創業公司就應該技術選型 Spring Cloud Alibaba , 開箱即用
大家好,我是Tom哥~
互聯網時代,面對復雜業務,講究 分而治之。將一個大的單體系統拆分為若干個微服務,保證每個系統的職責單一,可以垂直深度擴展。
但是一個個獨立的微服務像一座座孤島,如何將他們串聯起來,才能發揮最大價值。
這時,我們就要提微服務的生態圈。
那么微服務生態圈都有哪些模塊?他們的作用分別是什么?
服務的注冊、發現。生產者啟動時,會將自己的信息注冊上報,這樣調用方只需連接注冊中心,根據一定的負載算法,就可以與服務提供方建立連接,從而實現應用間的解耦。
- 服務調用。通過多種協議(如:HTTP等)實現目標服務的真正調用。
- 負載均衡。主要是提供多種負載算法,滿足不同業務場景下的集群多實例的選擇機制
- 服務的穩定性。提供了服務熔斷、限流、降級
- 分布式配置中心。應用的配置項統一管理,修改后能動態生效
- 消息隊列。非核心邏輯從同步流程抽離,解耦,異步化處理,縮短RT時間
- 網關。將一些通用的處理邏輯,如:限流、鑒權、黑白名單、灰度等抽取到一個單獨的、前置化系統統一處理。
- 監控。監控系統的健康狀況
- 分布式鏈路追蹤。查看接口的調用鏈路,為性能優化、排查問題提供輸入
- 自動化部署。持續集成,快速部署應用。
圍繞這些功能模塊,Spring Cloud Alibaba 為我們提供了微服務化開發的一站式解決方案,我們只需要少量的Spring 注解 和 yaml配置,便可以快速構建出一套微服務系統。真的是創業者的福音。
那么這套生態規范都提供了哪些技術框架呢?

一、Spring Boot(服務基座)
Spring Boot 是Spring框架的擴展,提供更加 豐富的注解,根據 約定勝于配置 原則,與市場主流的開源框架打通, 設計了 Starter 和 AutoConfiguration 機制,簡化配置流程,通過簡單的jar包引入,快速具備組件集成能力。大大提高了程序員的開發效率。
特點:
- 提供了豐富的注解,不要在XML文件中定義各種繁瑣的bean配置
- 內嵌 Web容器,如:Tomcat(默認)、Jetty、Undertow
- 集成了主流開源框架,根據項目依賴自動配置
二、Nacos(注冊中心、分布式配置中心)
Nacos 是阿里巴巴的開源的項目,全稱 Naming Configuration Service ,專注于服務發現和配置管理領域。
Nacos 致力于幫助您發現、配置和管理微服務。Nacos 提供了一組簡單易用的特性集,幫助您快速實現動態服務發現、服務配置、服務元數據及流量管理。功能齊全,可以替換之前的 Spring Cloud Netflix Eureka、Spring Cloud Config、Spring Cloud Bus,野心巨大。
客戶端語言方面目前支持 Java,go 、python、 C# 和 C++等主流語言
開源地址:https://github.com/alibaba/nacos
Nacos 有一個控制臺,可以幫助用戶管理服務,監控服務狀態、應用的配置管理。
集群化部署:
由于 Nacos 是單節點,無論做為注冊中心還是分布式配置中心,一旦服務器掛了,作為底層服務引發的麻煩還是非常大的。如何保證其高可用?
Nacos 官方提供的集群部署架構圖:
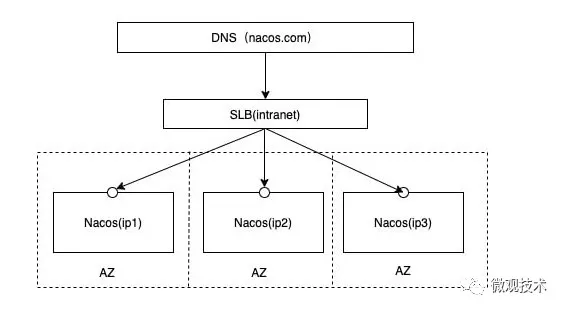
??https://nacos.io/zh-cn/docs/cluster-mode-quick-start.html??
在nacos的解壓目錄nacos/conf目錄下,有配置文件cluster.conf,每行配置成 ip:port。(一般配置3個或3個以上節點)
# ip:port
200.8.9.16:8848
200.8.9.17:8848
200.8.9.18:8848
這樣保證客戶端只需要寫一次,由 Leader節點將數據同步到其他節點,保證各個節點的數據一致性
對于上層的SLB,我們可以采用 Nginx 或者 OpenResty,在 upstream 模塊里配置 Nacos 的集群IP 地址列表,實現負載均衡功能。
另外,借助Nginx的心跳檢測,當某臺 Nacos 服務掛掉后,SLB 會自動屏蔽,將流量切換到其他 Nacos 實例。
當然 OpenResty 也可能成為單點故障,為了保證高可用,我們需要借助 Keepalived

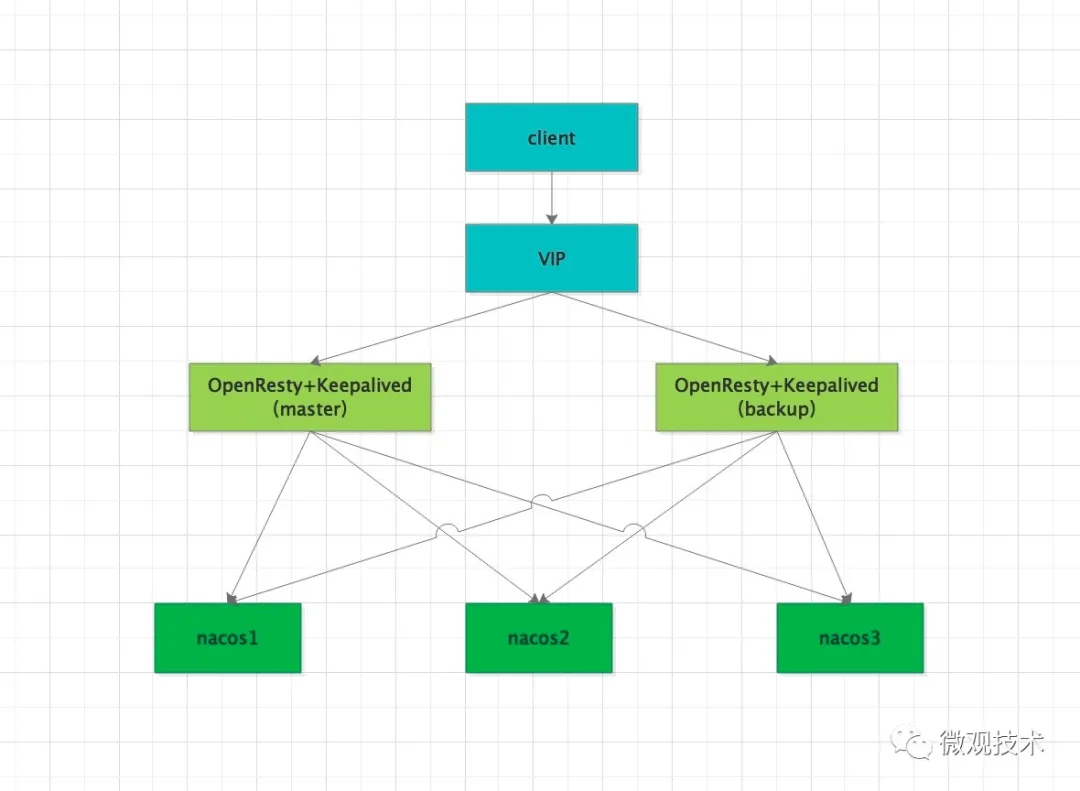
客戶端請求 VIP,然后請求打到了 OpenResty,由 OpenResty 轉發給具體的某個 Nacos 節點。
OpenResty 只有一個節點提供服務,另一個暫停狀態,如果 master 節點宕機,那 backup 接替繼續工作。從而解決了單點故障問題。
Keepalived 作為一種高性能的服務器高可用或熱備解決方案,用來防止服務器單點故障的發生。市面資料很多,下文鏈接是《Keepalived+Nginx部署方案》具體操作步驟
??https://help.fanruan.com/finereport/doc-view-2905.html??
三、RestTemplate + Ribbon (遠程調用)
Spring Cloud Ribbon 基于 Netflix Ribbon 封裝的負載均衡框架。內部集成了多種負載算法,如:隨機、輪詢等。
與注冊中心打通,能自動獲取服務提供者的地址列表。結合自身的負載算法,選擇一個目標實例發起服務調用。
Ribbon 也提供了擴展接口,支持自定義負載均衡算法。
public class CustomRule extends AbstractLoadBalancerRule {
private AtomicInteger count = new AtomicInteger(0);
@Override
public Server choose(Object key) {
return choose(getLoadBalancer(), key);
}
private Server choose(ILoadBalancer loadBalancer, Object key) {
List<Server> allServers = loadBalancer.getAllServers();
int requestNumber = count.incrementAndGet();
if (requestNumber >= Integer.MAX_VALUE) {
count = new AtomicInteger(0);
}
if (null != allServers) {
int size = allServers.size();
if (size > 0) {
int index = requestNumber % size;
Server server = allServers.get(index);
if (null == server || !server.isAlive()) {
return null;
}
return server;
}
}
return null;
}
}
缺點:
調用方每次發起遠程服務調用時,都需要填寫遠程目標地址,還要配置各種參數,非常麻煩,不是很方便
// 注冊到Nacos的應用名稱
private final String SERVER_URL = "http://nacos-provider-demo";
@Resource
private RestTemplate restTemplate;
@RequestMapping("/hello")
public String hello() {
// 遠程服務調用
return restTemplate.getForObject(SERVER_URL + "/hello", String.class);
}
四、OpenFeign(遠程調用)
RestTemplate + Ribbon 每次發起遠程服務調用時,都需要填寫遠程目標地址,還要配置各種參數,非常麻煩。
Feign 是一個輕量級的 Restful HTTP 客戶端,內嵌了 Ribbon 作為客戶端的負載均衡。面向接口編程,使用時只需要定義一個接口并加上@FeignClient注解,非常方便。
OpenFeign 是 Feign 的增強版。對 Feign 進一步封裝,支持 Spring MVC 的標準注解和HttpMessageConverts
依賴包:
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-openfeign</artifactId>
</dependency>
@FeignClient(value = "${provider.name}")
public interface OrderService {
// 調用服務提供者的 /create_order 接口
@RequestMapping(value = "/create_order",method = RequestMethod.GET)
public String createOrder();
其中,@FeignClient(value = "${provider.name}") 定義了服務提供方的工程名,底層自動打通了注冊中心,會拿到 artifactId 對應的IP列表,根據一定的負載均衡算法,可以將請求打到目標服務器上。
OpenFeign 默認等待接口返回數據的時間是 1 秒,超過這個時間就會報錯。如果想調整這個時間,可以修改配置項 feign.client.config.default.readTimeout
五、Dubbo Spring Cloud(遠程調用)
RestTemplate + Ribbon 和 OpenFeign 都是基于HTTP協議調用遠程接口。而 Dubbo Spring Cloud 是基于 TCP 協議來調用遠程接口。相比 HTTP 的大量的請求頭,TCP 更輕量級。
Dubbo Spring Cloud = Spring Cloud + Dubbo
特性:
- 支持多種注冊中心,用于服務的注冊、發現
- 內置多種負載均衡策略
- 服務粒度是面向接口,支持 TCP 輕量級協議
- 容易擴展,采用 微內核 + 插件 的設計原則,擴展點更強
依賴包:
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-starter-dubbo</artifactId>
</dependency>
注意:雖然是將 Dubbo 集成到了 Spring Cloud,增加了一些 注解 和 yaml 配置項,開發更方便,但大部分調用玩法還是遵守 Dubbo 框架那一套。
幾個重要的配置項:
- dubbo.scan.base-packages # dubbo 服務掃描基準包,上報注冊服務
- dubbo.protocol.name: dubbo # 支持的協議
- dubbo.protocol.port: -1 # dubbo 協議端口( -1 表示自增端口,從 20880 開始)
- dubbo.registry.address # 注冊中心地址
六、Spring Cloud Gateway(網關)
分布式時代,一個復雜的系統被拆分為若干個微服務系統,每個系統都配置獨立的域名肯定不合適。為了解決這個問題,網關便誕生了。
網關充當反向代理的角色,作為流量的第一入口,承載了很多基礎的、公共的模塊功能,如:流控、鑒權、監控、路由轉發等。

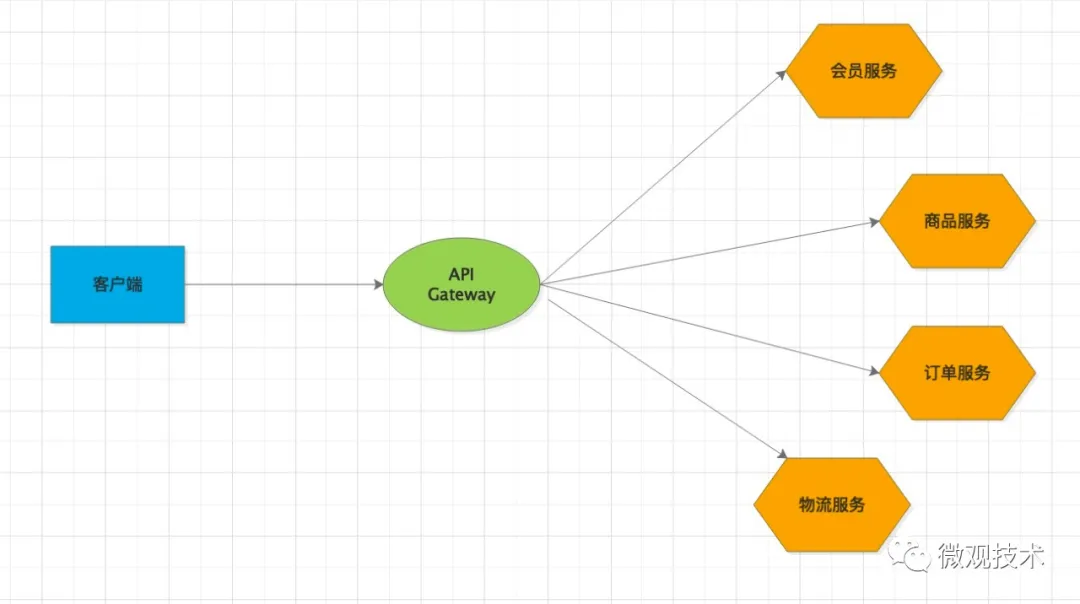
Spring Cloud 生態早期的網關是 Netflix 公司的Zuul,后來Zuul社區停止了維護。官方后來推出了 Spring Cloud Gateway,其底層是基于 WebFlux 框架,而WebFlux框架的底層采用高性能通訊框架 Netty,性能是 Zuul 的 1.6 倍。
核心組件:
1、路由。
內部主要是負責轉發規則。
2、斷言(Predicate)
如果返回為true,當前路由才有效,才會路由到具體的服務。官方提供了很多內置路由斷言,如果滿足不了你的訴求,也可以自定義路由斷言工廠。
所有的路由斷言工廠都是繼承自 AbstractRoutePredicateFactory,自定義類的命名也有固定規則,“配置名”+RoutePredicateFactory。這樣,在yaml配置時,只需要寫前面定義的配置名即可。
3、過濾器(Filter)
主要是請求、響應之間增加一些自定義的邏輯。按作用范圍分為:全局和局部。全局是作用于所有的路由;而局部只是作用于某一個路由。
跟上面的斷言類似,除了官方提供的過濾器,也支持自定義。
局部過濾器:繼承自 AbstractGatewayFilterFactory,自定義類的命名也有固定規則,“配置名”+GatewayFilterFactory。這樣,在yaml配置時,只需要寫前面定義的配置名即可。
全局過濾器:實現GlobalFilter,Ordered 兩個接口,實現邏輯跟上面的局部過濾器類似。這里就不展開了。其中的 Ordered 接口主要是負責優先級,數值越小,優先級越高。
依賴包:
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-gateway</artifactId>
</dependency>
yaml 的配置示例:
spring:
cloud:
gateway:
routes: #路由,可配置多個
- id: user_route # 路由id 唯一即可,默認是UUID
uri: lb://user-server-sample # 匹配成功后提供的服務的地址
order: 1 # 路由優先級,數值越小優先級越高,默認0
predicates:
- Path=/user/** # 斷言,路徑匹配進行路由
# - User=0, 1000 # 自定義路由斷言工廠 只允許查詢id為0 - 1000之間的用戶
# - Method=POST # 表示需要POST方式請求
# - Query=id, \d+ # 參數名id,正則表達式為\d+(一個或多個數字)
filters:
- AddRequestHeader=X-Request-token, 12345678 #為原始請求加上請求頭及值
當然,服務提供方的地址可能經常變化,為了動態感知,我們引入 Nacos 注冊中心,用于服務的注冊、發現,統一管理服務的IP地址。網關路由轉發時,只需從 Nacos 動態獲取即可。
七、Sentinel(熔斷、限流、降級)
Sentinel 是阿里開源的流控框架,提供了簡單易用的控制臺,比 Hystrix支持的范圍更廣。
集成簡單,只需要少量配置,即可快速接入,支持如:gRPC、Dubbo、Spring Cloud 等
同類競品框架:
- Hystrix 框架已經停止維護;
- Resilience4j 一種輕量級容錯庫,專為 Java 8 和函數式編程而設計。通過裝飾器的方式,以使用斷路器,速率限制器,重試或隔板來增強任何功能接口,lambda 表達式或方法引用。
流控規則:
頁面元素介紹:
資源名:唯一即可
針對來源:對調用者限流,填寫應用名稱(Spring.application.name的值),只針對某個服務限流
閾值類型
- QPS:每秒接收的請求數
- 線程數:能使用的業務線程數
流控模式
- 直接:達到條件后,直接執行某個流控效果
- 關聯:如果訪問關聯接口B達到了閾值,則讓接口A返回失敗
- 鏈路:記錄從入口資源的流量,達到條件也只限流入口資源
流控效果
- 快速失敗:直接返回失敗結果
- Warm Up:預熱,開始有一個緩沖期,初始值 = 閾值/ codeFactor(默認 3),然后慢慢達到設置的閾值
- 排隊等待:讓請求以均勻的速度通過,如果請求超過閾值就等待,如果等待超時則返回失敗
降級規則:
- RT
- 異常數
- 異常比例
系統規則:
流控規則和降級規則是針對某個資源來說的,而系統規則是針對整個應用的,粒度更大,當前所有的接口服務都會應用這個系統規則。
授權規則:
根據調用方判斷調用的接口資源是否被允許,如:黑名單、白名單機制
熱點規則:
將粒度進一步細化,可以針對方法的參數做規則控制,為每個參數設置單獨的閾值,也可以多個參數組合。從而實現單個方法的熱點流量,按業務需求進一步控制。
@SentinelResource注解
@SentinelResource 注解可以根據實際情況定制化功能,跟 Hystrix 的 @HystrixCommand 注解功能類似。達到閾值后,系統的默認提示是一段英文,很不友好,所以我們要自定義兜底方法。
// 資源名稱為handle1
@RequestMapping("/handle1")
@SentinelResource(value = "handle1", blockHandler = "blockHandlerTestHandler")
public String handle1(String params) {
// 業務邏輯處理
return "success";
}
// 接口方法 handle1 的 兜底方法
public String blockHandlerTestHandler(String params, BlockException blockException) {
return "兜底返回";
}
注意:@SentinelResource注解中,除了blockHandler字段外,還有fallback字段
- blockHandler:主觀層面,如果被限流,則調用該方法,進行兜底處理
- fallback:對業務的異常兜底,比如,執行過程中拋了各種Exception,則調用該方法,進行兜底處理
通過上面兩層兜底,可以讓Sentinel 框架更加人性化,體驗更好。
集群流控:
單機限流很容易做,但是互聯網很多應用都是集群部署,畢竟其下游還掛載著 mysql、或者其他微服務,為了防止對下游的大流量沖擊,采用集群流控。防止單機的流量不均勻, 理想下 QPS = 單機閾值 * 節點數
八、Seata(分布式事務)
事務的原子性和持久性可以確保在一個事務內,更新多條數據,要么都成功,要么都失敗。在一個系統內部,我們可以使用數據庫事務來保證數據一致性。那如果一筆交易,涉及到跨多個系統、多個數據庫的時候,用單一的數據庫事務就沒辦法解決了,此時需要引入分布式事務
Seata 是一款開源的分布式事務解決方案,致力于提供高性能和簡單易用的分布式事務服務。Seata 將為用戶提供了 AT、TCC、SAGA 和 XA 事務模式,默認 AT 模式 ,為用戶打造一站式的分布式解決方案。
優點:
- 對業務無侵入:即減少技術架構上的微服務化所帶來的分布式事務問題對業務的侵入
- 高性能:減少分布式事務解決方案所帶來的性能消耗

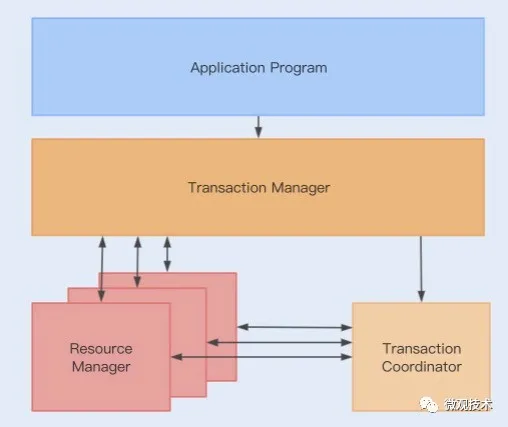
Seata有3個基本組成部分:
- 事務管理器(TM):定義全局事務的范圍:開始全局事務,提交或回滾全局事務。
- 事務協調器(TC):維護全局事務和分支事務的狀態,驅動全局提交或回滾。
- 資源管理器(RM):管理正在處理的分支事務的資源,與TC對話以注冊分支事務并報告分支事務的狀態,并驅動分支事務的提交或回滾。
運行流程:
- TM 向 TC 申請開啟一個全局事務,全局事務創建成功并生成一個全局唯一的 XID
- XID 在微服務調用鏈路的上下文中傳播
- RM 向 TC 注冊分支事務,TC 返回分支事務ID ,并將其納入 XID 對應全局事務的管轄
- RM 執行本地業務表操作,并記錄 undo_log 日志,提交本地事務
- 當所有的 RM 都執行完后,TM 向 TC 發起針對 XID 的全局提交或回滾決議
- TC 調度 XID 下管轄的全部分支事務完成提交或回滾請求。如果提交,刪除 undo_log 日志就可以了。如果是回滾,根據 undo_log 表記錄逆向回滾本地事務,把數據還原,最后再刪除 undo_log 日志。
關于 Seata 之前寫過很多文章,這里就不展開了,感興趣可以看看
- 業務無侵入框架Seata, 解決分布式事務問題
- 深度剖析 Seata TCC 模式【圖解 + 源碼分析】
- 七種分布式事務的解決方案,一次講給你聽
九、Spring Cloud Stream (異步消息)
Spring Cloud Stream 是統一消息中間件編程模型的框架,屏蔽了底層消息中間件的差異。支持的MQ 框架有 RabbitMQ、Kafka、RocketMQ 等
常用注解:
- @Input:標記為輸入信道,消費消息
- @Output:標記為輸出信道,生產消息
- @StreamListener:監聽某個隊列,接收消息,處理自身的業務邏輯
- @EnableBinding:綁定通道
依賴包:
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-starter-stream-rocketmq</artifactId>
</dependency>
綁定通道:
@SpringBootApplication
@EnableBinding({CustomSource.class})
public class StreamProduceApplication {
public static void main(String[] args) {
SpringApplication.run(StreamProduceApplication.class, args);
}
}
定義輸出信道:
public interface CustomSource {
@Output("output1")
MessageChannel output1();
}
yaml 配置:
spring:
cloud:
stream:
rocketmq:
binder:
name-server: 127.0.0.1:9876 # rocketMq服務地址
bindings:
output1:
producer:
transactional: true # 事務
group: myTxProducerGroup # 事務分組
bindings:
output1:
destination: test-transaction-topic # 主題
content-type: application/json # 數據類型
發送消息:
@Service
public class SendMessageService {
@Resource
private CustomSource customSource;
public String sendMessage() { //發送簡單字符串消息的方法
String message = "字符串測試消息";
// 發送消息
customSource.output1().send(MessageBuilder.withPayload(message).build());
return "發送成功!";
}
}
十、SkyWalking(分布式鏈路追蹤)
SkyWalking 是 一款 APM(應用性能監控)系統,專為微服務、云原生架構、容器(Docker、k8s、Mesos)而設計。通過探針收集應用的指標,進行分布式鏈路追蹤,感知服務間的調用鏈路關系。
特性:
- 支持告警
- 采用探針技術,代碼零侵入
- 輕量高效,不需要大數據平臺
- 多個語言自動探針。包括 Java,.NET Core 和 Node.JS。
- 強大的可視化后臺


- 上部分 Agent :負責從應用中,收集鏈路信息,發送給 SkyWalking OAP 服務器。目前支持 SkyWalking、Zikpin、Jaeger 等提供的 Tracing 數據信息。而我們目前采用的是,SkyWalking Agent 收集 SkyWalking Tracing 數據,傳遞給服務器。
- 下部分 SkyWalking OAP :負責接收 Agent 發送的 Tracing 數據信息,然后進行分析(Analysis Core) ,存儲到外部存儲器( Storage ),最終提供查詢( Query )功能。
- 右部分 Storage :Tracing 數據存儲。目前支持 ES、MySQL、Sharding Sphere、TiDB、H2 多種存儲器。而我們目前采用的是 ES ,主要考慮是 SkyWalking 開發團隊自己的生產環境采用 ES 為主。
左部分 SkyWalking UI :負責提供控臺,查看鏈路等等。
SkyWalking 部署起來還是很簡單的,apache官網直接下載并解壓即可。
??https://skywalking.apache.org/??
SkyWalking 快速入門手冊:
??https://skywalking.apache.org/zh/2020-04-19-skywalking-quick-start/??
十一、XXL-JOB(分布式任務調度)
關于定時任務,相信大家都不陌生。但是單節點的定時任務有很多不足:
- 不支持集群,如果同時部署多個節點,會競爭數據,造成數據重復
- 如果是單節點,宕機后,任務無法自動感知、重啟
- 不支持任務失敗重試
- 不支持執行時間的動態調整
- 無報警機制
- 無任務數據統計功能
- 不支持數據分片
無論是集群化,還是周邊的生態建設,都不完備。而 XXL-JOB,可以完美解決這些問題。
XXL-JOB 是一款分布式任務調度框架,依賴的組件少(僅依賴 Java 和 MySQL),開箱即用。并提供了可視化界面,統計任務數據,動態修改任務執行時間,內置郵件報警,支持任務分片和任務失敗重試。
核心模塊:
1、調度中心
本身不執行業務邏輯,只負責向執行器發送調度命令。
2、執行器
接收調度中心的請求,并執行業務邏輯。
依賴包:
<dependency>
<groupId>com.xuxueli</groupId>
<artifactId>xxl-job-core</artifactId>
<version>2.2.0</version>
</dependency>
yaml 配置:
server:
port: 8082 #程序端口
xxl:
job:
admin:
addresses: http://127.0.0.1:8002/xxl-job-admin # 調度中心地址,多個用逗號分開
accessToken: # 調度中心和執行器通信的token,如果設置,兩邊要一樣
executor:
appname: xxl-job-executor-sample #執行器名稱
address: # 執行器地址,默認使用xxl.job.executor.address配置項,如果為空,則使用xxl.job.executor.ip + xxl.job.executor.port
ip: # 執行器IP
port: 9989 #執行器端口,與調度中心通信的端口
logpath: D:/work/Spring-Cloud-Alibaba/sample/logs # 日志保存路徑
logretentiondays: 30 # 日志保留天數
XxlJobSpringExecutor 初始化:
@Bean
public XxlJobSpringExecutor xxlJobExecutor() { // XXL-JOB執行器初始化
XxlJobSpringExecutor xxlJobSpringExecutor = new XxlJobSpringExecutor();
xxlJobSpringExecutor.setAdminAddresses(adminAddresses);
xxlJobSpringExecutor.setAppname(appname);
xxlJobSpringExecutor.setAddress(address);
xxlJobSpringExecutor.setIp(ip);
xxlJobSpringExecutor.setPort(port);
xxlJobSpringExecutor.setAccessToken(accessToken);
xxlJobSpringExecutor.setLogPath(logPath);
xxlJobSpringExecutor.setLogRetentionDays(logRetentionDays);
return xxlJobSpringExecutor;
}
我們可以采用 BEAN 模式, 使用 @XxlJob 注解描述代碼。優點:適用于一些復雜的業務場景。
也可以采用 GLUE 模式,將 執行代碼 托管到調度中心在線維護。優點:簡單快捷,不需要單獨的業務工程。
如果要處理的數據量較大時,我們可以采用分片處理機制,將任務均攤到每個節點,從而減輕單個節點的壓力。
shardingVO.getIndex() # 當前執行器的分片序號(從0開始)
shardingVO.getTotal() # 總分片數,執行器集群的數量
# dataSource 待處理的所有原始數據
for (Integer val : dataSource) { // 遍歷代理
if (val % shardingVO.getTotal() == shardingVO.getIndex()) { // 取余
//TODO 歸屬于當前分片處理
}
}
XXL-JOB 快速入門手冊:
??https://www.xuxueli.com/xxl-job/??
巨人肩膀:
《Spring Cloud Alibaba 微服務實戰》