













Meta AI推出“雜食者”:一個模型搞定圖像視頻和3D數據的分類任務
本文經AI新媒體量子位(公眾號ID:QbitAI)授權轉載,轉載請聯系出處。
最近,Meta AI推出了這樣一個“雜食者” (Omnivore)模型,可以對不同視覺模態的數據進行分類,包括圖像、視頻和3D數據。

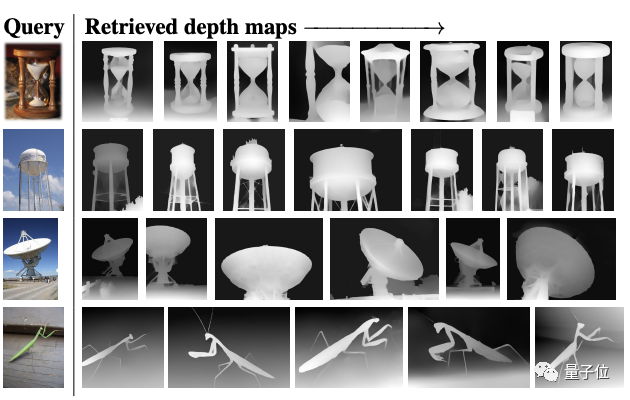
比如面對最左邊的圖像,它可以從深度圖、單視覺3D圖和視頻數據集中搜集出與之最匹配的結果。
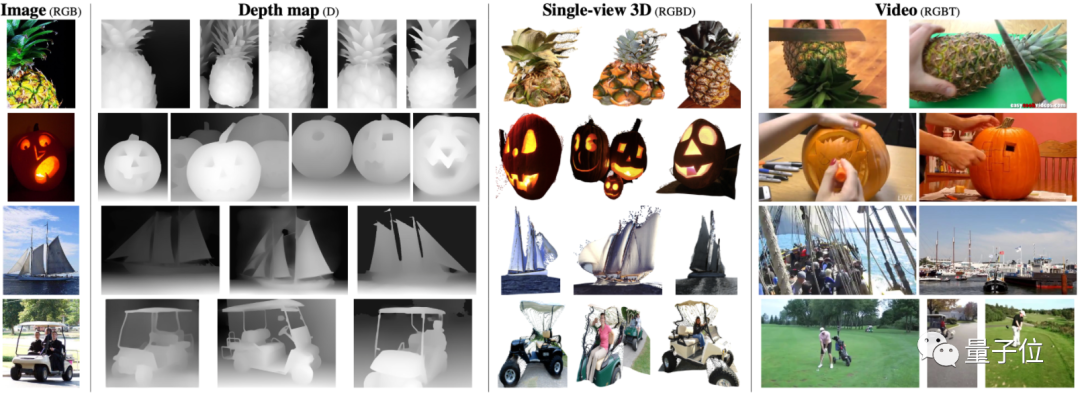
這在之前,都要分用不同的模型來實現;現在一個模型就搞定了。
而且Omnivore易于訓練,使用現成的標準數據集,就能讓其性能達到與對應單模型相當甚至更高的水平。
實驗結果顯示,Omnivore在圖像分類數據集ImageNet上能達到86.0%?的精度,在用于動作識別的Kinetics數據集上能達84.1%,在用于單視圖3D場景分類的SUN RGB-D也獲得了67.1%。
另外,Omnivore在實現一切跨模態識別時,都無需訪問模態之間的對應關系。
不同視覺模態都能通吃的“雜食者”
Omnivore基于Transformer體系結構,具備該架構特有的靈活性,并針對不同模態的分類任務進行聯合訓練。
模型架構如下:
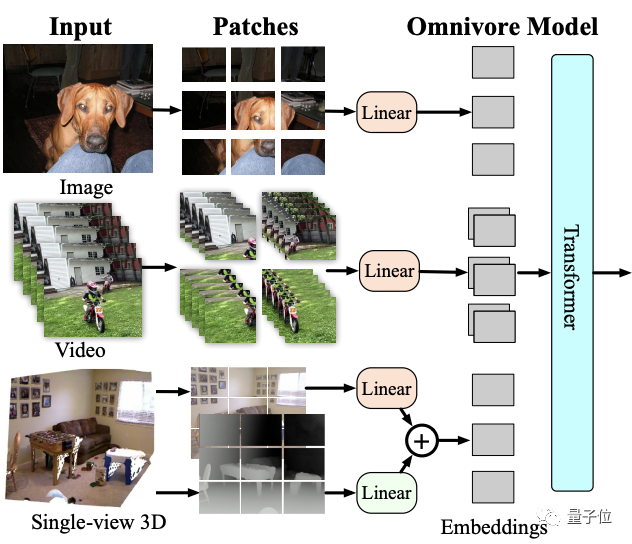
Omnivore會將輸入的圖像、視頻和單視圖3D圖像轉換為embedding,并饋送到Transformer中。
雖然它可以使用任何vision transformer架構來處理patch embedding,但鑒于Swin transformer在圖像和視頻任務上的強大性能,這里就使用該架構作為基礎模型。
具體來說,Omnivore將圖像轉為patch,視頻轉為時空tube(spatio-temporal tube),單視圖3D圖像轉為RGB patch和深度patch。
然后使用線性層將patches映射到到embedding中。其中對RGB patch使用同一線性層,對深度patch使用單獨的。
總的來說,就是通過embedding將所有視覺模式轉換為通用格式?,然后使用一系列時空注意力(attention)操作來構建不同視覺模式的統一表示。
研究人員在ImageNet-1K數據集、Kinetics-400數據集和SUN RGB-D數據集上聯合訓練出各種Omnivore模型。
這種方法類似于多任務學習和跨模態對齊,但有2點重要區別:
1、不假設輸入觀測值對齊(即不假設圖像、視頻和3D數據之間的對應關系);
2、也不假設這些數據集共享相同的標簽空間(label space)。
性能超SOTA
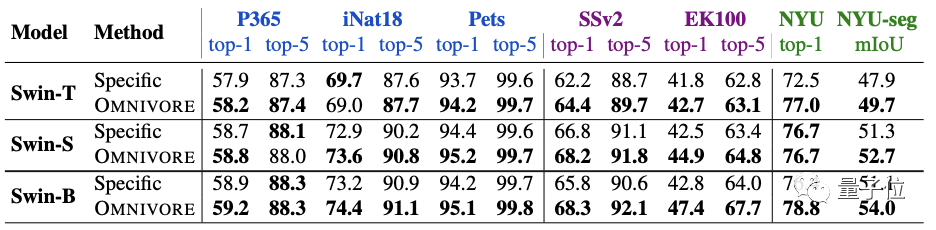
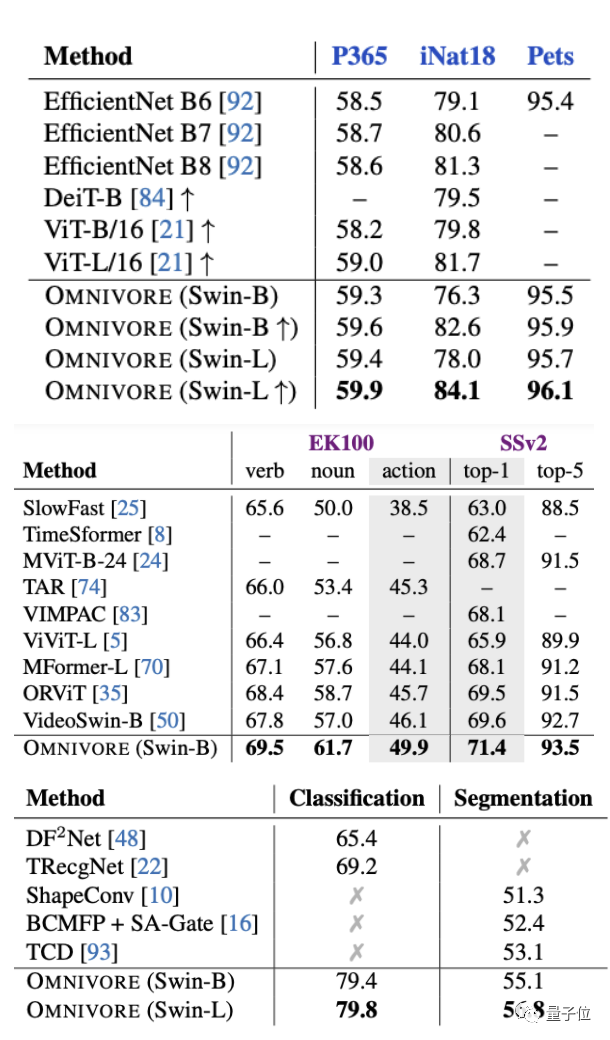
實驗方面,首先將Omnivore與各視覺模態對應的特定模型(?下表中指Specific)進行比較。
一共有三種不同的模型尺寸:T、S和B。
預訓練模型在七個下游任務上都進行了微調。
圖像特定模型在IN1K上預訓練。視頻特定模型和單視圖3D特定模型均使用預訓練圖像特定模型的inflation進行初始化,并分別在K400和SUN RGB-D上進行微調。
結果發現,Omnivore在幾乎所有的下游任務上的性能都相當于或優于各特定模型。
其中尺寸最大的Swin-B實現了全部任務上的SOTA。
將Omnivore與具有相同模型架構和參數數量的特定模型比較也是相同的結果。
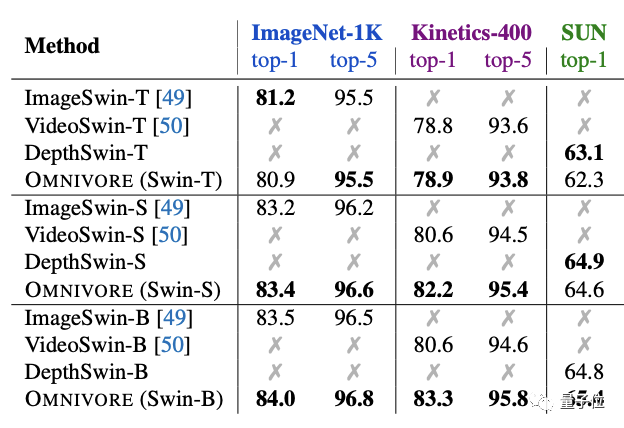
其中Omnivore在IN1K、K400和SUN數據集上從頭開始聯合訓練,而特定模態的模型針對每個數據集專門訓練:
ImageSwin模型從零開始訓練,VideoSwin和DepthSwin模型則從ImageSwin模型上進行微調。
接下來將Omnivore與圖像、視頻和3D數據分類任務上的SOTA模型進行比較。
結果仍然不錯,Omnivore在所有預訓練任務中都表現出了優于SOTA模型的性能(下圖從上至下分別為圖像、視頻和3D數據)。
此外,在ImageNet-1K數據集上檢索給定RGB圖像的深度圖也發現,盡管Omnivore沒有接受過關于1K深度圖的訓練,但它也能夠給出語義相似的正確答案。
最后,作者表示,盡管這個“雜食者”比傳統的特定模式模型有了很多進步,但它有一些局限性。
比如目前它僅適用于單視圖3D圖像,不適用于其他3D表示,如體素圖(voxels)、點云圖等。
論文地址:
?????https://arxiv.org/abs/2201.08377????
代碼已開源:
????https://github.com/facebookresearch/omnivore????


























