













強化學(xué)習(xí)AI能帶你1打5嗎?MIT新研究:AI并不是人類的最佳隊友
強化學(xué)習(xí)的AI在圍棋、星際爭霸、王者榮耀等游戲以絕對的優(yōu)勢碾壓了人類玩家,也證明了思維能力可以通過模擬來得到。
但如果這么強的AI成為了你的隊友,能被帶飛嗎?
MIT林肯實驗室的研究人員最近的在紙牌游戲Hanabi(花火)中人類和AI agenet之間的合作研究結(jié)果表明,盡管RL agent的個人表現(xiàn)能力十分出色,但當跟人類玩家一起匹配的時候,卻只會讓人直呼太坑。
 最佳隊友">
最佳隊友">https://arxiv.org/pdf/2107.07630.pdf
Hanabi是一個需要玩家之間互相溝通合作取勝的游戲,在這個游戲中,人類玩家更喜歡可預(yù)測的基于規(guī)則的AI系統(tǒng),而非黑盒的神經(jīng)網(wǎng)絡(luò)模型。
 最佳隊友">
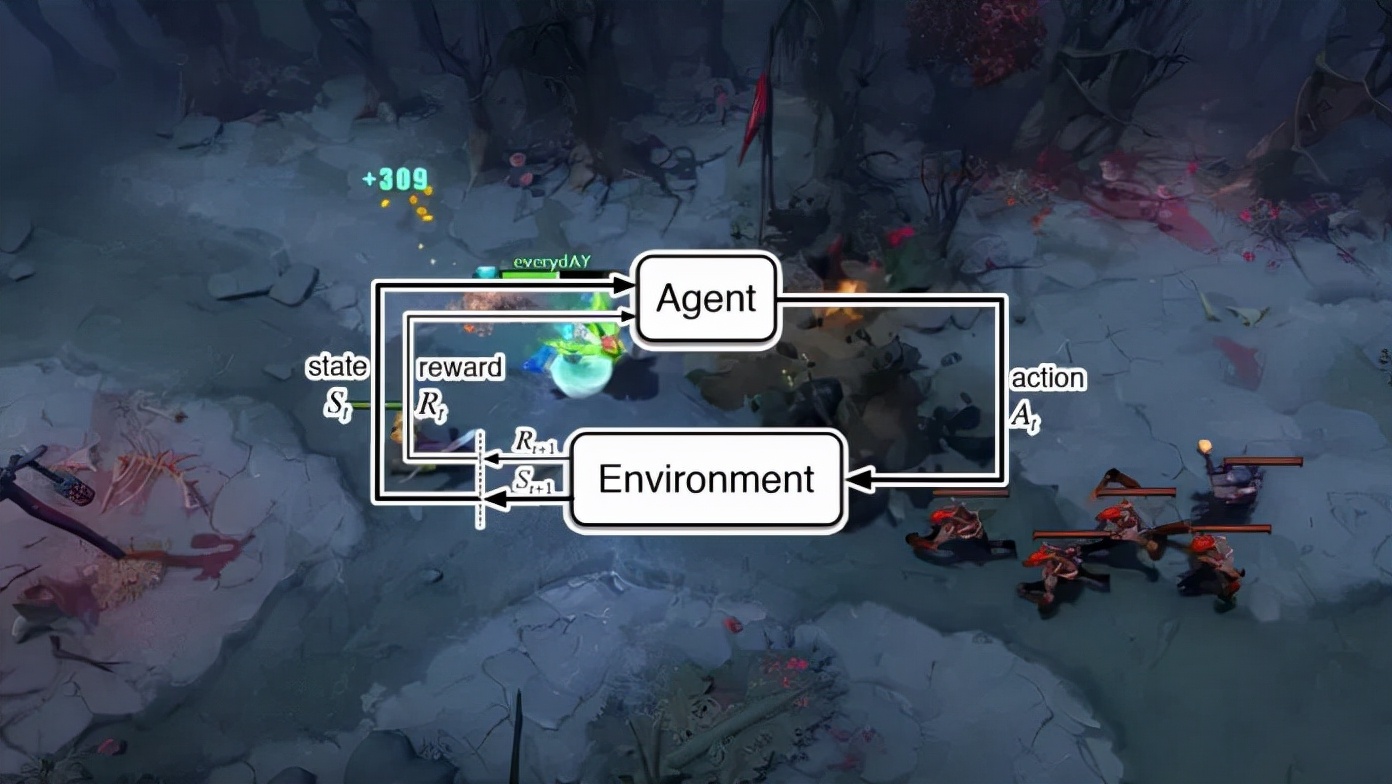
最佳隊友">一般來說,最先進的游戲機器人使用的算法都是深度強化學(xué)習(xí)(deep reinforcement learning)。首先通過在游戲中提供一個agent和一組可能的候選action集合,通過來自環(huán)境的反饋機制來進行學(xué)習(xí)。在訓(xùn)練過程中,還會采用隨機的探索action來最大化目標,從而獲得最優(yōu)的action序列。
深增強學(xué)習(xí)的早期研究依靠人類玩家提供的游戲數(shù)據(jù)進行學(xué)習(xí)。最近研究人員已經(jīng)能夠在沒有人類數(shù)據(jù)的情況下,純粹依靠自我博弈來開發(fā)RL agent。
MIT 林肯實驗室的研究人員更關(guān)注讓如此強大的AI 如何成為隊友,這項工作也能讓我們進一步了解是什么阻礙了強化學(xué)習(xí)的應(yīng)用只能局限于電子游戲,而無法擴大到現(xiàn)實應(yīng)用中。
 最佳隊友">
最佳隊友">最近的強化學(xué)習(xí)研究大多應(yīng)用于單人游戲(Atari Breakout 打磚塊)或者對抗性游戲(星際爭霸,圍棋),其中AI 主要的對手是人類玩家或者是其他的AI 機器人。
在這些對抗中,強化學(xué)習(xí)取得了空前的成功,因為機器人對這些游戲并沒有一些先入為主的偏見和假設(shè),而是從零開始學(xué)習(xí)打游戲,并以最好的玩家數(shù)據(jù)進行訓(xùn)練。
事實上,AI學(xué)會打游戲以后,甚至還會自己創(chuàng)造一些技巧。一個有名的例子是DeepMind的alphago在它的比賽中下了一步棋,但分析師當時認為這一步棋是一個錯誤,因為它違背了人類專家的直覺。
但同樣的舉動卻帶來了不一樣的結(jié)果,AI最后憑借這手成功擊敗了人類。所以當RL agent與人類合作時,研究人員認為同樣的聰明才智也可以發(fā)揮作用。
在MIT研究人員的實驗中選擇了紙牌游戲Hanabi,其中包括兩到五名玩家,他們必須合作以特定的順序出牌。Hanabi 很簡單,但它也是一個需要合作和有限的信息的游戲。
Hanabi游戲發(fā)明于2010年,由二到五個玩家參與,玩家需以正確的順序一起打出五種不同顏色的牌。游戲特點:所有玩家都可以看到對方的牌,但卻看不到自己的牌。
根據(jù)游戲規(guī)則,玩家可以互相提示自己手里的牌(但僅限于牌的顏色或數(shù)字),讓其他玩家可以推斷他們應(yīng)該出什么牌,但提示的次數(shù)是有限制的。
正是這種高效溝通的行為使Hanabi具備了一種科學(xué)魅力。例如,人類可以很自然地理解其他玩家的提示,哪張卡片是可出的,但是機器本質(zhì)上無法理解這些提示。
到目前為止人工智能程序已經(jīng)可以在玩Hanabi花火游戲時贏得很高分數(shù),但只限于與其他類似的智能機器人一起玩。在不熟悉其他玩家的游戲風格或者有「臨時」(從未一起玩過的)玩家的情況下,對程序的挑戰(zhàn)最大,也更接近真實情況。
近年來,幾個研究團隊探討了可以玩Hanabi的AI機器人的發(fā)展,其中一些強化學(xué)習(xí)agent使用符號AI。
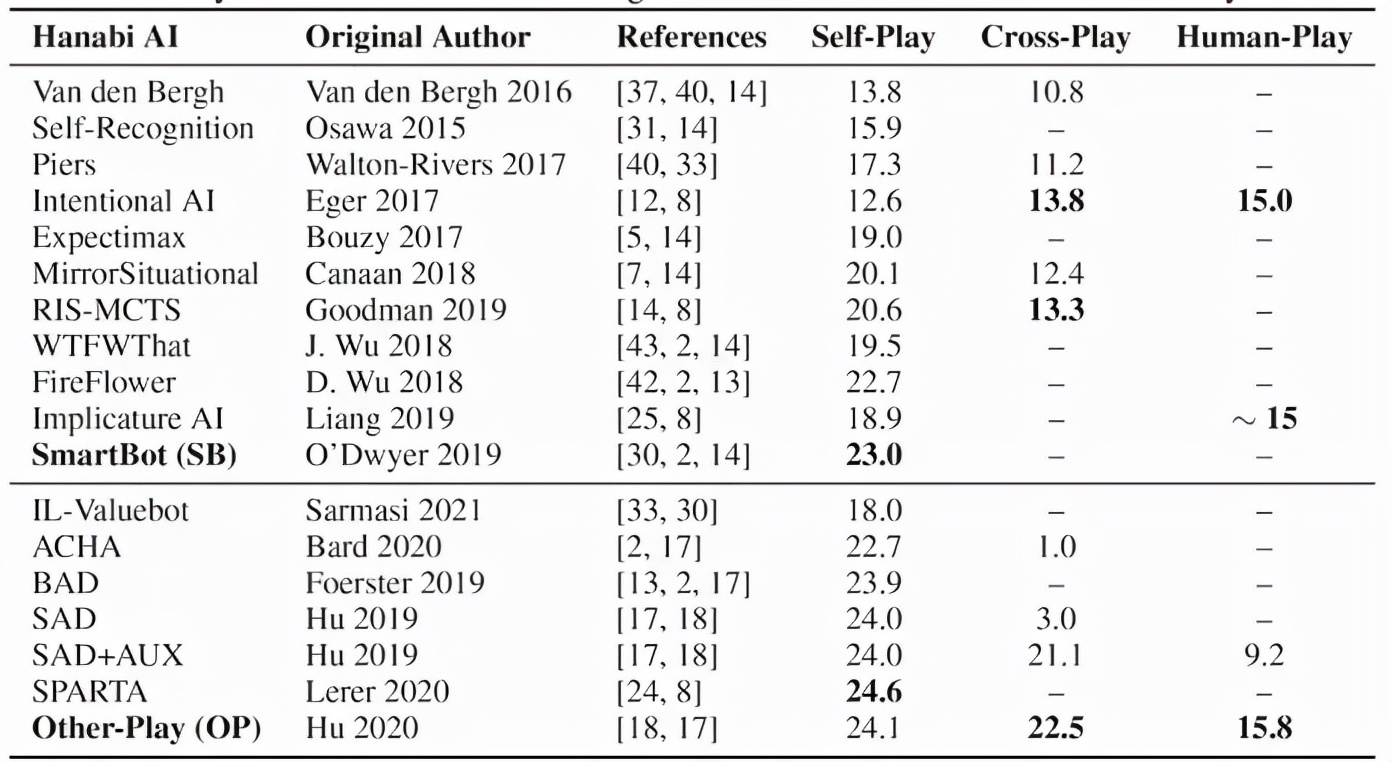
AI的評估主要采用他們的性能,包括self-play(和自己玩),cross-play(和其他類型的agent一起玩),Human-play(和人類合作)。
 最佳隊友">
最佳隊友">和人類玩家之間的cross-play,對于衡量人與機器之間的合作尤為重要,也是論文實驗的基礎(chǔ)。
為了檢驗人工智能協(xié)作的有效性,研究人員使用了SmartBot,這是一種基于規(guī)則的self-play人工智能系統(tǒng),還有一種在跨游戲和RL算法中排名最高的模型Hanabi機器人Other-Play。
在實驗中,人類參與者與AI agent一起玩了幾次Hanabi游戲,每次隊友的AI都不相同,實驗人員并不知道在和哪個模型一起玩。
研究人員根據(jù)客觀和主觀指標評估了人類AI合作的水平。客觀指標包括分數(shù)、錯誤率等。主觀指標包括人類玩家的經(jīng)驗,包括他們對AI團隊成員的信任和舒適程度,以及他們理解AI動機和預(yù)測其行為的能力。
兩種人工智能模型的客觀表現(xiàn)無顯著差異。但研究人員預(yù)計,人類玩家對Other-Play有更積極的主觀體驗,因為他們接受過與其他玩家合作的訓(xùn)練。
根據(jù)對參與者的調(diào)查,與基于規(guī)則的SmartBot Agent相比,經(jīng)驗豐富的Hanabi玩家在其他游戲RL算法方面的經(jīng)驗較少,成功的一個關(guān)鍵點是為其他玩家提供偽裝線索的技能。
例如,說「一個方塊」卡放在桌子上,你的隊友手里拿著兩個方塊。當你指著卡片說「這是兩張」或「這是一個正方形」時,你暗地里告訴你的隊友玩這張卡片,而不告訴他關(guān)于卡片的全部信息。一個經(jīng)驗豐富的玩家會立刻就能夠領(lǐng)會這個提示。但向AI 隊友提供相同類型的信息證明要困難得多。
一個參與者表示,我已經(jīng)給了隊友很明顯的提示了,但他根本就沒用,我不知道為什么。
一個有趣的現(xiàn)實是,Other-play一直在避免創(chuàng)建「秘密」的約定,他們只是在執(zhí)行self-play時開發(fā)的這些預(yù)定規(guī)則。這使得Other-play成為其他AI算法的最佳隊友,盡管AI算法并不是其訓(xùn)練計劃的一部分。但研究人員認為,這是他在訓(xùn)練過程中已經(jīng)假設(shè)了會遇到哪些類型的隊友。
值得注意的是,Other-play假設(shè)隊友也針對zero-shot 協(xié)調(diào)進行了優(yōu)化。相比之下,人類Hanabi玩家通常不會使用這種假設(shè)進行學(xué)習(xí)。
游戲前常規(guī)設(shè)置和游戲后復(fù)盤是人類Hanabi玩家的常見做法,使人類學(xué)習(xí)更容易獲得few-shot協(xié)調(diào)的能力。
研究人員表示,目前的研究結(jié)果表明,人工智能的客觀任務(wù)表現(xiàn)(self-play和cross-play)在與其他AI模型合作時,可能與人類的信任和偏好無關(guān)。
這就產(chǎn)生了一個問題:哪些客觀指標與主觀的人類偏好相關(guān)?
鑒于訓(xùn)練基于RL的agent所需的數(shù)據(jù)量巨大,訓(xùn)練環(huán)中的人是不可行的。因此,如果我們想訓(xùn)練被人類合作者接受和評估的AI agent,我們需要找到可訓(xùn)練的,可以替代或與人類偏好密切相關(guān)的目標函數(shù)。
同時,研究人員也說明,不要將Hanabi實驗的結(jié)果外推到他們無法測試的其他環(huán)境、游戲或領(lǐng)域。
論文還承認了實驗中的一些局限性,研究人員正在努力解決這些局限性。例如,受試者群體很小(只有29名參與者),并且偏向于精通Hanabi的人,這意味著他們已經(jīng)預(yù)先定義了AI團隊成員的行為期望,并且更有可能對RL agent有負面體驗。
然而,研究結(jié)果對未來加強學(xué)習(xí)研究具有重要意義。
如果最先進的RL agent甚至不能在一個限制性和窄范圍的游戲中成為一個可以接受的合作者,那么我們真的應(yīng)該期待同樣的RL技術(shù)在應(yīng)用于更復(fù)雜、更微妙、更具后果性的游戲和現(xiàn)實世界的情況時只是可以用。
在技術(shù)和學(xué)術(shù)領(lǐng)域,關(guān)于強化學(xué)習(xí)的爭論很多,而且確實如此,研究結(jié)果也表明不應(yīng)將RL系統(tǒng)的顯著性能視為在所有可能的應(yīng)用中都能獲得相同的高性能。
在學(xué)習(xí)型智能體在復(fù)雜的人類機器人交互等情況下成為有效的合作者之前,需要更多的理論和應(yīng)用工作。




















