













擴散模型訓練方法一直錯了!謝賽寧:Representation matters
是什么讓紐約大學著名研究者謝賽寧三連呼喊「Representation matters」?他表示:「我們可能一直都在用錯誤的方法訓練擴散模型。」即使對生成模型而言,表征也依然有用。基于此,他們提出了 REPA,即表征對齊技術,其能讓「訓練擴散 Transformer 變得比你想象的更簡單。」
Yann LeCun 也對他們的研究表示了認可:「我們知道,當使用自監督學習訓練視覺編碼器時,使用具有重構損失的解碼器的效果遠不如使用具有特征預測損失和崩潰預防機制的聯合嵌入架構。這篇來自紐約大學 @sainingxie 的論文表明,即使你只對生成像素感興趣(例如使用擴散 Transformer 生成漂亮圖片),也應該包含特征預測損失,以便解碼器的內部表征可以根據預訓練的視覺編碼器(例如 DINOv2)預測特征。」

我們知道,在生成高維視覺數據方面,基于去噪的生成模型(如擴展模型和基于流的模型)的表現非常好,已經得到了廣泛應用。近段時間,也有研究開始探索將擴展模型用作表征學習器,因為這些模型的隱藏狀態可以捕獲有意義的判別式特征。
而謝賽寧指導的這個團隊發現(另一位指導者是 KAIST 的 Jinwoo Shin),訓練擴散模型的主要挑戰源于需要學習高質量的內部表征。他們的研究表明:「當生成式擴散模型得到來自另一個模型(例如自監督視覺編碼器)的外部高質量表征的支持時,其性能可以得到大幅提升。」
REPresentation Alignment(REPA),即表征對齊技術,便基于此而誕生了。這是一個基于近期的擴散 Transformer(DiT)架構的簡單正則化技術。

- 論文標題:Representation Alignment for Generation: Training Diffusion Transformers Is Easier Than You Think
- 論文地址:https://arxiv.org/pdf/2410.06940
- 項目地址:https://sihyun.me/REPA/
- 代碼地址:https://github.com/sihyun-yu/REPA
本質上講,REPA 就是將一張清晰圖像的預訓練自監督視覺表征蒸餾成一個有噪聲輸入的擴展 Transformer 表征。這種正則化可以更好地將擴展模型表征與目標自監督表征對齊。
方法看起來很簡單,但 REPA 的效果卻很好!據介紹,REPA 能大幅提升模型訓練的效率和效果。相比于原生模型,REPA 能將收斂速度提升 17.5 倍以上。在生成質量方面,在使用帶引導間隔(guidance interval)的無分類器引導時,新方法取得了 FID=1.42 的當前最佳結果。
REPA:用于表征對齊的正則化
REPresentation Alignment(REPA)是一種簡單的正則化方法,其使用了近期的擴展 Transformer 架構。簡單來說,該技術就是一種將預訓練的自監督視覺表征蒸餾到擴展 Transformer 的簡單又有效的方法。這讓擴散模型可以利用這些語義豐富的外部表征進行生成,從而大幅提高性能。

觀察
REPA 的誕生基于該團隊得到的幾項重要觀察。
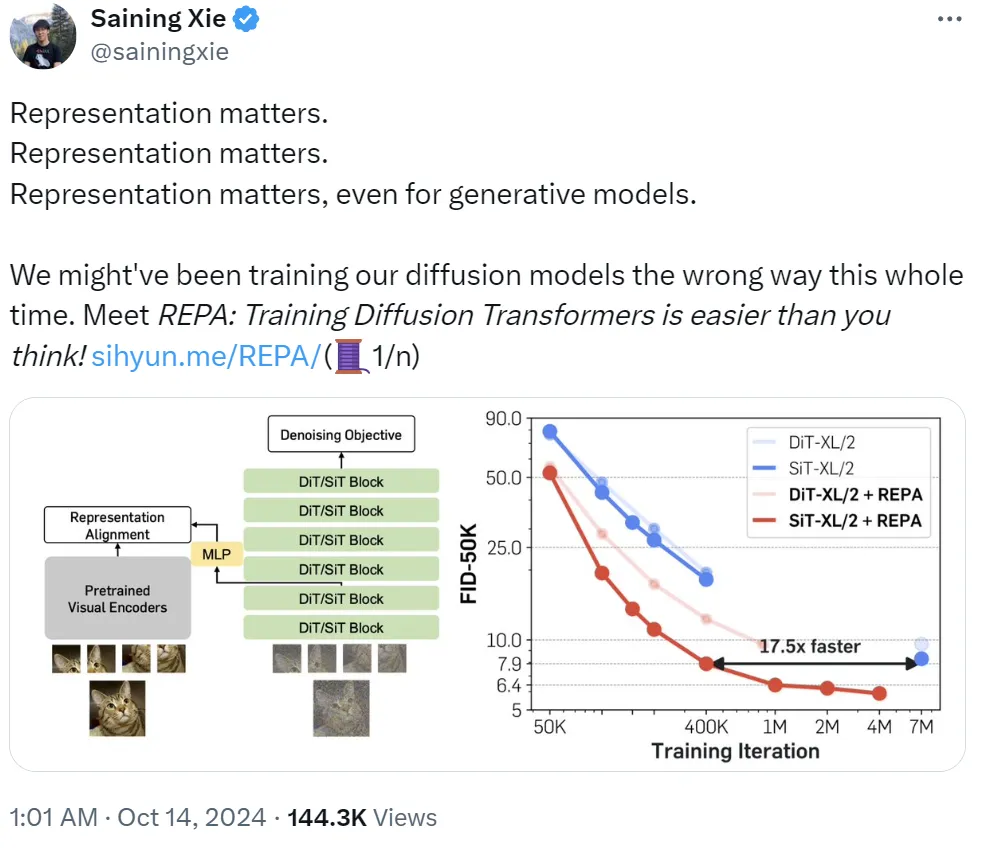
他們研究了在 ImageNet 上預訓練得到的 SiT(可擴展插值 Transformer)模型的逐層行為,該模型使用了線性插值和速度預測(velocity prediction)進行訓練。他們研究的重點是擴散 Transformer 和當前領先的監督式 DINOv2 模型之間的表征差距。他們從三個角度進行了研究:語義差距、特征對齊進展以及最終的特征對齊。
對于語義差距,他們比較了使用 DINOv2 特征的線性探測結果與來自 SiT 模型(訓練了 700 萬次迭代)的線性探測結果,采用的協議涉及到對擴散 Transformer 的全局池化的隱藏狀態進行線性探測。
接下來,為了測量特征對齊,他們使用了 CKNNA;這是一種與 CKA 相關的核對齊(kernel alignment)指標,但卻是基于相互最近鄰。這樣一來,便能以量化方式評估對齊效果了。圖 2 總結了其結果。
擴散 Transformer 與先進視覺編碼器之間的語義差距明顯。如圖 2a 所示,可以觀察到,預訓練擴散 Transformer 的隱藏狀態表征在第 20 層能得到相當高的線性探測峰值。但是,其性能仍遠低于 DINOv2,表明這兩種表征之間存在相當大的語義差距。此外,他們還發現,在此峰值之后,線性探測性能會迅速下降,這表明擴散 Transformer 必定從重點學習語義豐富的表征轉向了生成具有高頻細節的圖像。
擴散表征已經與其它視覺表征(細微地)對齊了。圖 2b 使用 CKNNA 展示了 SiT 與 DINOv2 之間的表征對齊情況。可以看到,SiT 模型表征的對齊已經優于 MAE,而后者也是一種基于掩碼圖塊重建的自監督學習方法。但是,相比于其它自監督學習方法之間的對齊分數,其絕對對齊分數依然較低。這些結果表明,盡管擴散 Transformer 表征與自監督視覺表征存在一定的對齊,但對齊程度不高。
當模型增大、訓練變多時,對齊效果會更好。該團隊還測量了不同模型大小和訓練迭代次數的 CKNNA 值。圖 2c 表明更大模型和更多訓練有助于對齊。同樣地,相比于其它自監督視覺編碼器之間的對齊,擴散表征的絕對對齊分數依然較低。
這些發現并非 SiT 模型所獨有,其它基于去噪的生成式 Transformer 也能觀察到。該團隊也在 DiT 模型上觀察到了類似的結果 —— 其使用 DDPM 目標在 ImageNet 上完成了預訓練。
與自監督表征的表征對齊
REPA 將模型隱藏狀態的 patch-wise 投影與預訓練自監督視覺表征對齊。具體來說,該研究使用干凈的(clean)圖像表征作為目標并探討其影響。這種正則化的目的是讓擴散 transformer 的隱藏狀態從包含有用語義信息的噪聲輸入中預測噪聲不變、干凈的視覺表征。這能為后續層重建目標提供有意義的引導。
形式上,令 ?? 為預訓練編碼器,x* 為干凈圖像。令 y*=??(x*) ∈ ?^{N×D} 為編碼器輸出,其中 N、D > 0 分別是 patch 的數量和 ?? 的嵌入維度。
REPA 是將 與 y* 對齊,其中
與 y* 對齊,其中 是擴散 transformer 編碼器輸出
是擴散 transformer 編碼器輸出 通過可訓練投影頭 h_? 得到的投影。實踐中 h_? 的參數化是簡單地使用多層感知器(MLP)完成的。
通過可訓練投影頭 h_? 得到的投影。實踐中 h_? 的參數化是簡單地使用多層感知器(MLP)完成的。
特別地,REPA 通過最大化預訓練表征 y* 和隱藏狀態 h_t 之間的 patch-wise 相似性來實現對齊,其中 n 是 patch 索引,sim (?,?) 是預定義的相似度函數。

在實踐中,是基于一個系數 λ 將該項添加到基于擴散的原始目標中。例如,對于速度模型的訓練,其目標變為:

其中 λ > 0 是一個超參數,用于控制去噪和表示對齊之間的權衡。該團隊主要研究這種正則化對兩個常用目標的影響:DiT 中使用的改進版 DDPM 和 SiT 中使用的線性隨機插值,盡管也可以考慮其他目標。
結果
REPA 改善視覺擴展
該研究首先比較兩個 SiT-XL/2 模型在前 400K 次迭代期間生成的圖像,其中一個模型應用 REPA。兩種模型共享相同的噪聲、采樣器和采樣步驟數,并且都不使用無分類器引導。使用 REPA 訓練的模型表現更好。

REPA 在各個方面都展現出強大的可擴展性
該研究通過改變預訓練編碼器和擴散 transformer 模型大小來檢查 REPA 的可擴展性,結果表明:與更好的視覺表征相結合可以改善生成和線性探測結果。
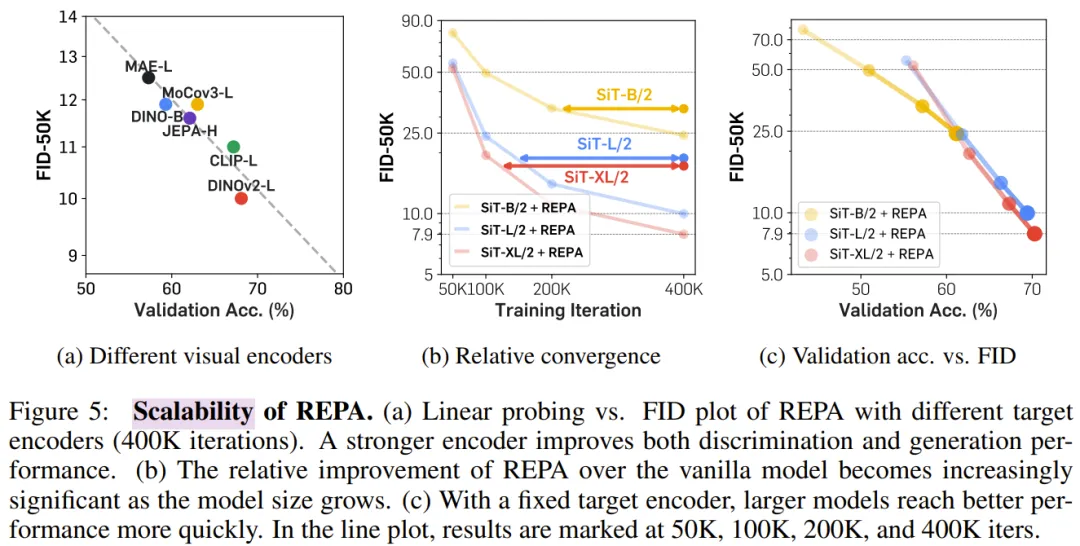
REPA 還在大型模型中提供了更顯著的加速,與普通模型相比,實現了更快的 FID-50K 改進。此外,增加模型大小可以在生成和線性評估方面帶來更快的增益。
REPA 顯著提高訓練效率和生成質量
最后,該研究比較了普通 DiT 或 SiT 模型與使用 REPA 訓練的模型的 FID 值。

在沒有無分類器引導的情況下,REPA 在 400K 次迭代時實現了 FID=7.9,優于普通模型在 700 萬次迭代時的性能。
使用無分類器引導,帶有 REPA 的 SiT-XL/2 的性能優于最新的擴散模型,迭代次數減少為 1/7,并通過額外的引導調度實現了 SOTA FID=1.42。
該團隊也執行了消融研究,探索了不同時間步數、不同視覺編碼器和不同 λ 值(正則化系數)的影響。詳見原論文。





























