你只會用 split?試試 StringTokenizer,性能可以快 4 倍!!
我們都知道,分割字符串要使用 String 的 split() 方法,split 方法雖然深入人心,使用也簡單,但效率太低!
其實在 JDK 中,還有一個性能很強的純字符串分割工具類:StringTokenizer。
這個類在 JDK 1.0 中就推出來了,但在實際工作卻發現很少有人使用,網上有人說不建議使用了,甚至還有人說已經廢棄了,真的是這樣嗎?
StringTokenizer 被廢棄了嗎?
棧長翻閱了一些資料,原來在 Oracle JDK 官方文檔中已經有了描述,這是最新的 Oracle JDK 15 的官方文檔關于 StringTokenizer 的說明:
StringTokenizer is a legacy class that is retained for compatibility reasons although its use is discouraged in new code. It is recommended that anyone seeking this functionality use the split method of String or the java.util.regex package instead.
參考:https://docs.oracle.com/en/java/javase/15/docs/api/java.base/java/util/StringTokenizer.html
StringTokenizer 原來是一個遺留類,并未被廢棄,只是出于兼容性原因而被保留,在新代碼中已經不鼓勵使用它了,建議使用 String 的 split 方法或 java.util.regex 包代替。
再來看 StringTokenizer 類的源碼:
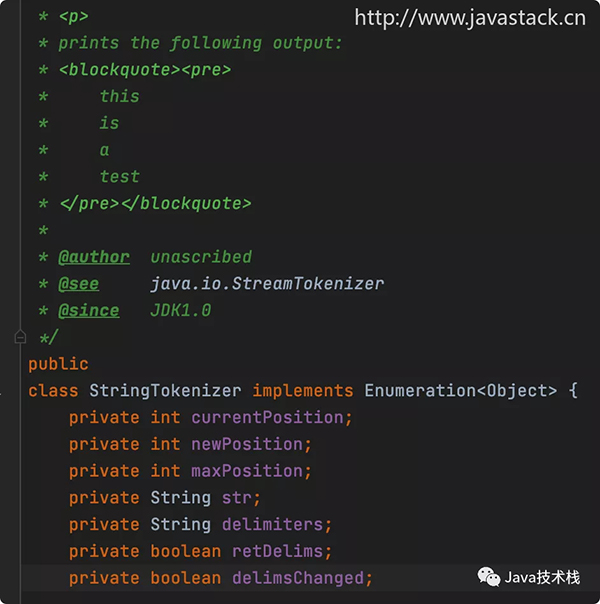
可以看到 StringTokenizer 類并未標識 @Deprecated,說明在后續的版本中也還可以繼續使用,官方還會繼續保留,并不會進行刪除。
就像 JDK 集合中的 Vector 和 Hashtable 類一樣,雖然它們略顯笨重,但并不說明它們沒有用了,另外,它們也不存在致命缺陷,所以一直保留到現在并未廢除掉。
StringTokenizer 沒人用了嗎?
答案:非也!
棧長在最新的 Spring 5.x 框架 StringUtils 工具類中就發現了 StringTokenizer 的使用身影:
org.springframework.util.StringUtils#tokenizeToStringArray
另外,棧長還看到了一篇《Faster Input for Java》的文章,其中就介紹了他們是使用 StringTokenizer 來分割字符串的,其效率是 string.split() 的 4 倍:
We split the input line into string tokens, since one line may contain multiple values. To split the input, StringTokenizer is 4X faster than string.split().
參考:https://www.cpe.ku.ac.th/~jim/java-io.html
所以,即使 JDK 不鼓勵使用它了,但它并未被廢除,并且性能還這么強,在一些對性能比較敏感的系統中,或者對性能比較有要求的編程競賽中,StringTokenizer 就能發揮重要作用。
所以,大膽用吧,StringTokenizer 還是可以用的,用的好還能出奇效!
StringTokenizer vs split
說了這么多,相信大部分人都只用過 split,而沒用過 StringTokenizer,那么棧長今天就來對比下這兩個字符串分割法的性能及利弊。
測試代碼如下:
- import java.util.Random;
- import java.util.StringTokenizer;
- /**
- * @author: 棧長
- * @from: 公眾號Java技術棧
- */
- public class SplitTest {
- private static final int MAX_LOOP = 10000;
- /**
- * @author: 棧長
- * @from: 公眾號Java技術棧
- */
- public static void main(String[] args) {
- StringBuilder sb = new StringBuilder();
- System.out.println(sb.toString());
- for (int i = 0; i < 1000; i++) {
- sb.append(new Random().nextInt()).append(" ");
- }
- split(sb.toString());
- stringTokenizer(sb.toString());
- }
- /**
- * @author: 棧長
- * @from: 公眾號Java技術棧
- */
- private static void split(String str) {
- long start = System.currentTimeMillis();
- for (int i = 0; i < MAX_LOOP; i++) {
- String[] arr = str.split(" ");
- StringBuilder sb = new StringBuilder();
- for (int j = 0; j < arr.length; j++) {
- sb.append(arr[j]);
- }
- }
- System.out.printf("split 耗時 %s ms\n", System.currentTimeMillis() - start);
- }
- /**
- * @author: 棧長
- * @from: 公眾號Java技術棧
- */
- private static void stringTokenizer(String str) {
- long start = System.currentTimeMillis();
- for (int i = 0; i < MAX_LOOP; i++) {
- StringTokenizer stringTokenizer = new StringTokenizer(str, " ");
- StringBuilder sb = new StringBuilder();
- while (stringTokenizer.hasMoreTokens()) {
- sb.append(stringTokenizer.nextToken());
- }
- }
- System.out.printf("StringTokenizer 耗時 %s ms", System.currentTimeMillis() - start);
- }
- }
在我本機測試結果如下:
| 測試次數 | split | StringTokenizer |
|---|---|---|
| 1 | 1ms | 1ms |
| 10 | 7ms | 3ms |
| 100 | 30ms | 16ms |
| 1000 | 129ms | 51ms |
| 10000 | 570ms | 486ms |
| 100000 | 3816ms | 3130ms |
從測試數據看,雖然 StringTokenizer 有一點性能優勢,但并不太明顯,我并沒有測試出有 4 倍的性能差距,可能和測試數據、測試方法、以及測試的 JDK 版本有關系。
然后,我再把 split 測試方法中的 " " 改成 "\\s":
| 測試次數 | split | StringTokenizer |
|---|---|---|
| 1 | 6ms | 1ms |
| 10 | 25ms | 4ms |
| 100 | 90ms | 20ms |
| 1000 | 240ms | 59ms |
| 10000 | 835ms | 481ms |
| 100000 | 5616ms | 3362ms |
把 split 方法改成正則表達式再測試,這下差距就明顯了。
我們都知道解析正則表達式會比較慢一點,這很正常,但 StringTokenizer 并不支持傳入正則表達式,只能使用字符串作為分隔符,所以這測試結果就沒多大意義了,這就是癥結了。。
總結
雖然 JDK 不鼓勵使用 StringTokenizer 了,但并不說明它不能用了,相反,如果你的系統對性能有非常嚴格的要求,又不是很復雜的字符串分割,好好使用它反而可以帶來高效。
但話又說回來,一般的應用程序用 split 也就夠了,因為它夠簡單、又支持正則表達式,在一般的應用中也不會存在像文中測試的大批量的字符串循環分割,另外,StringTokenizer 在單次分割的性能上也沒有性能優勢。
最后,關于字符串的分割方法,我們除了字符串本身的 split 方法,我們還要知道 StringTokenizer 這個類,多知道點不是壞事。另外,在 Spring、Apache Commons 工具類中也都有封裝好的 StringTokenizer 工具類,有興趣的可以直接拿去用。
好了,今天的分享就到這里了。
本節教程所有實戰源碼已上傳到這個倉庫:
https://github.com/javastacks/javastack