













阿里二面:什么是mmap?
平時(shí)在面試中你肯定會(huì)經(jīng)常碰見(jiàn)的問(wèn)題就是:RocketMQ為什么快?Kafka為什么快?什么是mmap?
這一類(lèi)的問(wèn)題都逃不過(guò)的一個(gè)點(diǎn)就是零拷貝,雖然還有一些其他的原因,但是今天我們的話題主要就是零拷貝。
傳統(tǒng)IO
在開(kāi)始談零拷貝之前,首先要對(duì)傳統(tǒng)的IO方式有一個(gè)概念。
基于傳統(tǒng)的IO方式,底層實(shí)際上通過(guò)調(diào)用read()和write()來(lái)實(shí)現(xiàn)。
通過(guò)read()把數(shù)據(jù)從硬盤(pán)讀取到內(nèi)核緩沖區(qū),再?gòu)?fù)制到用戶(hù)緩沖區(qū);然后再通過(guò)write()寫(xiě)入到socket緩沖區(qū),最后寫(xiě)入網(wǎng)卡設(shè)備。
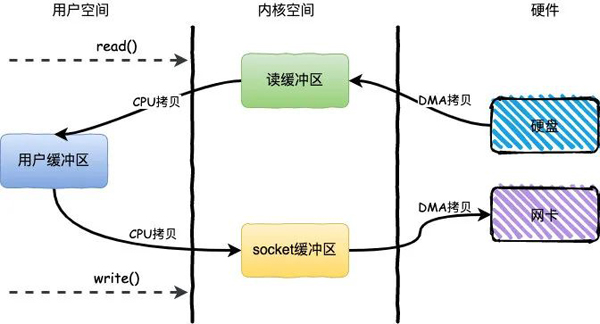
整個(gè)過(guò)程發(fā)生了4次用戶(hù)態(tài)和內(nèi)核態(tài)的上下文切換和4次拷貝,具體流程如下:
- 用戶(hù)進(jìn)程通過(guò)read()方法向操作系統(tǒng)發(fā)起調(diào)用,此時(shí)上下文從用戶(hù)態(tài)轉(zhuǎn)向內(nèi)核態(tài)
- DMA控制器把數(shù)據(jù)從硬盤(pán)中拷貝到讀緩沖區(qū)
- CPU把讀緩沖區(qū)數(shù)據(jù)拷貝到應(yīng)用緩沖區(qū),上下文從內(nèi)核態(tài)轉(zhuǎn)為用戶(hù)態(tài),read()返回
- 用戶(hù)進(jìn)程通過(guò)write()方法發(fā)起調(diào)用,上下文從用戶(hù)態(tài)轉(zhuǎn)為內(nèi)核態(tài)
- CPU將應(yīng)用緩沖區(qū)中數(shù)據(jù)拷貝到socket緩沖區(qū)
- DMA控制器把數(shù)據(jù)從socket緩沖區(qū)拷貝到網(wǎng)卡,上下文從內(nèi)核態(tài)切換回用戶(hù)態(tài),write()返回
那么,這里指的用戶(hù)態(tài)、內(nèi)核態(tài)指的是什么?上下文切換又是什么?
簡(jiǎn)單來(lái)說(shuō),用戶(hù)空間指的就是用戶(hù)進(jìn)程的運(yùn)行空間,內(nèi)核空間就是內(nèi)核的運(yùn)行空間。
如果進(jìn)程運(yùn)行在內(nèi)核空間就是內(nèi)核態(tài),運(yùn)行在用戶(hù)空間就是用戶(hù)態(tài)。
為了安全起見(jiàn),他們之間是互相隔離的,而在用戶(hù)態(tài)和內(nèi)核態(tài)之間的上下文切換也是比較耗時(shí)的。
從上面我們可以看到,一次簡(jiǎn)單的IO過(guò)程產(chǎn)生了4次上下文切換,這個(gè)無(wú)疑在高并發(fā)場(chǎng)景下會(huì)對(duì)性能產(chǎn)生較大的影響。
那么什么又是DMA拷貝呢?
因?yàn)閷?duì)于一個(gè)IO操作而言,都是通過(guò)CPU發(fā)出對(duì)應(yīng)的指令來(lái)完成,但是相比CPU來(lái)說(shuō),IO的速度太慢了,CPU有大量的時(shí)間處于等待IO的狀態(tài)。
因此就產(chǎn)生了DMA(Direct Memory Access)直接內(nèi)存訪問(wèn)技術(shù),本質(zhì)上來(lái)說(shuō)他就是一塊主板上獨(dú)立的芯片,通過(guò)它來(lái)進(jìn)行內(nèi)存和IO設(shè)備的數(shù)據(jù)傳輸,從而減少CPU的等待時(shí)間。
但是無(wú)論誰(shuí)來(lái)拷貝,頻繁的拷貝耗時(shí)也是對(duì)性能的影響。
零拷貝
零拷貝技術(shù)是指計(jì)算機(jī)執(zhí)行操作時(shí),CPU不需要先將數(shù)據(jù)從某處內(nèi)存復(fù)制到另一個(gè)特定區(qū)域,這種技術(shù)通常用于通過(guò)網(wǎng)絡(luò)傳輸文件時(shí)節(jié)省CPU周期和內(nèi)存帶寬。
那么對(duì)于零拷貝而言,并非真的是完全沒(méi)有數(shù)據(jù)拷貝的過(guò)程,只不過(guò)是減少用戶(hù)態(tài)和內(nèi)核態(tài)的切換次數(shù)以及CPU拷貝的次數(shù)。
這里,僅僅有針對(duì)性的來(lái)談?wù)剮追N常見(jiàn)的零拷貝技術(shù)。
- mmap+write
mmap+write簡(jiǎn)單來(lái)說(shuō)就是使用mmap替換了read+write中的read操作,減少了一次CPU的拷貝。
mmap主要實(shí)現(xiàn)方式是將讀緩沖區(qū)的地址和用戶(hù)緩沖區(qū)的地址進(jìn)行映射,內(nèi)核緩沖區(qū)和應(yīng)用緩沖區(qū)共享,從而減少了從讀緩沖區(qū)到用戶(hù)緩沖區(qū)的一次CPU拷貝。
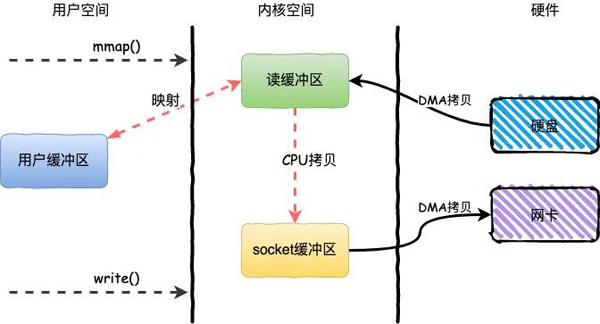
整個(gè)過(guò)程發(fā)生了4次用戶(hù)態(tài)和內(nèi)核態(tài)的上下文切換和3次拷貝,具體流程如下:
- 用戶(hù)進(jìn)程通過(guò)mmap()方法向操作系統(tǒng)發(fā)起調(diào)用,上下文從用戶(hù)態(tài)轉(zhuǎn)向內(nèi)核態(tài)
- DMA控制器把數(shù)據(jù)從硬盤(pán)中拷貝到讀緩沖區(qū)
- 上下文從內(nèi)核態(tài)轉(zhuǎn)為用戶(hù)態(tài),mmap調(diào)用返回
- 用戶(hù)進(jìn)程通過(guò)write()方法發(fā)起調(diào)用,上下文從用戶(hù)態(tài)轉(zhuǎn)為內(nèi)核態(tài)
- CPU將讀緩沖區(qū)中數(shù)據(jù)拷貝到socket緩沖區(qū)
- DMA控制器把數(shù)據(jù)從socket緩沖區(qū)拷貝到網(wǎng)卡,上下文從內(nèi)核態(tài)切換回用戶(hù)態(tài),write()返回
mmap的方式節(jié)省了一次CPU拷貝,同時(shí)由于用戶(hù)進(jìn)程中的內(nèi)存是虛擬的,只是映射到內(nèi)核的讀緩沖區(qū),所以可以節(jié)省一半的內(nèi)存空間,比較適合大文件的傳輸。
- sendfile
相比mmap來(lái)說(shuō),sendfile同樣減少了一次CPU拷貝,而且還減少了2次上下文切換。
sendfile是Linux2.1內(nèi)核版本后引入的一個(gè)系統(tǒng)調(diào)用函數(shù),通過(guò)使用sendfile數(shù)據(jù)可以直接在內(nèi)核空間進(jìn)行傳輸,因此避免了用戶(hù)空間和內(nèi)核空間的拷貝,同時(shí)由于使用sendfile替代了read+write從而節(jié)省了一次系統(tǒng)調(diào)用,也就是2次上下文切換。
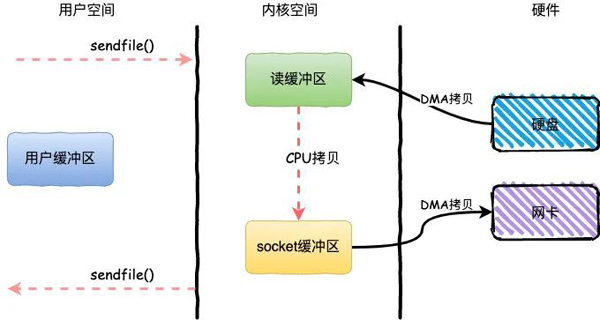
整個(gè)過(guò)程發(fā)生了2次用戶(hù)態(tài)和內(nèi)核態(tài)的上下文切換和3次拷貝,具體流程如下:
- 用戶(hù)進(jìn)程通過(guò)sendfile()方法向操作系統(tǒng)發(fā)起調(diào)用,上下文從用戶(hù)態(tài)轉(zhuǎn)向內(nèi)核態(tài)
- DMA控制器把數(shù)據(jù)從硬盤(pán)中拷貝到讀緩沖區(qū)
- CPU將讀緩沖區(qū)中數(shù)據(jù)拷貝到socket緩沖區(qū)
- DMA控制器把數(shù)據(jù)從socket緩沖區(qū)拷貝到網(wǎng)卡,上下文從內(nèi)核態(tài)切換回用戶(hù)態(tài),sendfile調(diào)用返回
sendfile方法IO數(shù)據(jù)對(duì)用戶(hù)空間完全不可見(jiàn),所以只能適用于完全不需要用戶(hù)空間處理的情況,比如靜態(tài)文件服務(wù)器。
- sendfile+DMA Scatter/Gather
Linux2.4內(nèi)核版本之后對(duì)sendfile做了進(jìn)一步優(yōu)化,通過(guò)引入新的硬件支持,這個(gè)方式叫做DMA Scatter/Gather 分散/收集功能。
它將讀緩沖區(qū)中的數(shù)據(jù)描述信息--內(nèi)存地址和偏移量記錄到socket緩沖區(qū),由 DMA 根據(jù)這些將數(shù)據(jù)從讀緩沖區(qū)拷貝到網(wǎng)卡,相比之前版本減少了一次CPU拷貝的過(guò)程
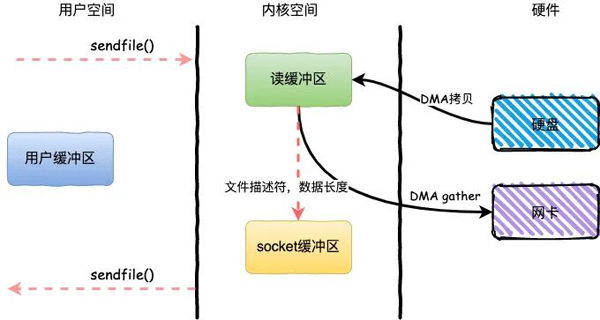
整個(gè)過(guò)程發(fā)生了2次用戶(hù)態(tài)和內(nèi)核態(tài)的上下文切換和2次拷貝,其中更重要的是完全沒(méi)有CPU拷貝,具體流程如下:
- 用戶(hù)進(jìn)程通過(guò)sendfile()方法向操作系統(tǒng)發(fā)起調(diào)用,上下文從用戶(hù)態(tài)轉(zhuǎn)向內(nèi)核態(tài)
- DMA控制器利用scatter把數(shù)據(jù)從硬盤(pán)中拷貝到讀緩沖區(qū)離散存儲(chǔ)
- CPU把讀緩沖區(qū)中的文件描述符和數(shù)據(jù)長(zhǎng)度發(fā)送到socket緩沖區(qū)
- DMA控制器根據(jù)文件描述符和數(shù)據(jù)長(zhǎng)度,使用scatter/gather把數(shù)據(jù)從內(nèi)核緩沖區(qū)拷貝到網(wǎng)卡
- sendfile()調(diào)用返回,上下文從內(nèi)核態(tài)切換回用戶(hù)態(tài)
DMA gather和sendfile一樣數(shù)據(jù)對(duì)用戶(hù)空間不可見(jiàn),而且需要硬件支持,同時(shí)輸入文件描述符只能是文件,但是過(guò)程中完全沒(méi)有CPU拷貝過(guò)程,極大提升了性能。
應(yīng)用場(chǎng)景
對(duì)于文章開(kāi)頭說(shuō)的兩個(gè)場(chǎng)景:RocketMQ和Kafka都使用到了零拷貝的技術(shù)。
對(duì)于MQ而言,無(wú)非就是生產(chǎn)者發(fā)送數(shù)據(jù)到MQ然后持久化到磁盤(pán),之后消費(fèi)者從MQ讀取數(shù)據(jù)。
對(duì)于RocketMQ來(lái)說(shuō)這兩個(gè)步驟使用的是mmap+write,而Kafka則是使用mmap+write持久化數(shù)據(jù),發(fā)送數(shù)據(jù)使用sendfile。
總結(jié)
由于CPU和IO速度的差異問(wèn)題,產(chǎn)生了DMA技術(shù),通過(guò)DMA搬運(yùn)來(lái)減少CPU的等待時(shí)間。
傳統(tǒng)的IOread+write方式會(huì)產(chǎn)生2次DMA拷貝+2次CPU拷貝,同時(shí)有4次上下文切換。
而通過(guò)mmap+write方式則產(chǎn)生2次DMA拷貝+1次CPU拷貝,4次上下文切換,通過(guò)內(nèi)存映射減少了一次CPU拷貝,可以減少內(nèi)存使用,適合大文件的傳輸。
sendfile方式是新增的一個(gè)系統(tǒng)調(diào)用函數(shù),產(chǎn)生2次DMA拷貝+1次CPU拷貝,但是只有2次上下文切換。因?yàn)橹挥幸淮握{(diào)用,減少了上下文的切換,但是用戶(hù)空間對(duì)IO數(shù)據(jù)不可見(jiàn),適用于靜態(tài)文件服務(wù)器。
sendfile+DMA gather方式產(chǎn)生2次DMA拷貝,沒(méi)有CPU拷貝,而且也只有2次上下文切換。雖然極大地提升了性能,但是需要依賴(lài)新的硬件設(shè)備支持。
























