













詳解數(shù)據(jù)存儲的六種可選技術

本文轉載自微信公眾號「數(shù)倉寶貝庫」,作者Saurabh。轉載本文請聯(lián)系數(shù)倉寶貝庫公眾號。
熱數(shù)據(jù)需要在內存中存儲和處理,因此適合用緩存或內存數(shù)據(jù)庫(如Redis或SAP Hana)。AWS提供了ElastiCache服務,可生成托管的Redis或Memcached環(huán)境。NoSQL數(shù)據(jù)庫是面向高速但小規(guī)模記錄(例如,用戶會話信息或物聯(lián)網(wǎng)數(shù)據(jù))的理想選擇。NoSQL數(shù)據(jù)庫對于內容管理也很有用,可以存儲數(shù)據(jù)目錄。
1結構化數(shù)據(jù)存儲
結構化數(shù)據(jù)存儲已經(jīng)存在了幾十年,是人們最熟悉的數(shù)據(jù)存儲技術。大多數(shù)事務型數(shù)據(jù)庫(如Oracle、MySQL、SQL Server和PostgreSQL)都是行式數(shù)據(jù)庫,因為要處理來自軟件應用程序的頻繁數(shù)據(jù)寫入。企業(yè)經(jīng)常將事務型數(shù)據(jù)庫同時用于報表,在這種情況下,需要頻繁讀取數(shù)據(jù),但數(shù)據(jù)寫入頻率要低得多。隨著數(shù)據(jù)讀取的需求越來越強,有更多的創(chuàng)新進入了結構化數(shù)據(jù)存儲的查詢領域,比如列式文件格式的創(chuàng)新,它有助于提高數(shù)據(jù)讀取性能,滿足分析需求。
基于行的格式將數(shù)據(jù)以行的形式存儲在文件中。基于行的寫入方式是將數(shù)據(jù)寫入磁盤的最快方式,但它不一定能最快地讀取,因為你必須跳過很多不相關的數(shù)據(jù)。基于列的格式將所有的列值一起存儲在文件中。這樣會帶來更好的壓縮效果,因為相同的數(shù)據(jù)類型現(xiàn)在被歸為一組。通常,它還能提供更好的讀取性能,因為你可以跳過不需要的列。
我們來看結構化數(shù)據(jù)存儲的常見選擇。例如,你需要從訂單表中查詢某個月的銷售總數(shù),但該表有50列。在基于行的架構中,查詢時會掃描整個表的50個列,但在列式架構中,查詢時只會掃描訂單銷售列,因而提高了數(shù)據(jù)查詢性能。我們再來詳細介紹關系型數(shù)據(jù)庫,重點介紹事務數(shù)據(jù)和數(shù)據(jù)倉庫處理數(shù)據(jù)分析的需求。
(1)關系型數(shù)據(jù)庫
RDBMS比較適合在線事務處理(OLTP)應用。流行的關系型數(shù)據(jù)庫有Oracle、MSSQL、MariaDB、PostgreSQL等。其中一些傳統(tǒng)數(shù)據(jù)庫已經(jīng)存在了幾十年。許多應用,包括電子商務、銀行業(yè)務和酒店預訂,都是由關系型數(shù)據(jù)庫支持的。關系型數(shù)據(jù)庫非常擅長處理表之間需要復雜聯(lián)合查詢的事務數(shù)據(jù)。從事務數(shù)據(jù)的需求來看,關系型數(shù)據(jù)庫應該堅持原子性、一致性、隔離性、持久性原則,具體如下:
- 原子性:事務將從頭到尾完全執(zhí)行,一旦出現(xiàn)錯誤,整個事務將會回滾。
- 一致性:一旦事務完成,所有的數(shù)據(jù)都要提交到數(shù)據(jù)庫中。
- 隔離性:要求多個事務能在隔離的情況下同時運行,互不干擾。
- 持久性:在任何中斷(如網(wǎng)絡或電源故障)的情況下,事務應該能夠恢復到最后已知的狀態(tài)。
通常情況下,關系型數(shù)據(jù)庫的數(shù)據(jù)會被轉存到數(shù)據(jù)倉庫中,用于報表和聚合。
(2)數(shù)據(jù)倉庫
數(shù)據(jù)倉庫更適合在線分析處理(OLAP)應用。數(shù)據(jù)倉庫提供了對海量結構化數(shù)據(jù)的快速聚合功能。雖然這些技術(如Amazon Redshift、Netezza和Teradata)旨在快速執(zhí)行復雜的聚合查詢,但它們并沒有針對大量并發(fā)寫入進行過優(yōu)化。所以,數(shù)據(jù)需要分批加載,使得倉庫無法在熱數(shù)據(jù)上提供實時洞察。
現(xiàn)代數(shù)據(jù)倉庫使用列式存儲來提升查詢性能,例如Amazon Redshift、Snowflake和Google Big Query。得益于列式存儲,這些數(shù)據(jù)倉庫提供了非常快的查詢速度,提高了I/O效率。除此之外,Amazon Redshift等數(shù)據(jù)倉庫系統(tǒng)還通過在多個節(jié)點上并行查詢以及大規(guī)模并行處理(MPP)來提高查詢性能。
數(shù)據(jù)倉庫是中央存儲庫,可以存儲來自一個或多個數(shù)據(jù)庫的累積數(shù)據(jù)。它們存儲當前和歷史數(shù)據(jù),用于創(chuàng)建業(yè)務數(shù)據(jù)的分析報告。雖然,數(shù)據(jù)倉庫集中存儲來自多個系統(tǒng)的數(shù)據(jù),但它們不能被視為數(shù)據(jù)湖。數(shù)據(jù)倉庫只能處理結構化的關系型數(shù)據(jù),而數(shù)據(jù)湖則可以同時處理結構化的關系型數(shù)據(jù)和非結構化的數(shù)據(jù),如JSON、日志和CSV數(shù)據(jù)。
Amazon Redshift等數(shù)據(jù)倉庫解決方案可以處理PB級的數(shù)據(jù),并提供解耦的計算和存儲功能,以節(jié)省成本。除了列式存儲外,Redshift還使用數(shù)據(jù)編碼、數(shù)據(jù)分布和區(qū)域映射來提高查詢性能。比較傳統(tǒng)的基于行的數(shù)據(jù)倉庫解決方案包括Netezza、Teradata和Greenplum。
2NoSQL數(shù)據(jù)庫
NoSQL數(shù)據(jù)庫(如Dynamo DB、Cassandra和Mongo DB)可以解決在關系型數(shù)據(jù)庫中經(jīng)常遇到的伸縮和性能挑戰(zhàn)。顧名思義,NoSQL表示非關系型數(shù)據(jù)庫。NoSQL數(shù)據(jù)庫儲存的數(shù)據(jù)沒有明確結構機制連接不同表中的數(shù)據(jù)(沒有連接、外鍵,也不具備范式)。
NoSQL運用了多種數(shù)據(jù)模型,包括列式、鍵值、搜索、文檔和圖模型。NoSQL數(shù)據(jù)庫提供可伸縮的性能、具有高可用性和韌性。NoSQL通常沒有嚴格的數(shù)據(jù)庫模式,每條記錄都可以有任意數(shù)量的列(屬性),這意味著某一行可以有4列,而同一個表中的另一行可以有10列。分區(qū)鍵用于檢索包含相關屬性的值或文檔。NoSQL數(shù)據(jù)庫是高度分布式的,可以復制。NoSQL數(shù)據(jù)庫非常耐用,高可用的同時不會出現(xiàn)性能問題。
SQL數(shù)據(jù)庫已經(jīng)存在了幾十年,大多數(shù)人可能已經(jīng)非常熟悉關系型數(shù)據(jù)庫。我們來看SQL數(shù)據(jù)庫和NoSQL數(shù)據(jù)庫之間的一些重大區(qū)別(見表1)。
表1 SQL數(shù)據(jù)庫和NoSQL數(shù)據(jù)庫的區(qū)別
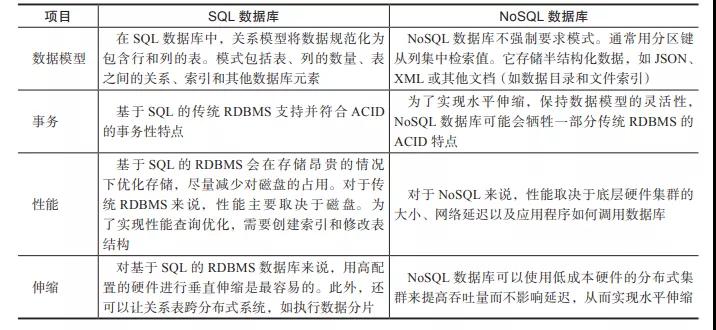
根據(jù)數(shù)據(jù)特點,市面上有各種類別的NoSQL數(shù)據(jù)存儲來解決特定的問題。我們來看NoSQL數(shù)據(jù)庫的類型。
3NoSQL數(shù)據(jù)庫類型
NoSQL數(shù)據(jù)庫的主要類型如下:
- 列式數(shù)據(jù)庫:Apache Cassandra和Apache HBase是流行的列式數(shù)據(jù)庫。列式數(shù)據(jù)存儲有助于在查詢數(shù)據(jù)時掃描某一列,而不是掃描整行。如果物品表有10列100萬行,而你想查詢庫存中某一物品的數(shù)量,那么列式數(shù)據(jù)庫只會將查詢應用于物品數(shù)量列,不需要掃描整個表。
- 文檔數(shù)據(jù)庫:最流行的文檔數(shù)據(jù)庫有MongoDB、Couchbase、MarkLogic、Dynamo DB和Cassandra。可以使用文檔數(shù)據(jù)庫來存儲JSON和XML格式的半結構化數(shù)據(jù)。
- 圖數(shù)據(jù)庫:流行的圖數(shù)據(jù)庫包括Amazon Neptune、JanusGraph、TinkerPop、Neo4j、OrientDB、GraphDB和Spark上的GraphX。圖數(shù)據(jù)庫存儲頂點和頂點之間的鏈接(稱為邊)。圖可以建立在關系型和非關系型數(shù)據(jù)庫上。
- 內存式鍵值存儲:最流行的內存式鍵值存儲是Redis和Memcached。它們將數(shù)據(jù)存儲在內存中,用于數(shù)據(jù)讀取頻率高的場景。應用程序的查詢首先會轉到內存數(shù)據(jù)庫,如果數(shù)據(jù)在緩存中可用,則不會沖擊主數(shù)據(jù)庫。內存數(shù)據(jù)庫很適合存儲用戶會話信息,這些數(shù)據(jù)會導致復雜的查詢和頻繁的請求數(shù)據(jù),如用戶資料。
NoSQL有很多用例,但要建立數(shù)據(jù)搜索服務,需要對所有數(shù)據(jù)建立索引。
4搜索數(shù)據(jù)存儲
Elasticsearch是大數(shù)據(jù)場景(如點擊流和日志分析)最受歡迎的搜索引擎之一。搜索引擎能很好地支持對具有任意數(shù)量的屬性(包括字符串令牌)的溫數(shù)據(jù)進行臨時查詢。Elasticsearch非常流行。一般的二進制或對象存儲適用于非結構化、不可索引和其他沒有專業(yè)工具能理解其格式的數(shù)據(jù)。
Amazon Elasticsearch Service管理Elasticsearch集群,并提供API訪問。它還提供了Kibana作為可視化工具,對Elasticsearch集群中的存儲的索引數(shù)據(jù)進行搜索。AWS管理集群的容量、伸縮和補丁,省去了運維開銷。日志搜索和分析是常見的大數(shù)據(jù)應用場景,Elasticsearch可以幫助你分析來自網(wǎng)站、服務器、物聯(lián)網(wǎng)傳感器的日志數(shù)據(jù)。Elasticsearch被大量的行業(yè)應用使用,如銀行、游戲、營銷、應用監(jiān)控、廣告技術、欺詐檢測、推薦和物聯(lián)網(wǎng)等。
5非結構化數(shù)據(jù)存儲
當你有非結構化數(shù)據(jù)存儲的需求時,Hadoop似乎是一個完美的選擇,因為它是可擴展、可伸縮的,而且非常靈活。它可以運行在消費級設備上,擁有龐大的工具生態(tài),而且運行起來似乎很劃算。Hadoop采用主節(jié)點和子節(jié)點模式,數(shù)據(jù)分布在多個子節(jié)點,由主節(jié)點協(xié)調作業(yè),對數(shù)據(jù)進行查詢運算。Hadoop系統(tǒng)依托于大規(guī)模并行處理(MPP),這使得它可以快速地對各種類型的數(shù)據(jù)進行查詢,無論是結構化數(shù)據(jù)還是非結構化數(shù)據(jù)。
在創(chuàng)建Hadoop集群時,從服務器上創(chuàng)建的每個子節(jié)點都會附帶一個稱為本地Hadoop分布式文件系統(tǒng)(HDFS)的磁盤存儲塊。你可以使用常見的處理框架(如Hive、Ping和Spark)對存儲數(shù)據(jù)進行查詢。但是,本地磁盤上的數(shù)據(jù)只在相關實例的生命期內持久化。
如果使用Hadoop的存儲層(即HDFS)來存儲數(shù)據(jù),那么存儲與計算將耦合在一起。增加存儲空間意味著必須增加更多的機器,這也會提高計算能力。為了獲得最大的靈活性和最佳成本效益,需要將計算和存儲分開,并將兩者獨立伸縮。總的來說,對象存儲更適合數(shù)據(jù)湖,以經(jīng)濟高效的方式存儲各種數(shù)據(jù)。基于云計算的數(shù)據(jù)湖在對象存儲的支持下,可以靈活地將計算和存儲解耦。
6數(shù)據(jù)湖
數(shù)據(jù)湖是結構化和非結構化數(shù)據(jù)的集中存儲庫。數(shù)據(jù)湖正在成為在集中存儲中存儲和分析大量數(shù)據(jù)的一種流行方式。它按原樣存儲數(shù)據(jù),使用開源文件格式來實現(xiàn)直接分析。由于數(shù)據(jù)可以按當前格式原樣存儲,因此不需要將數(shù)據(jù)轉換為預定義的模式,從而提高了數(shù)據(jù)攝取的速度。如圖1所示,數(shù)據(jù)湖是企業(yè)中所有數(shù)據(jù)的單一真實來源。
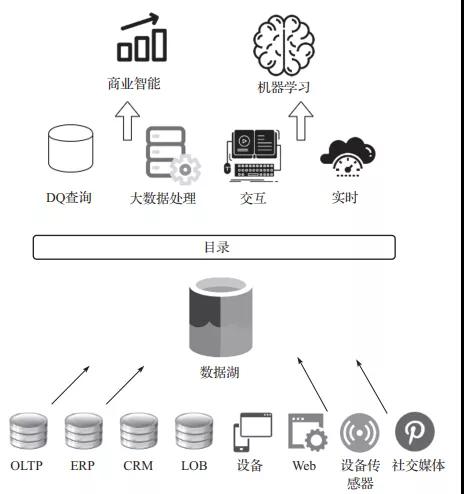
圖1 數(shù)據(jù)湖的對象存儲
數(shù)據(jù)湖的好處如下:
從各種來源攝取數(shù)據(jù):數(shù)據(jù)湖可以讓你在一個集中的位置存儲和分析來自各種來源(如關系型、非關系型數(shù)據(jù)庫以及流)的數(shù)據(jù),以產(chǎn)生單一的真實來源。它解答了一些問題,例如,為什么數(shù)據(jù)分布在多個地方?單一真實來源在哪里?
采集并高效存儲數(shù)據(jù):數(shù)據(jù)湖可以攝取任何類型的數(shù)據(jù),包括半結構化和非結構化數(shù)據(jù),不需要任何模式。這就回答了如何從各種來源、各種格式的數(shù)據(jù)中快速攝取數(shù)據(jù),并高效地進行大規(guī)模存儲的問題。
隨著產(chǎn)生的數(shù)據(jù)量不斷擴展:數(shù)據(jù)湖允許你將存儲層和計算層分開,對每個組件分別伸縮。這就回答了如何隨著產(chǎn)生的數(shù)據(jù)量進行伸縮的問題。
將分析方法應用于不同來源的數(shù)據(jù):通過數(shù)據(jù)湖,你可以在讀取時確定數(shù)據(jù)模式,并對從不同資源收集的數(shù)據(jù)創(chuàng)建集中的數(shù)據(jù)目錄。這使你能夠隨時、快速地對數(shù)據(jù)進行分析。這回答了是否能將多種分析和處理框架應用于相同的數(shù)據(jù)的問題。
你需要為數(shù)據(jù)湖提供一個能無限伸縮的數(shù)據(jù)存儲解決方案。將處理和存儲解耦會帶來巨大的好處,包括能夠使用各種工具處理和分析相同的數(shù)據(jù)。雖然這可能需要一個額外的步驟將數(shù)據(jù)加載到對應工具中,但使用Amazon S3作為中央數(shù)據(jù)存儲比傳統(tǒng)存儲方案有更多的好處。
數(shù)據(jù)湖還有其他好處。它能讓你的架構永不過時。假設12個月后,可能會有你想要使用的新技術。因為數(shù)據(jù)已經(jīng)存在于數(shù)據(jù)湖,你可以以最小的開銷將這種新技術插入工作流程中。通過在大數(shù)據(jù)處理流水線中構建模塊化系統(tǒng),將AWS S3等通用對象存儲作為主干,當特定模塊不再適用或有更好的工具時,可以自如地替換。
本文摘編自《解決方案架構師修煉之道》,經(jīng)出版方授權發(fā)布。(ISBN:9787111694441)轉載請保留文章出處。

















