模型大十倍,性能提升幾倍?谷歌研究員進行了一番研究
隨著深度學習模型的體量越來越大,進行任何形式的超參數調整都會變得非常昂貴,因為每次訓練運行都可能要花費數百萬美元。因此一些研究旨在探究「隨著模型大小增加,性能提高程度」的規律。進行這種規律預測有助于讓更小規模的研究拓展到更大更貴,但性能更高的環境。
通過利用在多個模型大小上執行的小規模實驗,人們可以找到簡單的函數比例關系(通常是冪律關系),這些函數可以在花費訓練所需的計算之前預測大型模型的性能。
理論是美好的,實際上想這么做顯然會遇到一些困難。如果不夠謹慎,推斷擴展性能可能會產生誤導,導致公司投資數百萬來訓練一個性能不比小模型更好的模型。本文會通過一個示例來介紹這是如何發生的,以及發生這種情況的一種原因。
作為研究擴展效應的示例,假設我們的目標是在具有 3 個隱藏層的寬得夸張的 MLP 中訓練 ImageNet。我們要從 64、128 和 256 隱藏大小開始,并使用這些來選擇超參數,在本例中為 Adam 找到了 3e-4 的學習率。我們還將訓練的長度固定為 30k 權重更新,每 batch 有 128 張圖像。
接下來,我們就可以試圖理解我們的模型是如何隨著隱藏層大小而變化的了。我們可以訓練各種大小的模型,并查看性能如何變化,繪制結果。
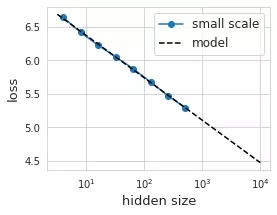
具有不同隱藏層體量的 8 個不同模型的性能(以藍色顯示)。擬合出來的線性回歸(黑色虛線)在理想情況下應該能夠預測給定隱藏層大小的損失。
你會發現,這數據看起來驚人地呈線性分布。太好了,我們找到了「規律」!我們可以用最小二乘法找到這種線性關系的系數:loss(hsize) = 7.0 - 0.275 log(hsize)。根據經驗,這似乎在隱藏層大小上保持了兩個數量級以上。
漂亮的插值讓人感到興奮,我們認為我們可以將隱藏大小外推一個數量級以上來訓練更大的模型。然而令人沮喪的是,我們發現實際情況下模型的性能大大偏離了預測曲線。
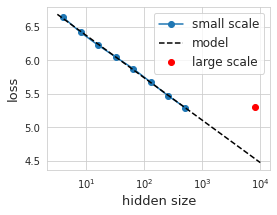
較大模型(紅色顯示)實現的性能非常差,并且大大低于我們對較小規模模型(黑色虛線)的預測。
在現實世界中,考慮到最近一段時間模型的體量,這樣的差錯可能會導致數千甚至上百萬美元。在大于 100 億的參數范圍內,進行任何形式的實驗來找出模型的錯誤幾乎是不可能的。
幸運的是,我們的示例工作規模很小,因此可以負擔得起對實驗進行詳盡無遺的測試——在這種情況下,我們可以運行 12 個模型大小,每個模型具有 12 個不同的學習率(每個有 3 個隨機初始化),共計 432 次試驗。
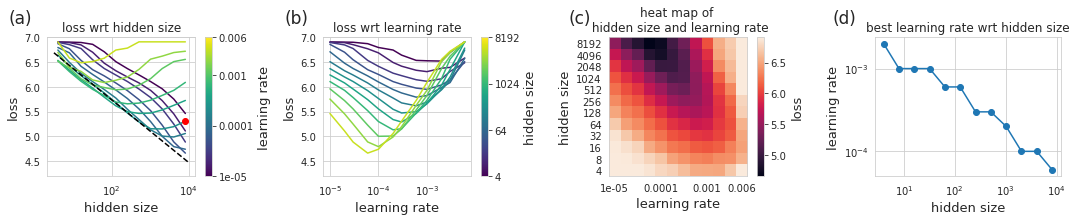
上圖展示了我們使用 12 種不同的學習率訓練 12 種不同模型大小的結果。每個小圖用了不同的表示方法。在 (a) 中展示了不同隱藏層大小實現的損失,學習率以彩色顯示——我們之前的推斷是使用單一的學習率。在 (b) 中,我們展示了給定學習率的損失,其中隱藏層數量以顏色區分。較大的模型達到較低的損失,但需要較小的學習率。在 (c) 中,我們展示了顯示學習率與隱藏層大小的熱圖,這里的每個像素都是完整訓練運行的結果。在 (d) 中,我們查看給定隱藏層大小的最佳學習率。
有了這些數據,故事就變得很清楚了,也就不足為奇了。隨著我們增加模型大小,最佳學習率會縮小。我們還可以看到,如果我們簡單地以較小的學習率進行訓練,我們將在給定模型大小下接近我們最初預測的性能。我們甚至可以對最佳學習率和模型大小之間的關系進行建模,然后使用這個模型來提出另一種預測。最佳學習率與隱藏層大小 (d) 的關系圖看起來是線性的,因此結合起來不會有太大的障礙。
即使有了這樣的修正,我們怎么知道這不是再次用一些其他超參數來實現的 trick,會在下一個隱藏大小的數量級上造成嚴重錯誤?學習率似乎很重要,但是學習率時間表呢?其他優化參數呢?架構決策呢?寬度和深度之間的關系如何?初始化呢?浮點數的精度(或缺乏)呢?在許多情況下,各種超參數的默認值和接受值都設置在相對較小的范圍內——誰能說它們適用于更大的模型?
隨著訓練大模型成為了學界業界的新潮流,模型體量擴展關系的問題似乎不斷出現。即使是簡單的事情,如使用此處所示的模型體量和學習率之比也并不總是能成功(例如為語言模型指定微調過程)。
在這里值得記住的是討論模型體量關系的論文《Scaling Laws for Neural Language Models》:https://arxiv.org/abs/2001.08361
其討論了很多問題如寬度、深度、體量、和 LR 之間的關系,還有 Batch size 大小的關系(https://arxiv.org/abs/1812.06162),但研究者也承認忽略了很多其他的問題。他們還討論了計算量和數據大小的關系,但在這里我們不討論或進行改變。
他們提出的縮放定律是在假設基礎模型是用性能最好的超參數訓練的假設下設計的。
所以對于潛在的誤導性推斷,我們能做些什么呢?在理想的情況下,我們將充分了解模型的各個方面如何隨比例變化,并利用這種理解來設計更大尺度的模型。沒有這一點,外推似乎令人擔憂,并可能導致代價高昂的錯誤。然而,考慮到有多少因素在起作用,要達到完全理解這一點是不可能的。考慮到計算成本,在每個尺度上調整每個參數看來并不是正確的解決方案。
那該怎么辦?一種潛在的解決方式是使用縮放定律來預測性能極限。隨著規模的擴大,如果性能偏離冪律關系,人們應該將其視為未正確調整或設置好的信號。聽說這是 OpenAI 經常使用的思路。換句話說,當擴展沒有按預期工作時,這可能意味著正在發生一些有趣的事情。知道該怎么做,或者要調整哪些參數來修復這種性能下降可能極具挑戰性。
在我看來,必須平衡使用縮放定律來推斷更大范圍的性能,并實際評估性能。從某種意義上來說,這是顯而易見的,它們只實踐中所做工作的粗略近似。隨著模型尺度研究的發展,我們希望這種平衡可以更加明確,并且可以更多地利用縮放關系來實現更多的小規模研究。
以這個特定的例子為例,雖然我們發現用固定的學習率進行簡單的性能預測并不能外推,但我們確實發現了模型大小和學習率之間的線性關系,這導致模型可以在測試的模型大小范圍內進行推測。如果我們嘗試推斷更大的模型,是否還有其他一些我們遺漏的因素呢?這是有可能的,不運行實驗很難知道。