計算機體系結構的一知半解
計算機的體系結構是關于計算機自身的系統架構,而軟件指令集架構在計算機體系結構中處于核心地位,因為軟件和硬件之間都是通過軟件指令集架構(ISA)來對話的。
例如,在20世紀60年代早期,IBM 有四個不兼容的計算機系列,面向小企業、大企業、科學和實時處理的市場細分,每個系列都有自己的 ISA、軟件棧和 I/O 系統。能否創建一個單一的 ISA來有效地統一起來呢?數據路徑是處理器的“肌肉”,執行算術運算,相對容易拓展,最大挑戰是處理器的擴展。受到軟件編程的啟發,莫里斯 · 威爾克斯提出了簡化控制的方法。控制器被指定為一個二維數組,稱之為“控制存儲區”,數組的每一列對應一條控制線,每一行對應一條微指令,寫微指令的過程稱為微程序設計。控制存儲器是通過內存實現的,這比邏輯門的成本要低得多。在微程序設計的幫助下,IBM 新的 ISA 徹底改變計算機行業,并主導了它的市場,以至于幾十年前的大型機家族現在仍然每年帶來百億美元以上的收入。
這是架構創新的成功,也往往需要大量的工程投資。
從集成電路到8086
當計算機開始使用集成電路時,摩爾定律意味著控制存儲可能會變得更大,反過來允許更復雜的 ISA。微處理器在20世紀70年代仍然處于8位時代(如英特爾8080) ,主要用匯編語言編程,競爭對手通過匯編語言的例子來展示他們的優勢。
英特爾的8800 ISA 是一個雄心勃勃的計算機架構項目,它具有基于32位能力的尋址、面向對象的體系結構、可變位長度的指令,以及用當時新的編程語言 Ada 編寫的操作系統。然而,英特爾在1979年緊急更換16位微處理器,新團隊用52周的時間來開發新的“8086”ISA,設計并制造芯片。由于時間緊迫,設計 ISA 只有10個人/周,主要是將8080的8位寄存器和指令集擴展到16位,這個團隊按計劃完成了8086。IBM 正在開發一種個人電腦來與蘋果 II 競爭,并且需要一個16位微處理器。IBM 感興趣的是摩托羅拉68000,但它落后于 IBM 的開發計劃,轉而使用了8086。后來IBM PC大賣,為英特爾 的8086 ISA帶來了一個非常光明的未來。
最初的8800項目在1986年停止使用,那一年英特爾在80386中將16位8086 ISA 擴展到32位,其寄存器也從16位擴展到32位,x86的 ISA 成功了,因為市場是很少有耐心的。
從復雜指令集到精簡指令集
20世紀80年代早期,業界對大型控制存儲器的復雜指令集計算機(CISC)進行了多項研究。隨著 Unix 操作系統使用高級語言編寫,關鍵問題就變成了: “編譯器會生成什么指令?”,硬件/軟件界面的顯著提升為架構創新創造了機會。
如果編譯器只使用簡單的寄存器操作和加載/存儲數據傳輸,避免了更復雜的指令, 使用簡單指令子集的程序運行速度要快三倍。這樣的實驗和向高級語言的轉變導致了從 CISC 轉向 RISC 的機會。首先,簡化了 RISC 指令,因此不需要微代碼解釋器。RISC 指令通常像微指令一樣簡單,可以直接由硬件執行。其次,原來用于 CISC ISA 微碼解釋器的存儲器被重新用作 RISC 指令的緩存。第三,基于圖形著色方案的寄存器分配器使編譯器更容易有效地使用寄存器。最后,可以在單個芯片中包括一個完整的32位數據通路,以及指令和數據緩存。在類似的技術中,CISC 每個指令周期執行了5到6個時鐘,而 RISC 的速度大約提高了4倍。
接下來的 ISA 創新是顯式并行指令集,在每條指令中捆綁多個獨立的操作。如果一條指令可以指定,編譯器技術可以有效地將操作分配到多個指令槽中,硬件就可以變得更簡單。與 RISC 方法一樣,將工作從硬件轉移到了編譯器。但基于這一思想的64位處理器,雖然在高度結構化的浮點程序中運行良好,但是對于分支較少的整數程序來說,它很難實現高性能。市場最終再次失去了耐心,導致出現了 x86的64位版本。
從PC時代到后PC時代
AMD 和英特爾使用了眾多資源和卓越的半導體技術來縮小 x86和 RISC 之間的性能差距。指令解碼器再次受到簡單指令性能優勢的啟發,在運行過程中將復雜的 x86指令翻譯成類似于 RISC的內部微指令,然后流水線執行 RISC 微指令。任何在 RISC上用于執行/分離指令和數據緩存、芯片上的二級緩存、深層管道以及同時獲取并執行多條指令的想法都可以并入 x86,在2011年前后,PC時代差不多到了巔峰時期。
PC軟件成為了一個巨大的市場,盡管 Unix 市場的軟件供應商會針對不同的商用 ISA 提供不同的軟件版本,但 PC 市場只有一個 ISA,所以軟件開發商提供的軟件只能與 x86 ISA 二進制兼容。龐大的軟件規模,相似的性能和更低的價格使得 x86主導了臺式計算機和小型服務器市場。
2007年,蘋果推出了 iPhone,開啟了后PC時代。智能手機公司沒有購買微處理器,而是使用其他公司的設計,主要是 ARM 的 RISC 處理器,在芯片上建立自己的系統(SoC)。移動設備設計人員認為芯片大小和能源效率與性能同樣重要,這使得 CISC 的 ISA 處于不利地位。此外,物聯網的到來極大地增加了處理器的數量以及在芯片尺寸、功耗、成本和性能方面所需的權衡。這種趨勢增加了設計時間和成本,進一步使 CISC 處理器處于不利地位。在如今的后 PC 時代,x86的出貨量自2011年以來幾乎每年下降10% ,而帶有 RISC 處理器的芯片則在飆升。如今,99% 的32位和64位處理器是 RISC。
回顧之后,市場解決了 RISC/CISC 的爭論, CISC 贏得了 PC 時代的后期階段,但 RISC 贏得了后 PC 時代。
當從單核時代到多核時代
“如果一個問題沒有解決方案,它可能不是一個問題,而是一個不需要解決的事實,而是需要隨著時間的推移加以解決。“
自20世紀70年代末以來,選擇的技術是基于金屬氧化物半導體(MOS)的集成電路,首先是nMOS ,然后是CMOS。MOS 技術的驚人改進速度成為驅動因素,使得有更積極的方法來實現給定 ISA 的性能。由于晶體管密度隨著速度線性增長而二次增長,人們使用了更多的晶體管來提高性能。雖然摩爾定律已經持續了幾十年 ,但在2000年左右開始放緩,到2018年,摩爾定律的預測與當前能力之間的差距大約為15倍,隨著 CMOS 技術接近基本極限,差距將繼續擴大。
在1986年到2002年之間,開發平行指令的層級是獲得性能的主要結構方法,隨著晶體管速度的提高,導致每年性能提高約50% 。為了保持流水線滿負荷運行,預測分支投機性地將代碼放入流水線以便執行。這種預測的使用既是性能的來源,也是效率低下的原因。當分支預測對的時候,可以提高性能,只需要很少的額外能量,甚至可以節省能量。但是當它“錯誤預測”分支時,處理器必須丟棄錯誤推測的指令,這時的計算工作和能量都被浪費了。處理器的內部狀態還必須恢復到錯誤預測分支之前的狀態,從而消耗額外的時間和能量。實際上,沒有什么程序能夠有能夠如此精確預測的分支。這導致了多核時代的誕生。
多核技術將確定并行性的責任轉移到了程序員和操作系統身上,無法解決能源效率的挑戰。無論是否有效地提高了計算效率,每個活躍的內核都在燃燒能量,而且并行計算的加速受限于順序運算的部分。真正的程序有更復雜的結構,允許在任何時刻使用不同數量的處理器。盡管如此,需要周期性地進行通信和同步,這意味著大多數應用程序都只能有效使用一小部分處理器。此外,多核處理器受到熱耗散功率(TDP)或封裝和冷卻系統的限制。TDP 的限制直接導致了處理器將放慢時鐘頻率并關閉空閑內核以防止過熱。
從通用處理到特定領域
那些掩飾成無法解決的問題是擺在我們面前的驚人機遇。
通用處理器固有的低效率,使得人們不可能在通用處理器中保持顯著的性能改進。鑒于提高性能以支持新的軟件功能的重要性, 還有哪些方法可能有前途呢?
一種更加以硬件為中心的方法是設計針對特定問題領域的計算機體系結構,并為該領域提供顯著的性能提升,因此被稱為“特定領域的體系結構”(DSA),這是一類為特定領域可編程的處理器通常是圖靈完整的,但是針對特定類別的應用進行了定制。它們不同于特定于應用程序的集成電路(ASIC) ,后者通常用于一個代碼很少更改的單一功能。DSA通常稱為加速器,數據應用系統可以取得更好的性能,包括圖形處理單元(GPU)、用于深度學習的神經網絡處理器和用于軟件定義網絡(SDN)的處理器。
DSA 為特定領域開發了一種更有效的并行形式,可以更有效地利用內存,而內存訪問比算術計算成本高得多。通用 CPU 通常支持32位和64位整數和浮點數數據。對于機器學習和圖形學中的許多應用來說,這比需要的精確度更高。例如,在DNN中,推理通常使用4位、8位或16位整數,從而提高了數據和計算的吞吐量。同樣,對于 DNN 訓練應用程序,FP 是有用的,但是32位可能就足夠了,16位是通常可以工作的。
DSA需要針對體系結構的高級操作,但是試圖從通用語言(如 Python、 Java、 c 等)中提取這種結構和信息是非常困難的。領域特定語言(DSL)支持這個過程,并使高效地編寫 DSA 成為可能。例如,DSL 可以使向量、稠密矩陣和稀疏矩陣的操作顯式化,從而使 DSL 編譯器能夠有效地將操作映射到處理器。DSL的例子包括 Matlab、 TensorFlow、 P4(一種用于編寫 SDN 程序的語言) ,以及 Halide等。
使用 DSL 時的挑戰是如何保持足夠的獨立性,使用 DSL 編寫的軟件可以移植到不同的架構,同時實現高效地將軟件映射到底層 DSA。例如,將 Tensorflow 轉換為使用 Nvidia GPU 或TPU的異構處理器。對于語言設計者、編譯器工作者和 DSA 架構師來說,在各個ISA之間平衡可移植性和效率是一個較大的挑戰。
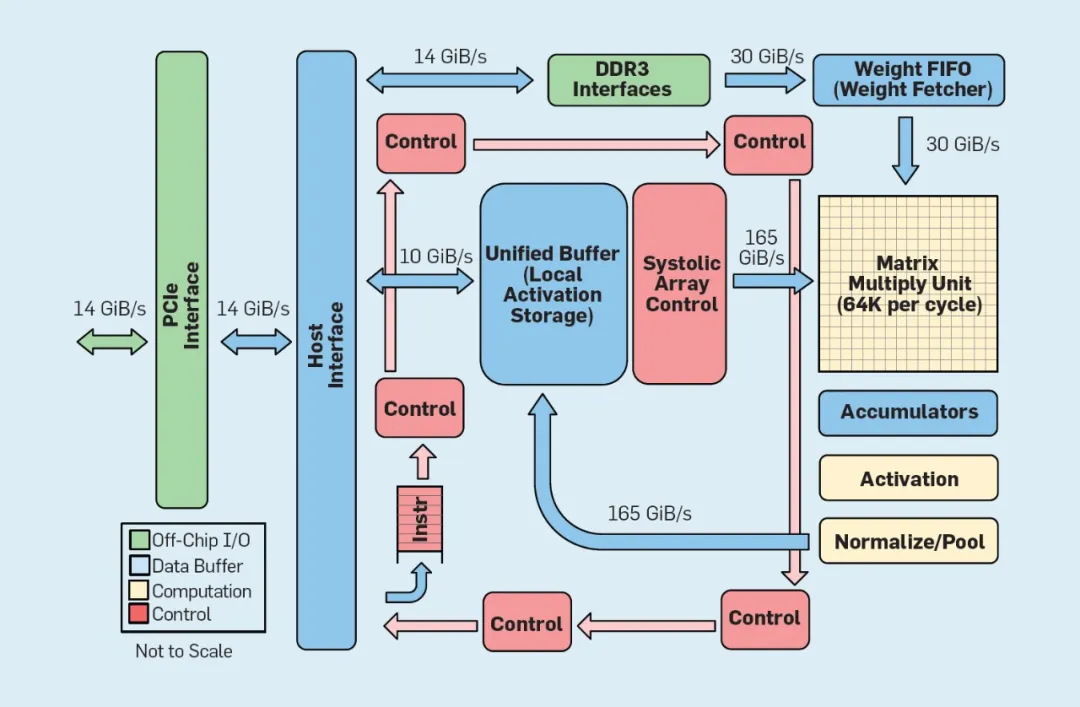
上圖所示,TPU 與通用處理器完全不同。主要的計算單元是一個矩陣單元,多種技術的結合是多重累加計算大約是通用單核 CPU 的100倍。與緩存不同,TPU 使用24兆字節的本地內存,大約是2015年通用 CPU 的兩倍功耗。使用基于 Google 六個常見推理問題的加權算術平均,TPU 比通用 CPU 快29倍。TPU 對于這種工作負載的能量效率比通用CPU 高出80倍以上。
從開放式體系結構到敏捷硬件開發
受到開源軟件成功的啟發,為了創建一個“ Linux for 處理器”,需要行業標準的開放式 ISA,這樣社區就可以創建開源核心。如果許多組織使用相同的 ISA 設計處理器,更大的競爭可能驅動更快的創新。
第一個例子是 RISC-V ,RISC-V 的社區在 RISC-V 基金會的管理下維護著這個架構 http://riscv.org/。開放式的 ISA 演變發生在公開的場合,硬件和軟件專家在最終決定之前進行合作。RISC-V 是一個模塊化的指令集,一小部分指令運行在開源軟件棧上,然后是可選的標準擴展,可以根據需要包含或省略這些擴展,基線版本包括32位和64位的版本。RISC-V 只能通過可選的擴展來增長,;即使不采用新的擴展,軟件棧仍然運行良好。RISC-V 的顯著特點是 ISA 的簡單性,與 ARM 公司開發的 armv8相比,RISC-V 只有很少的指令,以及較少的指令格式。RISC-V的指令格式只有6種,而 armv8至少有14種。由于 RISC-V 的目標范圍從數據中心芯片到物聯網設備,設計驗證可以成為開發成本的一個重要部分。簡單性降低了設計處理器和驗證硬件正確性的工作量。RISC-V 是一個干凈的設計,避免了微架構或技術相關特性,這些特性已經被編譯器技術的進步所取代。RISC-V還通過為自定義加速器保留大量操作碼空間來支持 DSA。
除了RISC-V,Nvidia 還在2017年宣布推出了一個免費開放的架構,名為NVDLA ,這是一個可擴展的、可配置的 DSA,用于機器學習推理。配置選項包括數據類型(int8、 int16或 fp16)和二維乘法矩陣的大小,ISA、軟件棧和實現都是開放的。
再次受到軟件開發流程的啟發,ECAD工具提高了抽象層次,支持敏捷開發,這種更高層次的抽象增加了設計之間的重用。
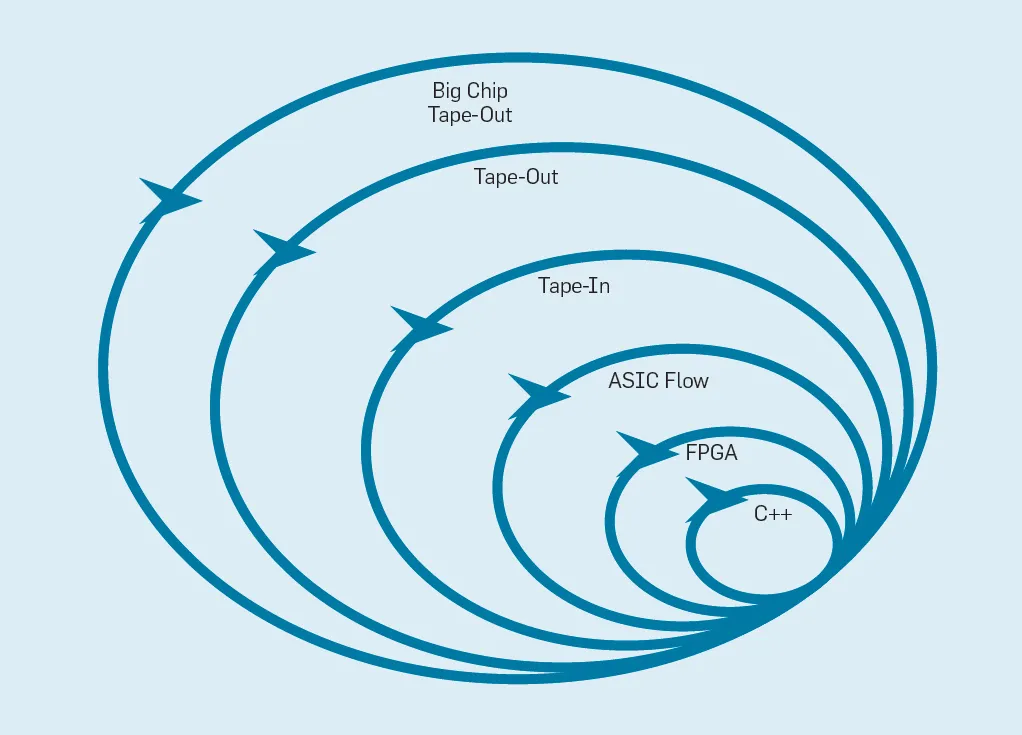
上圖圖概述了敏捷開發方法如何通過在適當的層次上改變原型來工作,最內層是軟件模擬器,如果一個模擬器能夠滿足一個迭代,那么軟件模擬器是進行改變最容易和最快捷的地方。下一個級別是FPGA,它可以比一個詳細的軟件模擬器快幾百倍。FPGA可以運行操作系統和類似于SPEC的完整基準,允許對原型進行更精確的評估。AWS在云中提供了FPGA服務,因此可以直接使用而無需首先購買硬件和建立實驗室。下一個外層使用 ECAD 工具來生成芯片的布局。即使在工具運行之后,在準備生產新的處理器之前,也需要一些手動步驟來精煉結果。如果目標是制造一個大型芯片,那么最外層的設計是昂貴的。
小結
軟件創新可以給計算機體系架構的創新帶來啟發,提高硬件/軟件接口的抽象層為創新提供了機會,市場最終決定了計算機體系結構的爭論。摩爾定律的終結不是必須要解決的問題,而是被認識到的事實,特定于領域的語言和體系結構使人們從專有指令集的鏈條中解放出來。在開源生態系統的幫助下,靈活開發的芯片將展示先進的技術,從而加速商業應用,處理器的 ISA 很可能是 RISC-V,流程也可能演進到敏捷硬件開發中來。