讓我們,從頭到尾,通透I/O模型

文末本文轉載自微信公眾號「yes的練級攻略」,作者是Yes呀。轉載本文請聯系yes的練級攻略公眾號。
你好,我是yes。
上篇我們已經搞懂了 socket 的通信內幕,也明白了網絡 I/O 確實會有很多阻塞點,阻塞 I/O 隨著用戶數的增長只能利用增加線程的方式來處理更多的請求,而線程不僅會占用內存資源且太多的線程競爭會導致頻繁地上下文切換產生巨大的開銷。
因此,阻塞 I/O 已經不能滿足需求,所以后面大佬們不斷地優化和演進,提出了多種 I/O 模型。
在 UNIX 系統下,一共有五種 I/O 模型,今天我們就來盤一盤它!
不過在介紹 I/O 模型之前,我們需要先了解一下前置知識。
內核態和用戶態
我們的電腦可能同時運行著非常多的程序,這些程序分別來自不同公司。
誰也不知道在電腦上跑著的某個程序會不會發瘋似得做一些奇怪的操作,比如定時把內存清空了。
因此 CPU 劃分了非特權指令和特權指令,做了權限控制,一些危險的指令不會開放給普通程序,只會開放給操作系統等特權程序。
你可以理解為我們的代碼調用不了那些可能會產生“危險”操作,而操作系統的內核代碼可以調用。
這些“危險”的操作指:內存的分配回收,磁盤文件讀寫,網絡數據讀寫等等。
如果我們想要執行這些操作,只能調用操作系統開放出來的 API ,也稱為系統調用。
這就好比我們去行政大廳辦事,那些敏感的操作都由官方人員幫我們處理(系統調用),所以道理都是一樣的,目的都是為了防止我們(普通程序)亂來。
這里又有兩個名詞:
- 用戶空間
- 內核空間。
我們普通程序的代碼是跑在用戶空間上的,而操作系統的代碼跑在內核空間上,用戶空間無法直接訪問內核空間的。當一個進程運行在用戶空間時就處于用戶態,運行在內核空間時就處于內核態。
當處于用戶空間的程序進行系統調用,也就是調用操作系統內核提供的 API 時,就會進行上下文的切換,切換到內核態中,也時常稱之為陷入內核態。
那為什么開頭要先介紹這個知識點呢?
因為當程序請求獲取網絡數據的時候,需要經歷兩次拷貝:
程序需要等待數據從網卡拷貝到內核空間。
因為用戶程序無法訪問內核空間,所以內核又得把數據拷貝到用戶空間,這樣處于用戶空間的程序才能訪問這個數據。
介紹這么多就是讓你理解為什么會有兩次拷貝,且系統調用是有開銷的,因此最好不要頻繁調用。
然后我們今天說的 I/O 模型之間的差距就是這拷貝的實現有所不同!
今天我們就以 read 調用,即讀取網絡數據為例子來展開 I/O 模型。
發車!
同步阻塞 I/O
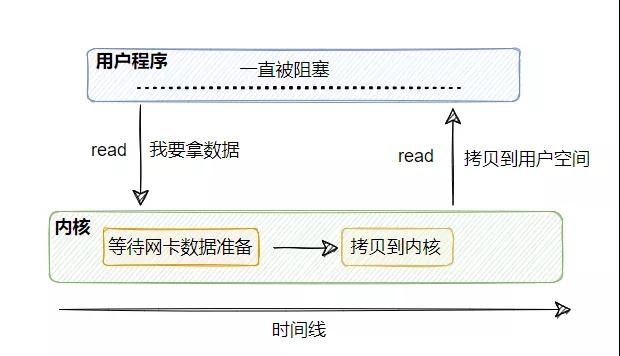
當用戶程序的線程調用 read 獲取網絡數據的時候,首先這個數據得有,也就是網卡得先收到客戶端的數據,然后這個數據有了之后需要拷貝到內核中,然后再被拷貝到用戶空間內,這整一個過程用戶線程都是被阻塞的。
假設沒有客戶端發數據過來,那么這個用戶線程就會一直阻塞等著,直到有數據。即使有數據,那么兩次拷貝的過程也得阻塞等著。
所以這稱為同步阻塞 I/O 模型。
它的優點很明顯,簡單。調用 read 之后就不管了,直到數據來了且準備好了進行處理即可。
缺點也很明顯,一個線程對應一個連接,一直被霸占著,即使網卡沒有數據到來,也同步阻塞等著。
我們都知道線程是屬于比較重資源,這就有點浪費了。
所以我們不想讓它這樣傻等著。
于是就有了同步非阻塞 I/O。
同步非阻塞 I/O
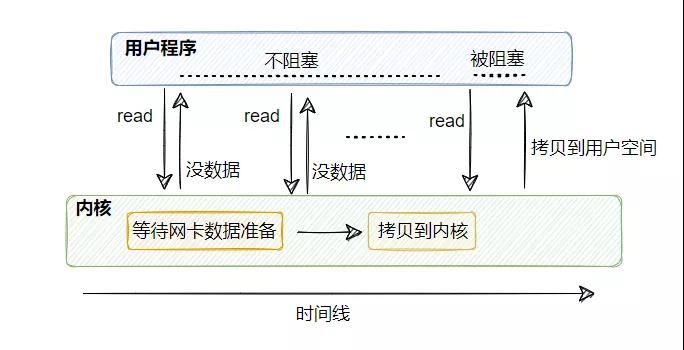
從圖中我們可以很清晰的看到,同步非阻塞I/O 基于同步阻塞I/O 進行了優化:
在沒數據的時候可以不再傻傻地阻塞等著,而是直接返回錯誤,告知暫無準備就緒的數據!
這里要注意,從內核拷貝到用戶空間這一步,用戶線程還是會被阻塞的。
這個模型相比于同步阻塞 I/O 而言比較靈活,比如調用 read 如果暫無數據,則線程可以先去干干別的事情,然后再來繼續調用 read 看看有沒有數據。
但是如果你的線程就是取數據然后處理數據,不干別的邏輯,那這個模型又有點問題了。
等于你不斷地進行系統調用,如果你的服務器需要處理海量的連接,那么就需要有海量的線程不斷調用,上下文切換頻繁,CPU 也會忙死,做無用功而忙死。
那怎么辦?
于是就有了I/O 多路復用。
I/O 多路復用
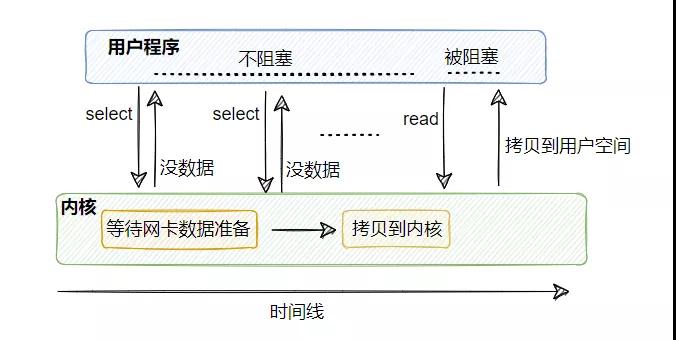
從圖上來看,好像和上面的同步非阻塞 I/O 差不多啊,其實不太一樣,線程模型不一樣。
既然同步非阻塞 I/O 在太多的連接下頻繁調用太浪費了, 那就招個專員吧。
這個專員工作就是管理多個連接,幫忙查看連接上是否有數據已準備就緒。
也就是說,可以只用一個線程查看多個連接是否有數據已準備就緒。
具體到代碼上,這個專員就是 select ,我們可以往 select 注冊需要被監聽的連接,由 select 來監控它所管理的連接是否有數據已就緒,如果有則可以通知別的線程來 read 讀取數據,這個 read 和之前的一樣,還是會阻塞用戶線程。
這樣一來就可以用少量的線程去監控多條連接,減少了線程的數量,降低了內存的消耗且減少了上下文切換的次數,很舒服。
想必到此你已經理解了什么叫 I/O 多路復用。
所謂的多路指的是多條連接,復用指的是用一個線程就可以監控這么多條連接。
看到這,你再想想,還有什么地方可以優化的?
信號驅動式I/O
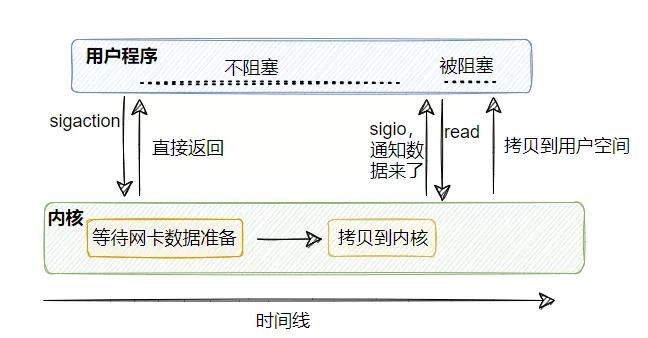
上面的 select 雖然不阻塞了,但是他得時刻去查詢看看是否有數據已經準備就緒,那是不是可以讓內核告訴我們數據到了而不是我們去輪詢呢?
信號驅動 I/O 就能實現這個功能,由內核告知數據已準備就緒,然后用戶線程再去 read(還是會阻塞)。
聽起來是不是比 I/O 多路復用好呀?那為什么好像很少聽到信號驅動 I/O?
為什么市面上用的都是 I/O 多路復用而不是信號驅動?
因為我們的應用通常用的都是 TCP 協議,而 TCP 協議的 socket 可以產生信號事件有七種。
也就是說不僅僅只有數據準備就緒才會發信號,其他事件也會發信號,而這個信號又是同一個信號,所以我們的應用程序無從區分到底是什么事件產生的這個信號。
那就麻了呀!
所以我們的應用基本上用不了信號驅動 I/O,但如果你的應用程序用的是 UDP 協議,那是可以的,因為 UDP 沒這么多事件。
因此,這么一看對我們而言信號驅動 I/O 也不太行。
異步 I/O
信號驅動 I/O 雖然對 TCP 不太友好,但是這個思路對的:往異步發展,但是它并沒有完全異步,因為其后面那段 read 還是會阻塞用戶線程,所以它算是半異步。
因此,我們得想下如何弄成全異步的,也就是把 read 那步阻塞也省了。
其實思路很清晰:讓內核直接把數據拷貝到用戶空間之后再告知用戶線程,來實現真正的非阻塞I/O!
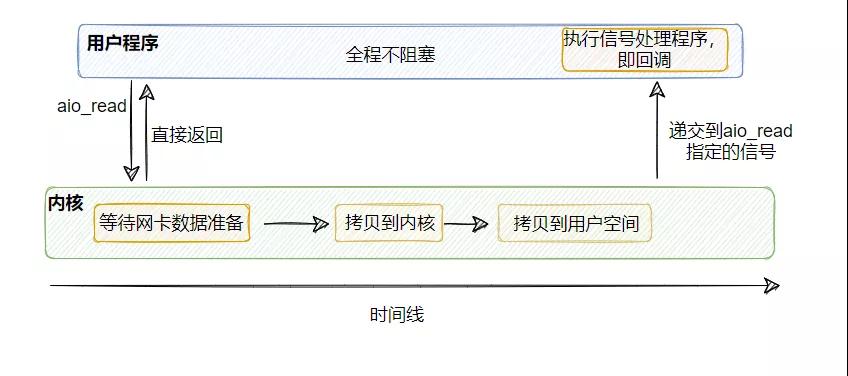
所以異步 I/O 其實就是用戶線程調用 aio_read ,然后包括將數據從內核拷貝到用戶空間那步,所有操作都由內核完成,當內核操作完畢之后,再調用之前設置的回調,此時用戶線程就拿著已經拷貝到用戶控件的數據可以繼續執行后續操作。
在整個過程中,用戶線程沒有任何阻塞點,這才是真正的非阻塞I/O。
那么問題又來了:
為什么常用的還是I/O多路復用,而不是異步I/O?
因為 Linux 對異步 I/O 的支持不足,你可以認為還未完全實現,所以用不了異步 I/O。
這里可能有人會說不對呀,像 Tomcat 都實現了 AIO的實現類,其實像這些組件或者你使用的一些類庫看起來支持了 AIO(異步I/O),實際上底層實現是用 epoll 模擬實現的。
而 Windows 是實現了真正的 AIO,不過我們的服務器一般都是部署在 Linux 上的,所以主流還是 I/O 多路復用。
最后
至此,想必你已經清晰五種 I/O 模型是如何演進的了。
下篇,我將講講談到網絡 I/O 經常會伴隨的幾個容易令人混淆的概念:同步、異步、阻塞、非阻塞。
參考:
https://time.geekbang.org/column/article/100307
https://zhuanlan.zhihu.com/p/266950886
我是yes,從一點點到億點點,我們下篇見~