為什么小批量可以使深度學習獲得更大的泛化

批大小是機器學習中重要的超參數之一。這個超參數定義了在更新內部模型參數之前要處理的樣本數量。
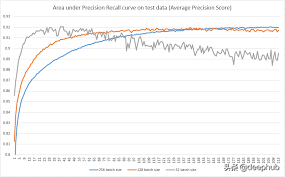
上圖為使用 SGD 測試不同批量大小的示例。
批量大小可以決定許多基于深度學習的神經網絡的性能。 有很多研究都在為學習過程評估最佳批量大小。 例如,對于 SGD可以使用批量梯度下降(使用批量中的所有訓練樣本)或小批量(使用一部分訓練數據),甚至在每個樣本后更新(隨機梯度下降)。 這些不同的處理方式可以改變模型訓練的的效果。
準確性并不是我們關心的唯一性能指標。 模型的泛化能力可能更加重要。 因為如果我們的模型在看不見的數據上表現不佳它就毫無用處。使用更大的批量會導致更差的網絡泛化。 論文“ON LARGE-BATCH TRAINING FOR DEEP LEARNING: GENERALIZATION GAP AND SHARP MINIMA”的作者試圖調查這種現象并找出為什么會發生這種情況。 他們的發現很有趣,所以我將在本文中進行詳細介紹。 了解這一點將能夠為自己的神經網絡和訓練方式做出更好的決策。
理解論文的假設
要理解任何論文,首先要了解作者試圖證明的內容。 作者聲稱他們發現了為什么大批量會導致更差的泛化。 他們“提供了支持大批量方法趨向于收斂到訓練和測試函數的sharp minima(尖銳的最小值)的觀點的數值證據——眾所周知,sharp minima會導致較差的泛化。 而小批量方法始終收斂到flat minima(平坦的最小值),論文的實驗支持一個普遍持有的觀點,即這是由于梯度估計中的固有噪聲造成的。” 我們將在本篇文章中做更多的說明,所以讓我們一步一步來。 下圖描繪了尖銳最小值和平坦最小值之間的差異。
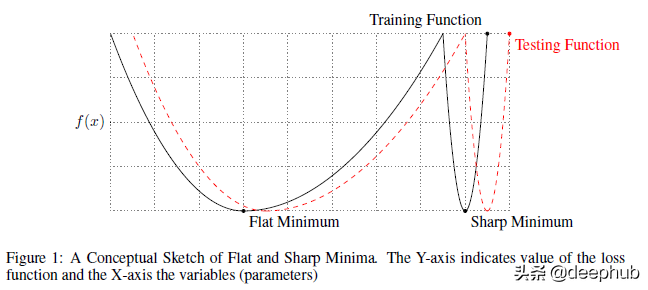
對于尖銳的最小值,X 的相對較小的變化會導致損失的較大變化
一旦你理解了這個區別,讓我們理解作者驗證的兩個(相關的)主要主張:
- 使用大批量將使訓練過程有非常尖銳的損失情況。 而這種尖銳的損失將降低網絡的泛化能力。
- 較小的批量創建更平坦的損失圖像。 這是由于梯度估計中的噪聲造成的。
作者在論文中強調了這一點,聲明如下:

我們現在將查看他們提供的證據。 他們設置實驗的一些方法很有趣,會教會我們很多關于設置實驗的知識。
定義銳度
銳度是一個易于掌握和可視化的直觀概念。 但是它也存在有一些問題。 例如機器學習對高維數據進行計算/可視化可能很費資源和時間。 作者也提到了這一點, 所以他們使用更簡單的啟發式方法:通過相鄰點來進行銳度的檢查, 該函數的最大值就可以用于靈敏度的計算。
論文原文中說到:
我們采用了一種敏感性度量,雖然不完美,但在計算上是可行的,即使對于大型網絡也是如此。 它基于探索解決方案的一個小鄰域并計算函數 f 在該鄰域中可以達到的最大值。 我們使用該值來測量給定局部最小值處訓練函數的靈敏度。 由于最大化過程是不準確的,并且為了避免被僅在 Rn 的微小子空間中獲得較大 f 值的情況所誤導,我們在整個空間 Rn 以及隨機流形中都執行了最大化
需要注意的是,作者將一定程度的交叉驗證集成到程序中。 雖然從解決方案空間中獲取多個樣本似乎過于簡單,但這是一種非常強大的方法并且適用于大多數情況。 如果你對他們計算的公式感興趣,它看起來像這樣。

查看相關的證明
我們了解了作者提出的基本術語/定義,讓我們看看提出的一些證據。 本篇文章中無法分享論文/附錄中的所有內容,所以如果你對所有細節感興趣可以閱讀論文的原文。
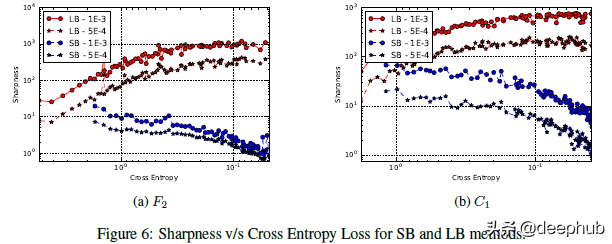
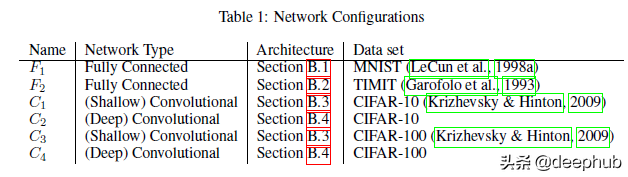
在上面的圖中可以看到交叉熵損失與銳度的關系圖。從圖中可以看到,當向右移動時損失實際上越來越小。那么這個圖表是什么意思呢?隨著模型的成熟(損失減少),Large Batch 模型的清晰度會增加。用作者的話來說,“對于在初始點附近的較大的損失函數值,小批次 和 大批次 方法產生相似的銳度值。隨著損失函數的減小,與 大批次 方法相對應的迭代的銳度迅速增加,而對于 小批次 方法銳度最初保持相對恒定然后降低,這表明在探索階段之后會收斂到平坦的最小化器。”
作者還有其他幾個實驗來展示結果。除了在不同類型的網絡上進行測試外,他們還在小批量和大批量網絡上使用了熱啟動。結果也與我們所看到的非常一致。
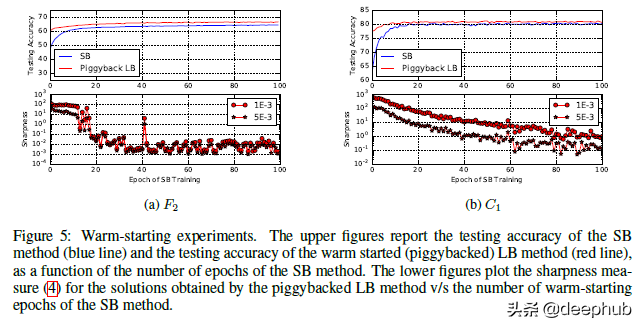
我在論文中發現的一個有趣的觀點是,當他們證明了這種較低的泛化與使用較大批大小時的模型過擬合或過度訓練無關時。 很容易假設過擬合是低泛化的原因(一般情況下我們都這么理解),但作者反對這一點。 要了解他們的論點,請查看此表。
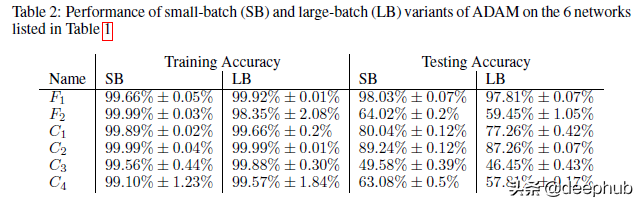
小批量訓練通常具有更好的訓練性能。 即使在我們使用小批量訓練的訓練精度較低的網絡中,我們也注意到會有更高的訓練精度。 作者以下原文可以作為重點,“我們強調,泛化差距不是由于統計中常見的過擬合或過度訓練造成的。 這種現象以測試準確度曲線的形式表現出來,該曲線在某個迭代峰值處,然后由于模型學習訓練數據的特性而衰減。 這不是我們在實驗中觀察到的。 F2 和 C1 網絡的訓練-測試曲線見圖 2,它們是其他網絡的代表。 因此,旨在防止模型過擬合的早停的啟發式方法并不能夠縮小泛化差距。”
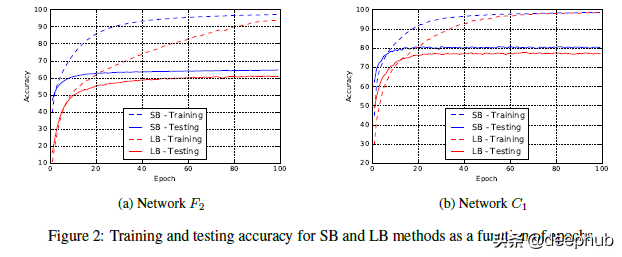
看看網絡收斂到測試精度的速度有多快
簡而言之,如果這是過度擬合的情況,將不會看到 大批次 方法的性能始終較低。 相反通過更早的停止,我們將避免過擬合并且性能會更接近。 這不是我們觀察到的。 我們的學習曲線描繪了一幅截然不同的表現。