













一文搞懂七種基本的GC垃圾回收算法
作者 | mingguangtu
本文主要是中村成洋、相川光寫的《垃圾回收的算法與實現》一書的讀書筆記,沒有輸出的學習就是一盤散沙。我們要學習GC就要系統性的學,形成自己的知識框架,后面再學習其他的GC實現,就知道該放在框架的哪個地方,本文起到了作為GC知識框架的作用。不管技術風云怎么變化,打牢基礎總是不會錯的。

一、為什么要有GC
1. 什么是GC
GC 是 Garbage Collection 的簡稱,中文稱為“垃圾回收”。GC ,是指程序把不用的內存空間視為垃圾并回收掉的整套動作。
GC 要做的有兩件事:
- 找到內存空間里的垃圾;
- 回收垃圾,讓程序能再次利用這部分空間。
滿足這兩項功能的程序就是 GC。
2. 為什么要有GC
在沒有 GC 的世界里,程序員必須自己手動進行內存管理,必須清楚地確保必要的內存空間,釋放不要的內存空間。
程序員在手動進行內存管理時,申請內存尚不存在什么問題,但在釋放不要的內存空間時,就必須一個不漏地釋放。這非常地麻煩。容易發(fā)生下面三種問題:內存泄露,懸垂指針,錯誤釋放引發(fā)BUG。
- 如果忘記釋放內存空間,該內存空間就會發(fā)生內存泄露(內存空間在使用完畢后未釋放),即無法被使用,但它又會持續(xù)存在下去。如果將發(fā)生內存泄露的程序放著不管,總有一刻內存會被占滿,甚至還可能導致系統崩潰。
- 在釋放內存空間時,如果忘記初始化指向已經回收的內存地址(對象已釋放)的指針,這個指針就會一直指向釋放完畢的內存空間。此時,這個指針處于一種懸掛的狀態(tài),我們稱其為“懸垂指針”(dangling pointer)。如果在程序中錯誤地引用了懸垂指針, 就會產生無法預期的 BUG。
- 一旦錯誤釋放了使用中的內存空間,下一次程序使用此空間時就會發(fā)生故障。大多數情況下會發(fā)生段錯誤,運氣不好的話還可能引發(fā)惡性 BUG,甚至引發(fā)安全漏洞。
為了省去上述手動內存管理的麻煩,人們鉆研開發(fā)出了 GC。如果把內存管理交給計算機, 程序員就不用去想著釋放內存了。
當然,技術領域的不變法則就是萬事皆有代價,GC 也會帶來一些麻煩,比如后臺程序需要耗費一定的CPU和內存資源去釋放內存,在系統繁忙的情況下會對業(yè)務程序性能造成一定的不利影響,為了解決GC帶來的問題,最近幾年出現了一門新的沒有GC的Rust語言,大有替代C語言的趨勢,不過學習曲線比較陡峭,感興趣的同學可以自行鉆研。
二、GC相關的基本術語
1. 對象、指針、活動對象、非活動對象、堆、根
GC操作的基本單元可以叫做對象。對象是內存空間的某些數據的集合。在本文中,對象由頭(header)和域(field)構成。
對象的頭,主要包含對象的大小、種類信息。對象中可訪問的部分稱為“域”,可以認為是 C 語言中結構體的成員變量。如圖2.1所示。
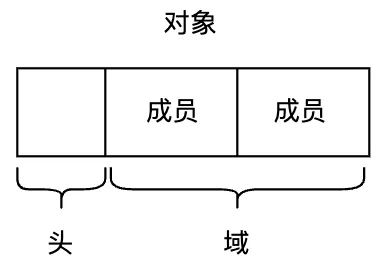
圖2.1 對象、頭、域
指針是指向內存空間中某塊區(qū)域的值。GC 是根據對象的指針指向去搜尋其他對象的。對象和指針的關系如圖2.2所示。
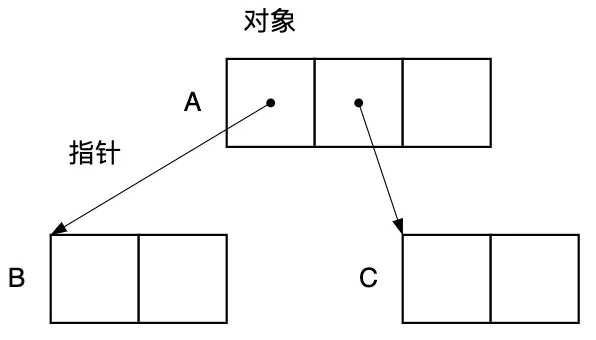
圖2.2 對象和指針
我們將內存空間中被其他對象通過指針引用的對象成為活動對象,沒有對象引用的對象是非活動對象,也就是GC需要回收的垃圾。如圖2.3所示。
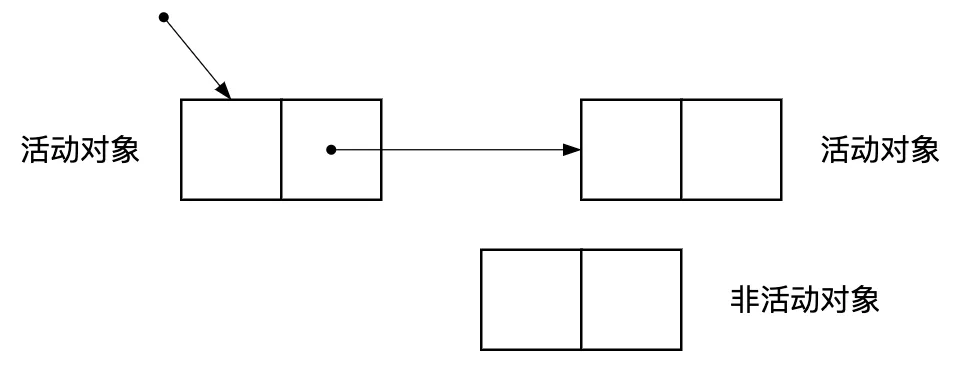
圖2.3 活動對象和非活動對象
根(root)是“根基”“根底”。在 GC 的世界里,根是指向對象的指針的“起點” 部分。堆指的是用于動態(tài)(也就是執(zhí)行程序時)存放對象的內存空間。當應用程序申請存放對象時, 所需的內存空間就會從這個堆中被分配給 應用程序。如圖2.4所示。
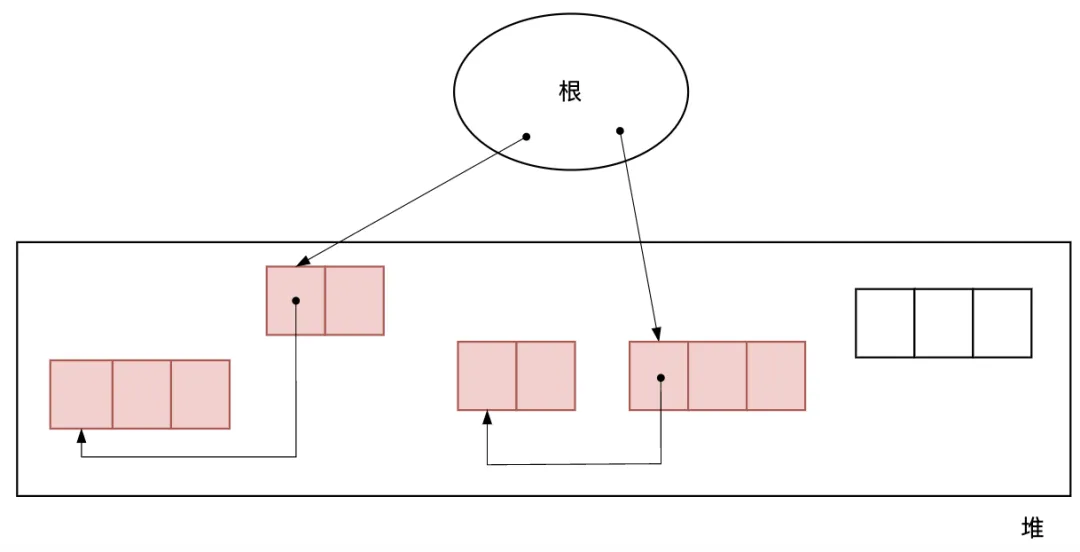
圖2.4 根和堆里的對象
2. GC算法性能的評價標準
評價 GC 算法的性能時,我們采用以下 4 個標準。
- 吞吐量
- 最大暫停時間
- 堆使用效率
- 訪問的局部性
(1) 吞吐量
GC的吞吐量是:運行用戶代碼時間 / (運行用戶代碼時間 + 垃圾收集時間)。
如圖2.5所示,在程序運行的整個過程中,應用程序的時間是X、Y、Z,應用程序的總時間是 X + Y + Z。GC一共啟動了兩次,花費的時間為A、B,則GC總花費的時間是 A + B。這種情況下 GC 的吞吐量為 (X + Y + Z) /(X + Y + Z + A + B)。
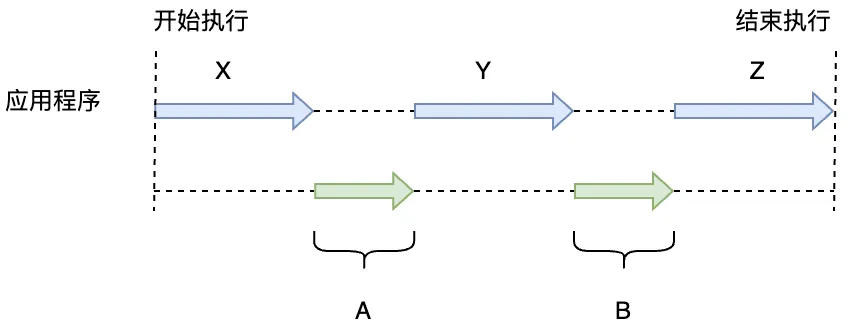
圖2.5 應用程序和GC的執(zhí)行示意圖
從這里的描述可知,GC的吞吐量就是應用程序執(zhí)行的時間(不是內存大小哦)和GC時間的比值,GC執(zhí)行的總時間越短,GC吞吐量越大。
人們通常都喜歡吞吐量高的 GC 算法。然而判斷各算法吞吐量的好壞時不能一概而論。因為工程技術中,任何好處都是有代價的。
(2) 最大暫停時間
本文介紹的所有GC算法,都會在GC執(zhí)行過程中另應用程序暫停執(zhí)行。最大暫停時間指的是“因執(zhí)行GC而暫停執(zhí)行應用程序的最長時間”。
當編寫像動作游戲這樣追求即時性的程序時,就必須盡量壓低 GC 導致的最大暫停時間。如果因為 GC 導致玩家頻繁卡頓,相信誰都會想摔手柄。對音樂和動畫這樣類似于編碼應用的程序來說,GC 的最大暫停時間就不那么重要了。更為重要的是,我們必須選擇一個整體處理時間更短的算法。
不管嘗試哪種 GC 算法,我們都會發(fā)現較大的吞吐量和較短的最大暫停時間不可兼得。所以應根據執(zhí)行的應用所重視的指標的不同,來分別采用不同的 GC 算法。
(3) 堆使用效率
堆使用效率,是指:程序在運行過程中,單位時間內能使用的堆內存空間的大小。舉個例子,GC 復制算法中將堆二等分,每次只使用一半,交替進行,因此總是只能利用堆的一半。相對而言,GC 標記-清除算法和引用計數法就能利用整個堆。
與吞吐量和最大暫停時間一樣,堆使用效率也是 GC 算法的重要評價指標之一。
然而,堆使用效率和吞吐量,以及最大暫停時間不可兼得。簡單地說就是:可用的堆越大,GC 運行越快;相反,越想有效地利用有限的堆,GC 花費的時間就越長。
(4) 訪問的局部性
計算機上有 4 種存儲器,分別是寄存器、緩存、內存、輔助存儲器。它們之間有著如圖 2.6 所示的層級關系。

圖2.6 存儲器的層次結構
眾所周知,越是可實現高速存取的存儲器容量就越小。計算機會盡可能地利用較高速的存儲器,但由于高速的存儲器容量小,不可能把所有要利用的數據都放在寄存器和高速緩存里。一般我們會把所有的數據都放在內存里,當 CPU 訪問數據時,僅把要使用的數據從內存讀取到緩存。由于數據是分塊讀取,我們還將它附近的所有數據都讀取到高速緩存中, 從而壓縮讀取數據所需要的時間。這種內存空間中相鄰的數據很可能存在連續(xù)訪問因而帶來訪問效率提升的情況,稱為“訪問的局部性”。
部分GC算法會利用這種局部性原理,把具有引用關系的對象安排在堆中較近的位置,就能提高在緩存Cache中讀取到想要的數據的概率,令應用程序高速運行。
三、常用的GC算法
三種最基本的GC算法是標記-清除法、引用計數法、GC復制算法。后面延伸出來的4種不過是三種基本算法的組合而已。
1. GC標記-清除法
GC 標記-清除算法由標記階段和清除階段構成。標記階段是把所有活動對象都做上標記的階段。清除階段是把那些沒有標記的對象,也就是非活動對象回收的階段。通過這兩個階段,就可以令不能利用的內存空間重新得到利用。
說了說明GC標記-清除算法的工作原理,下面分為標記、清除兩個階段來描述。
(1) 標記階段
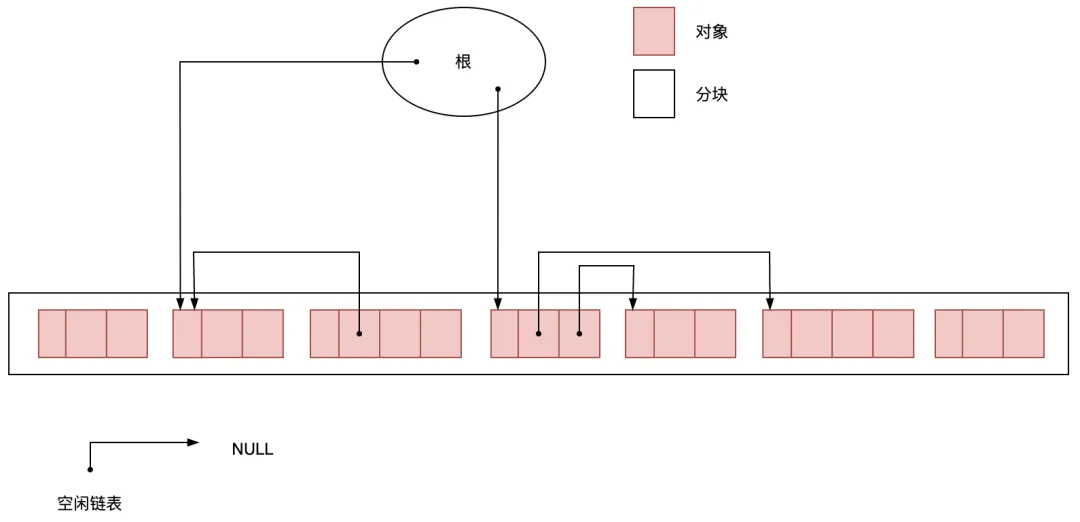
圖3.1 執(zhí)行GC前堆的狀態(tài)
執(zhí)行GC前堆的狀態(tài)如圖3.1所示。
在標記階段中,垃圾回收器Collector 會為堆里的所有活動對象打上標記。為此,我們首先要標記通過根直接引用的對象。首先我們標記這樣的對象,然后遞歸地標記通過指針數組能訪問到的對象。這樣就能把所有活動對象都標記上了。
標記Mark對象,是在對象的頭部進行置位操作。如圖3.2所示,是程序標記對象的動作示意。
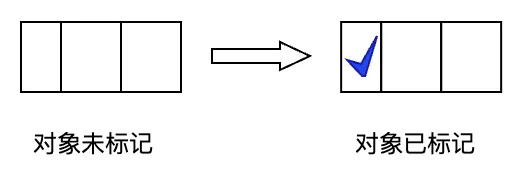
圖3.2 標記對象的動作示意
標記完所有活動對象后,標記階段就結束了。標記階段結束時的堆如圖 3.3 所示,從根對象沿著指針引用找下去,會發(fā)現有四個對象被引用,都需要打上標記位。
在標記階段中,程序會標記所有活動對象。毫無疑問,標記所花費的時間是與“活動對 象的總數”成正比的。
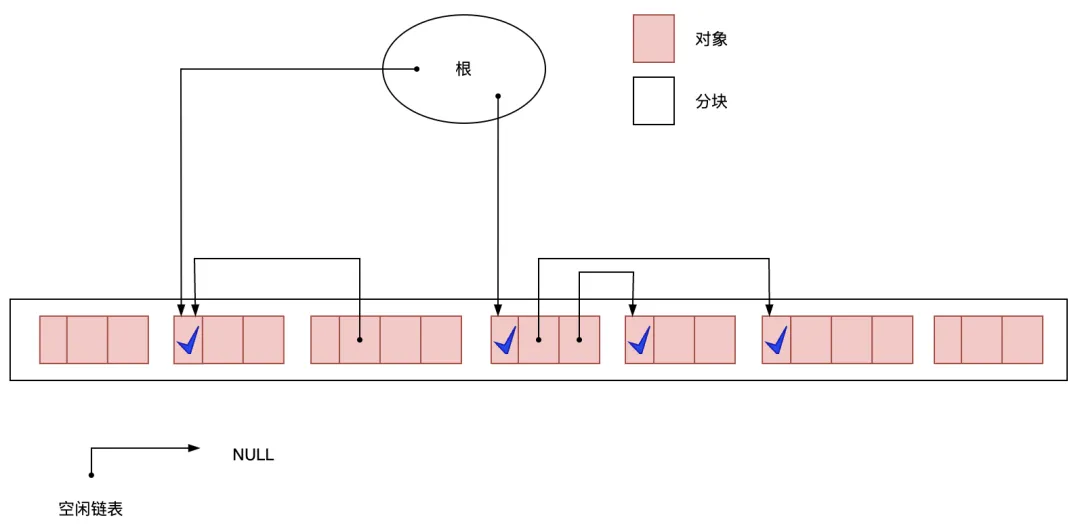
圖3.3 標記階段結束后的堆狀態(tài)
用一句話概括,標記階段就是“遍歷對象并標記”的處理過程。
(2) 清除階段
在清除階段中,垃圾回收器Collector 會遍歷整個堆,回收沒有打上標記的對象(即垃圾),使其能再次得到利用。
在清除階段,GC程序會遍歷堆,具體來說就是從堆首地址開始,按順序一個個遍歷對象的標志位。如果一個對象設置了標記位,就說明這個對象是活動對象,必然是不能被回收的。
GC程序會把非活動對象回收再利用。回收對象就是把對象作為分塊,連接到被稱為“空閑鏈表”的單向鏈表。在之后進行分配時只要遍歷這個空閑鏈表,就可以找到分塊了。
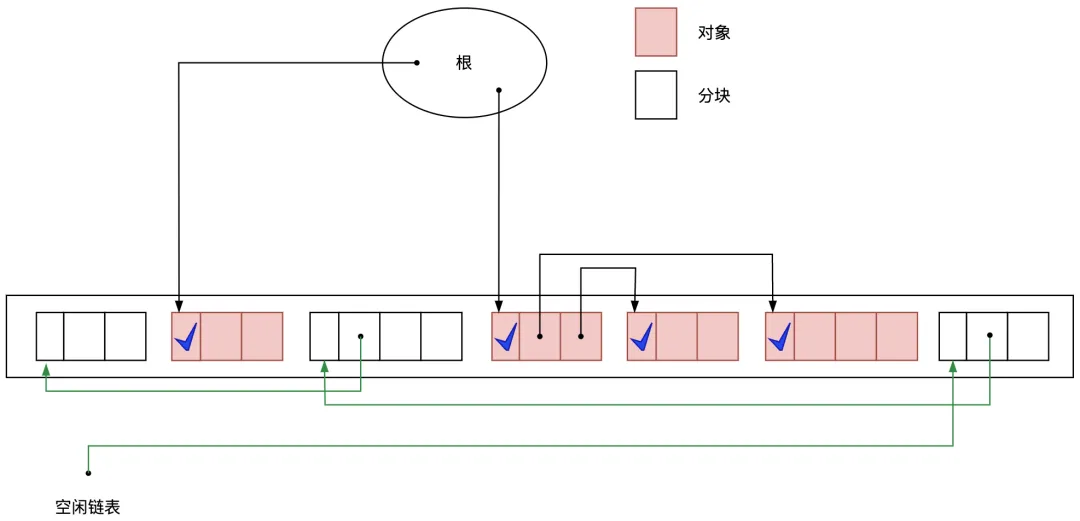
圖3.4 清除階段結束后的堆狀態(tài)
在清除階段,程序會遍歷所有堆,進行垃圾回收。也就是說,所花費時間與堆大小成正 比。堆越大,清除階段所花費的時間就會越長。
在GC的標記-清除過程中,還會不斷進行的兩個動態(tài)操作那就是分配和合并。
① 分配
分配是指將回收的垃圾進行再利用。
GC程序在清除階段已經把垃圾對象連接到空閑鏈表了。當應用程序創(chuàng)建新對象時,搜索空閑鏈表并尋找大小合適的分塊,這項操作就叫作分配。
② 合并
根據分配策略的不同可能會產生大量的小分塊。但如果它們是連續(xù)的, 我們就能把所有的小分塊連在一起形成一個大分塊。這種“連接連續(xù)分塊”的操作就叫作合并(coalescing),合并是在清除階段進行的。
(3) 標記清除法的優(yōu)點
- 實現簡單,很容易在基本的GC標記清除法基礎上改進,或者容易和其他算法組合形成新的GC算法。
- GC 標記-清除算法因為不會移動對象,所以非常適合搭配保守式 GC 算法。
(4) 標記清除法的缺點
- 碎片化。使用過程中會逐漸產生被細化的分塊,不久后就會導致無數的小分塊散布在堆的各處。
- 分配速度慢。GC 標記-清除算法中分塊不是連續(xù)的,因此每次分配都必須遍歷空閑鏈表,找到足夠大的分塊才行。
- 與寫時復制技術(copy-on-write)不兼容。這里不展開說了。
(5) GC標記-清除法的改進
① 改進一:分配速度的改進——多個空閑鏈表
之前介紹的基本標記-清除算法中只用到了一個空閑鏈表,在這個空閑鏈表中,對大的分塊和小的分塊進行同樣的處理。但是這樣一來,每次分配的時候都要遍歷一次空閑鏈表來尋找合適大小的分塊,這樣非常浪費時間。
可以尋求一種改進的方法,利用分塊大小不同的空閑鏈表,即創(chuàng)建只連接大分塊的空閑鏈表和只連接小分塊的空閑鏈表,甚至不同規(guī)格大小的分塊采用不同的空閑鏈表管理。這樣一來,只要按照應用程序所申請的對象大小選擇空閑鏈表,就能在短時間內找到符合條件的分塊了。我們知道,Golang的內存分配里就是這么做的了。
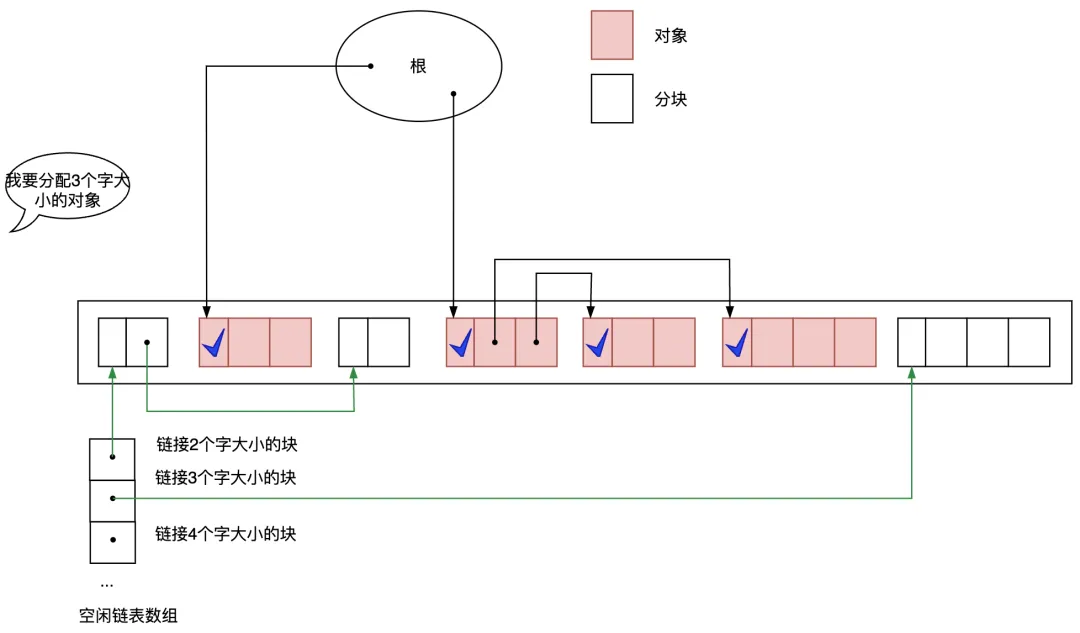
圖3.5 利用多個空閑鏈表提高分配速度
② 改進二:碎片化分塊問題的改進——BiBOP法
BiBOP 是 Big Bag Of Pages 的縮寫。用一句話概括就是“將大小相近的對象整理成固定大小的塊進行管理的做法”。
如圖3.6所示,是BiBOP 法的示意圖。把堆分割成多個規(guī)格大小的空間,讓每個規(guī)格的空間只能配置同樣大小的分塊。
2個字的分塊只能在最左邊的堆空間里分配,3個字的分塊只能在中間的堆空間分配,4個字的塊在最右邊。像這樣配置對象,就會提高內存的使用效率。

圖 3.6 BiBOP法的示意圖
2. 引用計數法
(1) 引用計數法的基本原理
引用計數法(Reference Counting)就是,讓所有對象事先記錄下“有多少程序引用自己”。形象點兒說,就是讓各對象知道自己的“人氣指數”,讓沒有人氣的對象自己消失。
引用計數法依靠“計數器”記錄有多少對象引用了自己(被引用數)。
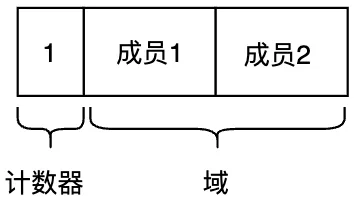
圖3.7 引用計數法中的對象
如圖3.8所示,是A的指針由指向B改為指向C時,各對象的計數器的變化情況。初始狀態(tài)下從根引用 A 和 C,從 A 引用 B。A 持有唯一指向 B 的指針,假設現在將該指針更新到了 C,B 的計數器值變成了 0,計數器變更時,計數器為0的對象會被回收,因此 B 被回收了。且 B 連接上了空閑鏈表, 能夠再被利用了。又因為新形成了由 A 指向 C 的指針,所以 C 的計數器的值增量為 2。
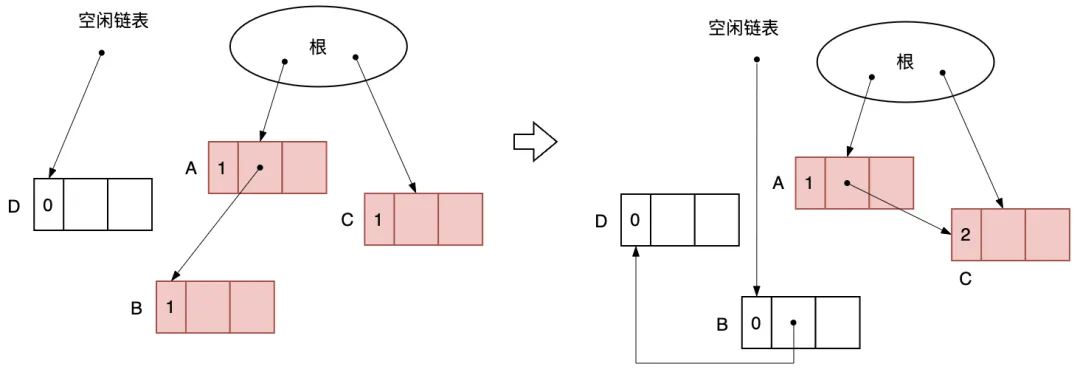
圖3.8 在對象引用變更時各對象的計數器的變化情況
(2) 引用計數法的優(yōu)點
- 可即刻回收垃圾。在引用計數法中,每個對象始終都知道自己的被引用數(就是計數器的值)。當被引用數的值為 0 時,對象馬上就會把自己作為空閑空間被GC程序連接到空閑鏈表。也就是說,各個對象在變成垃圾的同時就會立刻被回收。另一方面,在其他的 GC 算法中,即使對象變成了垃圾,程序也無法立刻判別。只有當內存分塊用盡后 GC 開始執(zhí)行時,才能知道哪個對象是垃圾,哪個對象不是垃圾。
- 最大暫停時間短。在引用計數法中,只有當應用程序更新指針時(計數器變更)程序才會執(zhí)行垃圾回收。也就是說, 每次生成垃圾時這部分垃圾都會被回收,因而大幅度地削減了GC的最大暫停時間。
- 沒有必要沿著指針查找被引用對象。引用計數法和 GC 標記-清除算法不一樣,沒必要由根沿著指針查找。當我們想減少沿著指針查找的次數時,它就派上用場了。打個比方,在分布式環(huán)境中,如果要沿各個計算節(jié)點之間的指針進行查找,成本就會增大。
(3) 引用計數法的缺點
- 計數器值的增減處理繁重。在程序繁忙的情況下,指針都會頻繁地更新。特別是有根的指針,會以極快的速度進行更新。在引用計數法中,每當指針更新時,計數器的值都會隨之更新,因此值的增減處理必然會變得繁重。
- 計數器需要占用很多位。用于引用計數的計數器最大必須能數完堆中所有對象的引用數。打個比方,假如我們用的是 32 位機器,那么就有可能要讓 2 的 32 次方個對象同時引用一個對象。考慮到這種情況, 就有必要確保各對象的計數器有 32 位大小。也就是說,對于所有對象,必須留有 32 位的空間。這就害得內存空間的使用效率大大降低了。
- 實現煩瑣復雜。該算法本身很簡單,但事實上實現起來卻不容易。進行指針更新操作時,需要同時變更對象引用和計數器,這容易導致遺漏,一旦遺漏了某處,內存管理就無法正確 進行,就會產生 BUG。
- 循環(huán)引用無法回收。因為兩個對象互相引用,所以各對象的計數器的值都是 1。但是這些對象組并沒有被其他任何對象引用。因此想一并回收這兩個對象都不行,只要它們的計數器值都 是 1,就無法回收。
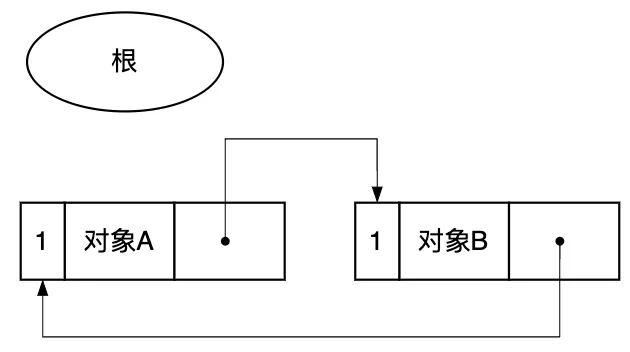
圖3.9 循環(huán)引用對象
最后,盡管引用計數法有很多缺點,引用計數法也不是一個“完全沒法用”的算法。事實上,很多處理系統和應用都在使用引用計數法。
因為引用計數法只要稍加改良,就會變得非常具有實用性了。
(4) 引用計數法的改進
① 改進一:延遲引用計數法
針對引用計數法“計數器增減處理繁重”的缺點,有人提出了延遲引用計數法(Deferred Reference Counting)。計數器值增減處理繁重的原因之一是從根的引用變化頻繁。延遲引用計數法就是讓從根引用的指針的變化不反映在計數器上,而是采用一個零數表ZCT(Zero Count Table)來存儲從根引用的各對象的被引用數,即使這個值變?yōu)?,程序也先不回收這個對象(延遲一詞體現在這),而是等零數表ZCT爆滿或者空閑鏈表為空時再掃描零數表ZCT,刪除確實沒有被引用的對象。這樣一來即使頻繁重寫堆中對象的引用關系,對象的計數器值也不會有所變化,因而大大改善了“計數器值的增減處理繁重”這一缺點。
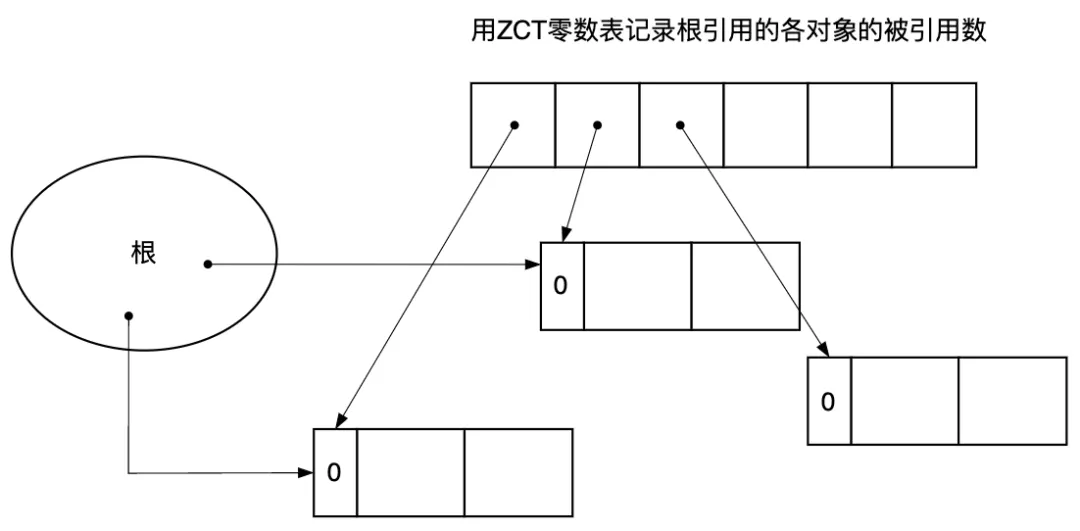
圖3.10 用零數表ZCT記錄根引用的各對象的被引用數
- 優(yōu)點:在延遲引用計數法中,程序延遲了根引用的計數。通過延遲,減輕了因根引用頻繁發(fā)生變化而導致的計數器增減所帶來的額外負擔。
- 缺點:為了延遲計數器值的增減,垃圾不能馬上得到回收,這樣一來垃圾就會壓迫堆,程序也就失去了引用計數法的一大優(yōu)點——可即刻回收垃圾。
② 改進二:減少計數器位數的Sticky 引用計數法
我們假設用于計數器的位數為 5 位,那么這種計數器最多只能數到 2 的 5 次方減 1,也就是 31 個引用數。如果此對象被大于 31 個對象引用,那么計數器就會溢出。對于計數器溢出的對象,有兩種處理方法:1)什么都不做,2)通過GC標記-清除法進行管理。
- 對于計數器溢出的對象,什么都不做。這樣一來,即使這個對象成了垃圾(即被引用數為 0),也不能將其回收。也就是說, 白白浪費了內存空間。然而事實上有很多研究表明,很多對象一生成馬上就死了。也就是說, 在很多情況下,計數器的值會在 0 到 1 的范圍內變化,鮮少出現 5 位計數器溢出這樣的情況。
- 對于計數器溢出的對象,通過GC標記-清除法進行管理。具體實現就不展開了。這種方式,在計數器溢出后即使對象成了垃圾,程序還是能回收它。另外還有一個優(yōu)點,那就是還能回收循環(huán)的垃圾。
3. GC復制算法
(1) 基本原理
GC 復制算法(Copying GC),就是只把某個空間里的活動對象復制到其他空間,把原空間里的所有對象都回收掉。在此,我們將復制活動對象的原空間稱為 From 空間,將粘貼活動對象的新空間稱為 To 空間。
GC 復制算法是利用 From 空間進行分配的。當 From 空間被完全占滿時,GC 會將活動對象全部復制到 To 空間。當復制完成后,該算法會把 From 空間和 To 空間互換,GC 也就結束了。From 空間和 To 空間大小必須一致。這是為了保證能把 From 空間中的所有活動對象都收納到 To 空間里。GC 復制算法的概要如圖 3.11 所示。
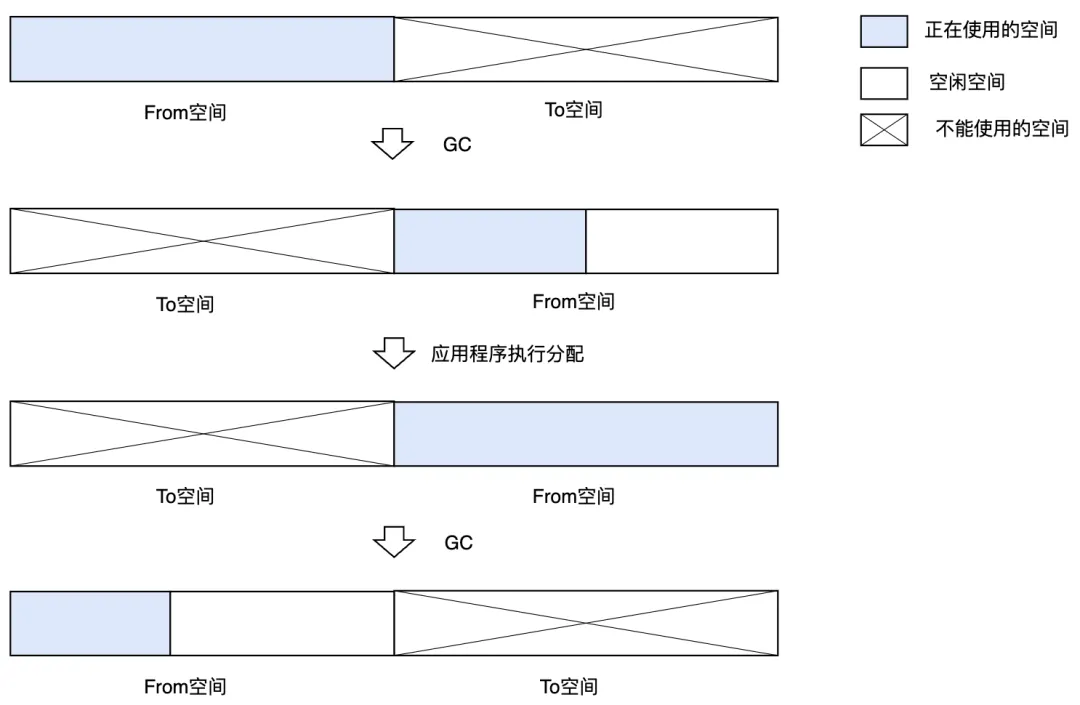
圖3.11 GC復制算法的示意圖
(2) GC復制算法的執(zhí)行過程
我們通過下面一個例子來說明GC復制算法的執(zhí)行過程。如圖3.12所示,堆里From空間已經分配滿了部分對象,對象間的引用關系如連線所示,即將開始GC,To空間目前沒有被使用,有個空閑分塊起始指針需要指向空間的開頭,對象復制到了空間放在free指向的位置。

圖3.12 初始狀態(tài)
開始GC后,首先復制的是從根引用的對象B和G,對象B先被復制到To空間,空閑分塊起始指針$free移到B對象之后。B 被復制后生成的對象稱為 B*',原對象B還在From空間,B里保存了指向B’的指針,因為原From空間還有其他對象要通過B找到B’。* 如圖3.13所示。
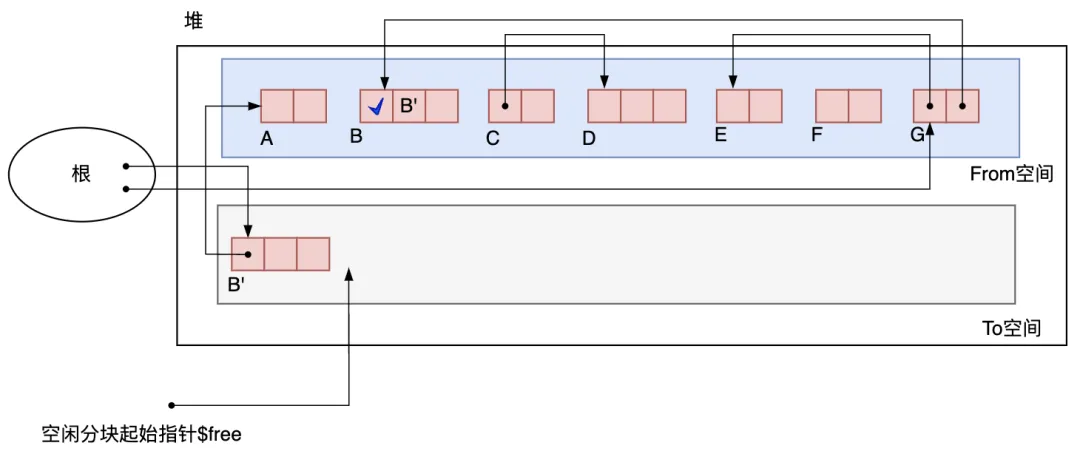
圖3.13 B被復制之后
目前只把 B*'*復制了過來,它的子對象 A 還在 From 空間里。下面要把這個 A 復制到 To 空間里。
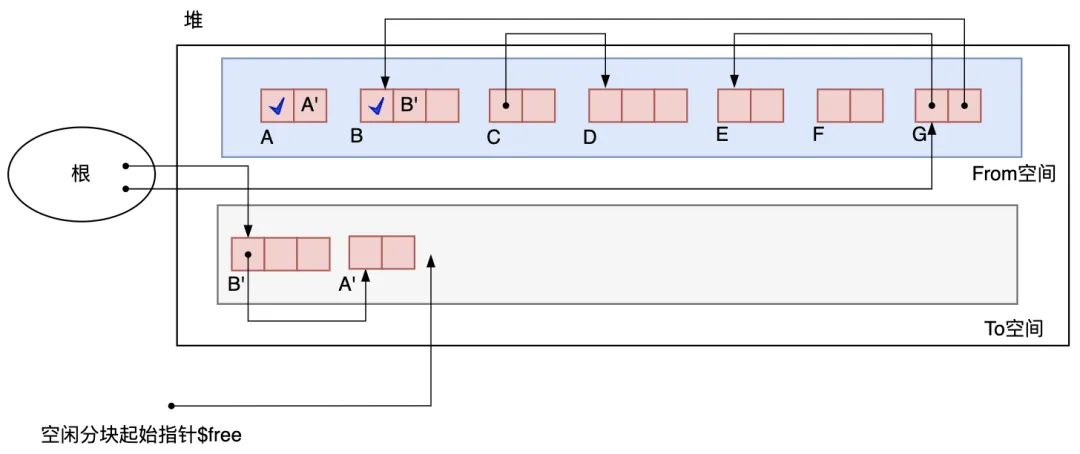
圖3.14 A被復制之后
這次才可以說在真正意義上復制了 B。因為 A 沒有子對象,所以對 A 的復制也就完成了。
接下來,我們要復制和 B 一樣從根引用的 G,以及其子對象 E。雖然 B 也是 G 的子對象, 不過因為已經復制完 B 了,所以只要把從 G 指向 B 的指針換到 B? 上就行了。
最后只要把 From 空間和 To 空間互換,GC 就結束了。GC 結束時堆的狀態(tài)如圖 3.15 所示。
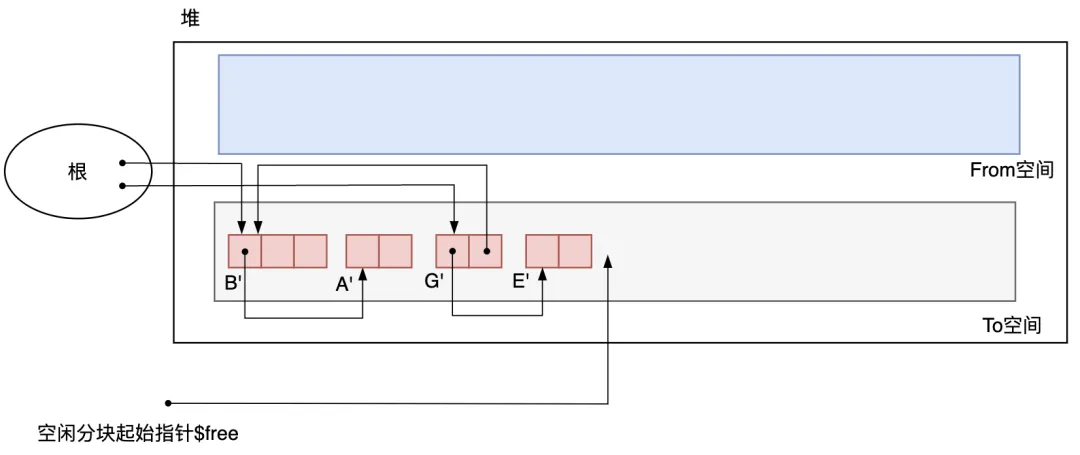
圖3.15 GC結束后
從GC復制算法的執(zhí)行過程可以知道,從根開始搜索對象,采用的是深度優(yōu)先搜索的方式。如圖3.16所示。
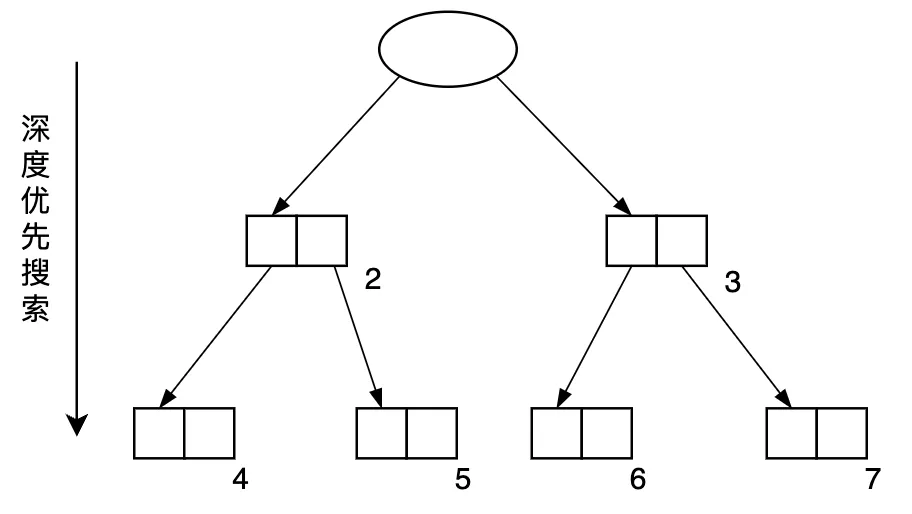
圖3.16 GC復制算法目前查找引用對象使用的是深度優(yōu)先搜索
(3) GC復制算法的優(yōu)點
- 優(yōu)秀的吞吐量。GC 標記-清除算法消耗的吞吐量是搜索活動對象(標記階段)所花費的時間和搜索整體堆(清除階段)所花費的時間之和。因為 GC 復制算法只搜索并復制活動對象,所以跟一般的 GC 標記-清除算法相比,它能在較短時間內完成 GC。也就是說,其吞吐量優(yōu)秀。
- 可實現內存的高速分配。GC 復制算法不使用空閑鏈表。這是因為分塊是一個連續(xù)的內存空間。因此,調查這個分塊的大小,只要這個分塊大小不小于所申請的大小,那么移動空閑分塊的指針就可以進行分配了。
- 不會發(fā)生碎片化。基于算法性質,活動對象被集中安排在 From 空間的開頭。像這樣把對象重新集中,放在堆的一端的行為就叫作壓縮。在 GC 復制算法中,每次運行 GC 時都會執(zhí)行壓縮。因此 GC 復制算法有個非常優(yōu)秀的特點,就是不會發(fā)生碎片化。
- 滿足高速緩存的局部性原理。在 GC 復制算法中有引用關系的對象會被安排在堆里離彼此較近的位置。訪問效率更高。
(4) GC復制算法的缺點
- 堆使用效率低下。GC 復制算法把堆二等分,通常只能利用其中的一半來安排對象。也就是說,只有一半 堆能被使用。相比其他能使用整個堆的 GC 算法而言,可以說這是 GC 復制算法的一個重大的缺陷。
- 不兼容保守式 GC 算法。因為GC復制算法會移動對象到另外的位置,保守式GC算法要求對象的位置不能移動,這在某些情況下有一點的優(yōu)勢。而GC復制算法沒有這種優(yōu)勢。
- 遞歸調用函數。復制某個對象時要遞歸復制它的子對象。因此在每次進行復制的時候都要調用遞歸函數,由此帶來的額外負擔不容忽視。比起這種遞歸算法,迭代算法更能高速地執(zhí)行。此外,因為在每次遞歸調用時都會消耗棧,所以還有棧溢出的可能。
(5) GC復制算法的改進
① 改進一:Cheney 的 GC 復制算法
Cheney的GC復制算法說起來也沒什么復雜的,就是將基本GC的深度優(yōu)先搜索改為廣度優(yōu)先搜索。這樣可以將遞歸復制改為迭代復制。
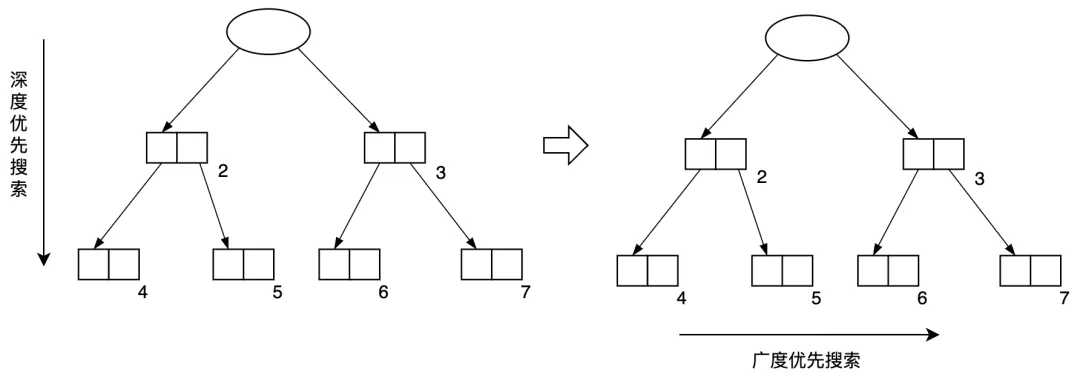
圖3.17 Cheney的GC復制算法將深度優(yōu)先搜索改為廣度優(yōu)先搜索
Cheney的GC復制算法的過程用下面幾張圖來描述。GC開始前的初始狀態(tài)如圖3.18所示。只是在指向To空間開頭的指針多了一個$scan,用來掃描已復制對象的指針,該指針是實現廣度優(yōu)先搜索查找對象的關鍵。
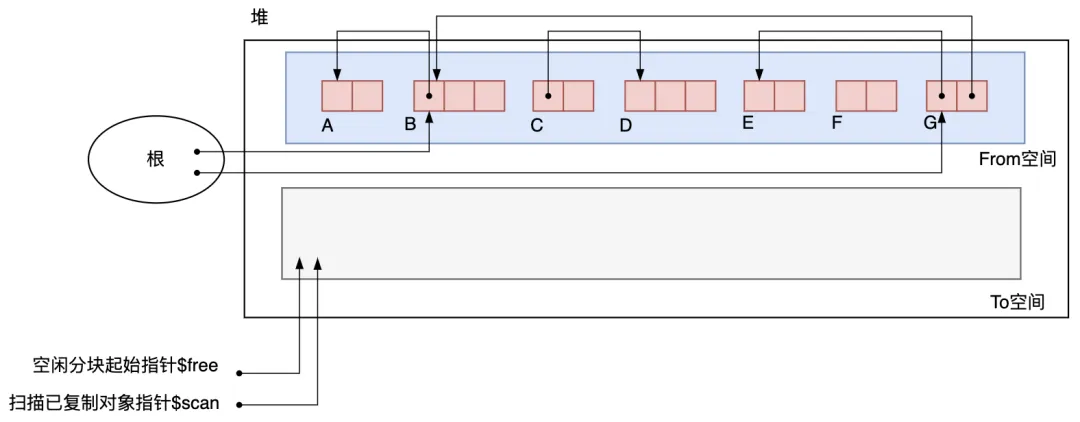
圖3.18 初始狀態(tài)
在 Cheney 的算法中,首先復制所有從根直接引用的對象,在這里就是復制 B 和 G。由于負責對已復制完的對象進行搜索并向右移動指針,free 負責對沒復制的對象進行復制并向右移動指針,此時仍然指著空間的開頭,free 從 To 空間的開頭向右移動了 B 和 G 個長度。如圖3.19所示。
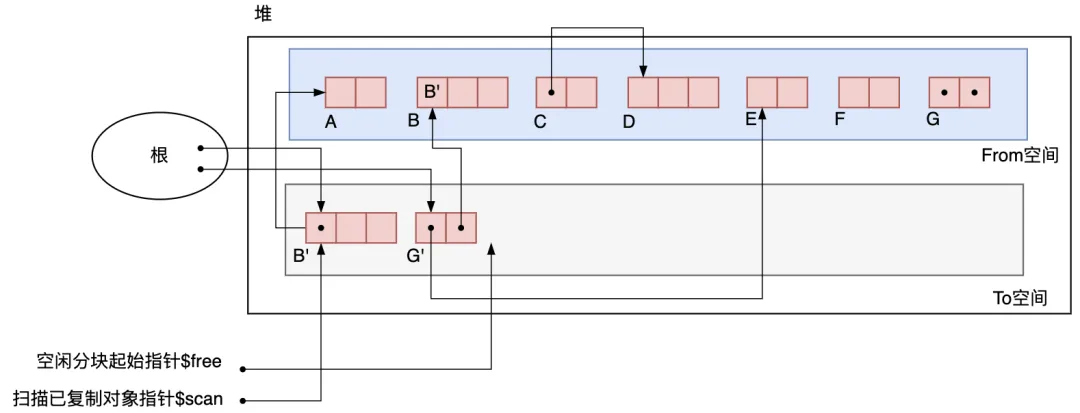
圖3.19 復制B和G之后
由于根引用的兩個對象B、G已經復制完成,接下來移動$scan指針搜索已復制對象B的子對象,然后把被 B? 引用的 A 復制到了 To 空間,同時把 scan 和 $free 分別向右移動了。

圖3.20 搜索 B' 之后
下面該搜索的是 G*'。搜索 G'后,E 被復制到了 To 空間,從 G'* 指向 B 的指針被換到了 B*'*。
下面該搜索 A' 和 E' 了,不過它們都沒有子對象,所以即使搜索了也不能進行復制。因為在 E' 搜索完成時 和free 一致,所以最后只要把 From 空間和 To 空間互換,GC 就結束了。如圖3.21所示。
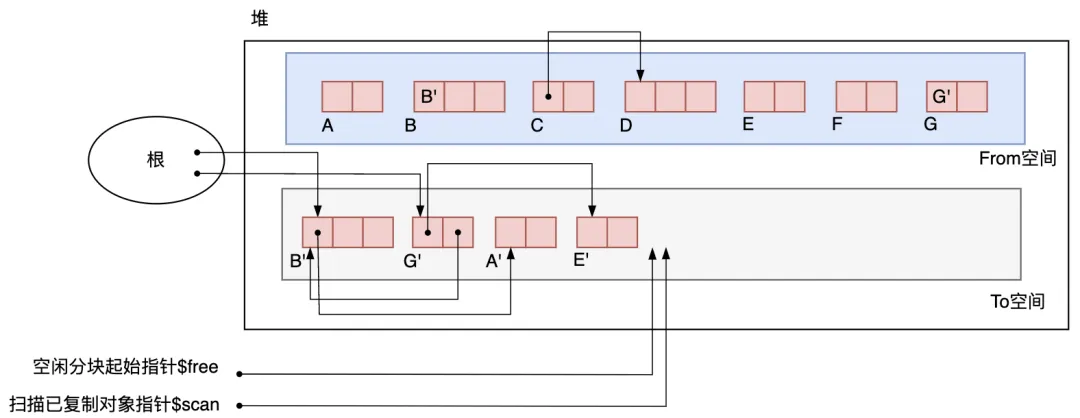
圖3.21 GC 結束后
不用遞歸算法而用迭代算法,可以抑制調用函數的額外負擔和棧的消耗。但是,帶來的缺點是有引用關系的對象在內存中沒有放在一起,沒有利用到高速緩存Cache的局部性原理,在訪問效率上要打個折扣。當然,對這一問題的改進是近似深度優(yōu)先搜索方法,這里就不展開了。
② 改進二:多空間復制算法
GC 復制算法最大的缺點是只能利用半個堆。這是因為該算法將整個堆分成了兩半,每次都要騰出一半。多空間復制算法可以改進GC復制算法“只能利用半個堆”的問題。
多空間復制算法說白了就是把堆 N 等分,對其中 2 塊空間執(zhí)行 GC 復制算法,對剩下的 (N-2)塊空間執(zhí)行 GC 標記-清除算法,也就是把這 2 種算法組合起來使用。
下面用四張圖來說明多空間復制算法的執(zhí)行過程。
首先將堆劃分成四個大小相同的子空間,分別用heap[0],heap[1],heap[2],heap[3]來表示。
第1次執(zhí)行GC之前,是heap[0]作為To空間,heap[1]作為From空間,可以分配活動對象。heap[2]和heap[3]也可以分配對象,不過是采用標記-清除算法,它們的空閑分塊用空閑鏈表鏈接起來。
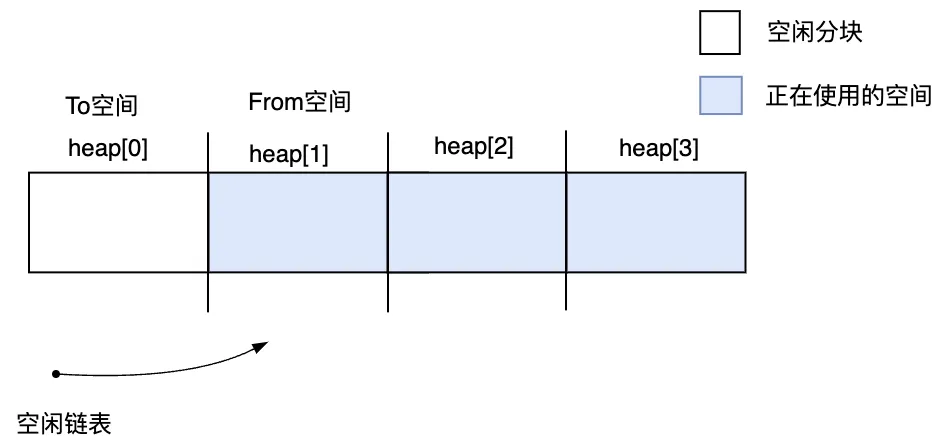
圖3.22 開始執(zhí)行第1次GC之前
第1次GC之后,作為From空間的heap[1]的活動對象復制到了作為To空間的heap[0]中。
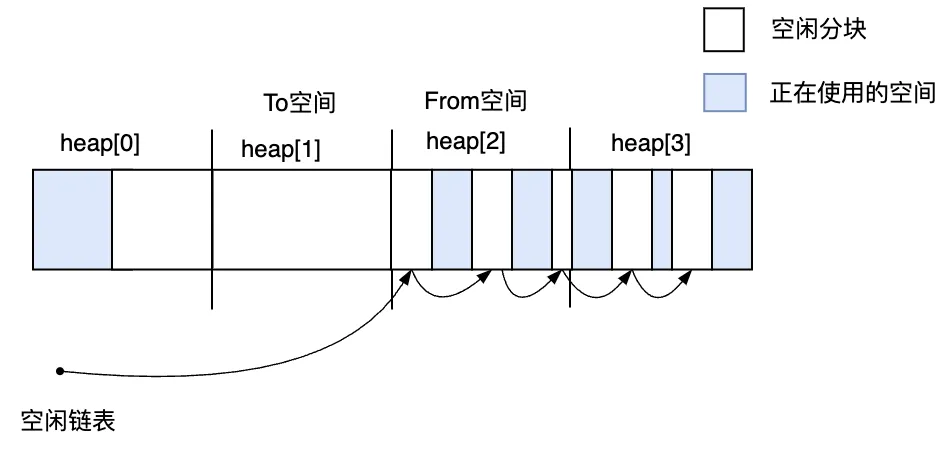
圖3.23 第1次GC結束之后
接下來,將 To 空間和 From 空間分別向右移動一個位置,將 heap[1] 作為 To 空間,將 heap[2] 作為 From 空間。此時,新對象可以分配在作為From空間的heap[2],heap[0]和heap[3]采用標記-清除算法,同樣可以分配新對象。
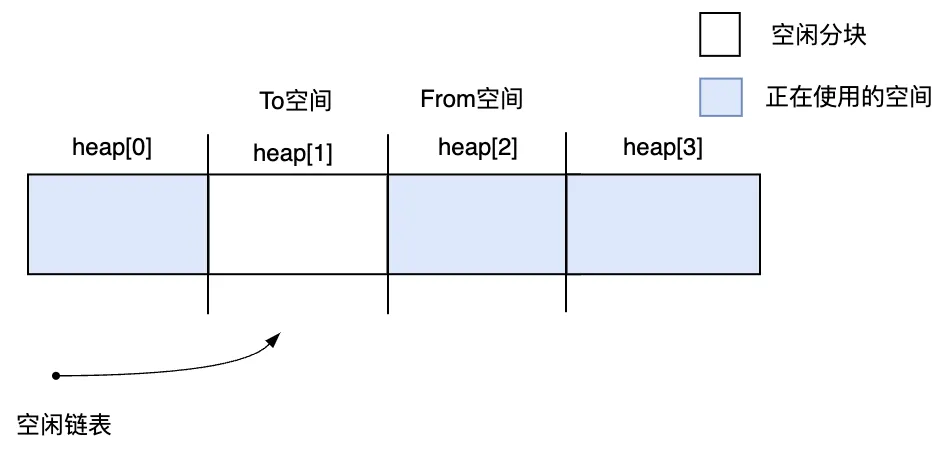
圖3.24 開始執(zhí)行第2次GC之前
如果作為From空間的heap[2],heap[0]和heap[3]三個空間又滿了,需要執(zhí)行第2次GC。此時,會把From空間的活動對象復制到作為To空間的heap[1]中,第2次GC結束之后的堆狀態(tài)如下圖3.25所示。
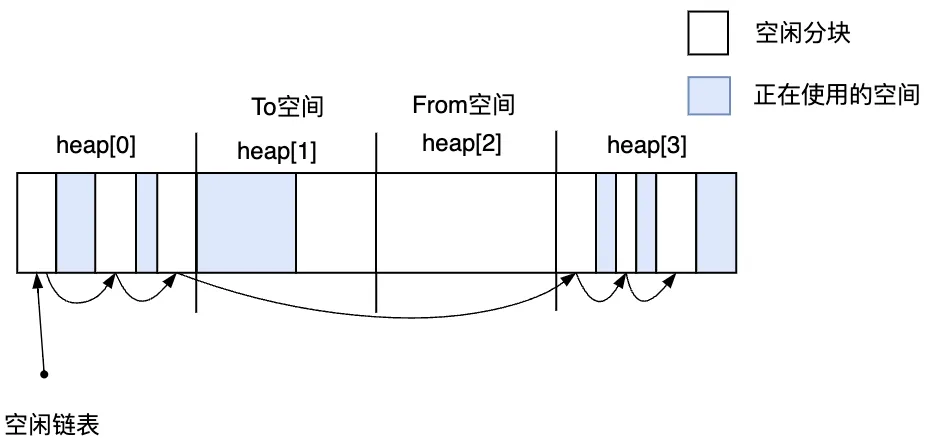
圖3.25 第2次GC結束之后
優(yōu)點:多空間復制算法沒有將堆二等分,而是分割成了更多塊空間,從而更有效地利用了堆。以往的 GC 復制算法只能使用半個堆,而多空間復制算法僅僅需要空出一個分塊,不能使用 的只有 1/N 個堆。
缺點:執(zhí)行 GC 復制算法的只有N等分中的兩塊空間,對于剩下的(N-2)塊空間執(zhí)行的是 GC 標記-清除算法。因此就出現了 GC 標記-清除算法固有的問題——分配耗費時間、分塊碎片化等。只要把執(zhí)行 GC 標記-清除算法的空間縮小,就可以緩解這些問題。打個比方,如果讓N = 3,就能把發(fā)生碎片化的空間控制在整體堆的 1/3。不過這時候為了在剩下的 2/3 的空間里執(zhí)行GC 復制算法,我們就不能使用其中的一半,也就是堆空間的 1/3。
從這里我們可以看到,幾乎不存在沒有缺點的萬能算法。
4. GC標記-壓縮算法
(1) 基本原理
GC 標記-壓縮算法(Mark Compact GC)是將 GC 標記-清除算法與 GC 復制算法相結合的產物。
GC 標記-壓縮算法由標記階段和壓縮階段構成。在 GC 標記-壓縮算法中新空間和原空間是同一個空間。
壓縮階段并不會改變對象的排列順序,只是把對象按順序從堆各處向左移動到堆的開頭。這樣就縮小了它們之間的空隙, 把它們聚集到了堆的一端。
(2) GC標記-壓縮算法的執(zhí)行過程
GC標記-壓縮算法的執(zhí)行過程的簡化版本,如下圖3.26所示。GC開始后,首先是標記階段。搜索根引用的對象及其子對象并打上標記,這里采用深度優(yōu)先搜索。然后將打上標記的活動對象復制到堆的開頭。壓縮階段并不會改變對象的排列順序,只是縮小了它們之間的空隙, 把它們聚集到了堆的一端。
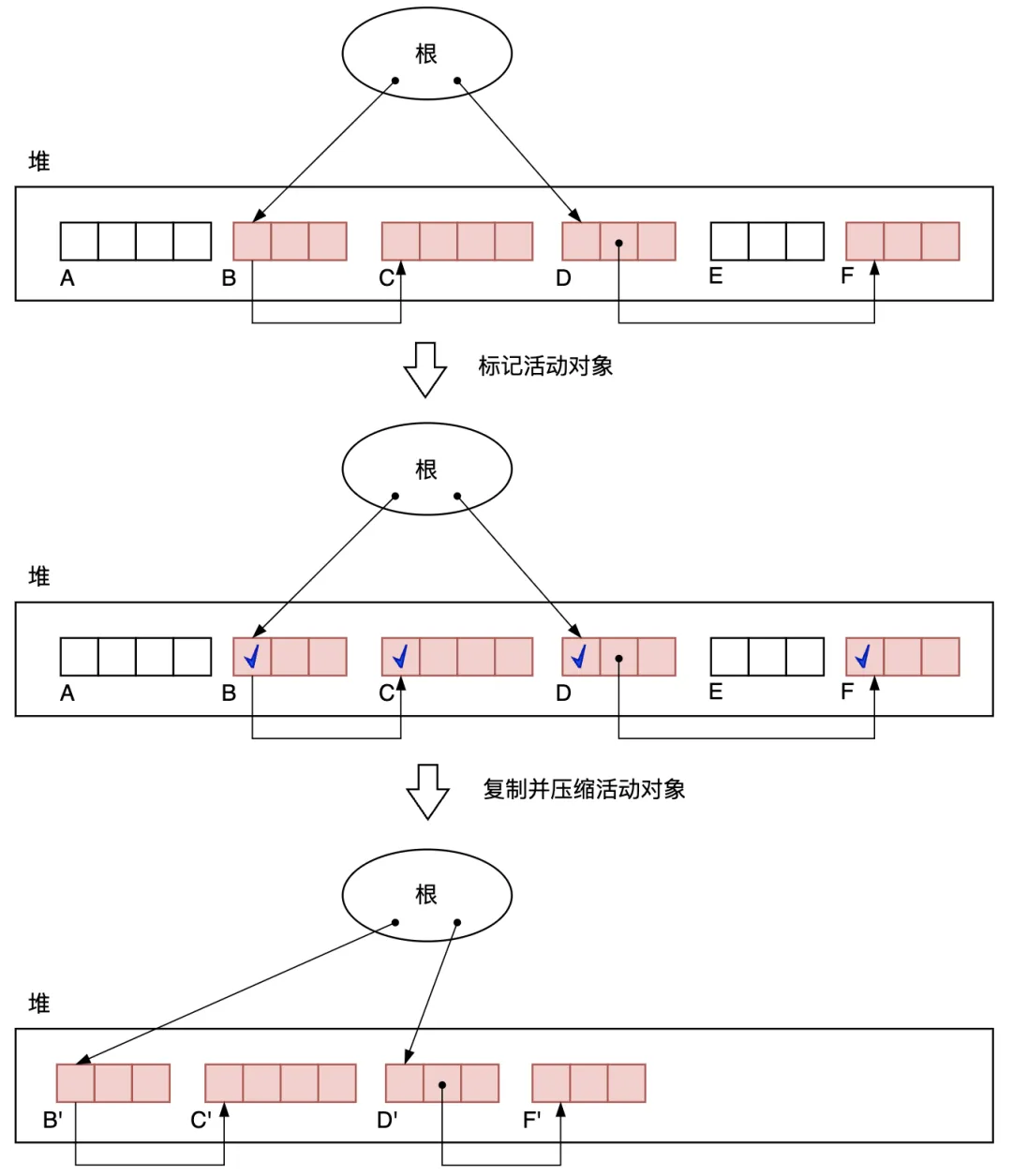
圖3.26 GC標記-復制算法的過程簡化版
這里需要重點說明的是壓縮過程。壓縮過程會通過從頭到尾按順序掃描堆 3 次,第1次是對每個打上標記的對象找到它要移動的位置并記錄在它們各自的成員變量forwarding里,第2次是重寫所有活動對象的指針,將它們指向原位置的指針改為指向壓縮后的對象地址,第3次是搜索整個堆,將活動對象移動到forwarding指針指向的位置完成對象的移動。
下面依次說明。
如圖3.27所示,是第1次順序掃描堆,對每個打上標記的對象,找到它要移動的位置并記錄在它們各自的成員變量forwarding里。
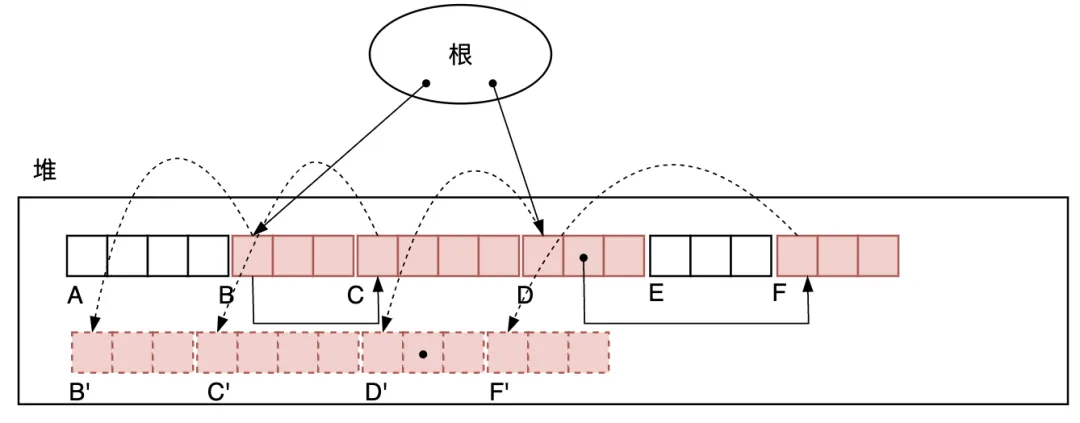
圖3.27 順序掃描堆,對各個活動對象用其forwarding指針記錄其要移動的目標位置
第2次掃描堆,更新重寫所有活動對象的指針,將它們指向原位置的指針改為指向壓縮后的對象地址,如圖3.28所示。
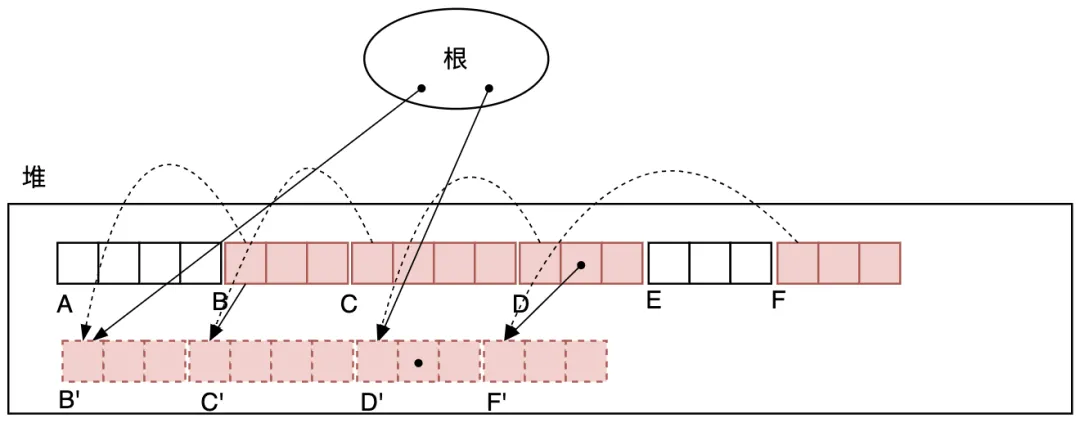
圖3.28 掃描堆,更新重寫所有活動對象的指針
第3次掃描堆,移動活動對象到其目的地址,完成對象的壓縮過程。
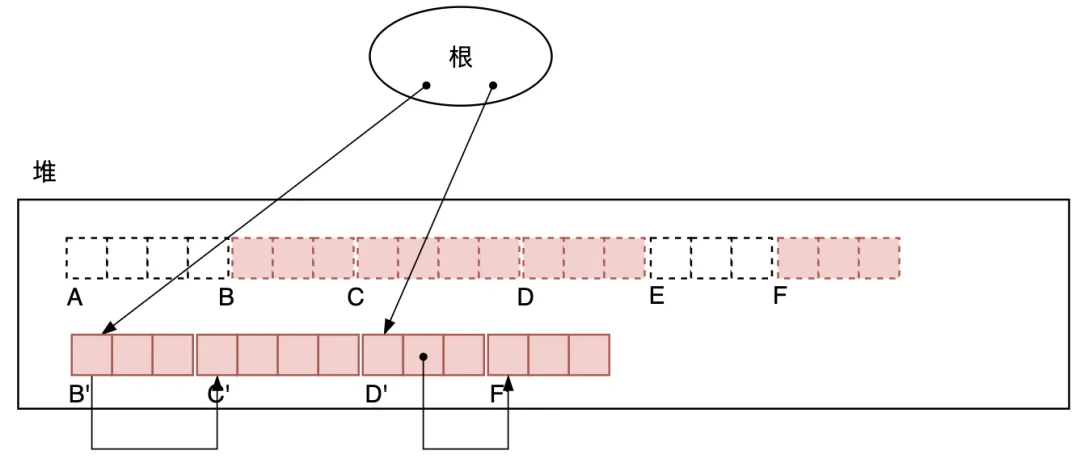
圖3.29 掃描堆,移動活動對象到其目的地址
三次堆掃描完成后,GC整個過程結束。GC結束狀態(tài)如圖3.30所示。
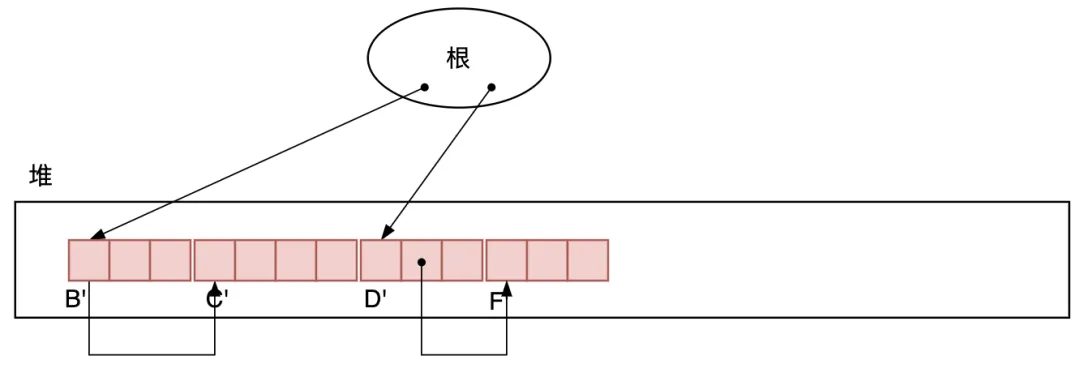
圖3.30 GC結束
(3) GC標記-壓縮算法的優(yōu)點
- 可有效利用堆。GC 標記-壓縮算法和其他算法相比而言,堆利用效率高。GC 標記-壓縮算法不會出現 GC 復制算法那樣只能利用半個堆的情況。GC 標記-壓縮算法可以在整個堆中安排對象,堆使用效率幾乎是 GC 復制算法的 2 倍。
- 沒有GC標記-清除法所帶來的碎片化問題。
(4) GC標記-壓縮算法的缺點
- 壓縮花費計算成本。壓縮有著巨大的好處,但也有相應的代價。必須對整個堆進行 3 次搜索。執(zhí)行該算法所花費的時間是和堆大小成正比的。
- GC 標記-壓縮算法的吞吐量要劣于其他算法。
(5) GC標記-壓縮算法的改進
① 改進一:減少堆搜索次數的Two-Finger二指算法
Two-Finger 算法有著很大的制約條件,那就是“必須將所有對象整理成大小一致”。
在基本的GC標記-壓縮算法中,通過執(zhí)行壓縮操作使活動對象往左邊滑動。而在 Two-Finger 算法中,是通過執(zhí)行壓縮操作來讓活動對象填補空閑空間。此時為了讓對象能恰好填補空閑空間, 必須讓所有對象大小一致。
Two-Finger二指算法中對象的移動過程,如下圖3.31所示。主要用到了兩個指針,空閑分塊指針和活動對象指針live,前者從左往右找,后者從右往左找。當找到了空閑分塊,live找到了活動對象,則將活動對象移動到空閑分塊$free的位置,實現對象的移動。
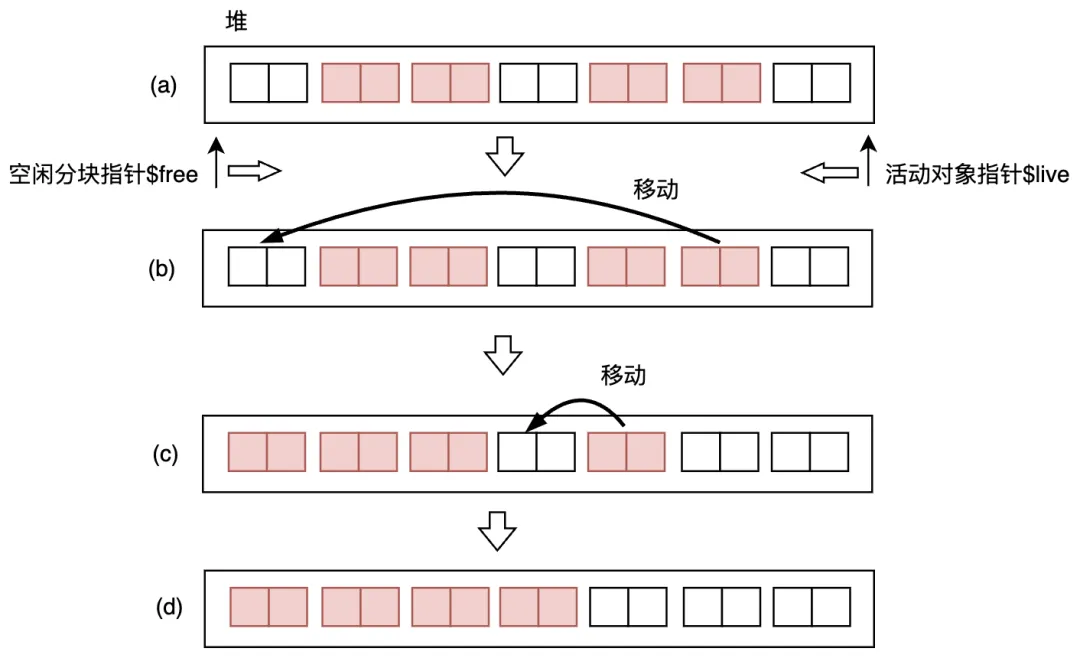
圖3.31 Two-Finger二指算法中對象的移動
- 優(yōu)點:Two-Finger二指算法,壓縮需要的搜索次數只有 2 次,在吞吐量方面占優(yōu)勢。
- 缺點:壓縮移動對象時沒有考慮把有引用關系的對象放在一起,無法利用高速緩存基于局部性原理提升訪存效率。該算法還有一個限制條件,那就是所有對象的大小必須一致,導致應用受限。不過和第3.1節(jié)介紹的要求“將大小相近的對象整理成固定大小的塊進行管理的做法”的BiBOP算法結合起來使用,會起到珠聯璧合的效果。
5. 保守式GC
(1) 什么是保守式GC
保守式 GC(Conservative GC)指的是“不能識別指針和非指針的 GC”。
如下圖所示,在C/C++等高級語言的早期GC程序里,如果寄存器、函數調用棧或全局變量空間等這些根空間里有一個數值型的變量0x00d0caf0和一個指針的地址是相同的值0x00d0caf0,則程序無法識別這個值到底是數值變量還是指針。
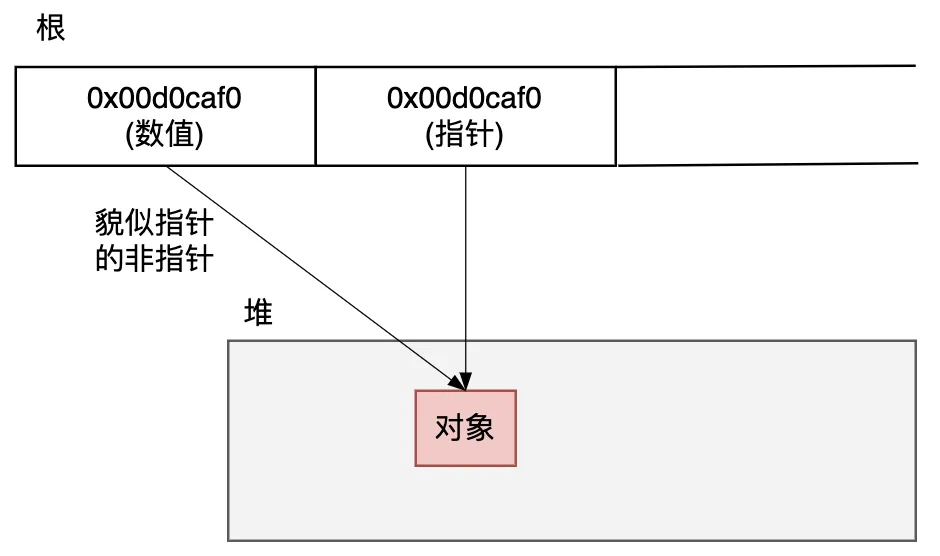
圖3.32 貌似指針的非指針
對于貌似指針的非指針,為了避免錯誤回收導致程序故障,采取“寧可放過,不可殺錯”的寬容原則,把它們當做活動對象而保留下來,像這樣,在運行 GC 時采取的是一種保守的態(tài)度,即“把可疑的東西看作指針,穩(wěn)妥處理”,所以我們稱這種方法為“保守式 GC ”。
保守式GC的特點是盡量不移動對象的位置,因為容易把非指針重寫從而產生意想不到的BUG。
當然,大部分高級程序語言如Java、Golang在語言設計之初就是強類型語言,不存在無法識別變量和指針的問題,它們采用的就是跟保守式GC相對應的準確式GC。
(2) 保守式GC的優(yōu)點
容易編寫語言處理程序(語言處理程序是指將源程序轉換成機器語言、以便計算機能夠運行的匯編程序、編譯程序和解釋程序)。處理程序基本上不用在意 GC 就可以編寫代碼。語言處理程序的實現者即使沒有意識到 GC 的存在,程序也會自己回收垃圾。因此語言處理程序的實現要比準確式 GC 簡單。
(3) 保守式GC的缺點
- 識別指針和非指針需要付出成本。在跟空間里,變量和指針的值相同的情況下,程序需要額外通過是否內存對齊、是否指向堆內對象的開頭等手段來判斷指針和非指針,成本較高。
- 錯誤識別指針會壓迫堆。當存在貌似指針的非指針時,保守式 GC 會把被引用的對象錯誤識別為活動對象。如果這個對象存在大量的子對象,那么它們一律都會被看成活動對象。這樣容易留下較多的垃圾對象,從而會嚴重壓迫堆。
- 能夠使用的 GC 算法有限。由于保守式GC的特點是盡量不移動對象的位置,因為容易把非指針重寫從而產生意想不到的BUG。所以基本上不能使用 GC 復制算法等移動對象的 GC 算法。
(4) 保守式GC的改進
① 改進一:準確式GC
準確式 GC(Exact GC)和保守式 GC 正好相反,它是能正確識別指針和非指針的 GC。
要能精確地識別指針和非指針,需要依賴程序語言設計之初的語言處理程序的支持。
大部分高級程序語言如Java、Golang,在語言設計之初就是強類型語言,不存在無法識別變量和指針的問題,它們采用的就是跟保守式GC相對應的準確式GC。
- 優(yōu)點:不會錯誤識別指針,不會將已經死了的對象識別為活動對象,因此GC回收垃圾會比較徹底。還可以使用GC復制算法等需要移動對象的算法,提高GC的吞吐量和效率。
- 缺點:當創(chuàng)建準確式 GC 時,語言處理程序(語言處理程序是指將源程序轉換成機器語言、以便計算機能夠運行的匯編程序、編譯程序和解釋程序)必須對 GC 進行一些支援。也就是說,在創(chuàng)建語言處理程序時必須顧及 GC。增加了語言處理程序的實現復雜度。
② 改進二:間接引用
保守式 GC 有個缺點,就是“不能使用 GC 復制算法等移動對象的算法”。解決這個問題的方法之一就是“間接引用”。
根和對象之間通過句柄連接。每個對象都有一個句柄,它們分別持有指向這些對象的指針。并且局部變量和全局變量沒有指向對象的指針,只裝著指向句柄的指針。當應用程序操作對象時,要通過經由句柄的間接引用來執(zhí)行。
只要采用了間接引用,那么即使移動了引用目標的對象,也不用改寫關鍵的值——根里面的值,改寫句柄里的指針就可以了。也就是說,我們只要采用間接引用來處理對象, 就可以移動對象。如下圖所示,在復制完對象之后,根的值并沒有重寫。
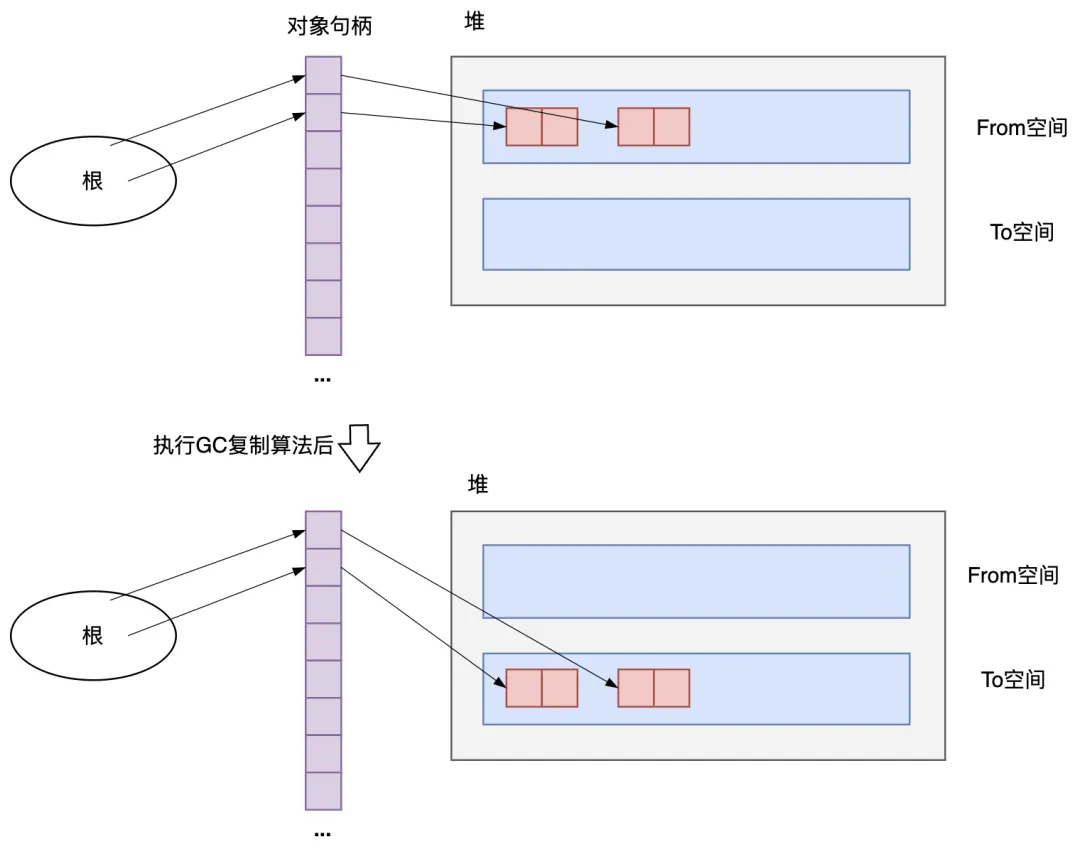
圖3.33 根到對象通過句柄間接引用
- 優(yōu)點:因為在使用間接引用的情況下有可能實現 GC 復制算法,所以可以得到 GC 復制算法所帶來的好處,例如消除碎片化等。
- 缺點:因為必須將所有對象都(經由句柄)間接引用,所以會降低訪問對象內數據的速度,這會關系到整個語言處理程序的速度。
③ 改進三:MostlyCopyingGC大部分復制算法
MostlyCopyingGC 就是“把那些不明確的根指向的對象以外的對象都復制的 GC 算法”。Mostly 是“大部分”的意思。說白了,MostlyCopyingGC 就是拋開那些不能移動的對象,將其他“大部分”的對象都進行復制的 GC 算法。這里不展開細說了。
6. 分代垃圾回收
程序應用中的一個經驗:大部分的對象在生成后馬上就變成了垃圾, 很少有對象能活得很久。
分代垃圾回收(Generational GC),利用了該經驗,在對象中導入了“年齡”的概念,經歷過一次 GC 后活下來的對象年齡為 1 歲。
(1) 新生代對象和老年代對象
分代垃圾回收中把對象分類成幾代,針對不同的代使用不同的 GC 算法,我們把剛生成的對象稱為新生代對象,到達一定年齡的對象則稱為老年代對象。
由于新生代對象大部分會變成垃圾,如果應用程序只對這些新生代對象執(zhí)行 GC,除了引用計數法以外的基本算法,都會進行只尋找活動對象的操作,如 GC 標記-清除算法的標記階段和 GC 復制算法等。因此,如果很多對象都會死去,花費在 GC 上的時間應該就能減少。
我們將對新對象執(zhí)行的 GC 稱為新生代 GC(minor GC)。minor 在這里的意思是“小規(guī)模的”。新生代 GC 的前提是大部分新生代對象都沒存活下來,GC 在短時間內就結束了。
另一方面,新生代 GC 將存活了一定次數的新生代對象當作老年代對象來處理。新生代對象上升為老年代對象的情況稱為晉升(promotion)。
因為老年代對象很難成為垃圾,所以我們對老年代對象減少執(zhí)行 GC 的頻率。相對于新生代 GC,將面向老年代對象的 GC 稱為老年代 GC(major GC)。
需要注意的是,分代垃圾回收不是跟 GC 標記-清除算法和 GC 復制算法并列在一起供開發(fā)人員選擇的算法,而是需要跟這些基本算法一并使用。比如新生代GC使用GC復制算法,而老年代GC由于頻率較低、可以使用最簡單的GC標記-清除算法。
(2) 分代垃圾回收的基本原理
分代垃圾回收算法把對分成了四個空間,分別是生成空間、2 個大小相等的幸存空間以及老年代空間。新生代對象會被分配到新生代空間,老年代對象則會被分配到老年代空間里。

圖3.34 分代垃圾回收的堆空間
應用程序創(chuàng)建的新對象一般會放到新生代空間里,當生成空間滿了的時候,新生代 GC 就會啟動,將生成空間中的所有活動對象復制,這跟 GC 復制算法是一個道理,復制的目標空間是幸存空間。
2 個幸存空間和 GC 復制算法里的 From 空間、To 空間很像,我們經常只利用其中的一個。在每次執(zhí)行新生代 GC 的時候,活動對象就會被復制到另一個幸存空間里。在此我們將正在使用的幸存空間作為 From 幸存空間,將沒有使用的幸存空間作為 To 幸存空間。
新生代 GC 也必須復制生成空間里的對象。也就是說,生成空間和 From 幸存空間這兩個空間里的活動對象都會被復制到 To 幸存空間里去——這就是新生代 GC。
只有從一定次數的新生代 GC 中存活下來的對象才會得到晉升,也就是會被復制到老年代空間去。
在執(zhí)行新生代 GC 時需要注意,需要考慮到從老年代空間到新生代空間的引用。新生代對象不只會被根和新生代空間引用,也可能被老年代對象引用。因此,除了一般 GC 里的根,還需要將從老年代空間的引用當作根(像根一樣的東西)來處理。
這里,使用記錄集用來記錄從老年代對象到新生代對象的引用。這樣在新生代 GC 時就可以不搜索老年代空間的所有對象,只通過搜索記錄集來發(fā)現從老年代對象到新生代對象的引用。
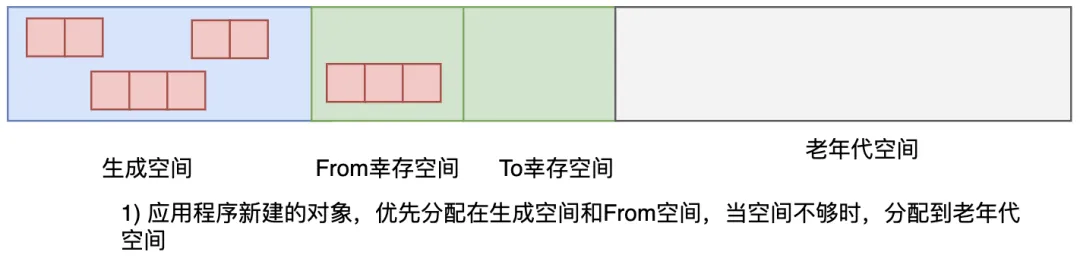
圖3.35 新對象分配在生成空間和From空間

圖3.36 MinorGC啟動,將活動對象復制到To空間
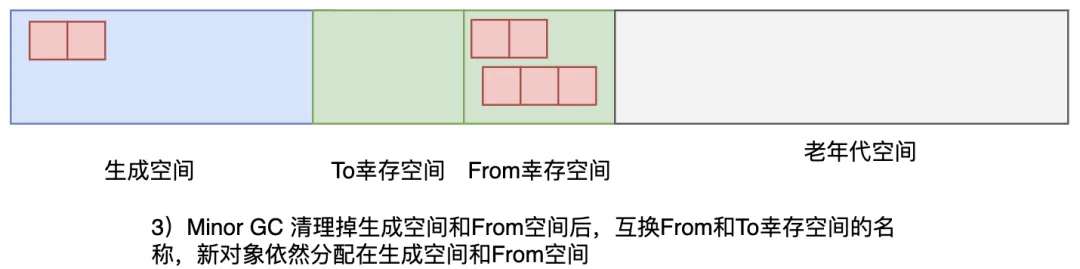
圖3.37 MinorGC清理完成后,互換From空間到To空間
通過新生代 GC 得到晉升的對象把老年代空間占滿后,就要執(zhí)行老年代 GC 了。老年代 GC 沒什么難的地方,它只用到了3.1節(jié)的 GC 標記-清除算法。
(3) 分代垃圾回收的優(yōu)點
“很多對象年紀輕輕就會死”這一經驗適合大多數情況,新生代 GC 只將剛生成的對象當成對象,這樣一來就能減少時間上的消耗。分代垃圾回收可以改善 GC 所花費的時間(吞吐量)。“據實驗表明,分代垃圾回收花費的時間是 GC 復制算法的 1/4。”
(4) 分代垃圾回收的缺點
“很多對象年紀輕輕就會死”這個法則畢竟只適合大多數情況,并不適用于所有程序。對對象會活得很久的程序執(zhí)行分代垃圾回收,就會產生以下兩個問題:
- 新生代GC所花費的時間增多
- 老年代GC頻繁運行
(5) 分代垃圾回收的改進
① 改進一:多代垃圾回收
分代垃圾回收將對象分為新生代和老年代,通過盡量減少從新生代晉升到老年代的對象, 來減少在老年代對象上消耗的垃圾回收的時間。
基于這個理論,大家可能會想到分為 3 代或 4 代豈不更好?這樣一來能晉升到最老一代的對象不就更少了嗎?這種方法就叫作多代垃圾回收(Multi-generational GC)。
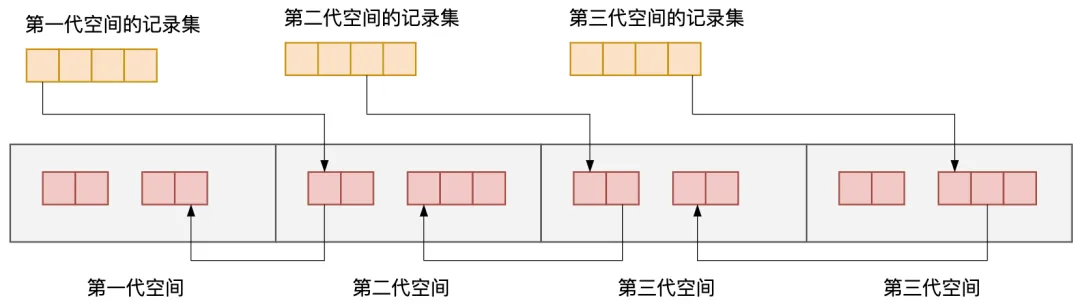
圖3.38 4代垃圾回收的堆空間
在這個方法中,除了最老的那一代之外,每代都有一個記錄集。X 代的記錄集只記錄來自比 X 老的其他代的引用。
分代數量越多,對象變成垃圾的機會也就越大,所以這個方法確實能減少活到最老代的對象。
但是我們也不能過度增加分代數量。分代數量越多,每代的空間也就相應地變小了,這樣一來各代之間的引用就變多了,各代中垃圾回收花費的時間也就越來越長了。
綜合來看,少設置一些分代能得到更優(yōu)秀的吞吐量,據說分為 2 代或者 3 代是最好的。
7. 增量式垃圾回收
增量式垃圾回收(Incremental GC)是一種通過逐漸推進垃圾回收來控制應用程序最大暫停時間的方法。
增量(incremental)這個詞有“慢慢發(fā)生變化” 的意思。就如它的名字一樣, 增量式垃圾回收是將 GC 和應用程序一點點交替運行的手法。增量式垃圾回收的示意圖如圖 3.39 所示。
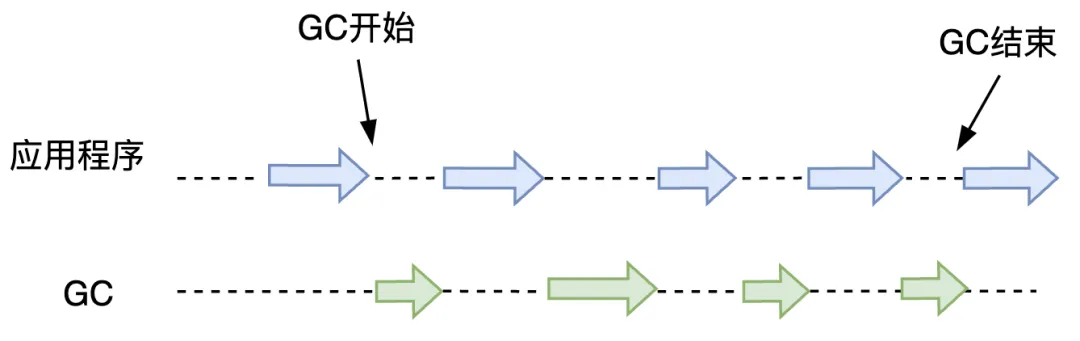
圖3.39 增量式垃圾回收示意圖
增量式垃圾回收也叫三色標記法(Tri-color marking)。本文中,增量式垃圾回收=三色標記法。
(1) 三色標記法
三色標記法是將對象根據搜索情況,分為三種顏色:
- 白色:還未搜索過的對象
- 灰色:正在搜索的對象
- 黑色:搜索完成的對象
GC 開始運行前所有的對象都是白色。GC 一開始運行,所有從根能到達的對象都會被標記,然后被堆到棧里。GC 只是發(fā)現了這樣的對象,但還沒有搜索完它們,所以這些對象就成了灰色對象。
灰色對象會被依次從棧中取出,其子對象也會被涂成灰色。當其所有的子對象都被涂成灰色時,對象就會被涂成黑色。
當 GC 結束時已經不存在灰色對象了,活動對象全部為黑色,垃圾則為白色。
這就是三色標記算法的概念。
三色標記法和GC標記-清除算法結合起來增量式執(zhí)行,就是我們本節(jié)要說的增量式垃圾回收,或叫增量式標記-清除算法。
增量式的 GC 標記-清除算法(三色標記法)可分為以下三個階段:
- 根查找階段
- 標記階段
- 清除階段
這本書的三色標記法解釋的并不清楚,下面我結合Golang的三色標記實現來說明具體過程。
①根查找階段
在根查找階段中,GC程序將直接從根引用的對象打上灰色標記,放到灰色隊列里,將Root根對象本身標記為黑色對象。根查找階段只在 GC 開始時運行一次。如下圖所示。
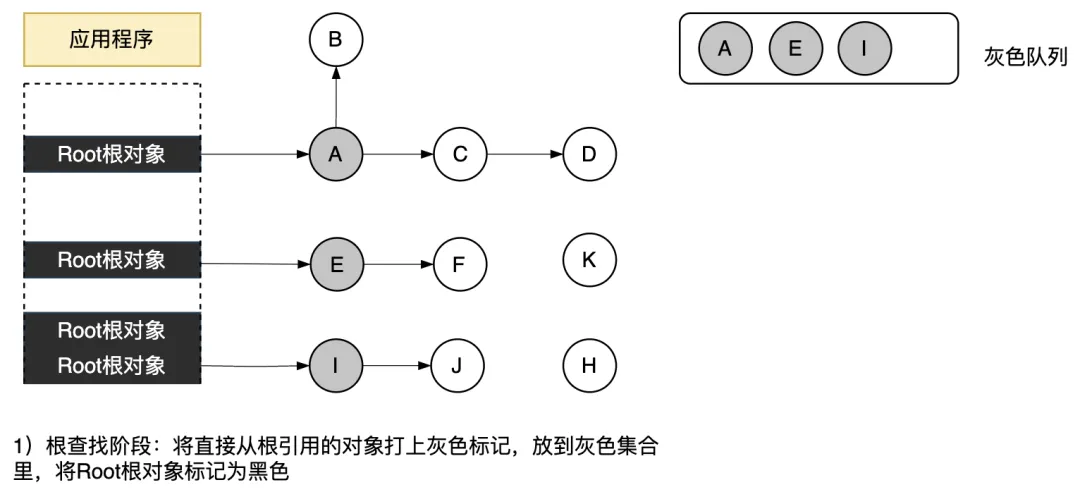
圖3.40 根查找階段
② 標記階段
從灰色隊列里取出對象,將其子對象涂成灰色,將該灰色對象本身標記為黑色。將這一系列操作執(zhí)行 X 次,在這里“X 次”是重點,不是一次處理所有的灰色對象,而是只處理一定個數,然后暫停 GC,再次開始執(zhí)行應用程序。這樣一來,就能縮短應用程序的最大暫停時間。
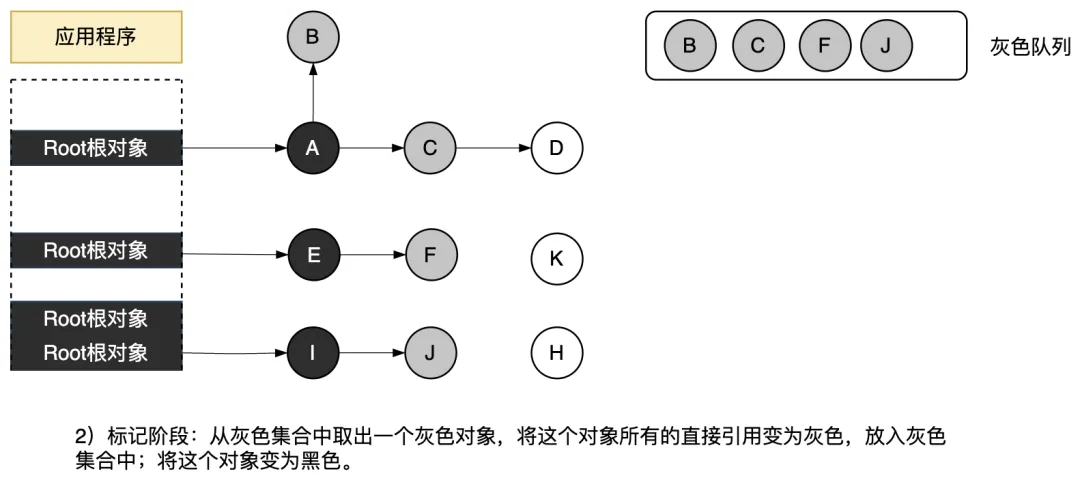
圖3.41 標記階段
將灰色隊列里的所有灰色對象,通過多次搜索階段、搜索并標記為黑色,完成后,意味著標記結束。標記結束時,灰色隊列為空,所有灰色對象都成了黑色。這里,黑色對象意味著活動對象,白色對象意味著空閑對象,白色對象等待著在清除階段被GC回收,也就是掛載到空閑鏈表上以供后面新對象分配使用。
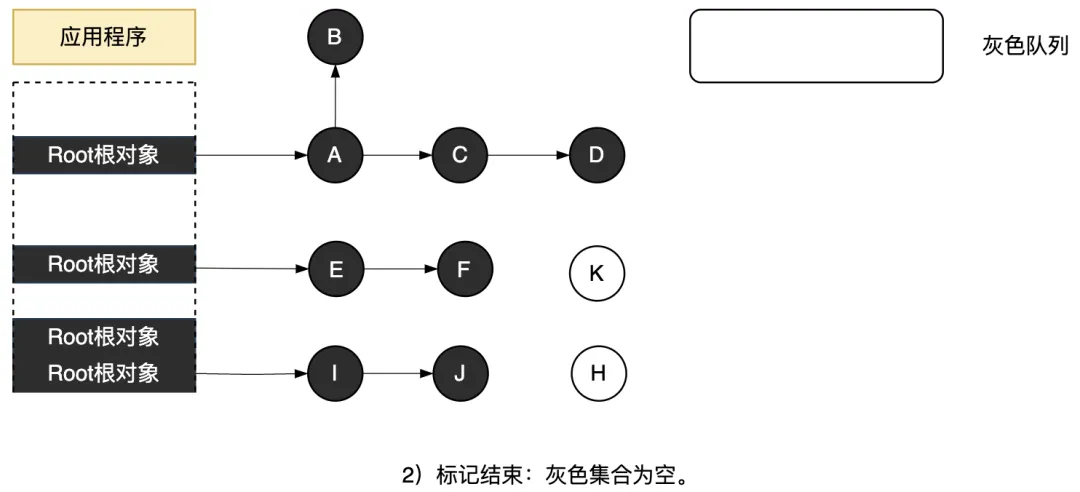
圖3.42 標記結束
③ 清除階段
在清除階段,將黑色對象視為活動對象并保留,將白色對象掛載到空閑鏈表以清除,便于后面新對象分配時使用。
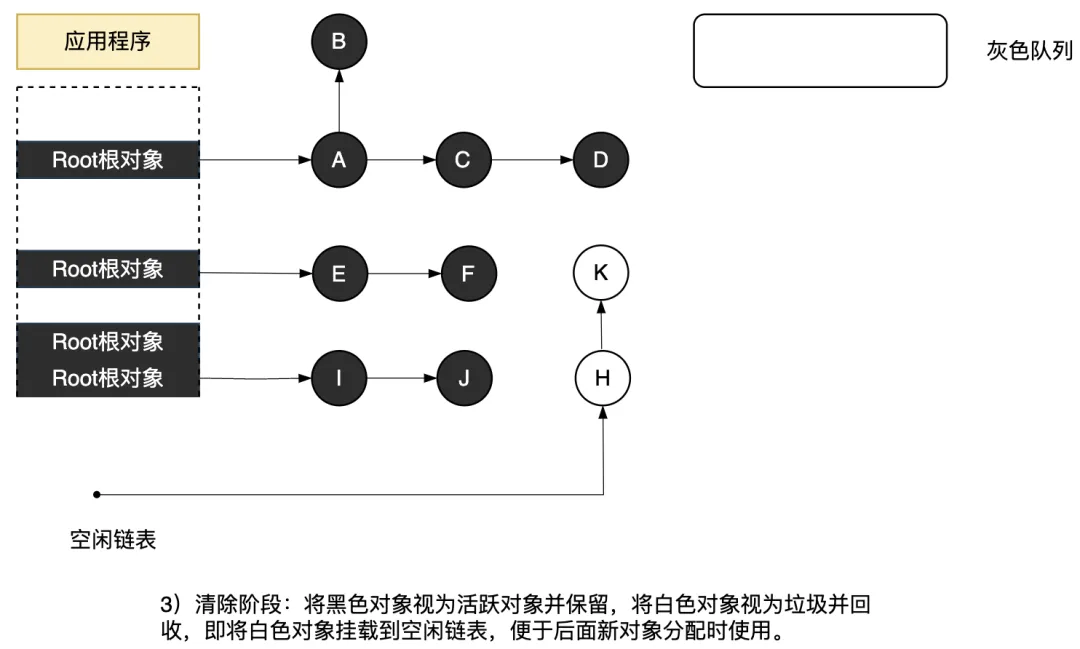
圖3.43 清除階段
三色標記清除算法本身是不可以并發(fā)或者增量執(zhí)行的,它需要STW暫停應用程序,而如果并發(fā)執(zhí)行,用戶程序可能在標記執(zhí)行的過程中修改對象的指針,容易把原本應該垃圾回收的死亡對象錯誤的標記為存活,或者把原本存活的對象錯誤的標記為已死亡,下面以后一種情況舉例說明。
如下圖所示。在一輪標記暫停的狀態(tài)是:A 被涂成黑色,B 被涂成灰色進入灰色隊列。所以下一輪標記,就要對 B 進行搜索了。如果在這兩次標記之間,應用程序把從 A 指向 B 的引用更新為從 A 指向 C 之后的狀態(tài),然后再刪除從 B 指向 C 的引用,如下圖c)所示。這個時候如果重新開始標記, B 原本是灰色對象,經過搜索后被涂成了黑色。然而盡管 C 是活動對象,程序卻不會對它進行搜索。這是因為已經搜索完有唯一指向 C 的引用的 A 了。
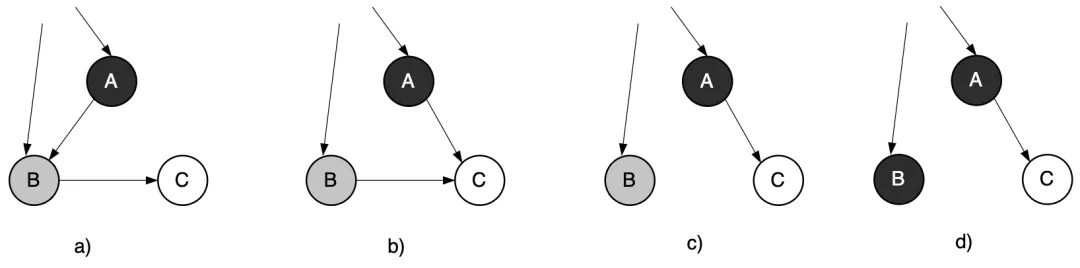
圖3.44 沒有STW時活動對象的標記遺漏
為了防止這種現象的發(fā)生,最簡單的方式就是STW,直接禁止掉其他用戶程序對對象引用關系的干擾,但是STW的過程有明顯的資源浪費,對所有的用戶程序都有很大影響。那么是否可以在保證對象不丟失的情況下合理的盡可能的提高GC效率,減少STW時間呢?答案是可以的,就是屏障機制。
(2) 寫入屏障
寫入屏障的具體操作是:在 A 對象引用 C 對象的時候,C 對象被標記為灰色。(將 C 掛在黑色對象A的下游,C 必須被標記為灰色)
這一操作滿足:不存在黑色對象引用白色對象的情況了, 因為白色會強制變成灰色。
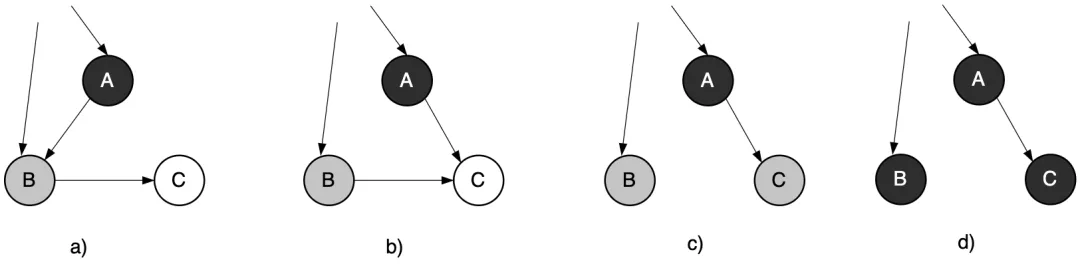
圖3.45 白色對象被引用時強制被標記為灰色
(3) 增量式垃圾回收的優(yōu)點
- 增量式垃圾回收不是一口氣運行 GC,而是和應用程序交替運行的,因此不會長時間妨礙到應用程序的運行。
- 增量式垃圾回收適合那些比起提高吞吐量,更重視縮短最大暫停時間的應用程序。
(4) 增量式垃圾回收的缺點
用到了寫入屏障,就會增加額外負擔。既然有縮短最大暫停時間的優(yōu)勢,吞吐量也一般。
(5) 增量式垃圾回收的改進
① 改進一:Steele的寫入屏障
具體操作:在標記過程中發(fā)出引用的對象是黑色對象,且新的引用的目標對象為灰色或白色,那么我們就把發(fā)出引用的對象涂成灰色。如下圖所示,A 原本為黑色,引用白色的 C,這時,A 需要回退到灰色。

圖3.46 黑色對象引用白色時,自身由黑變灰
Steele 的寫入屏障相比上文的寫入屏障來說,標記對象的條件要嚴格一些, 相應地寫入屏障帶來的額外負擔會增大。但是可以減少被標記的對象,從而防止了因疏忽而造成垃圾殘留的后果。
② 改進二:刪除屏障
具體操作: 被刪除的對象,如果自身為灰色或者白色,那么被標記為灰色。如下圖所示,C 被 B 刪除時,C 本身為白色,所以需要被標記為灰色。

圖3.47 對象被刪除時,如果自身為灰或白,標記為灰色
這種方式實現相對簡單,但是回收精度低,一個對象即使被刪除了最后一個指向它的指針也依舊可以活過這一輪,在下一輪GC中才會被清理掉。
還有很多提高標記效率又能避免誤刪或遺留對象的屏障機制,比如混合寫屏障,這里就不多討論了。
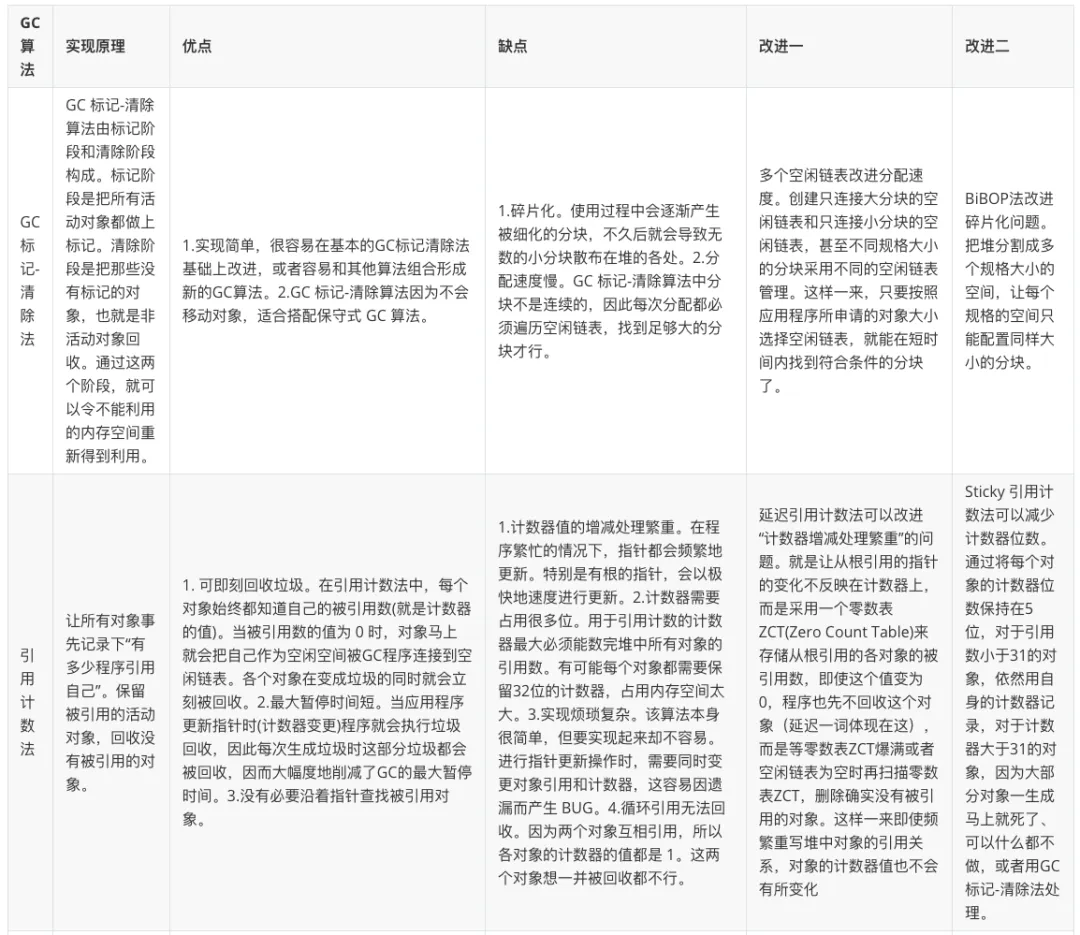
四、七種GC算法的對比分析


五、總結
內存其實就是一塊連續(xù)的空間,可以看做一個大數組,這塊空間在業(yè)務運行時,經常會或零散或整齊的分布一些大大小小的對象,怎么樣高效的分配和回收這塊空間,同時盡量不影響業(yè)務系統的運行,就是GC垃圾回收要做的事,學習了七種基本的GC算法之后,我們更加知道,工程技術中沒有“銀彈”,沒有完美無缺的算法,只有最適合自己業(yè)務系統的解法。
本文的重要性在于:我們在具體的工程實踐中,經常會遇到各種問題場景,每種場景都會遇到各種方案選型,各個不同方案的側重點是什么、有什么缺點、缺點怎樣改進,到底哪種方案是當前業(yè)務場景需要的,基于什么方面進行考慮選取某種方案,這些問題和疑惑,在思考并學習七種基本的GC算法的過程中,會得到很多啟發(fā)和收獲。
























