













生產故障|Kafka消息發送延遲達到幾十秒的罪魁禍首竟然是...

以前我在知其然而知其所以然,為什么Kafka在2.8版本中會“拋棄”Zookeeper一文中闡述了為什么官方要廢棄Zookeeper,當時我記得有讀者反駁說zookeeper非常穩定,基本不會出現什么問題,筆者在雙十一期間遇到的問題,就證明了Zookeeper的“脆弱性”,而zookeeper的脆弱性將對Kafka集群造成嚴重的影響。
1、故障現象
筆者在雙十一期間負責的kafka集群的響應時間飆升到了10~30s,嚴重影響消息的寫入。
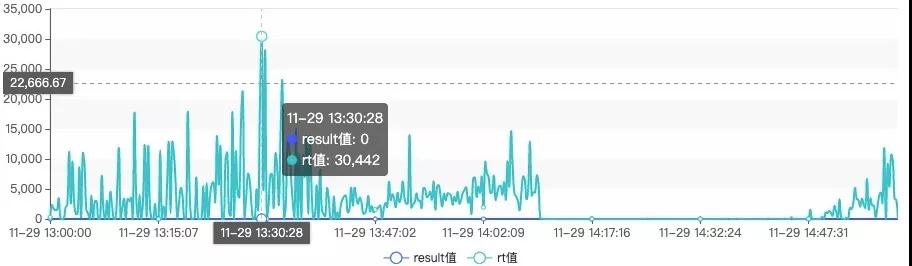
通過對日志分析發現存在大面積分區Leader選舉,__consumer_offsets主題的分區也大量進行分區Leader選舉,從而導致消息發送幾乎停止,大量消費組觸發重平衡,整個集群接近癱瘓,最終確定了根因:Broker節點與Zookeeper會話超時,觸發大量分區重新選舉。
本文借此故障,與大家一起剖析一下Zookeeper在Kafka中起了哪些作用,以及確定“罪魁禍首”的過程,希望給大家排查問題能帶來一定的啟發。
2、Zookeeper在Kafka中具有舉足輕重的作用
在正式進入故障分析之前,我們首先介紹一下Zookeeper在kafka架構設計中所起的角色。
核心理念:kafka的設計者對待Zookeeper的使用是非常謹慎的,即需要依靠Zookeeper進行控制器選舉,Broker節點故障實時發現,但又盡量降低對Zookeeper的依賴。
基于Zookeeper進行的程序開發,我們一般可以通過查看zookeeper中的目錄布局,可以窺探出哪些功能是依靠Zookeeper完成,Kafka在Zookeeper中的存儲目錄結構如下圖所示:
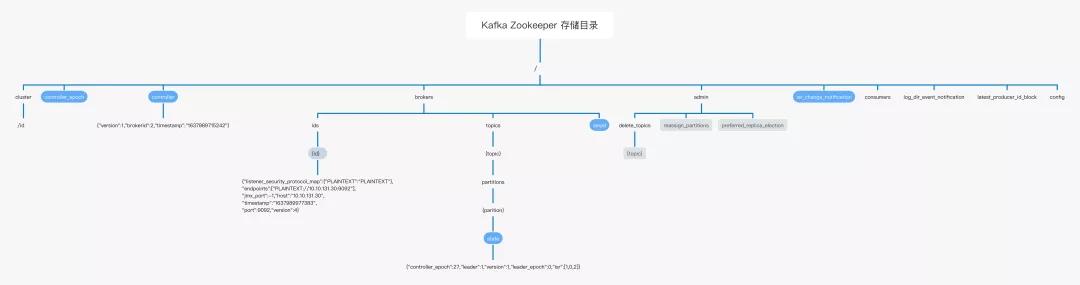
上述各個節點,其背后都關聯著Kafka一個核心工作機制,大家可以順藤摸瓜進行探究,本文需要重點介紹/brokers這個目錄的布局與作用,目錄詳情如下:
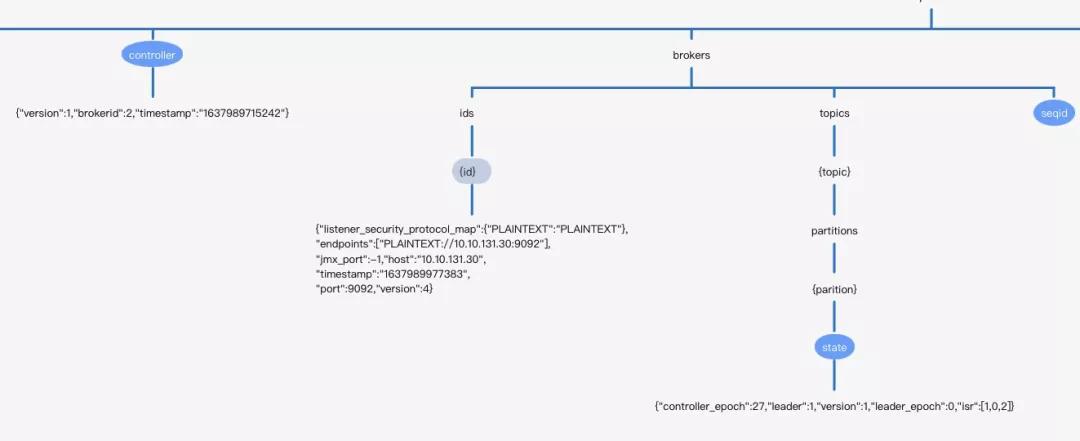
- /controller Kafka控制器的信息,Kafka控制器的選舉依靠zookeeper。
- /brokers/ids/{id} 在持久節點/brokers/ids下創建眾多的臨時節點,每一個節點,表示一個Broker節點,節點的內容存儲了Broker的基本信息,例如端口、版本、監聽地址等。
- /brokers/topics/{topic}/partitions/{partition}/state
在kafka2.8版本一下,Kafka中topic中的路由信息最終持久化在zookeeper中,每一個broker節點啟動后會在內存中緩存一份數據。/brokers節點每一個子節點表示一個具體的主題,主題的元數據主要包括分區的個數與每一個分區的狀態信息。每一個分區的狀態信息主要包括:
- controller_epoch 當前集群控制器的epoch,表示controller選舉的次數,我們可以理解為controller的“版本號”。
- leader 當前分區Leader所在的broker id。
- Leader_epoch 分區的leader_epoch,表示分區Leader選舉的次數,從0開始,每發生一次分區leader選舉該值就會加一,kafka通過引入leader epoch機制解決低版本依靠依賴水位線表示副本進度可能造成的數據丟失與數據不一致問題,這個將在后續文章中深入剖析。
- isr 分區的isr集合。
- version 存儲狀態分區狀態數據結構的版本號,這個字段大家可以忽略
在Zookeeper中有一種同樣的“設計模式”,就是可以通過在zookeeper中創建臨時節點+事件監聽機制,從而實現數據的實時動態感知,以/brokers/ids為例進行闡述:
- Kafka broker進程啟動時會向zookeeper創建一個臨時節點/brokers/ids/{id},其中id為broker的編號
- Kafka Broker進程停止后,創建的臨時節點在broker與zookeeper的會話超時后會被自動刪除,產生節點刪除事件
- Kafka controller 會自動監聽/brokers/ids 目錄的節點新增與刪除事件,一旦broker下線、上線,controller都會實時感知,從而采取必要處理。
經過上面的初步介紹,Kafka對zookeeper的依賴還是非常大的,特別是Kafka控制器的選舉、broker節點的存活狀態等都依賴zookeeper。
Kafka 控制器可以看出是整個kafka集群的“大腦”,如果它出現異動,其影響范圍之廣,影響程度之大可想而知,接下來的故障分析會給出更直觀的展現。
溫馨提示:本文主要是一個故障分析過程,后續關于kafka控制器如何選舉、leader_epoch副本同步機制等會在《Kafka原理與實戰》專欄中一一介紹,敬請關注。
3、問題分析
一看到消息發送響應時間長,我的第一反應是查看線程棧,是不是有鎖阻塞,但查看線程堆棧發現Kafka用于處理請求的線程池大部分都阻塞在獲取任務處,表明“無活可干”狀態:

說明客戶端端消息發送請求都沒有到達Kafka的排隊隊列,并且專門用于處理網絡讀寫的線程池也很空閑,那又是為什么呢?
消息發送端延遲超級高,但服務端線程又極度空閑,有點詭異?
繼續查看服務端日志,發現了大量主題(甚至連系統主題__consumer_offsets主題也發生了Leader選舉),日志如下:

核心日志:start at Leader Epoch 大量分區在進行Leader選舉。
Kafka中中只有Leader分區能處理讀、寫請求,follower分區只是從leader分區復制數據,在Leader節點宕機后參與leader選舉,故分區在進行Leader選舉時無法處理客戶端的寫入請求,而發送端又有重試機制,故消息發送延遲很大。
那到底在什么情況下會觸發大量主題進行重新選舉呢?
我們找到當前集群的Controler節點,查看state-change.log中,發現如下日志:

出現了大量分區的狀態從OnlinePartition變更為OfflinePartition。
溫馨提示:根據日志我們可以去查看源碼,找到輸出這些方法的調用鏈,就可以順藤摸瓜去找針對性的日志。
繼續查看Controler節點下的controller.log中發現關鍵日志:

核心日志解讀:
- [Controller id=1] Broker failure callback for 8 (kafka.controller.KafkaController) 控制器將節點8從集群的在線中移除,控制器為什么會將節點8移除呢?
接下來順藤摸瓜,去看一下節點8上的日志如下圖所示:

核心日志解讀:原來broker與zookeeper的會話超時,導致臨時節點被移除。
先不探究會話為什么會超時,我們先來看一下會話超時,會給Kafka集群帶來什么嚴重影響。
/brokers/ids下任意一個節點被刪除,Kafka控制器都能及時得到,并執行對應的處理。
這里需要分兩種情況考慮。
3.1 普通Broker節點被移除
處理入口為:KafkaController的onBrokerFailure方法,代碼詳情如下圖所示:
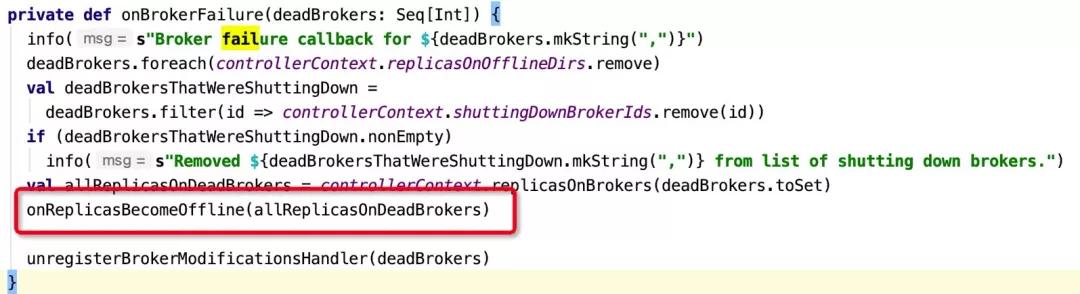
一個普通的broker在zk中被移除,Kafka控制器會將該節點上分配的所有分區的狀態從OnlinePartition變更為OfflinePartition,從而觸發分區的重新選舉。
擴展知識點:__consumer_offsets分區如果進行Leader重新選舉,大面積的消費組會觸發重平衡,背后的機制:
消費組需要在Broker端進行組協調器選舉,選舉算法如下:消費組的名稱的hashcode與主題 __ consumer_offsets的隊列總數取模,取余數,映射成 __consumer_offsets 分區,該分區的leader在哪個broker節點,該節點則會充當消費組的組協調器。
一旦該分區的Leader發生變化,對應的消費組必須重新選舉新的組協調器,從而觸發消費組的重平衡。
3.2 Controller節點被移除
如果zookeeper中移除的broker id 為 Kafka controller,其影響會更大,主要的入口如下圖所示:
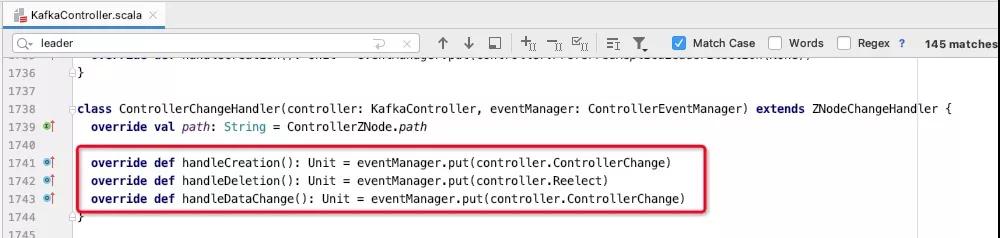
如果是controller節點會話超時,臨時節點/controller節點會被刪除,從而會觸發Kafka controller選舉,最終所有的broker節點都會收到節點/controller的刪除、新增或節點數據變化的通知,KafkaController的onControllerFailover方法會被執行,與會將于zookeeper相關的事件監聽器重新注冊、分區狀態機、副本狀態機都會停止并重新啟動,各個分區會觸發自動leader分區選舉。
可以這樣形容:一朝天子一朝臣,全部重新來過。
3.3 zookeeper會話超時根因排查
查看服務端日志,可以看到如下日志:

核心日志解讀:Closed socket connection for client ... 表示連接被客戶端主動關閉。
那為什么客戶端會主動關閉心跳呢?心跳處理的套路就是客戶端需要定時向服務端發送心跳包,服務端在指定時間內沒有收到或處理心跳包,則會超時。
要想一探究竟,唯一的辦法:閱讀源碼 ,通過研讀Zookeeper客戶端源碼,發現存在這樣一個設計:客戶端會把所有的請求先放入一個隊列中,然后通過一個發送線程(SendThread)從隊列中獲取請求,發送到服務端,關鍵代碼如下:
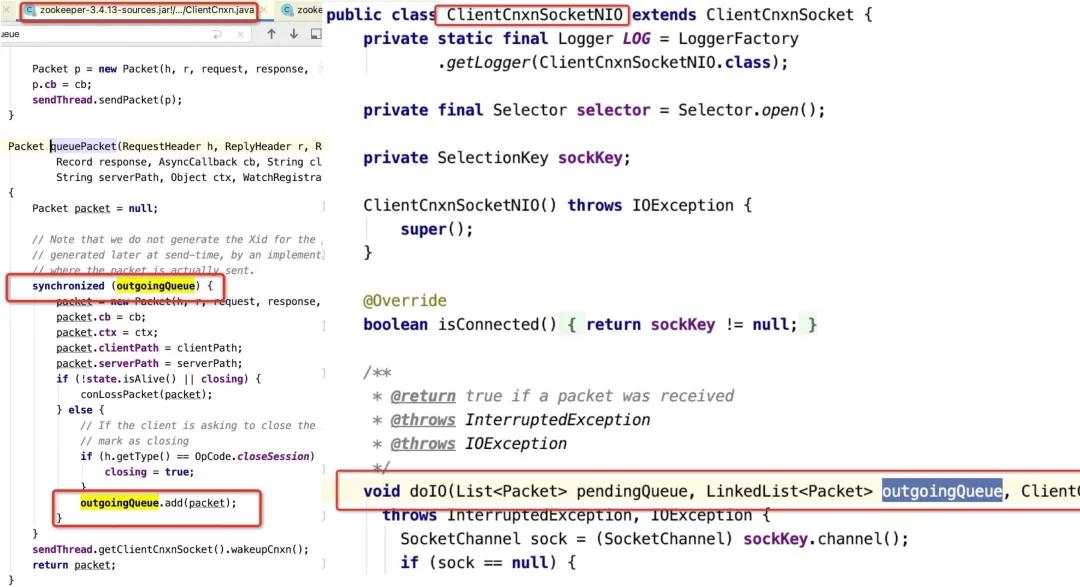
如果存在大量的zk更新操作,心跳包可能會處理不及時,而在出現zookeeper session會話超時之前,集群在大面積ISR擴張與收縮,頻繁更新zk,從而觸發了客戶端端心跳超時,這個問題也可以通過如下代碼進行復現:
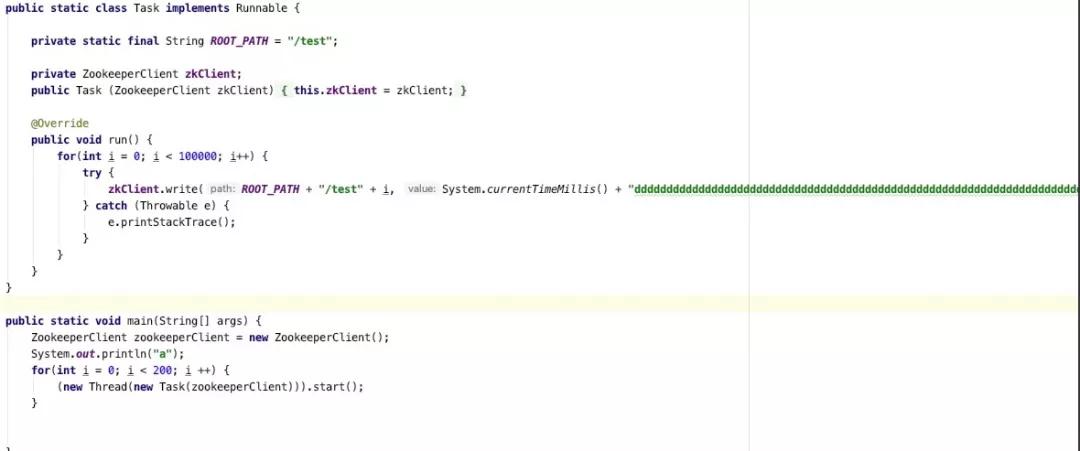
經過這波分析,由于zookeeper會話超時,導致大量分區重新選舉,最終導致消息發送延遲很大,并且消費組大面積重平衡的根本原因就排查清楚了,本期分享就到此為止,我們下期見。












