記一次艱難的GC問題排查!
本文轉載自微信公眾號「咖啡拿鐵」,作者咖啡拿鐵。轉載本文請聯系咖啡拿鐵公眾號。
背景
gc問題一直是一個很難排查的問題,但是他又是一個經常在我們開發業務中出現的。這不,最近在我的項目中就出現了一個比較奇葩的gc問題,排查過程比較繁瑣,所以在這里分享一下這個整個排查過程,希望對大家有一定的幫助
排查過程
確定GC出問題
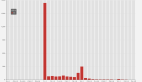
在某一天的上午突然出現了報警,發現是ZK斷開了鏈接,
從圖上看我們這個錯誤是間斷性的出現,最開始以為是zk出現了問題,后來經過排查其他服務的zk并沒有出現任何問題。所以就懷疑是內部的代碼出現問題導致的,研究之后發現是zk出現了心跳超時情況才導致的斷開鏈接,所以就懷疑了兩種情況:
- 網絡有抖動
- 機器間歇性卡死
如果網絡有抖動的話的確是會出現偶發性超時,但是很明顯,其他所有的服務都沒問題,應該不是抖動導致。所以機器應該是間歇性的一個卡死,一般出現這個情況首當其沖的就是我們CPU被打滿了,導致機器卡死,發現CPU并無問題,然后就是我們的gc帶來的STW,會導致我們的jvm進程卡頓。
觀察之后的確是young gc很慢,導致我們的JVM發生了GC卡頓,所以出現了這個現象。
排查原因
GC出現問題一般來說兩大法寶可以解決大部分問題:
- GC日志
- dump文件
出現問題之后我立馬打開了GC日志,截圖如下:
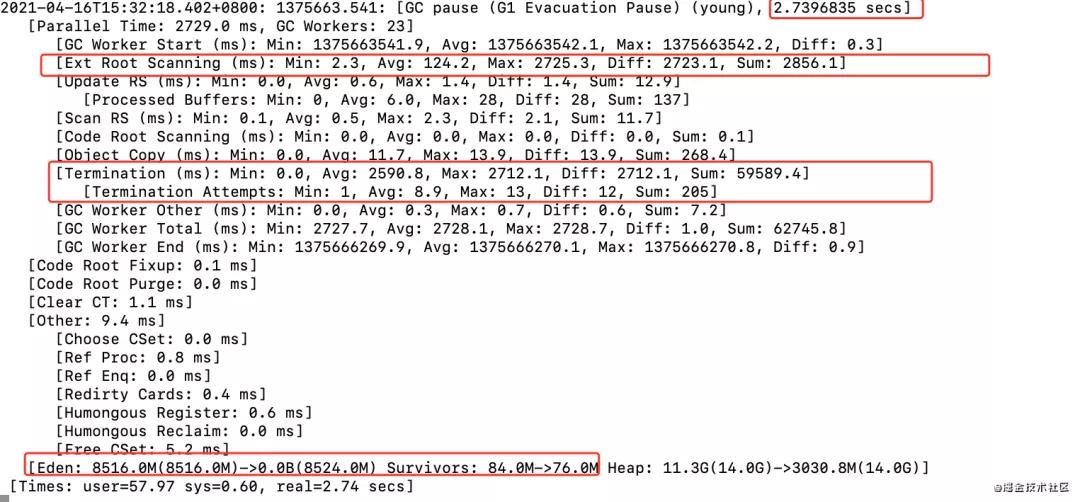
可以發現我們的young gc已經達到2.7s了,大家知道我們的young gc是全程STW的,那就意味著每次gc就會卡頓2.7s,那么zk超時斷開鏈接也就符合正常了。再看了下這個gc收集情況,每次也能完全收集。在日志中很明顯在root scanning的時間比較長,當時對這個階段不太熟悉(后面會繼續講),所以一直也不明白為什么這樣,在網上各種搜索,也沒有結論。
這個時候我在why哥公眾號讀到了一篇文章:https://mp.weixin.qq.com/s/KDUccdLALWdjNBrFjVR74Q, 建議大家可以閱讀一下這篇文章,這個文章中主要談到了我們jvm的一個優化,大家都知道我們進入STW的時候是需要一個安全點才可以的,而詢問是否進入到安全點是需要耗費資源的,所以jvm在做jit優化的時候會講counted loop 也就是計數循環優化成整個循環結束之后再進入安全點,在小米的技術文章中也提到了相關的問題:《HBase實戰:記一次Safepoint導致長時間STW的踩坑之旅》 。
看完這兩個文章之后,我突然想到了我們的代碼也是counted loop的形式,所以就懷疑有可能也是這個問題導致的,馬上進行代碼優化,將for(int i = 0; i< n; i++) 中的int 換成了long,就可以避免這種jit的優化,馬上興沖沖的將其上線,結果過了一天之后依然存在這個問題,此時人都快崩潰,搞了半天原來不是這個問題導致的。
定位問題
對于G1之前只是看了些原理相關的,但是此時原理相關的東西好像在這里基本沒啥用,所以我決定系統性的學習一下,這里我選擇的是《jvm G1源碼分析和調優》這本書,在讀到5.4節的時候:
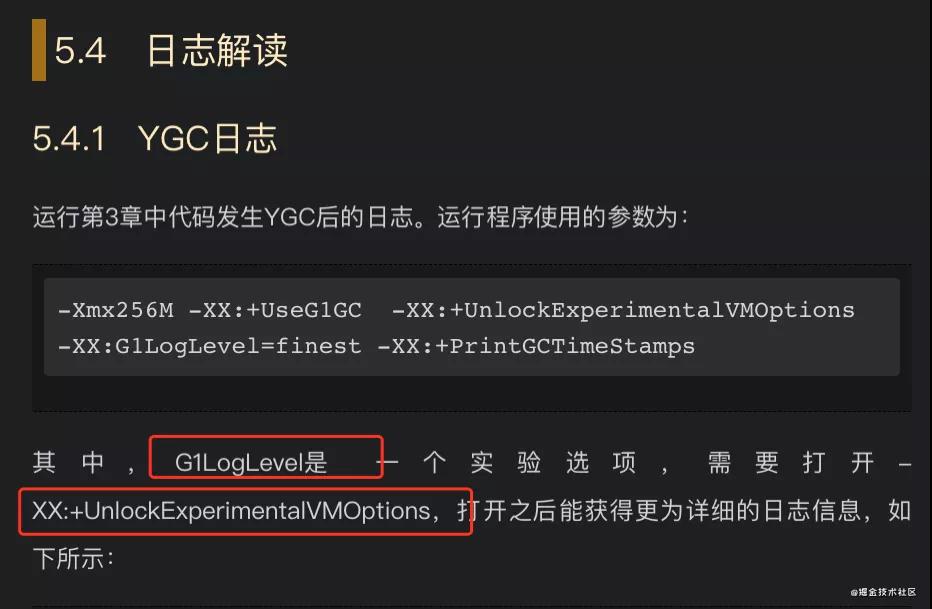
發現有兩個之前沒有見過的參數,一個是G1LogLevel,一個是UnlockExperimentalVMOptions,從解釋說明上來看配置了之后能獲取到更加詳細的YGC日志,于是加上了這個參數然后繼續觀察,日志格式太長,只截取了部分日志信息,有興趣的可以下來自己打印一下:
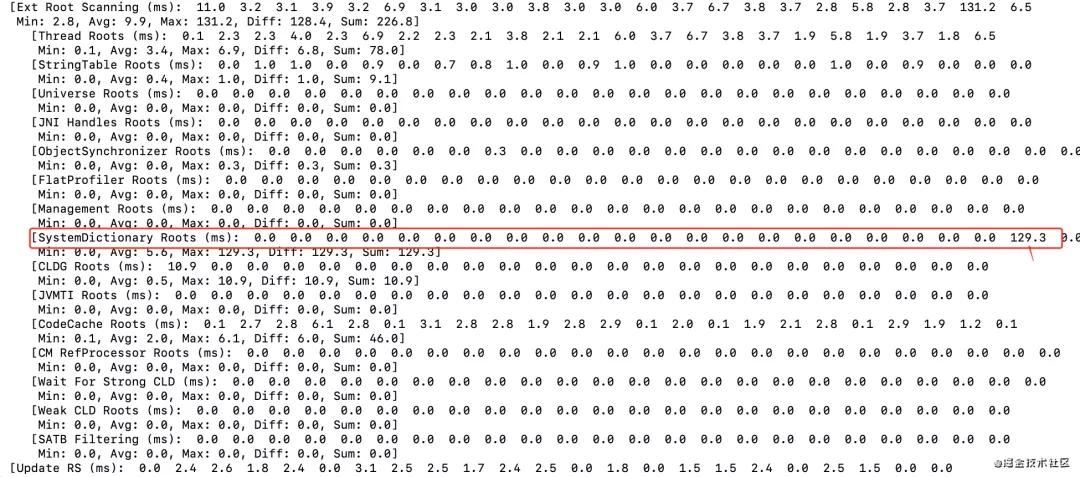
可以發現在SystemDictionary Roots階段是比較慢的,但是這個又是啥玩意呢?在書里面是沒有任何介紹的,于是又進行大量谷歌,終于是找到了一篇你假笨寫的一篇文章:JVM源碼分析之自定義類加載器如何拉長YGC,強烈推薦大家讀完這篇文章。
好了最后我來盤一盤到底為什么會出現gc慢的問題呢?我們這個定時任務是一個定時查詢微信退款信息的,微信的退款信息需要解析XML,就有如下代碼:
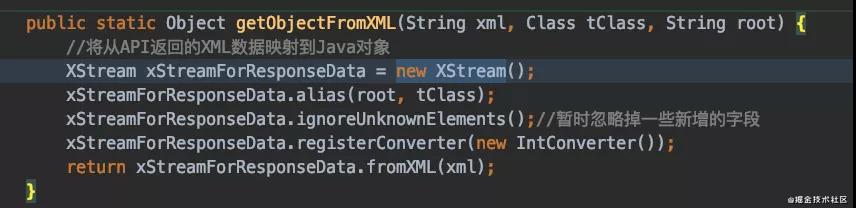
而我們的罪魁禍首其實就在這個new XStream這個方法中,我們的默認構造方法會調用下面的這個構造方法:

需要注意的是我們每次創建一個XStream都會新創建一個ClassLoader,先解釋一下ClassLoader,這里直接引用你假笨的一段話:
這里著重要說的兩個概念是初始類加載器和定義類加載器。舉個栗子說吧,AClassLoader->BClassLoader->CClassLoader,表示AClassLoader在加載類的時候會委托BClassLoader類加載器來加載,BClassLoader加載類的時候會委托CClassLoader來加載,假如我們使用AClassLoader來加載X這個類,而X這個類最終是被CClassLoader來加載的,那么我們稱CClassLoader為X類的定義類加載器,而AClassLoader為X類的初始類加載器,JVM在加載某個類的時候對AClassLoader和CClassLoader進行記錄,記錄的數據結構是一個叫做SystemDictionary的hashtable,其key是根據ClassLoader對象和類名算出來的hash值(其實是一個entry,可以根據這個hash值找到具體的index位置,然后構建一個包含kalssName和classloader對象的entry放到map里),而value是真正的由定義類加載器加載的Klass對象,因為初始類加載器和定義類加載器是不同的classloader,因此算出來的hash值也是不同的,因此在SystemDictionary里會有多項值的value都是指向同一個Klass對象。
我們把這個放到我們的場景來看就是下面這個情況:
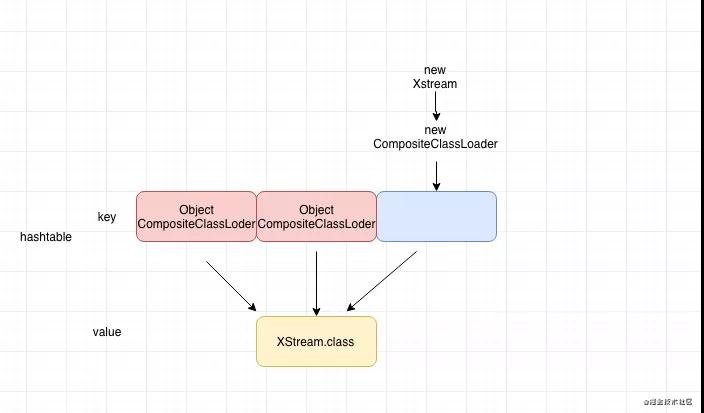
由于我們每次請求都會新創建一個Xstream對象,從而也會新創建一個ClassLoader,由于我們的ClassLoader的key是根據每個對象來算出來的hash值,如果每次都新創建,自然hash值不一樣,從而導致我們有很多ClassLoader指向XStream這個class。為什么SystemDictionary的大小會影響我們GC時間呢?
想象一下這么個情況,我們加載了一個類,然后構建了一個對象(這個對象在eden里構建)當一個屬性設置到這個類(static變量)里,如果gc發生的時候,這個對象是不是要被找出來標活才行,那么自然而然我們加載的類肯定是我們一項重要的gc root,這樣SystemDictionary就成為了gc過程中的被掃描對象了。
我們的class信息是被分配在哪里的呢?在java7的話是在永久代,在java8就來到了元數據空間也就是我們的堆上,所以我們的young gc的時候是不會回收我們的class信息的,那么我們怎么解決這個問題呢?
- java7: 在G1垃圾收集器中,只有在進行full GC的時候,永久代才會被回收,這一過程是stop-the-world的。當不做Full GC的時候,G1運行是最優化的。只有當永久代滿了或者應用分配內存的速度超過了G1回收垃圾的速度的時候,G1才會觸發Full GC。在CMS垃圾收集器中,我們可以使用-XX:+CMSClassUnloadingEnabled在CMS concurrent cycle中回收集永久代。在G1里面沒有對應的設置。G1只有在stop-the-world的Full GC的時候,才會回收永久代。我們可以根據應用的需要,設置PermSize和MaxPermSize參數來調優永久代的大小。
- java8:提供了四個參數-XX:MetaspaceSize,-XX:MaxMetaspaceSize,-XX:MinMetaspaceFreeRatio,-XX:MaxMetaspaceFreeRatio用來控制元空間的大小,當超過比例或者大小的時候就會進行收集。
但是我們這個問題不應該通過垃圾收集去解決,而是應該從根源上去解決,那就是不能使用默認的XStream構造函數,而是需要使用固定ClassLoader的構造函數。

經過修改之后上線,經過觀察,沒有出現慢GC的現象。
最后
經過這次排查的經驗來看,遇到GC問題尤其是那種比較不常見的,真的是非常難搞,你可能需要對這個問題進行系統的學習,以及大量的查找資料才能找到原因,我在排查這個問題的時候掉了不少頭發。在這里記錄一下這個經驗,希望對大家以后的一些排查能有幫助。