
3、VAL:在線階段
現在,當VAL被放置在一個未見過的環境中時,它使用其先前的知識來想象有用可供性的視覺表示,通過嘗試實現這些可供性來收集有用的交互數據,使用其自我評估指標更新其參數,并一直重復整個過程。
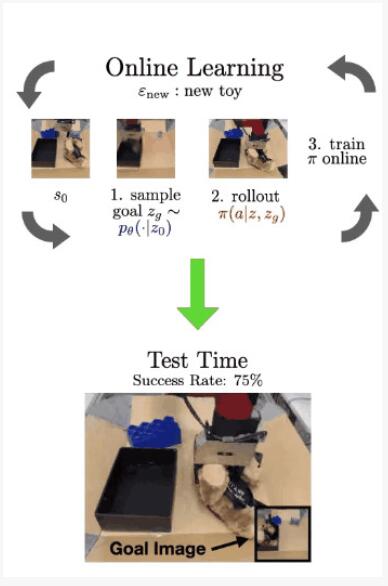
在這個真實的例子中,在左側我們看到了環境的初始狀態,它提供了打開抽屜和其他任務的功能。
在步驟1中,可供性模型對潛在目標進行采樣。通過解碼目標(使用 VQVAE 解碼器,在RL期間從未實際使用過,因為我們完全在潛在空間中操作),我們可以看到可供性是打開抽屜。
在步驟2中,我們使用具有采樣目標的訓練策略。我們看到它成功打開了抽屜,實際上它拉太大力了,直接把抽屜拉了出來。但這為RL算法進一步微調和完善其策略提供了極其有用的交互。
在線微調完成后,我們現在可以評估機器人在每個環境中實現相應的未見過的目標圖像的能力。
4、真實環境評估
我們在五個真實的測試環境中評估我們的方法,并評估VAL在無監督微調之前和五分鐘之后完成環境提供的特定任務的能力。
每個測試環境至少包含一個未見過的交互對象和兩個隨機抽樣的干擾對象。例如,當訓練數據中有打開和關閉抽屜時,新的抽屜有沒見過的把手。
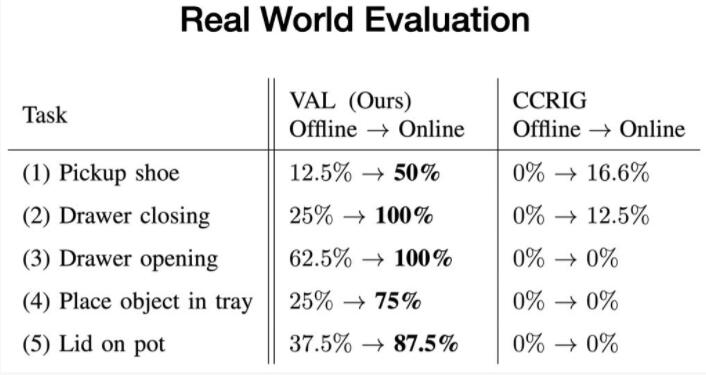
每個測試,我們都從離線訓練策略開始,它每次完成任務的方式都不一致。然后,我們使用我們的可供性模型收集更多經驗來采樣目標。最后,我們評估經過微調的策略,它能始終一致地完成任務。

我們發現,在這些環境中,VAL在離線訓練后始終顯示出有效的零樣本泛化,隨后通過其可供性導向的微調方案快速改進。與此同時,先前的自監督方法在這些新環境中幾乎沒有改善。這些令人興奮的結果表明,像VAL這樣的方法具有使機器人成功操縱的潛力,遠遠超出它們現在習慣的有限的出廠設置。
我們的2,500個高質量機器人交互軌跡數據集,涵蓋20個抽屜把手,20個鍋把手,60個玩具和60個干擾物,現已在我們的網站上公開發布。
數據集地址:https://sites.google.com/view/val-rl/datasets
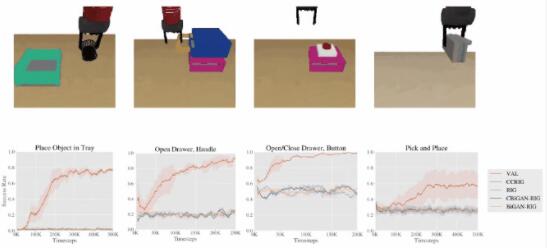
5、模擬評估與代碼
為了進一步分析,我們在具有視覺和動態變化的程序生成的多任務環境中運行 VAL。場景中的對象以及它們的顏色和位置都是隨機的。媒介可以用把手打開抽屜、抓取物體并移動它們、按按鈕打開隔間等等。
給定機器人一個包含各種環境的先驗數據集,并根據其在以下測試環境中的微調能力進行評估。
同樣,給定一個單一的非策略數據集,我們的方法可以快速學習高級操作技能,包括抓取物體、打開抽屜、移動物體,以及對各種新對象使用工具。
環境和算法代碼均已公開,請查閱我我們的代碼庫。
代碼地址:https://github.com/anair13/rlkit/tree/master/examples/val
6、未來的工作
就像計算機視覺和自然語言處理等領域的深度學習是由大型數據集和泛化驅動的一樣,機器人可能需要從類似規模的數據中學習。正因為如此,離線強化學習的改進對于使機器人能夠利用大型先驗數據集至關重要。此外,這些離線策略要么需要快速的非自主微調,要么需要完全自主的微調,以便在現實世界中部署是可行的。最后,一旦機器人獨立運行,我們就能獲得源源不斷的新數據,這就強調了終身學習算法的重要性和價值。























