LeCun新作:分層世界模型,數據驅動的人型機器人控制
有了大模型作為智能上的加持,人型機器人已然成為新的風口。
科幻電影中「安能辨我不是人」的機器人似乎已經越來越近了。
不過,要想像人類一樣思考和行動,對于機器人,特別是人型機器人來說,仍是個艱巨的工程問題。
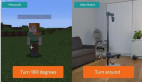
就拿簡單的學走路來說,利用強化學習來訓練可能會演變成下面這樣:

道理上沒什么問題(遵循獎勵機制),上樓梯的目標也達到了,除了過程比較抽象,跟大部分人類的行為模式可能不太一樣。
機器人之所以很難像人一樣「自然」行動,原因在于觀察和行動空間的高維性質,以及雙足動物形態固有的不穩定性。
對此,LeCun參與的一項工作給出了基于數據驅動的全新解決方案。

論文地址:https://arxiv.org/pdf/2405.18418
項目介紹:https://nicklashansen.com/rlpuppeteer
先看療效:

對比右邊的效果,新的方法訓練出了更接近于人類的行為,雖然有點「喪尸」的意味,但抽象度降低了不少,至少在大部分人類的能力范圍之內。
當然了,也有來搗亂的網友表示,「還是之前那個看著更有意思」。

在這項工作中,研究人員探索了基于強化學習的、高度數據驅動的、視覺全身人形控制方法,沒有任何簡化的假設、獎勵設計或技能原語。
作者提出了一個分層世界模型,訓練高級和低級兩個智能體,高級智能體根據視覺觀察生成命令,供低級智能體執行。

開源代碼:https://github.com/nicklashansen/puppeteer
這個模型被命名為Puppeteer,利用一個模擬的56-DoF人形機器人,在8個任務中生成了高性能的控制策略,同時合成了自然的類似人類的動作,并具有穿越挑戰性地形的能力。

高維控制的分層世界模型
在物理世界中學習訓練出通用的智能體,一直是AI領域研究的目標之一。
而人形機器人通過集成全身控制和感知,能夠執行各種任務,于是作為多功能平臺脫穎而出。
不過要模仿咱們這種高級動物,代價還是很大的。
比如下圖中,人型機器人為了不踩坑,就需要準確地感知迎面而來的地板縫隙的位置和長度,同時仔細協調全身運動,使其有足夠的動量和范圍來跨越每個縫隙。

Puppeteer基于LeCun在2022年提出的分層JEPA世界模型,是一種數據驅動的RL方法。

它由兩個不同的智能體組成:一個負責感知和跟蹤,通過關節級控制跟蹤參考運動;另一個「視覺木偶」(puppeteer),通過合成低維參考運動來學習執行下游任務,為前者的跟蹤提供支持。
Puppeteer使用基于模型的RL算法——TD-MPC2,在兩個不同的階段獨立訓練兩個智能體。
(ps:這個TD-MPC2就是文章開篇用來比較的那個動圖,別看有點抽象,那實際上是之前的SOTA,發表在今年的ICLR,一作同樣也是本文的一作。)
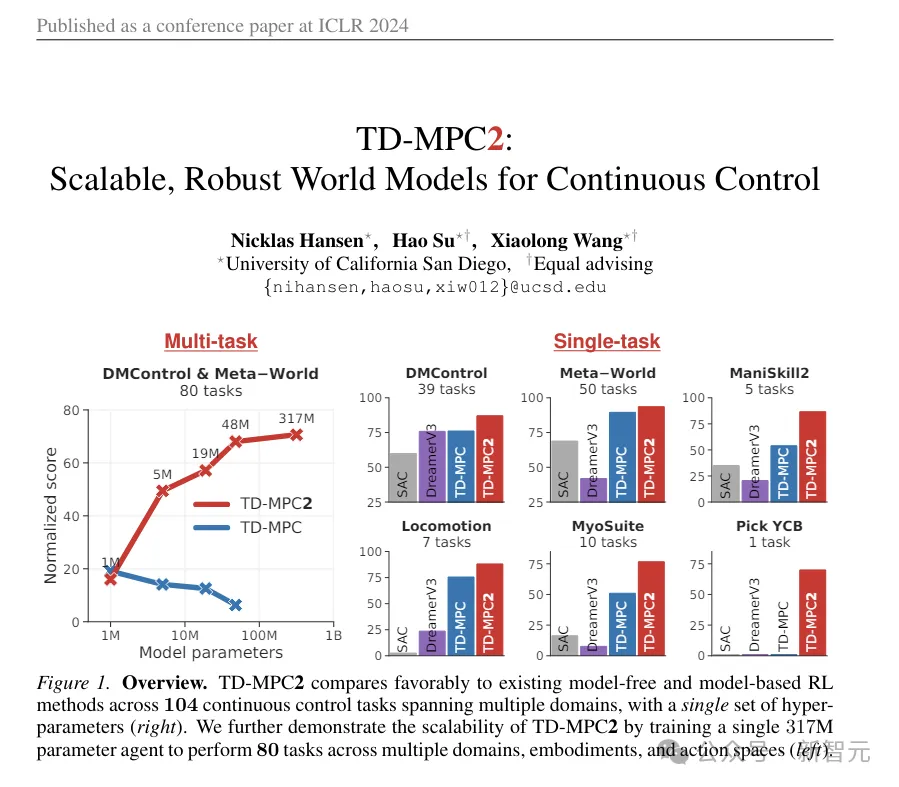
第一階段,首先對用于跟蹤的世界模型進行預訓練,使用預先存在的人類動作捕捉數據作為參考,將運動轉換為物理上可執行的動作。這個智能體可以保存起來,在所有下游任務中重復使用。
在第二階段,訓練一個木偶世界模型,該模型以視覺觀察為輸入,并根據指定的下游任務,整合另一個智能體提供的參考運動作為輸出。
這個框架看上去大道至簡:兩個世界模型在算法上是相同的,只是在輸入/輸出上不同,并且使用RL進行訓練,無需其他任何花里胡哨的東西。
與傳統的分層RL設置不同的是,「木偶」輸出的是末端執行器關節的幾何位置,而不是目標的嵌入。
這使得負責跟蹤的智能體易于在任務之間共享和泛化,節省整體計算占用的空間。
研究方法
研究人員將視覺全身人形控制,建模為一個由馬爾可夫決策過程(MDP)控制的強化學習問題,該過程以元組(S,A,T,R,γ,?)為特征,
其中S是狀態,A是動作,T是環境轉換函數, R是標量獎勵函數, γ是折扣因子,?是終止條件。
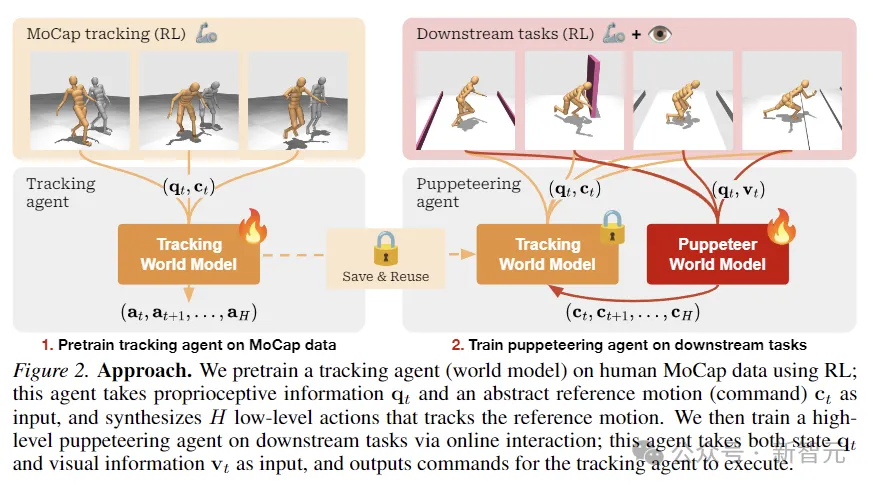
如上圖所示,研究人員使用RL在人類MoCap數據上預訓練跟蹤智能體,用于獲取本體感覺信息和抽象參考運動輸入,并合成跟蹤參考運動的低級動作。
然后通過在線互動,對負責下游任務的高級木偶智能體進行訓練,木偶接受狀態和視覺信息輸入,并輸出命令供跟蹤智能體執行。
TD-MPC2
TD-MPC2從環境交互中學習一個潛在的無解碼器世界模型,并使用學習到的模型進行規劃。

世界模型的所有組件都是使用聯合嵌入預測、獎勵預測和時間差異 損失的組合端到端學習的,而無需解碼原始觀察結果。
在推理過程中,TD-MPC2遵循模型預測控制(MPC)框架,使用模型預測路徑積分(MPPI)作為無導數(基于采樣)的優化器進行局部軌跡優化。
為了加快規劃速度,TD-MPC2還事先學習了一個無模型策略,用于預啟動采樣程序。
兩個智能體在算法上是相同的,都由以下6個組件組成:

實驗
為了評估方法的有效性,研究人員提出了一種新的任務套件,使用模擬的56自由度人形機器人進行視覺全身控制,總共包含8個具有挑戰性的任務,用于對比的方法包括SAC、DreamerV3以及TD-MPC2。
8個任務如下圖所示,包括5個視覺條件全身運動任務,以及另外3個沒有視覺輸入的任務。

任務的設計具有高度的隨機性,包括沿著走廊奔跑、跳過障礙物和縫隙、走上樓梯以及繞過墻壁。
5個視覺控制任務都使用與線性前進速度成正比的獎勵函數,而非視覺任務則獎勵任何方向的位移。

上圖繪制了學習曲線。結果表明,SAC和DreamerV3在這些任務上無法實現有意義的性能。
TD-MPC2在獎勵方面的性能與本文的方法相當,但會產生不自然的行為(參見下圖中的抽象動作)。


此外,為了證明Puppeteer生成的動作確實更「自然」,本文還進行了人類偏好的實驗,對46名參與者的測試表明,人類普遍喜歡本文方法生成的運動。