微服務架構的數據庫為什么喜歡分庫分表?
1.引入
微服務架構想必大家都是有所耳聞。
簡單來說,微服務架構就是把傳統的一個單體應用以一套"小服務"的方式進行開發,這些"小服務"可以運行在不同機器上,它們在自己的進程中運行,"小服務"之間可以通過像是 HTTP API 這樣的輕量級的機制進行通信,這些"小服務"緊緊圍繞項目的業務需求開發,同時,它們是以業務邊界進行劃分成獨立的微服務。這些微服務看似獨立又像是一個整體,構成了一個業務集群。
2.為何分庫
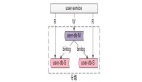
微服務架構從業務邏輯實現的角度上看系統的性能得到了優化,可是對數據庫的負擔就加重了。假設一個分布式電子商務系統,那么這個系統會包含會員信息、訂單信息、商品信息、商品庫存信息等等內容,數據存放在數據庫中,要訪問數據,就要與數據庫建立連接,而數據庫的連接是有限的,況且在這樣的業務環境下,會出現較多的高并發場景,如果都同時向這個商城數據庫訪問數據,數據庫顯然是受不起這樣的折騰。如圖:

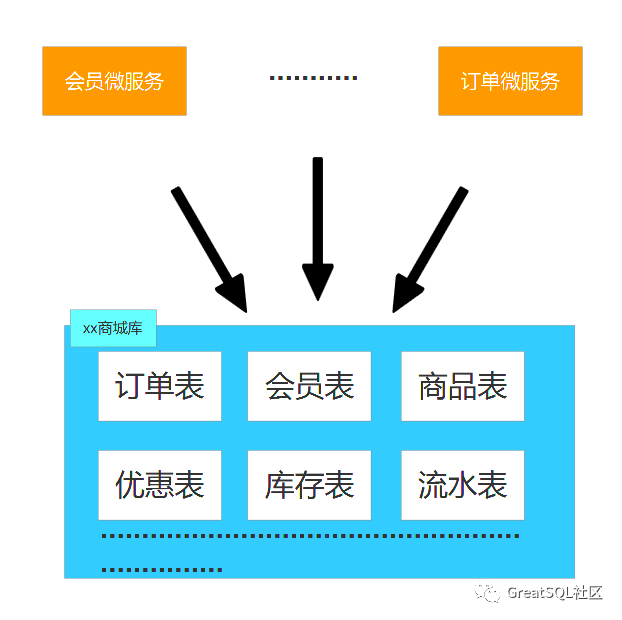
上文提到,微服務是以業務邊界進行劃分的,那么這些服務就可以使用不同的編程語言書寫,以及不同數據存儲技術,前提是保持最低限度的集中式管理。也就是說,各個微服務處理的數據可以達到自治。
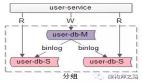
因此,為了處理高并發,設計數據庫就可以采取分庫的方式進行,使得各個微服務擁有自己獨立的數據庫,就好比訂單微服務自治訂單信息、支付流水信息、退款信息等等,當訂單微服務需要會員微服務的會員數據時,可以通過服務的通訊機制,比如feign,以此達到分擔傳統模式壓力的效果,如圖:

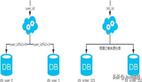
同時,對于每一個劃分好的庫也可以再進行分庫部署,劃分出的庫擁有相同的表,不同的只有存放的數據集。它可以有效的緩解單機單庫的性能瓶頸和壓力隨著需求的細化,項目的業務量是龐大的,這也導致項目的數據量是龐大的,數據庫分庫部署可以有效減輕磁盤負擔。如圖:

3.為何分表
微服務開發中,我們經常會遇到大表的情況,所謂大表是指存儲了百萬級乃至千萬級條記錄的表,這樣的表數據過于龐大,導致數據庫在查詢和插入的時候耗時太長,就算使用索引,在大量的數據面前,查詢的效率也會有所降低,更何況是使用不到索引的情況,下邊列舉一些使用不到索引的情況:
# 使用LIKE通配符置于字符串前面
mysql> SELECT * FROM test WHERE name LIKE '%小王';
# 函數運算
mysql> SELECT * FROM test WHERE UPPER(name) = 'ZS';
分表是對表進行分區,最主要的目的就是減輕數據庫的負擔,提高數據庫的效率。表分區是根據一定的規則,把數據庫的一張表分解為多個更小的表,使用分區的表從邏輯上看還是一個表,但物理存儲分為了多份,表分區后的每個部分,都可以獨立的進行數據處理,分區具有以下好處:
- 存儲空間更大了
- 查詢速度更快,只需要掃描需要的分區表,再將結果進行合并。不會因為全表掃描,而浪費不必要的資源
- 對于刪除數據來說,處理更方便了,只需要刪除對應分區的數據即可
- 跨越磁盤存儲,充分利用磁盤讀取,提高吞吐量
分區是將數據分段劃分在多個位置存放,可以是同一塊磁盤也可以在不同的機器。表分區有很多的策略,根據不同的策略可以適應多種業務場景,例如可以通過表內屬性值的范圍進行分表,如下圖,將商城支付流水表以流水時間進行劃分:

表在分區后,表面上還是一張表,但數據散列到多個位置了。應用程序讀寫的時候操作的還是大表的表名,數據庫系統自動去組織分區的數據。 使用分區需要注意:
MySQL 8.0版本前支持創建表分區的存儲引擎有InnoDB、Memory、MyISAM、MERGE,MySQL 8.0之后就只支持InnoDB存儲引擎了
分區表必須一致,即同一張表分區后,各個分區表必須使用一致的存儲引擎
3.1.表分區
表分區可在創建數據庫表的時候進行指定,格式如下:
CREATE TABLE TABLE_NAME(
………
)
PARTITION BY RANGE|LIST|HASH(TABLE_COLUMN)(
PARTITION P0……
)
上文提到表分區有不同策略,也可以稱為不同類型:
- RANGE分區
- LIST分區
- COLUMNS分區
- HASH分區
- KEY分區
- 子分區
3.1.1.RANGE分區
RANGE分區是基于一個給定連續區間范圍,區間之間的不能互相重疊,數據會根據范圍,分配到不同的分區,RANGE的分區鍵必須是單列的int類型,每個分區范圍必須按順序(后一個分區范圍值比前一個值大)。 假設指定一表為RANGE分區,分4個區,最后一個區為了防止數據定義問題,將其設置為數值最大值“MAXVALUE”:
mysql> CREATE TABLE testrange(
-> id INT PRIMARY KEY AUTO_INCREMENT,
-> name VARCHAR(10))
-> PARTITION BY RANGE(id)(
-> PARTITION p0 VALUES LESS THAN(50),
-> PARTITION p1 VALUES LESS THAN(100),
-> PARTITION p2 VALUES LESS THAN(150),
-> PARTITION p3 VALUES LESS THAN(MAXVALUE));
3.1.2.LIST分區
LIST分區的分區鍵的類型也只能是int類型,LIST分區是基于枚舉值列表進行分區,枚舉的范圍同樣不能有重復的值,如果插入數據不在枚舉范圍之內,則會報錯。
# 指定為LIST分區,分2個區
mysql> CREATE TABLE testlist(
-> id INT PRIMARY KEY AUTO_INCREMENT,
-> name VARCHAR(10))
-> PARTITION BY LIST(id)(
-> PARTITION p0 VALUES IN (1,2,3),
-> PARTITION p1 VALUES IN (4,6,9));
mysql> INSERT INTO testlist VALUES(null,'張三');
mysql> INSERT INTO testlist VALUES(2,'李四');
# 插入列限制數值不存在的數,則會提示這張表沒有改值的分區
mysql> INSERT INTO testlist VALUES(5,'李三');
ERROR 1526 (HY000): Table has no partition for value 5
3.1.3.COLUMNS分區
COLUMNS分區區別于RANGE分區和LIST分區的最大特點是支持多列的分區,COLUMNS分區有兩種形式,RANGE COLUMNS和LIST COLUMNS分區。兩種分區形式都支持整數類型,日期類型,字符類型,區別在于,如果COLUMNS分區的分區鍵有多個,當數據庫要進行數據插入時,會先考慮第一個鍵是否滿足,如果滿足條件就會進行數據寫入,如果不滿足條件就要對第二個鍵的條件進行判斷,以此類推。
mysql> CREATE TABLE testrancol(
-> sid INT,cid INT,PRIMARY KEY(sid,cid))
-> PARTITION BY RANGE COLUMNS(sid,cid)(
-> PARTITION p0 VALUES LESS THAN(1,10),
-> PARTITION p1 VALUES LESS THAN(10,20));
3.1.4.HASH分區
HASH分區主要用于將一整個數據,分散為若干個相等數量的分區,HASH分區有兩種類型:
(1)常規HASH分區,使用的是取模運算。假設分區數為4,則有0,1,2,3四個值,對應分區為四個。因為使用的取模運算,所以分區鍵必須是整數類型的列或返回整數類型的表達式:
mysql> CREATE TABLE testhash1(
-> id INT PRIMARY KEY,num VARCHAR(10))
-> PARTITION BY HASH(id) PARTITIONS 4;
# 如果此時插入數據id為83,則模4取余得3,將數據放在第三個分區中
(2)線性HASH分區,其語法書寫不同于常規HASH分區,需要加上LINEAR關鍵字。在數據分配的時候,使用的是2的冪運算進行分配數據的配分有兩步運算:
mysql> CREATE TABLE testhash2(
-> id INT PRIMARY KEY,num VARCHAR(10))
-> PARTITION BY LINEAR HASH(id) PARTITIONS 4;
# 1、第一步,算出V的值
# 計算方式為:V=POWER(2,CEILING(LOG(2,分區數)))
# 假設分區數為4,log()的值為2
# Ceiling()取最小整數,依舊是2
# power返回2的2次方,最后V=4
# 2、第二步,對分區鍵和V-1進行位與運算
# 假設分區鍵值為8和10:
# 那么插入8與10和4-1的3進行按位與運算得出插入分區分別是0與2分區
3.1.5.KEY分區
KEY分區有與HASH分區類似,不同的地方有以下幾點:
- KEY分區不允許使用自定義表達式作為分區鍵
- KEY分區如果不指定分區鍵,則會默認使用表中主鍵。如果沒有主鍵,則使用非空唯一鍵。如果都沒有,那就必須手動指定分區鍵
- 可以使用非數值類型的列作為分區鍵 KEY分區也分為常規KEY分區和線性KEY分區,其運算規則與HASH分區一致,不多做贅述。
mysql> CREATE TABLE testhash1(
-> id INT PRIMARY KEY,num VARCHAR(10))
-> PARTITION BY [LINEAR] KEY(id) PARTITIONS 4;
3.1.6.子分區
子分區是對分區表的每個區分,進行二次的分區,使用RANGE和LIST對表進行分區,則可以使用HASH或KEY進行子分區,假設表有2個分區,這2個分區又被進一步的分為2個子分區,總共有4個分區,寫法有兩種:
- 隱式創建子分區,子分區的名字是自動創建且重名,但不會沖突,輸入小于1900的年份,會按HASH分區的規則(模2運算),分別存放在兩個P0中:
mysql> CREATE TABLE testfh(
-> id INT,pur DATE)
-> PARTITION BY RANGE(YEAR(pur))
-> SUBPARTITION BY HASH(TO_DAYS(pur))
-> SUBPARTITIONS 2 (
-> PARTITION p0 VALUES LESS THAN(1900),
-> PARTITION p1 VALUES LESS THAN MAXVALUE);
- 顯示創建子分區,要求每個分區的子分區數量必須一致,且分區的創建必須一致,即全部子分區都使用隱式創建或顯式創建,不可混用,同時子分區的名字必須唯一
mysql> CREATE TABLE testfh(
-> id INT,pur DATE)
-> PARTITION BY RANGE(YEAR(pur))
-> SUBPARTITION BY HASH(TO_DAYS(pur))(
-> PARTITION p0 VALUES LESS THAN(1900)(
-> SUBPARTITION s0, SUBPARTITION s1),
-> PARTITION p1 VALUES LESS THAN MAXVALUE(
-> SUBPARTITION s2, SUBPARTITION s3));
3.2.表分區注意點
3.2.1.RANGE表分區注意點
使用RANGE策略進行表分區的好處在于分區后數據的擴容性好,不需要進行數據遷移,如果插入的數據超過原先建立分區的范圍可以根據實際情況考慮在原有基礎上增加表分區或者水平部署一張相同的表進行存放數據,增加表分區可參考以下格式:
# RANGE分區中添加分區,是在尾部進行添加,所以如果RANGE已經有包含最大值的分區,那么新添加的分區就會報錯
ALTER TABLE 表名 ADD PARTITION (PARTITION 分區名 VALES LESS THAN (范圍));
需要注意的是表在RANGE分區的時候指定的分區鍵需要考慮實際情況,如果使用不當會造成個別分區數據過多的情況。
假設一個電子商務系統需要存放訂單的相關信息,用戶進行商品購買則產生訂單,訂單往往包含多個不同商品,可以設置訂單項表用于存放訂單的每個商品id、商品名、價格、數量等數據,如果以商品id作為分區鍵則會產生"數據熱點"問題,有些商品銷量好,那么分區的數據就多,一些商品銷量不好那么數據就會很少。

3.2.2.HASH表分區注意點
使用HASH策略的好處就在于解決數據熱點問題,但是,HASH表分區的分區數量是固定的,如果數據過多達到了瓶頸,就要將分區數量進行修改了,因此原先已經存放的數據又要進行取模運算重新存放,需要進行數據遷移,語法如下:
# 增加2個分區
ALTER TABLE 表名 PARTITION 2;
# 減少2個分區
ALTER TABLE 表名 COALESCE PARTITION 2;
3.2.3.MySQL表分區遇到NULL值
當MySQL表分區遇到NULL值,MySQL不會禁止分區鍵有NULL值,但不同的分區類型會將NULL值當成不同的數據對待,如:
在RANGE分區中,NULL值被當成最小的數。
在LIST分區中,NULL被當成字符串,如果NULL不在LIST的枚舉范圍中,還有出現報錯
在HASH和KEY中,NULL值被當成0 所以,在使用分區時,要注意處理NULL值輸入,以免出現MySQL的誤判,將分區鍵設為NOT NULL或默認值都可以好的對應這種情況。
4.總結
本文介紹了為什么微服務架構大多采用分庫分表的方式進行設計數據庫,當然,分布式系統在設計過程中進行分庫分表還需要注意一些問題,比如,在我們創建數據庫表的時候是否可以先考慮表內數據的特性,事先將一些不經常需要更改的內容抽離出來,形成一張新的表,從某種程度上說,這種方式也是一種"分表"的操作。
同時,在進行分庫在涉及事務安全性的時候也需要注意,比如商城中用戶提交了訂單,那么系統就需要對所購買商品的庫存進行鎖定,如果出現用戶未支付訂單超時等問題,就需要將已經鎖定的庫存進行數據回滾了,可是訂單和庫存在不同的數據,要如何保證事務的原子性呢?如果都在本地部署,可以使用AOP對事務進行代理,在不同機器部署的情況下也可以通過設置undo_log表并通過阿里的Seata進行代理。但是在高并發情況下,這些方式容易造成"雪崩",這個時候還可以考慮消息隊列,通過延遲隊列來完成庫存的解鎖。