OCR+NLP 提取信息并分析,這個開源項目火了!
Python中文社區(ID:python-china)
文字是傳遞信息的高效途徑,利用OCR技術提取文本信息是各行業向數字智能化轉型的第一步。與此同時,針對OCR提取的海量文本信息,利用NLP技術進一步加工提取、分析理解后才能最大化發揮文本信息的價值。NLP技術可以提升OCR準確率,并從文本中抽取關鍵信息、構建知識圖譜,搭建檢索、推薦、問答系統等。

雖然各行業智能化產業升級已經在如火如荼的開展中,但是在實際應用落地中卻遇到諸多困難,比如:數據樣本不夠、模型精度不高、預測時延大等。為此,百度飛槳針對真實、高頻的產業場景,提供了從數據準備、模型訓練優化,到模型部署全流程的案例教程。
聽說文檔和代碼已經開源了,來吧
OCR + NLP 串聯技術難點
市面上有不少開源的OCR、NLP產品,但是如果想直接利用這些工具,會面臨底層框架不統一、串聯難度高、效果無法保證等問題。PaddleOCR和PaddleNLP是面向產業界的開發庫,均基于飛槳開源框架最新版本,能夠將OCR和NLP技術無縫結合。
今天我們針對金融行業研報、物流快遞單,來看看OCR + NLP信息抽取技術的應用。
OCR + NLP金融研報分析
當前,諸多投資機構都通過研報的形式給出對于股票、基金以及行業的判斷,讓大眾了解熱點方向、龍頭公司等各類信息。然而,分析和學習研報往往花費大量時間,研報數量的與日俱增也使得研報智能分析訴求不斷提高。這里我們采用命名實體識別技術,自動抽取研報中的關鍵信息,例如,“中國銀行成立于1912年。”中包含了組織機構、場景事件、時間等實體信息。

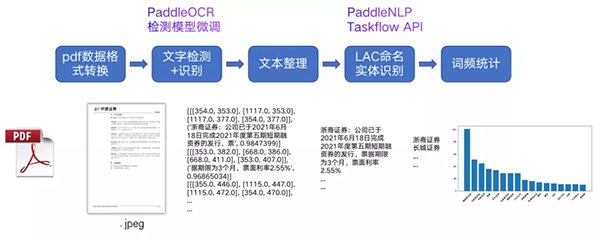
OCR+NLP Pipeline
針對研報數據的命名實體識別與詞頻統計整體流程如上圖所示。首先將研報pdf數據使用fitz包拆分為圖像格式,然后利用PaddleOCR套件在研報數據集上微調PP-OCR[1]的檢測模型,使用現有的識別模型獲得文本信息。PP-OCR是PaddleOCR中由百度自研的明星模型系列,由文本檢測、文本方向分類器與文本識別模塊串聯而成。
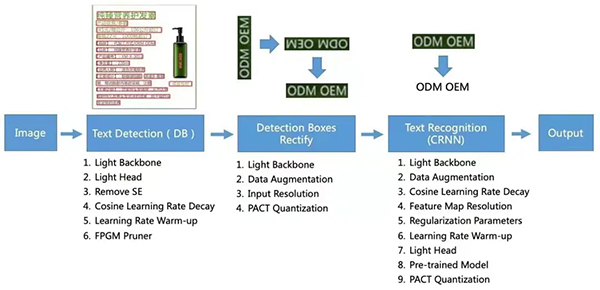
PP-OCR Pipeline
對OCR識別出的文本進行整理后,調用PaddleNLP中的Taskflow API抽取文本信息中的組織機構實體。最后對這些實體進行詞頻統計,就可初步判定當前研報分析的熱點機構。

Taskflow使用示意圖
目前,Taskflow API 支持自然語言理解(NLU)和生成(NLG)兩大場景共八大任務,包括中文分詞、詞性標注、命名實體識別、句法分析、文本糾錯、情感分析、生成式問答和智能寫詩,均可一鍵調用。
物流快遞單信息抽取
雙十一要到了,想必很多人都預備了一個滿滿的購物車。去年雙十一成交量4982億元,全國快遞企業共處理快件39億件,這背后則是物流行業工作量的驟增。除了滿負荷的長深高速公路,還有繁忙的快遞小哥。無論是企業業務匯總,還是寄件信息填寫,都少不了關鍵信息智能提取這一環節,這其中均采用了命名實體識別技術。
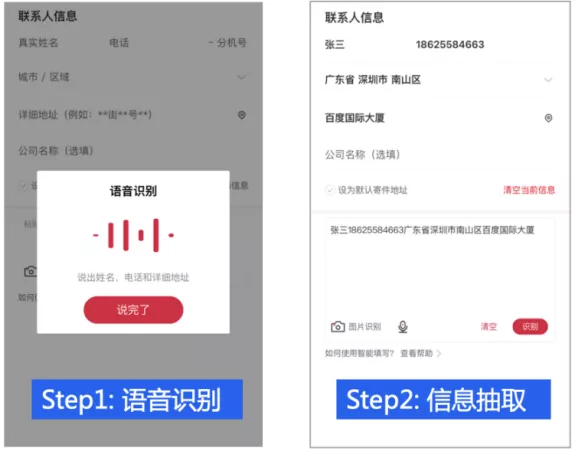
命名實體識別大體上有三種方案:字符串匹配、統計語言模型、序列標注。前兩種方法需要預先構建詞典、窮舉所有實體,無法發現新詞、變體等。本案例中采用了目前的主流方法——序列標注。
數據集包括1600條訓練集,200條訓練集和200條測試集,采用BIO體系進行標注。
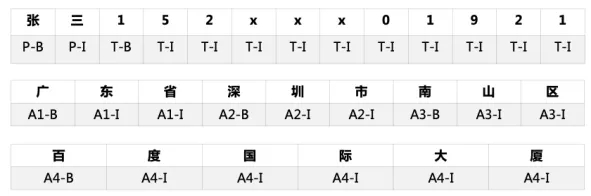
實體定義和數據集標注示例
針對輕量化、高精度的需求,可以選用RNN+CRF 方案。也可以采用預訓練模型,通過模型壓縮、動轉靜加速等方式滿足精度和性能的要求。我們采用Ernie-Gram[2] + CRF 獲得了最佳效果。
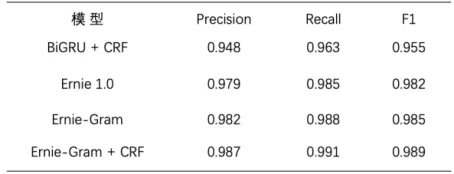
此外,命名實體識別技術可以應用于各類關鍵信息的提取,例如電商評論中的商品名稱、電子發票中的抬頭信息、收入證明中的金額、法律文書中的犯罪地點等信息。結合關系抽取、事件抽取技術,還可以構建知識圖譜、搭建問答系統等。