記一次 Kubernetes 排錯實戰
背景
收到測試環境集群告警,登陸Kubernetes集群進行排查。
故障定位
查看Pod
查看kube-system node2節點calico pod異常。
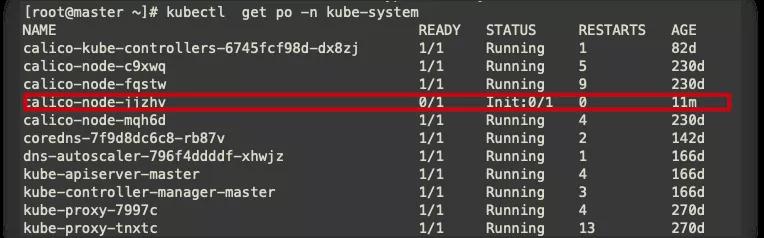
查看詳細信息,查看node2節點沒有存儲空間,cgroup泄露。

查看存儲
登陸node2查看服務器存儲信息,目前空間還很充足。
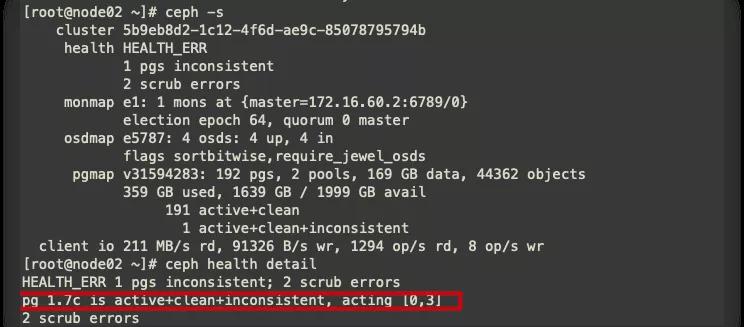
集群使用到的分布式存儲為Ceph,因此查看Ceph集群狀態。
操作
Ceph修復
目前查看到Ceph集群異常,可能導致node2節點cgroup泄露異常,進行手動修復Ceph集群。
數據的不一致性(inconsistent)指對象的大小不正確、恢復結束后某副本出現了對象丟失的情況。數據的不一致性會導致清理失敗(scrub error)。
Ceph在存儲的過程中,由于特殊原因,可能遇到對象信息大小和物理磁盤上實際大小數據不一致的情況,這也會導致清理失敗。
數據的不一致性(inconsistent)指對象的大小不正確、恢復結束后某副本出現了對象丟失的情況。數據的不一致性會導致清理失敗(scrub error)。
Ceph在存儲的過程中,由于特殊原因,可能遇到對象信息大小和物理磁盤上實際大小數據不一致的情況,這也會導致清理失敗。

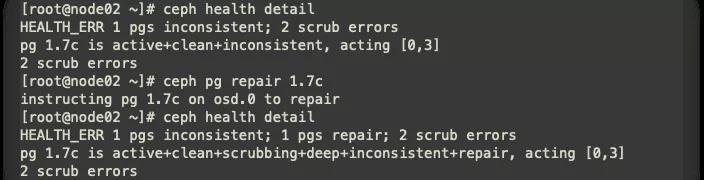
由圖可知,pg編號1.7c 存在問題,進行修復。
pg修復:
- ceph pg repair 1.7c
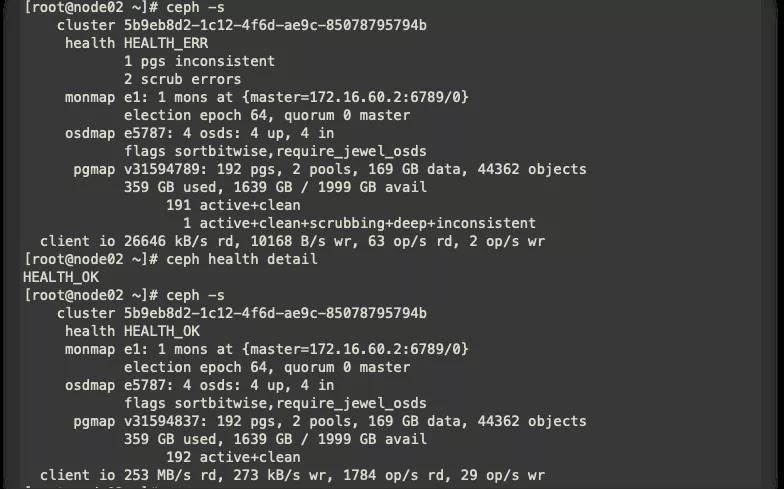
進行修復后,稍等一會,再次進行查看,Ceph集群已經修復。
進行Pod修復
對異常Pod進行刪除,由于有控制器,會重新拉起最新的Pod。

查看Pod還是和之前一樣,分析可能由于Ceph異常,導致node2節點cgroup泄露,網上檢索重新編譯。
Google一番后發現與https://github.com/rootsongjc/kubernetes-handbook/issues/313這個同學的問題基本一致。存在的可能有:
- Kubelet宿主機的Linux內核過低 - Linux version 3.10.0-862.el7.x86_64
- 可以通過禁用kmem解決
查看系統內核卻是低版本。

故障再次定位
最后,因為在啟動容器的時候runc的邏輯會默認打開容器的kmem accounting,導致3.10內核可能的泄漏問題。
在此需要對no space left的服務器進行reboot重啟,即可解決問題,出現問題的可能為段時間內刪除大量的Pod所致。
初步思路,可以在今后的集群管理匯總,對服務器進行維修,通過刪除節點,并對節點進行reboot處理。
對node2節點進行維護
標記node2為不可調度
- kubectl cordon node02
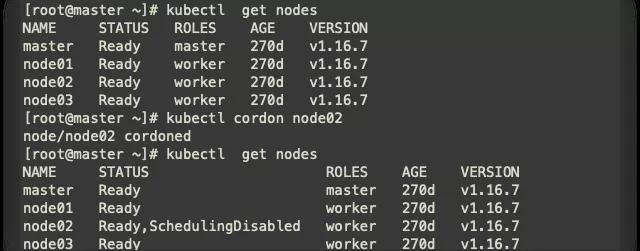
驅逐node2節點上的Pod
- kubectl drain node02 --delete-local-data --ignore-daemonsets --force
- --delete-local-data 刪除本地數據,即使emptyDir也將刪除;
- --ignore-daemonsets 忽略DeamonSet,否則DeamonSet被刪除后,仍會自動重建;
- --force 不加force參數只會刪除該Node節點上的ReplicationController,ReplicaSet,DaemonSet,StatefulSet or Job,加上后所有Pod都將刪除。
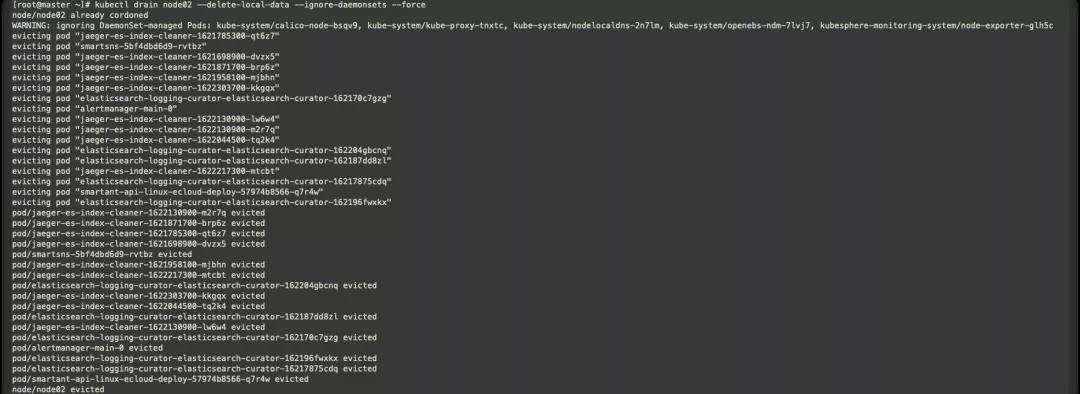
目前查看基本node2的Pod均已剔除完畢。
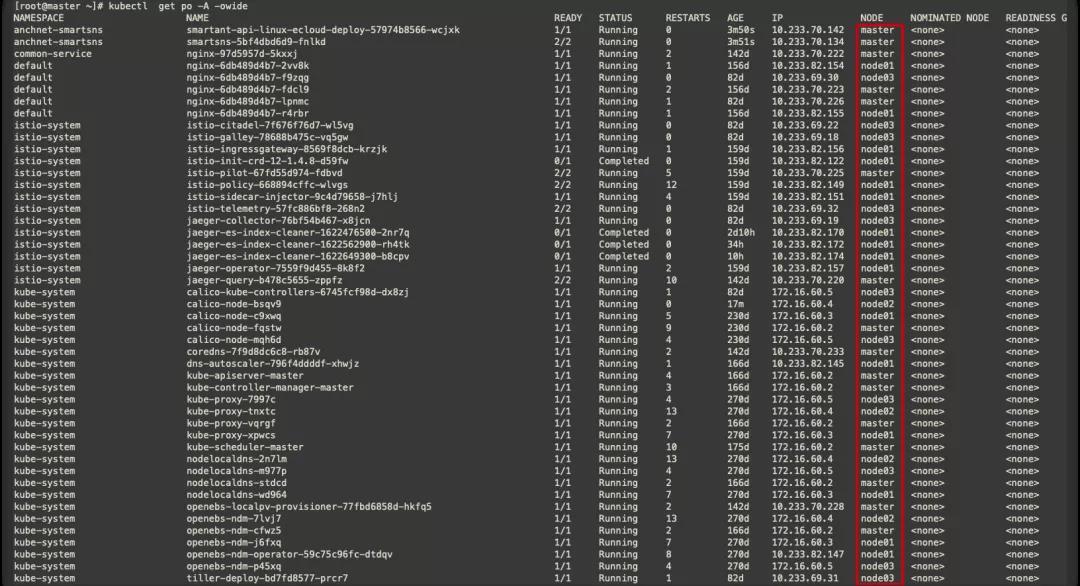
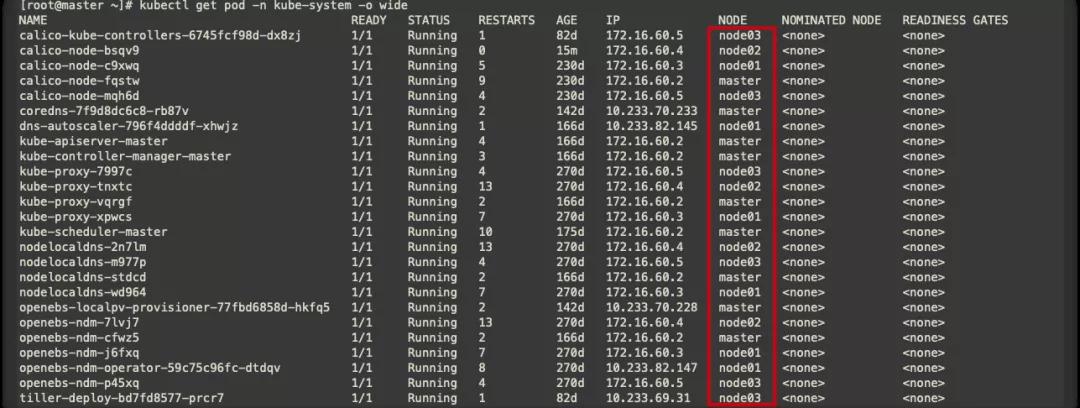
此時與默認遷移不同的是,Pod會先重建再終止,此時的服務中斷時間=重建時間+服務啟動時間+readiness探針檢測正常時間,必須等到1/1 Running服務才會正常。因此在單副本時遷移時,服務終端是不可避免的。
對node02進行重啟
重啟后node02已經修復完成。
對node02進行恢復:
恢復node02可以正常調度。
- kubectl uncordon node02
反思
后期可以對部署Kubernetes集群內核進行升級。
集群內可能Pod的異常,由于底層存儲或者其他原因導致,需要具體定位到問題進行針對性修復。
原文鏈接:https://juejin.cn/post/6969571897659015205