微服務難點剖析 | 服務拆的挺爽,問題是日志該怎么串聯起來呢?

本文轉載自微信公眾號「網管叨bi叨」,作者KevinYan11。轉載本文請聯系網管叨bi叨公眾號。
現在微服務架構盛行,很多以前的單體應用服務都被拆成了多個分布式的微服務,以解決應用系統發展壯大后的開發周期長、難以擴展、故障隔離等挑戰。
不過技術領域有個諺語叫--沒有銀彈,這句話的意思其實跟現實生活中任何事都有利和弊兩面一樣,意思是告訴我們不要寄希望于用一個解決方案解決所有問題,引入新方案解決舊問題的同時,勢必會引入新的問題。典型的比如,原本在單體應用里可以靠本地數據庫的ACID 事務來保證數據一致性。但是微服務拆分后,就沒那么簡單了。
同理拆分成為服務后,一個業務邏輯的完成一般需要多個服務的協作才能完成,每個服務都會有自己的業務日志,那怎么把各個服務的業務日志串聯起來,也會變難,今天我們就聊一下微服務的日志串聯的方案。
在早前的文章分布式鏈路跟蹤中的traceid和spanid代表什么? 這里我給大家介紹過 TraceId 和 SpanId 的概念。
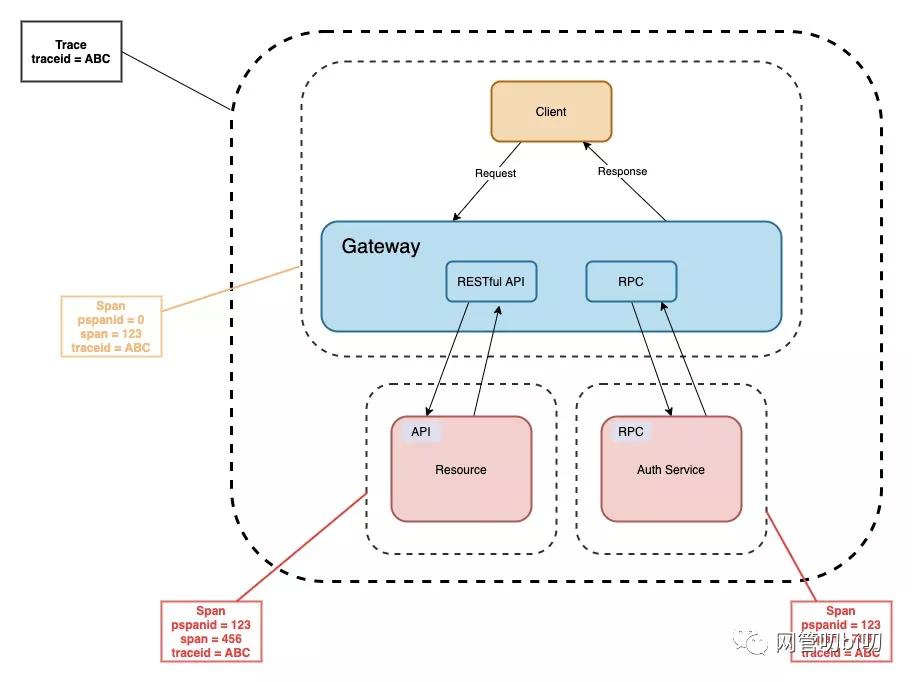
- trace 是請求在分布式系統中的整個鏈路視圖
- span 則代表整個鏈路中不同服務內部的視圖,span 組合在一起就是整個 trace 的視圖
在微服務的日志串聯里,我們同樣能使用這兩個概念,通過 trace 串聯出一個業務邏輯的所有業務日志,span 串聯出在單個服務里的業務日志。
而單個微服務的日志串聯的時候還有個挑戰是怎么把數據庫執行過程的一些日志也注入這些 traceid 和 spanid 打到業務日志里。下面我們就分別通過
- HTTP 服務間的日志追蹤參數傳遞
- HTTP 和 RPC 服務間的追蹤參數傳遞
- ORM 的日志中注入追蹤參數
來簡述一下微服務業務日志串聯的思路。提前聲明本文中給出的解決方案更多是 Go 技術棧的,其他語言的技術棧有些方案實現跟這里列舉的稍有不同,尤其是 Java 一些開源庫上比較容易實現的東西在 Go 這里并不簡單。
其實如果使用 APM 的話,是有比較統一的解決方案的,比如接入 Skywalking 就可以,不過還是有額外的學習成本以及需要引入外部系統組件的。
HTTP 服務間的日志追蹤參數傳遞
HTTP 服務間的追蹤參數傳遞,主要是靠在全局的路由中間件來搞,我們可以在請求頭里指定 TraceId 和 SpanId。當然如果是請求到達的第一個服務,則生成 TraceId 和 SpanId,加到Header 里往下傳。
- type Middleware func(http.HandlerFunc) http.HandlerFunc
- func withTrace() Middleware {
- // 創建中間件
- return func(f http.HandlerFunc) http.HandlerFunc {
- return func(w http.ResponseWriter, r *http.Request) {
- traceID := r.Header.Get("xx-tranceid")
- parentSpanID := r.Header.Get("xx-spanid")
- spanID := genSpanID(r.RemoteAddr)
- if traceID == "" {// traceID為空,證明是初始調用,讓root span id == trace id
- traceId = spanID
- }
- // 把 追蹤參數通過 Context 在服務內部處理中傳遞
- ctx := context.WithValue(r.Context(), "trace-id", traceID)
- ctx := context.WithValue(ctx, "pspan-id", parentSpanID)
- ctx := context.WithValue(ctx, "span-id", parentSpanID)
- r.WithContext(ctx)
- // 調用下一個中間件或者最終的handler處理程序
- f(w, r)
- }
- }
- }
上面主要通過在中間件程序,獲取 Header 頭里存儲的追蹤參數,把參數保存到請求的 Context 中在服務內部傳遞。上面的程序有幾點需要說明:
- genSpanID 是根據遠程客戶端IP 生成唯一 spanId 的方法,生成方法只要保證哈希串唯一就行。
- 如果服務是請求的開始,在生成spanId 的時候,我們把它也設置成 traceId,這樣就能通過 spanId == traceId 判斷出當前的 Span 是請求的開端、即 root span。
接下來往下游服務發起請求的時候,我們需要在把 Context 里存放的追蹤參數,放到 Header 里接著往下個 HTTP 服務傳。
- func HttpGet(ctx context.Context url string, data string, timeout int64) (code int, content string, err error) {
- req, _ := http.NewRequest("GET", url, strings.NewReader(data))
- defer req.Body.Close()
- req.Header.Add("xx-trace-tid", ctx.Value("trace-id").(string))
- req.Header.Add("xx-trace-tid", ctx.Value("span-id").(string))
- client := &http.Client{Timeout: time.Duration(timeout) * time.Second}
- resp, error := client.Do(req)
- }
HTTP 和 RPC 服務間的追蹤參數傳遞
上面咱們說的上下游服務都是 HTTP 服務的追蹤參數傳遞,那如果是 HTTP 服務的下游是 RPC 服務呢?
其實跟發HTTP請求可以配置HTTP客戶端攜帶 Header 和 Context 一樣,RPC客戶端也支持類似功能。以 gRPC 服務為例,客戶端調用RPC 方法時,在可以攜帶的元數據里設置這些追蹤參數。
- traceID := ctx.Value("trace-id").(string)
- traceID := ctx.Value("trace-id").(string)
- md := metadata.Pairs("xx-traceid", traceID, "xx-spanid", spanID)
- // 新建一個有 metadata 的 context
- ctx := metadata.NewOutgoingContext(context.Background(), md)
- // 單向的 Unary RPC
- response, err := client.SomeRPCMethod(ctx, someRequest)
RPC 的服務端的處理方法里,可以再通過 metadata 把元數據里存儲的追蹤參數取出來。
- func (s server) SomeRPCMethod(ctx context.Context, req *xx.someRequest) (reply *xx.SomeReply, err error) {
- remote, _ := peer.FromContext(ctx)
- remoteAddr := remote.Addr.String()
- // 生成本次請求在當前服務的 spanId
- spanID := utils.GenerateSpanID(remoteAddr)
- traceID, pSpanID := "", ""
- md, _ := metadata.FromIncomingContext(ctx)
- if arr := md["xx-tranceid"]; len(arr) > 0 {
- traceID = arr[0]
- }
- if arr := md["xx-spanid"]; len(arr) > 0 {
- pSpanID = arr[0]
- }
- return
- }
有一個概念我們需要注意一下,代碼里是把上游傳過來的 spanId 作為本服務的 parentSpanId 的,本服務處理請求時候的 spanId 是需要重新生成的,生成規則在之前我們介紹過。
除了 HTTP 網關調用 RPC 服務外,處理請求時也經常出現 RPC 服務間的調用,那這種情況該怎么弄呢?
RPC 服務間的追蹤參數傳遞
其實跟 HTTP 服務調用 RPC 服務情況類似,如果上游也是 RPC 服務,那么則應該在接收到的上層元數據的基礎上再附加的元數據。
- md := metadata.Pairs("xx-traceid", traceID, "xx-spanid", spanID)
- mdOld, _ := metadata.FromIncomingContext(ctx)
- md = metadata.Join(mdOld, md)
- ctx = metadata.NewOutgoingContext(ctx, md)
當然如果我們每個客戶端調用和RPC 服務方法里都這么搞一遍得類似,gRPC 里也有類似全局路由中間件的概念,叫攔截器,我們可以把追蹤參數傳遞這部分邏輯封裝在客戶端和服務端的攔截器里。
gRPC 攔截器的詳細介紹請看我之前的文章 -- gRPC生態里的中間件
客戶端攔截器
- func UnaryClientInterceptor(ctx context.Context, ... , opts ...grpc.CallOption) error {
- md := metadata.Pairs("xx-traceid", traceID, "xx-spanid", spanID)
- mdOld, _ := metadata.FromIncomingContext(ctx)
- md = metadata.Join(mdOld, md)
- ctx = metadata.NewOutgoingContext(ctx, md)
- err := invoker(ctx, method, req, reply, cc, opts...)
- return err
- }
- // 連接服務器
- conn, err := grpc.Dial(*address, grpc.WithInsecure(),grpc.WithUnaryInterceptor(UnaryClientInterceptor))
服務端攔截器
- func UnaryServerInterceptor(ctx context.Context, req interface{}, info *grpc.UnaryServerInfo, handler grpc.UnaryHandler) (resp interface{}, err error) {
- remote, _ := peer.FromContext(ctx)
- remoteAddr := remote.Addr.String()
- spanID := utils.GenerateSpanID(remoteAddr)
- // set tracing span id
- traceID, pSpanID := "", ""
- md, _ := metadata.FromIncomingContext(ctx)
- if arr := md["xx-traceid"]; len(arr) > 0 {
- traceID = arr[0]
- }
- if arr := md["xx-spanid"]; len(arr) > 0 {
- pSpanID = arr[0]
- }
- // 把 這些ID再搞到 ctx 里,其他兩個就省略了
- ctx := Context.WithValue(ctx, "traceId", traceId)
- resp, err = handler(ctx, req)
- return
- }
ORM 的日志中注入追蹤參數
其實,如果你用的是 GORM 注入這個參數是最難的,如果你是 Java 程序員的話,可能會對比如阿里巴巴的 Druid 數據庫連接池加入類似 traceId 這種參數習以為常,但是 Go 的 GORM 庫確實做不到,也有可能新版本可以,我用的還是老版本,其他 Go 的 ORM 庫沒有接觸過,知道的同學可以留言給我們普及一下。
GORM做不到在日志里加入追蹤參數的原因就是這個GORM 的 logger 沒有實現SetContext方法,所以除非修改源碼中調用db.slog的地方,否則無能為力。
不過話也不能說死,之前介紹過一種使用函數調用棧實現 Goroutine Local Storage 的庫 jtolds/gls ,我們可以通過它在外面封裝一層來實現,并且還需要重新實現 GORM Logger 的打印日志的 Print 方法。
下面大家感受一下,GLS 庫的使用,確實有點點怪,不過能過。
- func SetGls(traceID, pSpanID, spanID string, cb func()) {
- mgr.SetValues(gls.Values{traceIDKey: traceID, pSpanIDKey: pSpanID, spanIDKey: spanID}, cb)
- }
- gls.SetGls(traceID, pSpanID, spanID, func() {
- data, err = findXXX(primaryKey)
- })
重寫 Logger 的我就簡單貼貼,核心思路還是在記錄SQL到日志的時候,從調用棧里把 traceId 和 spanId 取出來放一并加入到日志記錄里。
- // 對Logger 注冊 Print方法
- func (l logger) Print(values ...interface{}) {
- if len(values) > 1 {
- // ...
- l.sqlLog(sql, args, duration, path.Base(source))
- } else {
- err := values[2]
- log.Error("source", source, "err", err)
- }
- }
- }
- func (l logger) sqlLog(sql string, args []interface{}, dur time.Duration, source string) {
- argsArr := make([]string, len(args))
- for k, v := range args {
- argsArr[k] = fmt.Sprintf("%v", v)
- }
- argsStr := strings.Join(argsArr, ",")
- spanId := gls.GetSpanId()
- traceId := gls.GetTraceId()
- //對于超時的,統一打warn日志
- if dur > (time.Millisecond * 500) {
- log.Warn("xx-traceid", traceId, "xx-spanid", spanId, "sql", sql, "args_detal", argsStr, "source", source)
- } else {
- log.Debug("xx-traceid", traceId, "xx-spanid", spanId, "sql", sql, "args_detal", argsStr, "source", source)
- }
- }
通過調用棧獲取 spanId 和 traceId 的是類似這樣的方法,由 GLS 庫提供的方法封裝實現。
- // Get spanID 用于Goroutine的鏈路追蹤
- func GetSpanID() (spanID string) {
- span, ok := mgr.GetValue(spanIDKey)
- if ok {
- spanID = span.(string)
- }
- return
- }
日志打印的話,也是對超過 500 毫秒的SQL執行進行 Warn 級別日志的打印,方便線上環境分析問題,而其他的SQL執行記錄,因為使用了 Debug 日志級別只會在測試環境上顯示。
總結
用分布式鏈路追蹤參數串聯起整個服務請求的業務日志,在線上的分布式環境中是非常有必要的,其實上面只是簡單闡述了一些思路,只有把日志搞的足夠好,上下文信息足夠多才會能高效地定位出線上問題。感覺這部分細節太多,想用一篇文章闡述明白非常困難。
而且還有一點就是日志錯誤級別的選擇也非常有講究,如果本該用Debug的地方,用了 Info 級別,那線上日志就會出現非常多的干擾項。
細節的地方怎么實現,就屬于實踐的時候才能把控的了。希望這篇文章能給你個實現分布式日志追蹤的主旨思路。