













Flink 是如何統一批流引擎的
本文轉載自微信公眾號「大數據技術派」,作者柯廣 。轉載本文請聯系大數據技術派公眾號。
2015 年,Flink 的作者就寫了 Apache Flink: Stream and Batch Processing in a Single Engine 這篇論文。本文以這篇論文為引導,詳細講講 Flink 內部是如何設計并實現批流一體的架構。
前言
unify-blocks
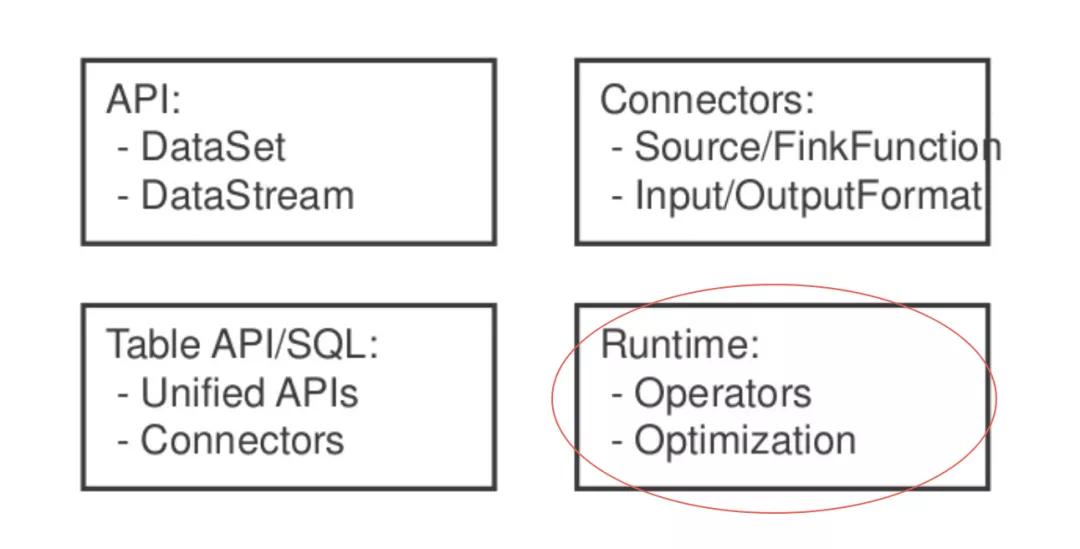
通常我們在 Flink 中說批流一體指的是這四個方向,其中 Runtime 便是 Flink 運行時的實現。
數據交換模型
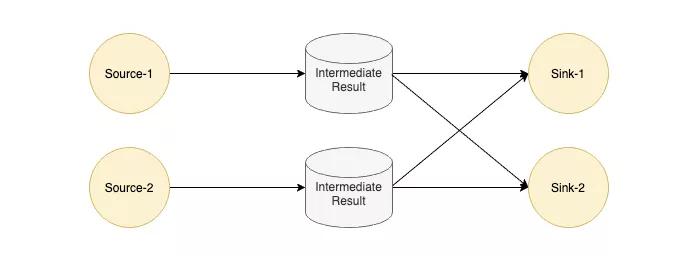
Flink 對于流作業和批作業有一個統一的執行模型。
unify-exec
Flink 中每個 Task 的輸出會以 IntermediateResult 做封裝,內部并沒有對流和批兩種作業做一個明確的劃分,只是通過不同類型的 IntermediateResult 來表達 PIPELINED 和 BLOCKING 這兩大類數據交換模型。
在了解數據交換模型之前,我們來看下為什么 Flink 對作業類型不作區分,這樣的好處是什么?

unify-example
如上圖所示,假如我們有一個工作需要將批式作業執行結果作為流式作業的啟動輸入,那怎么辦?這個作業是算批作業還是流作業?
很顯然,以我們的常識是無法定義的,而現有的工業界的辦法也是如此,將這個作業拆分為兩個作業,先跑批式作業,再跑流式作業,這樣當然可以,但是人工運維的成本也是足夠大的:
需要一個外界存儲來管理批作業的輸出數據。
需要一個支持批流作業依賴的調度系統。
如果期望實現這樣一個作業,那么首先執行這個作業的計算引擎的作業屬性就不能對批作業和流作業進行強綁定。那么 Flink 能否實現這樣的需求呢?我們先來看看數據交換的具體細節,最后再來一起看看這個作業的可行性。
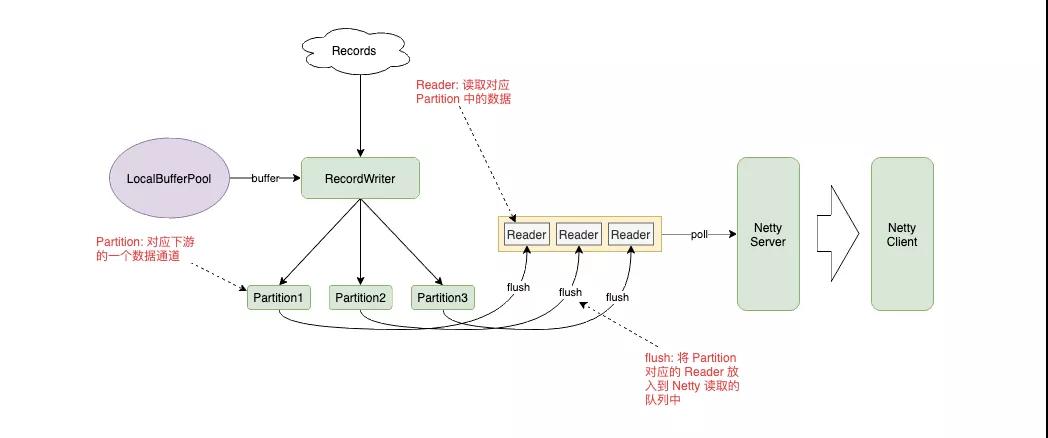
我們以 PIPELINED 數據交換模型為例,看看是如何設計的:
unify-pipelined
PIPELINED 模式下,RecordWriter 將數據放入到 Buffer 中,根據 Key 的路由規則發送給對應的 Partition,Partition 將自己的數據封裝到 Reader 中放入隊列,讓 Netty Server 從隊列中讀取數據,發送給下游。
我們將數據交換模式改為 BLOCKING,會發現這個設計也是同樣可行的。Partition 將數據寫入到文件,而 Reader 中維護著文件的句柄,上游任務結束后調度下游任務,而下游任務通過 Netty Client 的 Partition Request 喚醒對應的 Partition 和 Reader,將數據拉到下游。
調度模型
有 LAZY 和 EAGER 兩種調度模型,默認情況下流作業使用 EAGER,批作業使用 LAZY。
EAGER
這個很好理解,因為流式作業是 All or Nothing 的設計,要么所有 Task 都 Run 起來,要么就不跑。
LAZY
LAZY 模式就是先調度上游,等待上游產生數據或結束后再調度下游。有些類似 Spark 中的 Stage 執行模式。
Region Scheduling
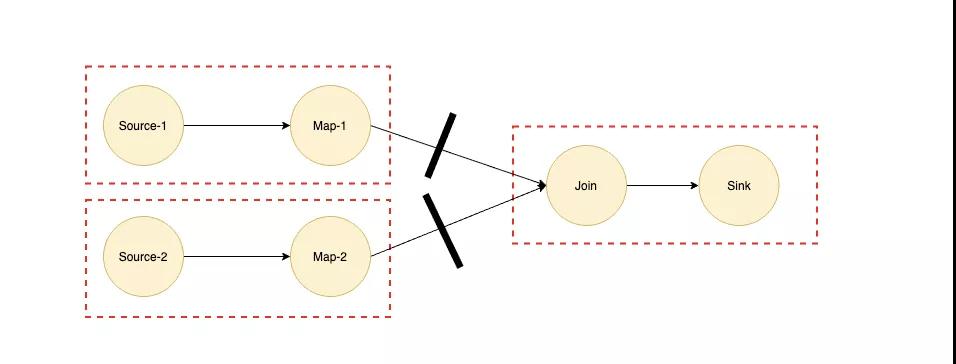
可以看到,不管是 EAGER 還是 LAZY 都沒有辦法執行我們剛才提出的批流混合的任務,于是社區提出了 Region Scheduling 來統一批流作業的調度,我們先看一下如何定義 Region:
unify-region
以 Join 算子為例,我們都知道如果 Join 算子的兩個輸入都是海量數據的話,那么我們是需要等兩個輸入的數據都完全準備好才能進行 Join 操作的,所以 Join 兩條輸入的邊對應的數據交換模式對應的應該是 BLOCKING 模式,我們可以根據 BLOCKING 的邊將作業劃分為多個子 Region,如上圖虛線所示。
如果實現了 Region Scheduling 之后,我們在上面提到的批流混合的作業就可以將深色部分流式作業劃為一個 Region,淺色部分批式作業再劃分為多個 Region,而淺色部分是深色部分 Region 的輸入,所以根據 Region Scheduling 的原則會優先調度最前面的 Region。
總結
上面提到了數據交換模型和調度模型,簡單來講其實就兩句話:
1 實現了用 PIPELINED 模型去跑批式作業
用 PIPELINED 模型跑流式作業和用 BLOCKING 模型跑批式作業都是沒有什么新奇的。這里提到用 PIPELINED 模式跑批作業,主要是針對實時分析的場景,以 Spark 為例,在大部分出現 Shuffle 或是聚合的場景下都會出現落盤的行為,并且調度順序是一個一個 Stage 進行調度,極大地降低了數據處理的實時性,而使用 PIPELINED 模式會對性能有一定提升。
可能有人會問類似 Join 的算子如何使用 PIPELINED 數據交換模型實現不落盤的操作?事實上 Flink 也會落盤,只不過不是在 Join 的兩個輸入端落盤,而是將兩個輸入端的數據傳輸到 Join 算子上,內存撐不住時再進行落盤,海量數據下和 Spark 的行為并沒有本質區別,但是在數據量中等,內存可容納的情況下會帶來很大的收益。
2 集成了一部分調度系統的功能
根據 Region 來調度作業時,Region 內部跑的具體是流作業還是批作業,Flink 自身是不關心的,更關心的 Region 之間的依賴關系,一定程度上,利用這種調度模型我們可以將過去需要拆分為多個作業的執行模式放到一個作業中來執行,比如上面提到的批流混合的作業。
















