如何排查Python中的內存問題?
譯文【51CTO.com快譯】發現應用程序內存不足是開發者遇到的糟糕問題之一。內存問題一般很難加以診斷和修復,而在Python中尤為困難。Python的自動垃圾收集讓您易于上手該語言,但出現問題時,開發者不知道如何識別和修復問題。
本文介紹如何診斷和修復開源AutoML庫EvalML中的內存問題。解決內存問題沒什么訣竅,但我希望開發者、尤其是Python開發者可以了解將來遇到這類問題時可利用的工具和優秀實踐。
什么是內存泄漏?
任何編程語言最重要的功能之一是能夠將信息存儲在計算機內存中。每當您的程序創建一個新變量,它都會分配一些內存用于存儲該變量的內容。
內核為程序訪問計算機的CPU、內存和磁盤存儲等資源定義了接口。每種編程語言提供了要求內核分配和釋放內存塊供運行中的程序使用的方法。
程序要求內核留出內存塊供使用,但隨后由于錯誤或崩潰,程序完成使用該內存后從未告訴內核,就會發生內存泄漏。在這種情況下,內核將繼續認為被遺忘的內存塊仍被運行中的程序使用,其他程序無法訪問這些內存塊。
如果運行程序時同樣的泄漏一再發生,被遺忘的內存總量會變得很龐大,因而消耗計算機的大部分內存!在這種情況下,如果程序隨后嘗試請求更多內存,內核會拋出“內存不足”錯誤,程序將停止運行,換句話說“崩潰”。
因此,找到并修復所編寫的程序中的內存泄漏很重要,否則程序最終可能會耗盡內存并崩潰,或者可能導致其他程序崩潰。
第1步:確定是內存問題
應用程序崩潰的原因有很多:也許運行代碼的服務器崩潰了,也許代碼本身存在邏輯錯誤,所以確定眼前的問題是內存問題很重要。
EvalML性能測試悄然崩潰。突然,服務器停止記錄進度,作業悄然停止。服務器日志會顯示編程錯誤引起的任何堆棧追蹤,所以我有預感:崩潰是作業耗用所有的可用內存引起的。
我又重新進行了性能測試,但這次啟用了Python的內存分析器,以獲取內存使用情況圖。測試再次崩潰,當我查看內存圖時,發現了該圖:
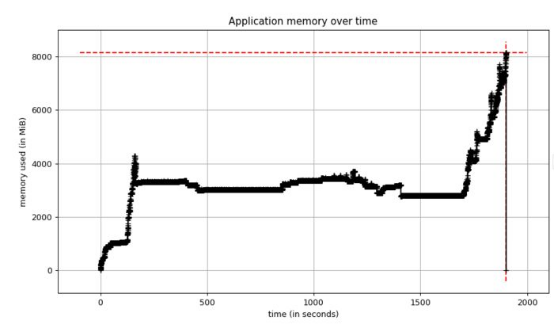
圖1.性能測試的內存使用情況
內存使用情況逐漸保持穩定,但隨后達到8 GB!我知道應用服務器有8GB 的內存,所以該圖證實我們耗盡了內存。此外,內存穩定時,我們使用約4 GB的內存,但之前版本的EvalML使用約2 GB的內存。由于某種原因,當前版本使用的內存是平常的大約兩倍。
現在需要找出原因。
第2步:用極簡示例在本地重現內存問題
查明內存問題的原因需要大量實驗和迭代,因為答案通常并不明顯。如果是這樣,您可能不會將其寫入代碼!出于這個原因,我認為用盡可能少的代碼行重現問題很重要。這個極簡示例使您可以在修改代碼時在分析器下快速運行它,查看是否取得進展。
我憑經驗知道,大概在我看到大峰值時,應用程序運行含有150萬行的出租車數據集。我將應用程序精簡至僅運行該數據集的部分。我看到了類似上述的峰值,但這次內存使用量達到了10 GB!
見此情形,我知道有一個足夠好的極簡示例可深入研究。
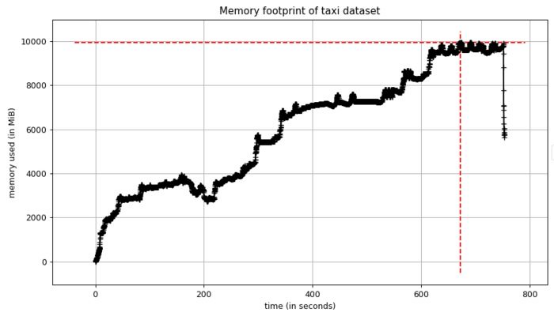
圖2. 出租車數據集本地重現的內存使用情況
第3步:找到分配最多內存的代碼行
一旦將問題隔離到盡可能小的代碼塊,我們可以看到程序在何處分配最多的內存。這便于您重構代碼和修復問題。
filprofiler是個出色的Python工具。它顯示應用程序中每一行代碼在內存使用高峰時的內存分配情況。這是本地示例的輸出結果:
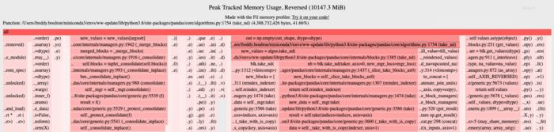
圖3. fil-profile的輸出
filprofiler根據內存分配情況對應用程序中的代碼行(以及依賴項的代碼)進行排名。線越長越紅,分配的內存越多。
分配最多內存的代碼行用來創建pandas數據幀(pandas/core/algorithms.py和pandas/core/internal/managers.py),數據量達4GB!我在這里截斷了filprofiler的輸出,但它能夠將pandas代碼追溯到用EvalML來創建Pandas數據幀的代碼。
是的,EvalML創建Pandas數據幀,但這些數據幀在整個AutoML算法中都是短暫的,一旦不再使用就應該被釋放。由于實際情況并非如此,加上這些數據幀在內存中的時間足夠長,我認為最新版本帶來了內存泄漏。
第4步:識別泄漏對象
在Python中,泄漏對象是使用完成后沒有被Python的垃圾收集器釋放的對象。由于 Python使用引用計數作為主要的垃圾收集算法之一,這些泄漏對象通常是由對象占有引用時間過長引起的。
這類對象很難找到,但可以用一些Python工具簡化搜尋。第一個工具是垃圾收集器的gc.DEBUG_SAVEALL標志。若設置該標志,垃圾收集器將無法訪問的對象存儲在gc.garbage列表中。這讓您可以進一步研究這些對象。
第二個工具是objgraph庫。一旦對象在gc.garbage列表中,我們可以根據pandas數據幀過濾該列表,并使用objgraph查看哪些其他對象引用這些數據幀、將它們保存在內存中。
這是我在可視化其中一個數據幀后看到的對象圖的一個子集:
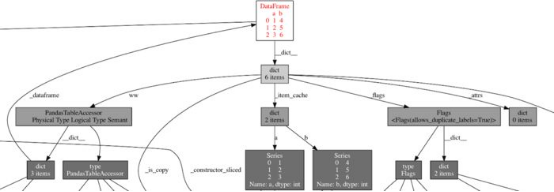
圖4. Pandas數據幀使用內存圖,顯示導致內存泄漏的循環引用
這就是我要找的確鑿證據!數據幀通過創建循環引用的PandasTableAccessor對自身進行引用,因此這會將對象保留在內存中,直到Python的垃圾收集器運行并釋放它。(可以通過dict、PandasTableAccessor、dict和_dataframe 追蹤循環。)這對EvalML來說有問題,因為垃圾收集器將這些數據幀保存在內存中的時間太長,以至于我們耗盡內存!
我能夠將PandasTableAccessor追溯到Woodwork庫,并將該問題提交給維護者。他們在新版本中修復后,向pandas存儲庫提交了相關的問題單,這個例子表明了開源生態系統中的合作。
Woodwork更新發布后,我可視化同一個數據幀的對象圖,循環消失了!
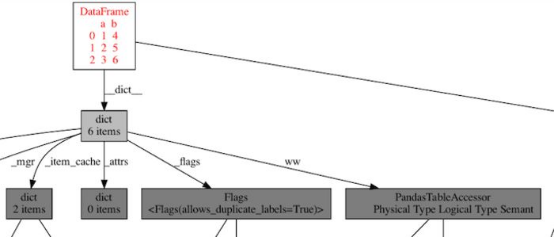
圖5.woodwork升級后pandas數據幀的對象圖。不再有循環!
第5步:驗證修復是否有效
我在EvalML中升級Woodwork 版本后,測量了應用程序的內存使用情況。結果發現,內存使用量現在不到過去的一半!
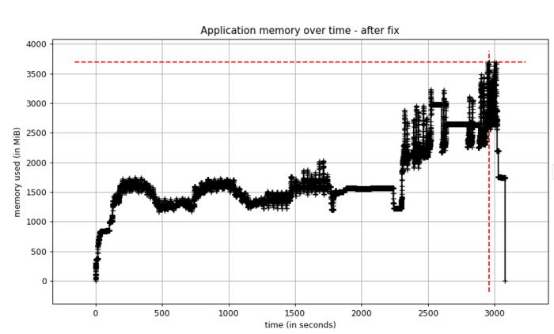
圖6. 修復后性能測試的內存使用情況
原文標題:How to troubleshoot memory problems in Python,作者:Freddy Boulton
【51CTO譯稿,合作站點轉載請注明原文譯者和出處為51CTO.com】