論文榮登計算機體系結構頂會ISCA,芯片架構成為邊緣AI最佳并行計算選擇
AI 大模型的爆發帶動了 GPU 的強勁需求,從云端到邊緣滲透的 AI 應用也將帶動邊緣 AI 服務器及加速處理器的需求。通過對比 GPGPU、FPGA、NPU 和 ASIC,可重構計算架構 CGRA 成為最適合邊緣 AI 的并行計算架構。由芯動力提出的可重構并行處理器(RPP)是比傳統 CGRA 更適合大規模并行處理的計算架構,這不但通過試驗評測得到證實,而且也通過 ISCA 會議得到國際學術權威的認可。基于 RPP 架構的 R8 芯片及后續更高性能的迭代芯片將是邊緣 AI 服務器和 AI PC 的理想 AI 加速處理器選擇。
目錄
一、什么是邊緣 AI?
二、邊緣 AI 服務器市場趨勢
三、適合邊緣 AI 的理想計算架構
四、RPP 架構詳解
五、RPP 處理器 R8 能效對比
六、RPP 處理器到國際學術權威認可
七、結語
一、什么是邊緣 AI?
邊緣 AI(AI Edge)是人工智能 (AI) 與邊緣計算交叉的先進技術,這一概念源于 AI 從云端向邊緣下沉的分布式計算范式轉變。邊緣 AI 的核心是將 AI 算法直接嵌入到產生大量數據的本地環境中,例如智能手機、物聯網設備或本地服務器,通過位于網絡 “邊緣”(即更靠近數據源)的設備和系統進行實時數據處理和分析。
相對于傳統的數據中心或云計算平臺的 AI 訓練或推理,邊緣 AI 的主要優勢在于 “就地處理”,大大減少了數據傳輸和處理的延遲,這在智能監控、自動駕駛、實時醫療診斷或工業自動化控制等應用場景中尤其重要。
實現邊緣 AI 計算的設備和系統主要包括:
- 智能終端:主要用于產生或收集數據的設備,如智能傳感器、智能手機、AI PC 或物聯網設備等;
- 邊緣 AI 服務器:直接對所收集數據進行處理和分析的邊緣設備及軟硬件系統,比如專用的大語言模型(LLM)AI 推理服務器、智能駕駛區域計算中心服務器等;
- 通信網絡設備:盡管邊緣 AI 應用對通信網絡的帶寬和速率要求沒有云端那么高,但也必須提供可靠的高速連接才能達到邊緣 AI 所需的低延遲和實時性要求。
本文主要討論邊緣 AI 服務器及其市場發展趨勢、對 AI 加速處理器的要求,以及適合邊緣 AI 應用的并行計算架構和處理器實現。
二、邊緣 AI 服務器市場趨勢
AI 服務器是指專為人工智能應用而設計的高性能計算機設備,能夠支持大規模數據處理、模型訓練、推理計算等復雜任務。AI 服務器通常配備高性能的處理器、高速內存、大容量高速存儲系統,以及高效的散熱系統,以滿足 AI 算法對計算資源的極高需求。按不同的分類標準,AI 服務器可以大致分為訓練服務器、推理服務器、GPU 服務器、FPGA 服務器、CPU 服務器、云端 AI 服務器,以及邊緣 AI 服務器等。
據 Gartner 預測,從現在到 2027 年,AI 服務器市場規模將保持高速增長,年復合增長率高達 30%。該機構發布的《2024 年第一季度全球服務器市場報告》顯示,今年 Q1 全球服務器市場銷售額為 407.5 億美元,同比增長 59.9%;出貨量為 282.0 萬臺,同比增長 5.9%。在眾多 AI 服務器供應商中,浪潮信息蟬聯全球第二,中國第一,其服務器出貨量在全球市場占比 11.3%,同比增長 50.4%,在 TOP5 廠商中增速第一。
另據中商產業研究院發布的《2024-2029 年中國服務器行業需求預測及發展趨勢前瞻報告》,2022 年末,國內市場總規模超過 420 億元,同比增長約 20%;2023 年約為 490 億元,市場增速逐步放緩;預計 2024 年市場規模將達 560 億元。從出貨量來看,2022 年中國 AI 服務器市場出貨量約 28.4 萬臺,同比增長約 25.66%;2023 年約為 35.4 萬臺,預計 2024 年將達到 42.1 萬臺。
在 AI 大模型發展早期,AI 服務器需求以模型訓練為主,因而訓練型服務器占據市場主導地位。目前,AI 服務器市場中 57.33%為訓練型服務器,推理型服務器占比達 42.67%。然而,隨著生成式 AI 應用往邊緣端滲透,預計未來推理型服務器將逐漸成為市場主流,邊緣 AI 服務器從出貨量上將超過云端訓練和推理服務器。
IDC 最新發布的《中國半年度邊緣計算市場(2023 全年)跟蹤》報告數據顯示,2023 年中國邊緣計算服務器市場繼續保持穩步上升,同比增長 29.1%。IDC 預測,到 2028 年,中國邊緣計算服務器市場規模將達到 132 億美元。

作為邊緣計算的重要組成部分,2023 年定制邊緣服務器規模已達 2.4 億美元,相較 2022 年增長 16.8%。從廠商銷售額角度來看,邊緣定制服務器市場中占比較大的廠商分別是浪潮信息、聯想、華為、新華三。隨著邊緣計算應用的多樣化發展,新興服務器廠商在車路協同、邊緣 AI 和智能終端等業務場景和應用市場將有較大突破,使得邊緣服務器市場呈現出多樣化格局。
三、適合邊緣 AI 的理想計算架構
PC 時代由 WINTEL(微軟 Windows + 英特爾 CPU)聯盟主導、智能手機時代由 Android+Arm 聯盟主導,AI 時代將由哪個聯盟主導呢?一個新的聯盟正初露端倪,那就是由英偉達和臺積電組成的 NT 聯盟(Nvidia+TSMC)。據華爾街投資專家預測,2024 年 NT 聯盟總營收預計將達到 2000 億美元,總凈利潤 1000 億美元,總市值有望突破 5 萬億美元。由云端 AI 訓練和 AI 大模型應用驅動的英偉達 GPU 和臺積電 AI 芯片制造業務將成為今年最大的贏家。
盡管英偉達在云端 AI 訓練和推理市場占據了絕對主導地位,但在邊緣 AI 應用場景中英偉達的 GPGPU 卻不是最佳選擇,因為其計算架構固有的高功耗和高成本問題限制了其在更為廣泛而分散的邊緣 AI 應用中的作用。計算機架構領域的學者專家都在尋求能夠替代 GPGPU 的高能效并行技術架構,基于特定域專用架構(DSA)的 ASIC 設計是一種可行的關鍵思路,比如谷歌的張量處理單元 (TPU) ,這種專為加速機器學習工作負載而設計的處理器采用脈動陣列架構,可高效執行乘法和累加運算,主要面向數據中心應用。另外一個思路是以三星為代表的神經處理單元 (NPU) ,它專為移動場景而設計,具有節能的內積引擎,可利用輸入特征圖稀疏性來優化深度學習推理的性能。
雖然 TPU 和 NPU 都能夠提供部分替代 GPGPU 的高性能和節能解決方案,但它們的專用設計屬性限制了其多功能性和廣泛的適用性。總部位于美國加州且在臺灣和大陸都有研發中心的邊緣 AI 芯片初創公司耐能(Kneron)提出了可重構 NPU 的方案,使得 NPU 芯片有 ASIC 高性能而又不犧牲數據密集型算法的可編程性。憑借獨特創新的架構和優異的性能,耐能團隊獲得 IEEE CAS 2021 年 Darlington 最佳論文獎。耐能第 4 代可重構 NPU 可以支持同時運行 CNN 和 Transformer 網絡,既可做機器視覺,也可運行語義分析。與僅面向特定應用的普通 AI 模型不同,耐能的可重構人工神經網絡(RANN)技術更加靈活,可滿足不同應用需求并適應各種計算體系架構。據該公司宣稱,其邊緣 GPT AI 芯片 KL830 可應用于 AI PC、USB 加速棒和邊緣服務器,當與 GPU 配合使用時,NPU 可將設備能耗降低 30%。
可重構硬件是另一種可提供高性能和節能計算的解決方案,現場可編程門陣列 (FPGA) 是可重構硬件計算的代表,其特點是細粒度可重構性。FPGA 利用具有可編程互連的可配置邏輯塊來實現自定義計算內核。這種定制的計算能力使得基于 FPGA 的加速器能夠部署在金融計算、深度學習和科學仿真等廣泛的大規模計算應用中。然而,FPGA 提供的位級可重構性會帶來明顯的面積和功率額外開銷,而且沒有規模成本效益,這極大地限制了其在需要低功耗和小尺寸的應用場景中的適用性。
粗粒度可重構架構 (CGRA) 代表另一類可重構硬件。與 FPGA 相比,CGRA 提供粗粒度的可重構性,例如字級可重構功能單元。由于 CGRA 內部的 ALU 模塊已經構建完成,且其互聯也要比 FPGA 更簡單、規模更小,因此其延時和性能要顯著好于在門級上進行互連形成組合計算邏輯的 FPGA。CGRA 更適合 word-wise 類型 (32bit 為單位) 的可重構計算,而且可以緩解 FPGA 存在的時序、面積和功率開銷問題,是未來邊緣 AI 的理想高性能并行計算架構。
下面我們大致梳理一下 CGRA 的發展歷程:
- 早在 1991 年,國際學術界就開啟了可重構芯片的研究;
- 2003 年,歐洲宇航防務集團 (EADS) 率先在衛星上采用可重構計算芯片;
- 2004 年,歐洲 IMEC 提出動態可重構結構 ADRES,在三星的生物醫療、高清電視等系列產品中得到應用,日本的瑞薩科技也采用這種架構。
- 2006 年,清華大學微電子所魏少軍教授帶領的可重構計算團隊開始進行可重構計算理論和架構研究;
- 2017 年,美國國防高級研究計劃局(DARPA)宣布啟動電子復興計劃(Electronics Resurgence Initiative,簡稱 ERI),將 “可重構計算” 技術列為美國未來 30 年的戰略技術之一;
- 2018 年,基于清華大學可重構計算技術的清微智能成立,正式開啟商業化進程。2019 年,清微智能量產全球第一款可重構智能語音芯片 TX210,證明了可重構計算的商業價值。2020 年,清微智能獲得中國電子學會技術發明一等獎;2023 年,國家大基金二期投資清微智能。目前,清微智能共有邊緣端 TX2、TX5 系列芯片,以及用于服務器領域的 TX8 系列三大芯片產品。其中,TX2 和 TX5 系列芯片已應用于智能安防、金融支付、智能穿戴,智能機器人等多個領域;面向云端市場的 TX8 高算力芯片主要應用場景是 AI 大模型的訓練和推理。
- 國內另一家基于可重構計算技術的 AI 芯片初創公司珠海芯動力于 2017 年成立,其可重構并行處理器(RPP)架構是改進版的 CGRA。2021 年首顆芯片 RPP-R8 成功流片,2023 年進入金融計算、工業攝像和機器人等邊緣 AI 應用市場,并與浪潮信息達成戰略合作進入邊緣 AI 服務器市場。
國際計算機學術界和高科技產業界已形成共識,基于 CGRA 架構的可重構計算芯片具備廣泛的通用計算能力,可以應用于各種邊緣 AI 計算場景,是解決通用高算力和低功耗需求的必由之路。
四、RPP 處理器架構詳解
RPP 和 CGRA 都是屬于粗粒度的可重構陣列,都可以達到類似 ASIC 的面積密度和功率效率,而且都是可以用軟件編程的。但是,RPP 在可重構類型和編程模型方面跟 CGRA 還是不同的,具體表現為:
1. RPP 是準靜態可重構陣列,而傳統 CGRA 一般用于動態可重構陣列。靜態可重構整列是指每個指令在處理單元(PE)的執行不隨時間變化,數據流也是不變的。對于編譯器來講,靜態的可重構陣列不需要對指令在時間上進行安排,這樣就可以讓 RPP 構造更加簡單,指令的分配速度很低。因此,RPP 很容易實現一個大型的陣列,譬如 32x32 的陣列。RPP 比傳統 CGRA 更加適用于大規模并行計算。
2. RPP 使用的是多線程 SIMT 編程模型,而 CGRA 通常使用的是單線程語言編程。RPP 可以兼容 CUDA 語言,更加適合并行計算。CUDA 語言要求編程人員從一開始就考慮數據的并行度,把并行算法用 CUDA 語言表現出來;編譯器則不需要分析并行計算度,編譯器就非常簡單;CUDA 語言是 SIMT 類型,只用于數據并行的計算,而且并行度在一個程序里保持不變。CGRA 則通常使用 C 語言 + 獨立的編譯器,雖然理論上可以覆蓋任意的計算類型,但是編譯器非常復雜,很難達到較高的編譯效率。
下面圖表對 RPP 及幾個主流的可重構加速架構做了對比。

RPP 架構的優勢可以總結為以下四點:
- 具有墊片暫存器(gasket memory)的環形可重構并行處理架構,允許在不同數據流之間高效地重用數據;
- 分層式內存設計具有多種數據訪問模式、地址映射策略和共享內存模式,可實現高效靈活的內存訪問;
- 各種硬件優化機制,如并發內核執行、寄存器拆分和重新填充,以及異構標量和向量計算,從而提高了整體硬件利用率和性能;
- 一個兼容 CUDA 的端到端完整軟件棧,具有編譯器、運行時環境、高度優化的 RPP 庫,可實現邊緣 AI 應用的快速高效部署。
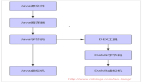
芯動力基于 RPP 架構提出了 RPP 硬件設計框圖,并通過 R8 芯片真實的展現出這種并行計算架構的優越性。這種硬件設計實現主要由一個環形可重構處理器(Circular Reconfigurable Processor)、一個內存單元和一個序列器組成,見下圖。
- 循環可重構處理器是大規模并行計算的核心計算組件。
- 內存單元被分成多個內存組,每個內存組都與一個緩存配對,以利用程序的時間和空間局部性實現高效的數據重用。只有當環形可重構處理器內的寄存器和緩沖區已滿時,中間數據才會被傳輸并存儲在內存單元中。
- 序列器用于解碼和分發指令到環形可重構處理器,并使用緩存來存儲從 DDR 收到的指令。

環形可重構處理器包括 NPU 處理單元 (PE) 和一個墊片內存。每個 PE 都配備了一個內存端口,以方便對內存單元進行數據訪問。內存端口設計有模式控制器、地址計算單元和多個多路復用器,以支持不同的數據訪問模式和共享內存模式。為了實現靈活的處理器內通信,每個 PE 都集成了一個開關盒 (SB) 和一個互連開關盒 (ICSB),以實現高效的數據轉發。這些 PE 按線性順序連接,墊片內存充當第一個和最后一個 PU 之間的橋梁,從而形成環形拓撲。
環形可重構處理器內的數據處理從第一個 PE 開始,并以流水線方式遍歷 PE,中間計算結果按順序輸出到后續 PE。墊片內存緩存最后一個 PE 的輸出并將它們重新循環到第一個 PE,從而最大限度地提高數據局部性并消除內存單元的內存流量。PE 中的關鍵計算組件是處理引擎。在每個 PE 中,都有多個算術邏輯單元 (ALU),其中每個 ALU 都與數據寄存器和地址寄存器耦合。這些數據寄存器聚合在一起形成一個數據緩沖區,便于在每個 PE 內快速訪問數據。
此外,線性交換網絡和墊片存儲器的組合實現了靈活的數據流控制和高效的數據重用,同時消除了傳統基于網格的 CGRA 設計中復雜的網絡路由。結合對內存單元的靈活高效數據訪問,RPP 可以優化數據流處理,最小化內存流量,從而最大限度地提高資源利用效率。
RPP 處理器采用 SIMT 編程模型來為靈活多線程管道啟用流式數據流處理。

為了確保與現有 GPGPU 軟件生態系統的兼容性,芯動力的 RPP 處理器采用了擁有廣泛用戶群的 CUDA。CUDA 代碼由基于 LLVM 的前端解析,為 RPP 后端生成 PTX 代碼。RPP 編譯器將 CUDA 內核解釋為數據流圖并將它們映射到虛擬數據路徑(VDP)。然后根據硬件約束將 VDP 分解為多個物理數據路徑(PDP),每個 PDP 的配置由序列器在運行時生成。
RPP 的軟件堆棧可以支持廣泛的大規模并行應用,包括機器學習、視頻 / 圖像處理和信號處理等。對于機器學習應用,該堆棧與不同的主流框架兼容,例如 PyTorch、ONNX、Caffe 和 TensorFlow。此外,用戶可以靈活地使用 CUDA 定義他們的自定義程序。這些高級應用程序由 RPP 框架處理,該框架包含一個編譯器和不同領域特定的庫。在軟件堆棧的底部,采用 RPP 運行時環境和 RPP 驅動程序來確保使用工具鏈編譯的程序可以在底層硬件上無縫執行。
五、RPP 處理器 R8 能效對比
基于以上 RPP 處理器硬件設計和完整軟件堆棧實現的 RPP-R8 芯片在計算性能和能效上表現如何呢?
R8 芯片的性能參數如下表所示:

針對邊緣計算場景,芯動力將 RPP-R8 芯片與兩款英偉達邊緣 GPU 進行了比較:Jetson Nano 和 Jetson Xavier AGX。Jetson Nano 的芯片尺寸與 RPP 相似,可在物理面積限制內提供相關比較;選擇 Jetson Xavier AGX 是基于其與 RPP-R8 相當的理論吞吐量。芯動力在 ResNet-50 推理上評估了這三個 AI 加速平臺,其中 Jetson Nano 的吞吐量來自基準測試論文,而 Xavier AGX 的性能數據來自英偉達官方網站。

如上表所示,RPP-R8 的實測運行吞吐量分別是 Jetson Nano 和 Jetson Xavier AGX 的 41.3 倍和 2.3 倍。要知道,Jetson Xavier AGX 的芯片尺寸幾乎是 R8 的三倍,工藝也更先進(12 nm vs. 14 nm),但其性能低于 R8。在能效方面,R8 的能效分別是 Jetson Nano 和 Jetson Xavier AGX 的 27.5 倍和 4.6 倍。這些結果表明,在面積和功率預算有限的邊緣 AI 場景中,RPP-R8 的表現明顯優于 Jetson Nano 和 Jetson Xavier AGX。

深度學習推理是一種廣受認可的大規模并行工作負載,也是 RPP-R8 硬件的關鍵應用。鑒于 Yolo 系列模型與 ResNet-50 等分類模型相比表現出更高的計算復雜度,芯動力選擇英偉達 Jeston Nano Orin 作為 GPU 平臺,其峰值吞吐量比 Jetson AGX Xavier 更高,為 40 TOPS。由于 CPU 通常不是為高性能深度學習推理而構建的,因此選擇 Jetson Xavier Nx 作為比較低端的 GPU 平臺,具有 21 TOPS 的峰值吞吐量。評估批處理大小為 1、2 和 4 的工作負載,反映了真實的邊緣場景。上圖顯示了三個平臺的吞吐量性能比較,RPP-R8 在 Yolo-v5m 和 Yolo-v7 tiny 上展示了更高的吞吐量。在批量大小為 1 的情況下,RPP-R8 的吞吐量大約比 Jeston Nano Orin 高 1.5× ~2.5 倍,比 Jeston Xavier Nx 高 2.6× ~4.3 倍。
評估與測試結果表明,RPP 在延遲、吞吐量和能效方面優于傳統的 GPU、CPU 和 DSP 等架構。RPP 處理器的性能提升歸功于其獨特的硬件特性,主要包括:1) 循環數據流處理:中間結果流經 PE 之間的流水線寄存器和 FIFO,顯著減少了數據移動和到遠程內存存儲的內存流量;與 GPU 和 CPU 中的數據處理相比,這種模式效率更高。2) 分層內存系統:RPP 通過其分層內存系統最大化數據局部性。RPP-R8 芯片面積的很大一部分(約 39.9%)專用于片上存儲器。這種設計選擇提供了廣泛的內存容量,增強了數據重用并減少了頻繁訪問外部存儲器的需求。3) 矢量化和多線程管道:RPP 的硬件架構和編程模型可實現有效的矢量化和多線程管道。這種設計充分利用了 RPP 進行并行處理的全部計算潛力,確保其資源得到最大程度的利用,從而提高性能。
除了在能耗、延遲和吞吐量方面的優勢外,RPP 還因其小面積而脫穎而出。只有 119 平方毫米的芯片面積消耗使得 RPP-R8 成為面積受限的邊緣計算的理想平臺。RPP 的另一個特點是其高可編程性,由全面的端到端軟件堆棧支持,可顯著提高部署效率。與 CUDA 的兼容性使用戶能夠利用熟悉的 CUDA 生態系統,從而縮短學習曲線并促進更容易的采用。支持即時編程和圖形編程模式,為用戶提供了高度的靈活性,滿足各種計算需求。包括 OpenRT 和 RPP-BLAS 在內的不同庫支持也促進了各種場景中的高性能和高效部署。全棧解決方案,包括硬件架構和軟件支持,使 RPP 在各種邊緣計算硬件中脫穎而出。
六、RPP 架構得到國際學術權威認可
由芯動力攜手英國帝國理工、劍橋大學、清華大學和中山大學等頂尖學府的計算機架構團隊共同撰寫的論文《Circular Reconfigurable Parallel Processor for Edge Computing》(RPP 芯片架構)已成功被第 51 屆計算機體系結構國際研討會(ISCA 2024)的 Industry Track 收錄。芯動力創始人兼 CEO 李原博士與帝國理工博士畢業生 Hongxiang Fan(現在英國劍橋的三星 AI 中心做研究科學家)受邀在阿根廷布宜諾斯艾利斯舉行的 ISCA 2024 會議上發表演講,與 Intel 和 AMD 等國際知名企業的專家同臺交流。

本屆 ISCA 共收到來自全球 423 篇高質量論文投稿,經過嚴謹的評審流程,僅有 83 篇論文脫穎而出,總體接收率低至 19.6%。其中,Industry Track 的錄取難度尤為突出,接收率僅為 15.3%。
作為計算機體系結構領域的頂級學術盛會,ISCA 由 ACM SIGARCH 與 IEEE TCCA 聯合舉辦。自 1973 年創辦以來,一直是推動計算機系統結構領域進步的先鋒力量,其廣泛的影響力和卓越的貢獻使其成為谷歌、英特爾、英偉達等行業巨頭競相展示前沿研究成果的高端平臺。ISCA 與 MICRO、HPCA、ASPLOS 并稱為四大頂級會議,而 ISCA 更是其中的佼佼者,論文錄取率常年保持在 18% 左右。多年來,眾多在 ISCA 上發表的研究成果已成為推動半導體和計算機行業發展的關鍵動力。
本次入選的可重構并行處理器(RPP)論文為邊緣計算領域注入了強勁動力。實驗結果充分證實,作為一款并行計算的硬件平臺,RPP 的性能全面超越當前市場上的 GPU,特別是在對延遲、功耗和體積有著極高要求的應用場景中表現尤為出色。
六、結語
ChatGPT 引爆了 AI 大模型,從而帶動了 GPU 和 AI 加速器的巨大需求。AI 應用的發展趨勢將從云端 AI 訓練和推理逐漸往邊緣和端側 AI 滲透,為各種 AI 應用提供軟硬件支持的 AI 服務器也同樣遵循從數據中心到邊緣計算的分布式擴展趨勢。傳統 GPGPU 在邊緣 AI 應用場景中開始暴露出明顯的架構缺陷,其高成本、高功耗和高延遲問題迫使業界專家尋求更為高能效的并行計算架構。
在對比 CPU、GPU、ASIC、FPGA 和 NPU 等不同計算架構后,我們發現可重構計算架構 CGRA 是比較適合邊緣 AI 應用的,尤其是芯動力提出的可重構并行處理器(RPP)。通過與英偉達同類 GPU 對比分析,基于 RPP 架構的 R8 芯片在延遲、功耗、面積成本、通用性和快速部署方面都表現出色,我們認為這是目前最理想的邊緣 AI 并行計算架構。
在今年 7 月份阿根廷舉行的 ISCA2024 學術會議上,關于 RPP 處理器架構的論文得到國際學術權威認可。隨著邊緣 AI 的發展,AI 服務器和 AI PC 將迎來快速增長的黃金時期,而支持這類邊緣 AI 設備的 AI 加速器也將同步增長。由珠海芯動力科技提出的 RPP 處理器芯片也將得到業界認可,成為邊緣 AI 應用場景中最為理想的 AI 加速處理器。