













緩存,原來我們一直都用錯了!
緩存,是互聯網分層架構中,非常重要的一個部分,通常用它來降低數據庫壓力,提升系統整體性能,縮短訪問時間。
有架構師說“緩存是萬金油,哪里有問題,加個緩存,就能優化”,緩存的濫用,可能會導致一些錯誤用法。
四類緩存常見誤用,你中招了嗎?
誤用一:把緩存作為服務與服務之間傳遞數據的媒介。
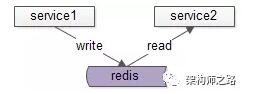
如上圖:
(1)服務1和服務2約定好key和value,通過緩存傳遞數據;
(2)服務1將數據寫入緩存,服務2從緩存讀取數據,達到兩個服務通信的目的。
該方案存在的問題是:
(1)數據管道,數據通知場景,MQ更加適合;
(2)多個服務關聯同一個緩存實例,會導致服務耦合。
誤用二:使用緩存未考慮雪崩。
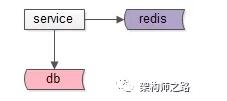
常規的緩存玩法,如上圖:
(1)服務先讀緩存,緩存命中則返回;
(2)緩存不命中,再讀數據庫。
什么時候會產生雪崩?
如果緩存掛掉,所有的請求會壓到數據庫,如果未提前做容量預估,可能會把數據庫壓垮(在緩存恢復之前,數據庫可能一直都起不來),導致系統整體不可服務。
如何應對潛在的雪崩?
提前做容量預估,如果緩存掛掉,數據庫仍能扛住,才能執行上述方案。
否則,就要進一步設計,更具體的,有兩類常見方案。
方案一:高可用緩存
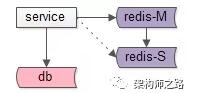
如上圖:使用高可用緩存集群,一個緩存實例掛掉后,能夠自動做故障轉移。
方案二:緩存水平切分
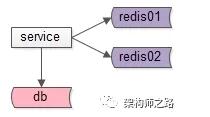
如上圖:使用緩存水平切分,一個緩存實例掛掉后,不至于所有的流量都壓到數據庫上。
誤用三:調用方緩存數據。
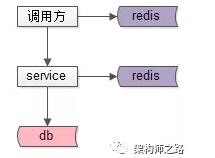
如上圖:
(1)服務提供方緩存,向調用方屏蔽數據獲取的復雜性(這個沒問題);
(2)服務調用方,也緩存一份數據,先讀自己的緩存,再決定是否調用服務(這個有問題)。
該方案存在的問題是:
(1)調用方需要關注數據獲取的復雜性;
(2)更嚴重的,服務修改db里的數據,淘汰了服務cache之后,難以通知調用方淘汰其cache里的數據,從而導致數據不一致;
(3)有人說,服務可以通過MQ通知調用方淘汰數據,額,難道下游的服務要依賴上游的調用方,分層架構設計不是這么玩的。
誤用四:多服務共用緩存實例。
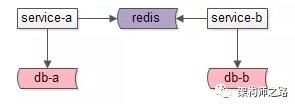
如上圖:
(1)服務A和服務B共用一個緩存實例(不是通過這個緩存實例交互數據)。
該方案存在的問題是:
(1)可能導致key沖突,彼此沖掉對方的數據;
畫外音:可能需要服務A和服務B提前約定好了key,以確保不沖突,常見的約定方式是使用namespace:key的方式來做key。
(2)不同服務對應的數據量,吞吐量不一樣,共用一個實例容易導致一個服務把另一個服務的熱數據擠出去;
(3)共用一個實例,會導致服務之間的耦合,與微服務架構的“數據庫,緩存私有”的設計原則是相悖的;
建議的玩法是:
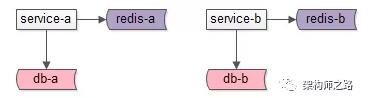
如上圖:各個服務私有化自己的數據存儲,對上游屏蔽底層的復雜性。
總結
緩存使用小技巧:
(1)服務與服務之間不要通過緩存傳遞數據;
(2)如果緩存掛掉,可能導致雪崩,此時要做高可用緩存,或者水平切分;
(3)調用方不宜再單獨使用緩存存儲服務底層的數據,容易出現數據不一致,以及反向依賴;
(4)不同服務,緩存實例要做垂直拆分。
這些坑,你踩過嗎?
【本文為51CTO專欄作者“58沈劍”原創稿件,轉載請聯系原作者】























