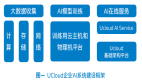
面向AI Everywhere:英特爾在人工智能領域的突圍
原創【51CTO.com原創稿件】隨著云計算、大數據、5G和物聯網技術的普及,人工智能也在加速發展,大眾對于人臉識別、視頻監控、工業質檢、遠程維護等AI應用場景也算得上耳熟能詳。但事實上,AI發展遠非一帆風順,其落地之路一直是荊棘叢生。
首先,如何在海量數據中構建更高效的數據集,從而在更短時間內獲得更好的訓練效果是一大挑戰;其次,人工智能技術本身的賦能屬性會使其和業務場景深度深度結合,如何基于場景加速AI模型的構建是關鍵;再者,較大的模型才有可能獲得較好的準確度,但大模型往往也對硬件的算力提出了更高的技術要求;還有,如何通過軟硬件協同優化加速AI部署,也是影響AI大規模落地的要義。
從中不難窺見,圍繞著“數據、算法、算力”三要素,人工智能應用開發的整個過程可以說環環相扣。無論是數據處理,還是建模、訓練,抑或部署,針對每個具體步驟進行細節優化,才有可能真正突破瓶頸,加速AI落地。當然這一切都離不開底層技術供應商的支持。
在日前舉行的英特爾 On技術創新峰會上,英特爾基于一系列創新發布向大眾描繪了一張“AI Everywhere”的愿景圖。英特爾在開發者生態系統、工具、技術和開放平臺上的深度投資,正在為人工智能的普及掃清道路。
? ??
??
數據基礎設施的優化革新
數據是人工智能的基石。如果能在更短時間內將數據變為洞察,對于人工智能的開發而言無疑事半功倍。
在數據基礎設施建設方面,英特爾早有布局。開源開發平臺BigDL臺簡化了Spark生產環境中的端到端分布式大數據和人工智能管線,利用Apache Spark幫助用戶無縫擴展、數據預處理和Tensorflow或PyTorch建模,縮短了構建解決方案的時間,并為推薦系統、時序分析、隱私、保護機器學習等對象提供面向行業特定應用的數據管線。BigDL目前已被Mastercard、Burger King、SK Telecom等廠商應用于生產環境中,其應用規模還在不斷增大。
在數據預處理方面,英特爾對相關工具進行了優化。開源庫Modin能夠使Pandas應用程序加速多達20倍,通過Jupyter Notebook幾乎可以實現從PC到云的無限擴展;對于熱門的Python數學庫NumPy和SciPy,英特爾也做了針對性優化,使用oneMKL等oneAPI核心構建基塊將線性代數、快速傅里葉變換隨機數生成器及elementwise函數的速度提升達100倍。
算力加速度:硬件平臺的“魚與熊掌”兼得
隨著應用的復雜性不斷增加,單純堆積CPU內核已經無法滿足應用程序對于性能、功耗、成本的要求。人們開始使用越來越多的傾向于各種非CPU計算單元。作為老牌芯片廠商,英特爾近年來在AI硬件領域的投入取得了“魚與熊掌”兼得的成果。
在硬件平臺的構建上,英特爾已經打造了一個完整的XPU平臺——從CPU到GPU到FPGA再到深度學習專用加速器,適用于各種類型的AI需求。
在新近的數代產品中,英特爾的每個CPU核心均增添了內置AI加速能力,無需任何獨立加速器即可貼合一般用戶需求。值得關注的是,在本次會議上,英特爾宣布,其目標是到2022年將英特爾至強可擴展處理器的人工智能性能提高30倍。據悉,下一代英特爾至強可擴展處理器(代號“Sapphire Rapids”)將利用內置高級矩陣擴展(AMX)引擎,英特爾?神經壓縮機(INC),以及基于oneAPI開放行業標準的oneDNN優化,進一步提升計算性能。
除了內置AI加速的通用CPU,英特爾在GPU平臺建設上同樣有不俗表現。Ponte Vecchio可對AI、HPC和高級分析工作負載進行加載。其新型微架構專為可拓展性而構建,能夠將多種內部和外部制程技術與先進的封裝技術相結合,從而量身定制產品。
此外,基于業界對于深度學習訓練的需求不斷增長,深度學習訓練模型為提高準確性也變得越來越大,訓練這些模型導致計算消耗和相關成本呈指數級飆升,市場對于專用深度學習訓練處理器也日益迫切。在這一背景下,英特爾又推出了Habana Gaudi處理器。這個取自畫家之名的處理器可以在云端和數據中心提高深度學習訓練效率。據資料顯示,Gaudi加速器提高了Amazon EC2訓練實例的效率,與目前基于GPU的實例相比,性能比最多可提高40%。
開發者福音:通向跨架構編程的可能
當硬件體系漸趨完善,GPU、FPGA以及各種針對不同應用而開發的專用芯片與CPU一起組成復雜的異構平臺時,新的問題應運而生。
一般而言,要發揮這種異構平臺的性能,開發者需要深入了解底層硬件的體系結構,以便針對性的利用各個異構單元的優勢。但事實上,在普通的軟件工程師或算法工程師群體中,能夠了解和掌握這些硬件相關的開發知識的人往往寥寥無幾。
針對這一點,英特爾推出了oneAPI工具包。oneAPI早在2018年底舉行的英特爾架構日上就已亮相,其在英特爾生態布局中的地位不言而喻。
oneAPI提供了一個統一的軟件編程接口,這使得應用程序開發者可以專注于算法和應用的開發,而無需關心太多底層細節的實現。除了編程接口外,oneAPI還會包含完整的開發環境、軟件庫、驅動程序、調試工具等要素,而且這些加速庫都已經針對底層硬件進行了優化設計。以Neural Compressor為例,作為一種開源Python庫,它可以跨多個面向CPU和GPU的英特爾優化深度學習框架自動進行模型壓縮,將優化時間縮短達一個數量級。
對開發者來說,oneAPI提供的是一種通用、開放的編程體驗,讓開發者可以自由選擇架構,而無需在性能上作出妥協,同時也大大降低了使用不同的代碼庫、編程語言、編程工具和工作流程所帶來的復雜性。
部署神器OpenVINO的的進化
在人工智能領域,只有同時提供硬件和軟件生態,才能在激烈的競爭中殺出一席之地。為了充分挖掘處理器的性能,各個廠家都發布了各種軟件框架和工具。OpenVINO是英特爾推出的一款全面的工具套件,用于快速部署應用和解決方案。
通常人工智能應用開發中,當模型訓練結束,上線部署時會遇到各種問題:模型性能是否滿足線上要求?模型如何嵌入到原有工程系統?這些問題在很大程度上決定著投資回報率。只有深入且準確地理解深度學習框架,才能更好地滿足上線要求。但遺憾的是,新的算法模型和所用框架層出不窮,要求開發者隨時掌握未免強人所難。
OpenVINO針對的就是這一痛點。作為Pipeline工具集,OpenVINO可以兼容各種開源框架訓練好的模型,擁有算法模型上線部署的各種能力。這就意味著,只要掌握了這一工具,你可以輕松地將預訓練模型在英特爾的CPU上快速部署起來。
在歷時三年多的時間里,OpenVINO在不斷改進中。據了解,OpenVINO2022.1的2.0版本將在第一季度發布。這一版本有三大突破:
其一,針對給開發人員造成的問題進行重要升級,包括將更多默認值合并到模型轉換,API內保留原有架構內的模型輸入布局和精度,從而減少代碼更改;
其二,從根源上改進了OpenVINO在計算機視覺方面的表現,使其現在可支持橫跨從邊緣到云端的廣泛模型,尤其是自然語言處理和文本分類;
其三,新增自動硬件目標優化功能,全新自動插件可以自動發現系統加速器并與推理模型要求進行匹配,這大大優化了延遲與吞吐量。
結語
在本屆英特爾 On技術創新峰會上,英特爾面向人工智能領域展現出了一種鮮明的態度:不是要將某幾個硬件產品做強,而是要面向AI市場,提供從硬件到軟件的全棧解決方案。英特爾投資多個人工智能架構以滿足不同的用戶需求,使用開放的基于標準的編程模型,使開發人員更容易在更多的用例中運行更多的人工智能工作負載。
在人工智能這一賽道上,英特爾也為其他同業競爭者樹立了標桿:在原有的硬件開發能力基礎上,通過對英特爾至強可擴展處理器上的流行庫和框架進行廣泛優化,使開發人員更容易獲得和擴展AI。英特爾致力于攜手合作伙伴、擁抱開發者,共建AI創新生態,共創“AI Everywhere”的圖景。無盡的遠方,有觸手可及的未來。
???
【51CTO原創稿件,合作站點轉載請注明原文作者和出處為51CTO.com】