基于MySQL復制的業務需求分析和改進
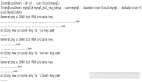
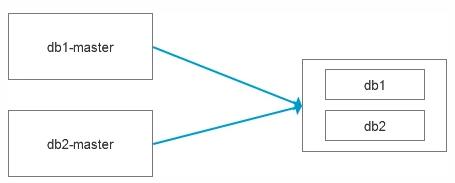
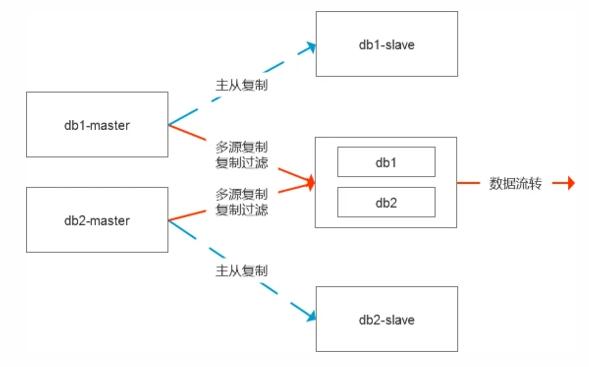
今天和同事聊起了一個問題,主要背景是有2個數據庫需要數據流轉至數倉系統,雖然數據庫的存儲容量很大,但是需要流轉的數據量不大,舉個例子,比如源數據庫有100張表占用800G,但是數據流轉只需要10張表,占用30G, 所以在構建數據源集市的時候,我們就選擇了多源復制的模式,把兩個數據庫合在一起對外交付,本質上還是基于主從復制的模式,只是更加靈活而已。
近期有個新需求,打破了這種平靜,現在需要新增幾張數據表流轉至數倉系統,尷尬的是這幾張表因為歷史原因沒有分表,單表的數據量在幾億,如果采用邏輯導出導入的方式,需要差不多5個小時左右,而且最關鍵的是,還帶來了一系列問題:
1)這種數據導出導入的模式,數據導入完成后的數據補齊工作很難,因為數據是從主庫復制,所以這個中間節點上面始終是一種動態的數據處理過程,從理論上來說,是沒有辦法追齊數據的
2)數據復制基于GTID,什么時候該做取舍也是個難題,比如其他的10張表在實時復制,而新增的表會產生新的GTID,在數據沒有應用過來之前,會有一系列的GTID無法自動修復。
如果把這個圖畫的更全面一些,其實是這樣的結構,默認是有數據的容災節點的,中間節點是直接從主庫進行數據復制的。
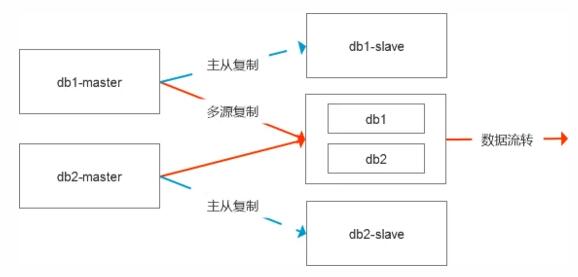
要解決現在的這個問題,導出導入5個小時顯然是不合理的,而相對來說理想的方式便是基于物理數據的處理模式。
一種是傳輸表空間,直接把ibd文件拷貝到中間節點,然后修復數據的差異,這個時候有兩種修復差值的模式,一種是基于表中的增量時間來處理,相對不夠通用,第二種則是更嚴謹的模式,則是修改數據的復制鏈路,基于從庫級聯復制即可。
這里的關鍵便是在開啟傳輸表空間前就停止slave復制,讓整個系統處于靜止狀態,這樣能夠保證數據的完整性,這個過程如果是復制ibd文件,30G左右的文件大概30分鐘就能搞定。
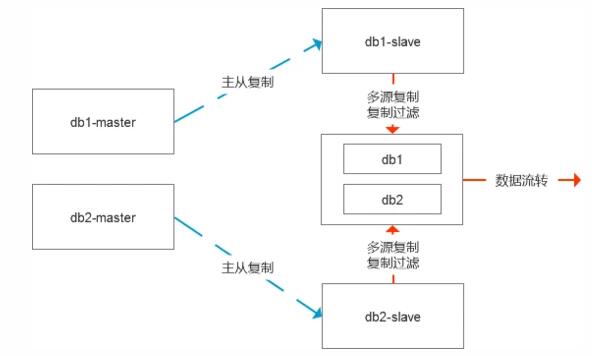
復制完成后,可以根據需求是繼續保留基于從庫復制還是重新調整GTID綁定到主庫端去。
最終的變更狀態和原來基本保持一致。
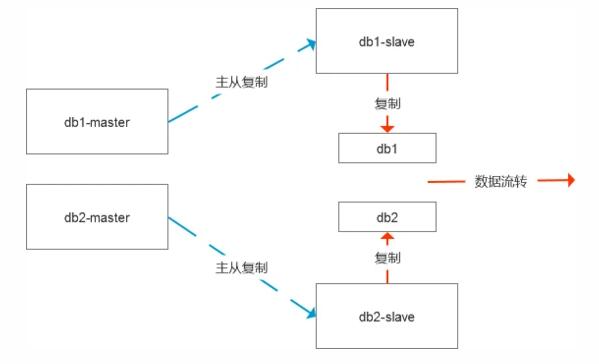
第二種處理模式簡單直接,即需要尋找數據問題的根因,比如源庫有100張表占用800G,但是需要流轉10張表占用30G,那么我們是不是可以直接基于數據庫級,實例級進行數據復制,等數據復制狀態正常后我們把那90張表都清理掉,在處理過程中,對于一些可能出現的復制異常編碼進行統一的過濾處理。這樣我們的數據始終是實時更新的狀態,無論是狀態性數據實時更新還是日志型數據實時更新都可以靈活的適配。
同時在這個時候我們對于多源復制也可以做一些取舍,在這種場景下我覺得使用的意義就不是很大了。
綜上,數據復制是一個很好的數據開關,能夠靈活的適配和處理很多偏向于業務需求的數據邏輯,在這個過程中,基于系統層,物理的處理模式要遠比邏輯處理要高效的多。