在線“殺死” App 的卡頓難題!
原創
ANR(Application Not Response)是安卓開發團隊經常遇到的無響應問題,但卻很難定位和根除。尤其是線上問題,由于難以復現,導致開發者難以有效地快速解決。為此,本?將為大家分享作者是如何在?個?內降低 50% 的 ANR 線上問題發?率的探索與實踐,希望能對開發者有所幫助或啟發。
Google 的一項內部研究表明,過高的崩潰與 ANR 發生率會直接影響應用的評分情況,并且很難在商店中累積起用戶量,嚴重影響應用在商店的排名情況。這一系列的連鎖反應將會給應用帶來很大的損失,且有可能失去在應用商店獲得谷歌推薦的資格。因此,ANR 問題對于?多數安卓團隊來說十分棘手,尤其是線上問題令人頭疼。因為本地問題可以復現,線上 ANR 卻很難。因而探究線上 ANR 問題的治理?案更具意義。
觸因與流程分析
1. 關于 ANR
從用戶側看, ANR 問題是指?戶在使?應?過程中出現了嚴重卡頓或卡死時,系統給出的?響應提示彈窗。而從系統側看,ANR 問題就是 AMS 在執?特定?法時出現的超時錯誤,觸發點有四個:
- InputDispatching Timeout
- BroadcastQueue Timeout
- Service Timeout
- ContentProvider Timeout
系統的 ANR 觸發流程?致可分為兩個部分:
?戶可以直觀感受到的 ANR 彈窗,這部分由 AMS 處理。
同時 AMS 還會發出?個 SIGQUIT 信號: SignalCatcher 線程會接收到這個信號,并且處理后續的 dump 邏輯;市?上的 ANR 錯誤收集 SDK?部分都依賴于這個原理。
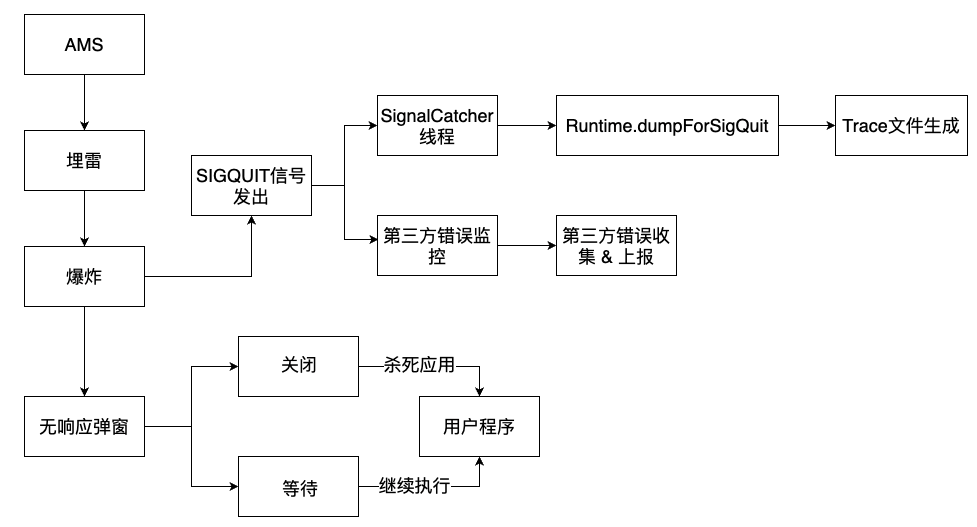
2. 現狀與挑戰
根據美圖秀秀 Android 端的線上監控數據表現, ANR 問題?乎是崩潰問題的兩倍。在這種情況下,?先要考慮的就是如何將問題數量降低,然后再考慮后續?案。
?對大批問題,?先就是對數據進?分析、歸類和梳理以便找出頭部問題。美圖秀秀的線上頭部問題分布如下:
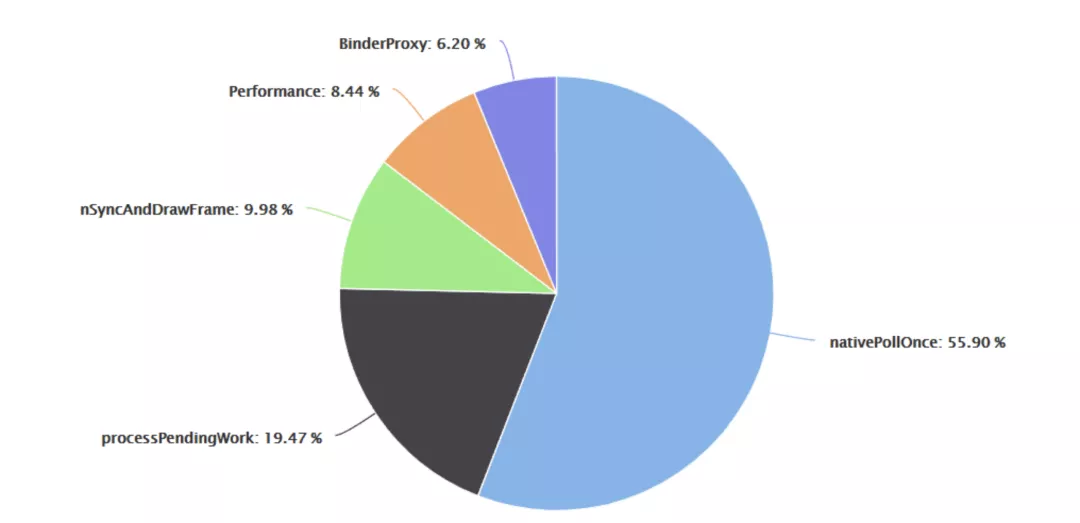
這些問題經過簡單分析后,得出了如下結論:
nativePollOnce 問題,暫時不能依賴現有的?志信息得出結論。不過其占?較?,要放在?優先級處理。processPendingWork 問題已經有可靠的處理?案。占?不低,應該放在較?的優先級處理。
剩余問題數量相近,所以處理順序并不固定。
分析與實踐
在分析具體問題之前,?先跟?家分享?下筆者在處理問題過程中總結的?些經驗。
我們遇到的絕?部分問題,都可以分為兩類:
有源問題:是指可以直接溯源、定位到的問題;有源問題通常可以直接解決,其處理結果直接影響到線上的某個指標(如:相應問題的發?次數,發?率等等)
?源問題:問題成因不定且沒有確定的線索;?對?源問題更多時候需要“?膽假設,??求證” 。通常?源問題需要更多的現場信息以及側?證據來溯源。成功溯源之后的?源問題可轉換成?個或 多個有源問題。
當?系列問題有了明確的優先級以及分類之后,我們就可以開始分析單體 Case 了。
1. MessageQueue.nativePollOnce 問題
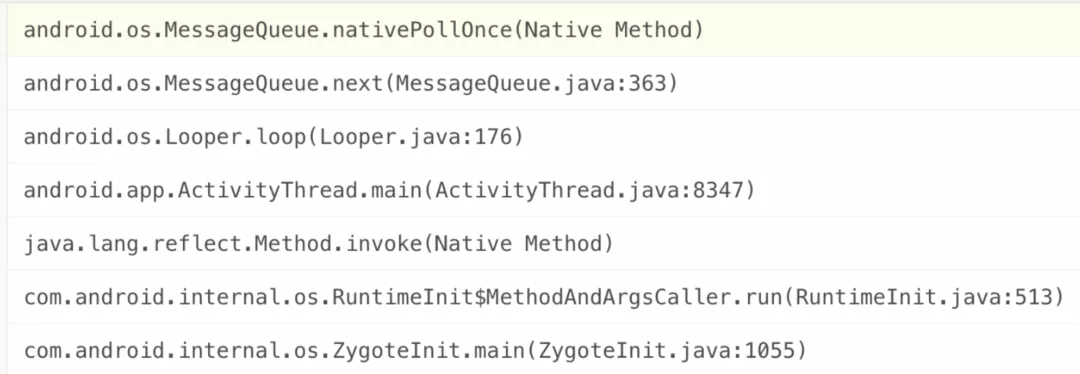
線上上報的堆棧如上圖所示。棘手之處在于:如果只看上報的堆棧和錯誤?志,很難排查出問題的根本原因。上?提到過,處理這類問題要“?膽假設”,其可能的原因有:
- 主線程狀態異常導致“停頓”
- 卡頓堆棧漂移
- 其他未知原因
- 有了假設之后,就需要“??求證”了:
- 假設主線程異常,那么因何產??
- 假設卡頓堆棧漂移,那么真實的卡頓堆棧在哪??
1.1 主線程卡死情況
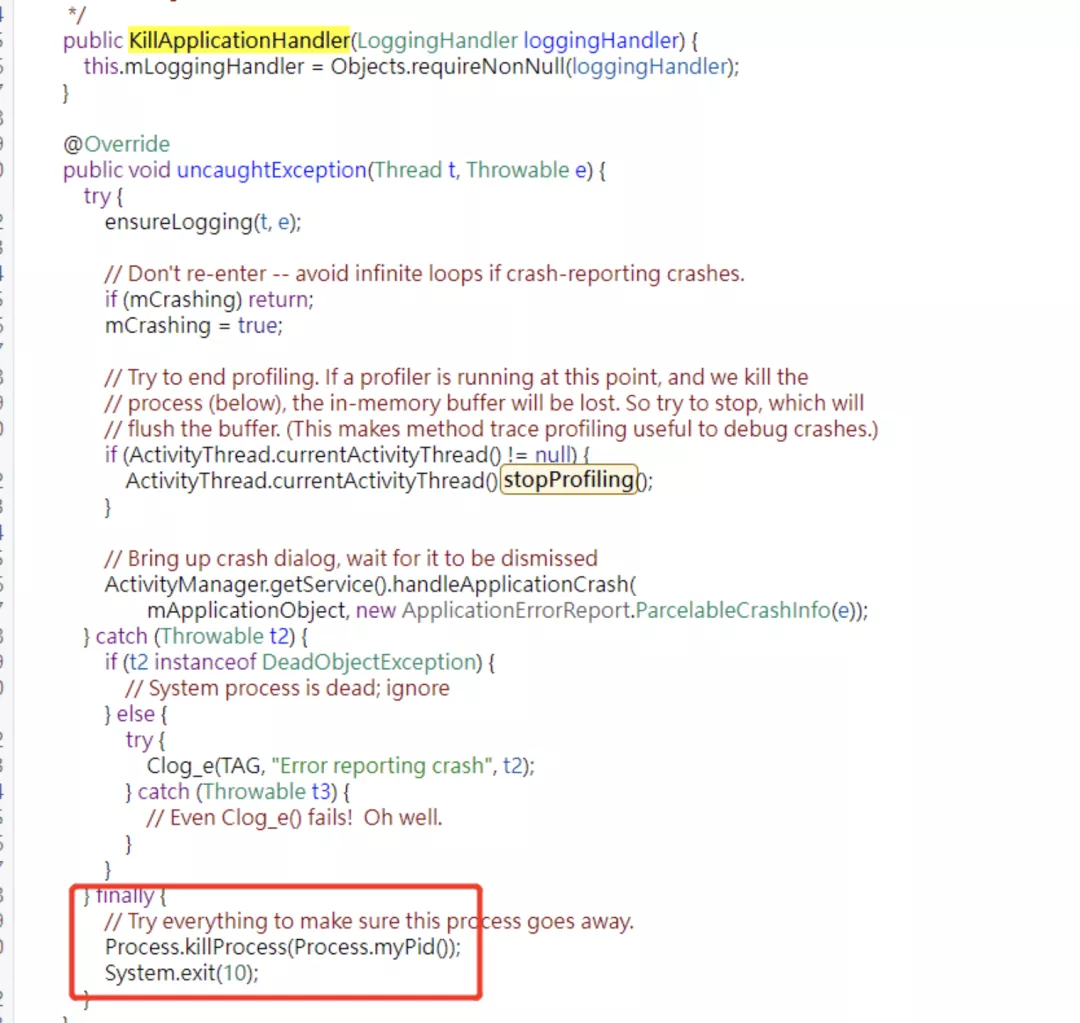
Android 應?啟動過程中有這樣的?段邏輯:zygote 初始化 →RuntimeInit 初始化。在 RuntimeInit 初始化過程中會注冊?個默認的錯誤處理器來響應異常,如下所示:

默認的異常處理機制會在線程發? Crash 時同步給 ActivityThread、ActivityManagerService 之后再“kill”掉?身。
那么如果當主線程發?異常的情況下,不使?系統的處理鏈路或異常處理過程中耗時過久就會發? ANR。當主線程發?了崩潰后其實已處于終?狀態。此時主線程 Looper 的 MessageQueue 組件?法繼續添加新的消息,? Android 應?的運?恰恰依賴的就是主線程的消息輪詢 -- 線上這個錯誤堆棧也是指向了 MessageQueue 組件在等待新消息的到來。因此,當主線程發?異常并?法及時 kill 掉進程時,系統就 會觸發 ANR 超時機制。按照以上的邏輯推斷,我們通過埋點找出了線上異常處理鏈的各個?法耗時數據:
通過對?各個異常處理?法的耗時可以發現,Firebase 異常分析 SDK 在異常處理鏈路中耗時最?。預計移除此組件可降低該問題的發?數量。
最終在去除 Firebase 異常分析 SDK 的版本上線之后,線上數據顯示整體的 ANR 率都有所下降。
接下來分析另?種情況:
1.2 卡頓堆棧漂移
在這種情況下,錯誤上報中的卡頓堆棧已經失真,?法反映出當時現場的真實的情況。因此,增加線上的慢函數監控可以更準確地分析此問題。
線上慢函數監控的原理:
查看 Looper 的源碼得知:主線程所有執?的任務都在 Looper.loop() ?法中的 msg.target.dispatchMessage 中派發執?。在這?有個 Printer 組件分別在消息的執?前、后會 有?個打印的?法調?。可通過 Looper.setMessageLogging ?法設置?個 Printer ,來監控每 個 Message 的執?時間:

監控邏輯的關鍵代碼:

在后期,我們通過這種?式獲得了以下慢函數數據:
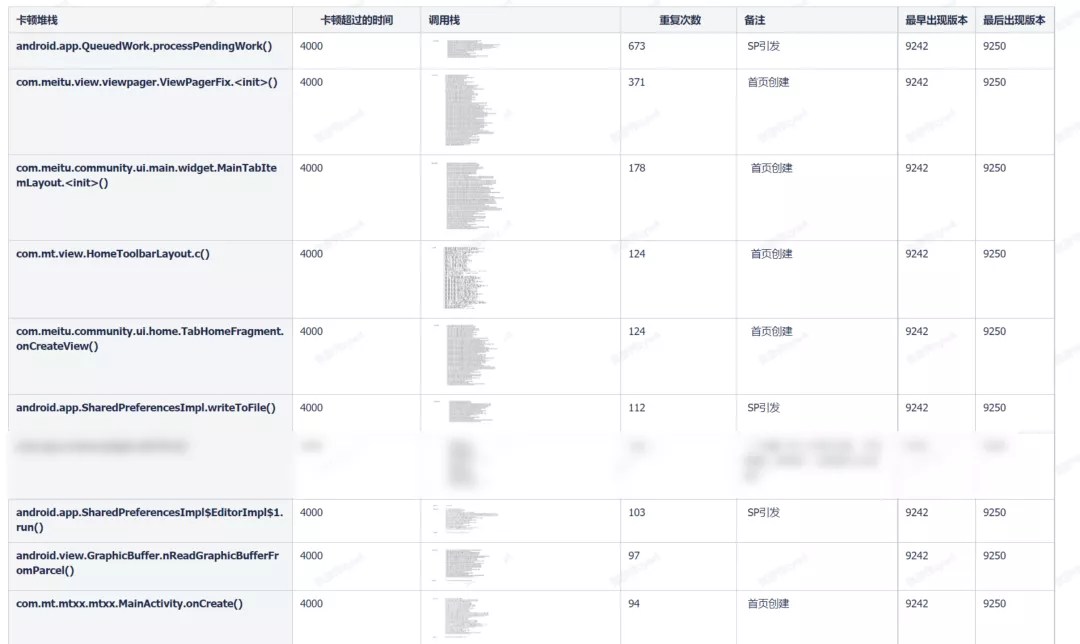
整理后得到的分布數據:
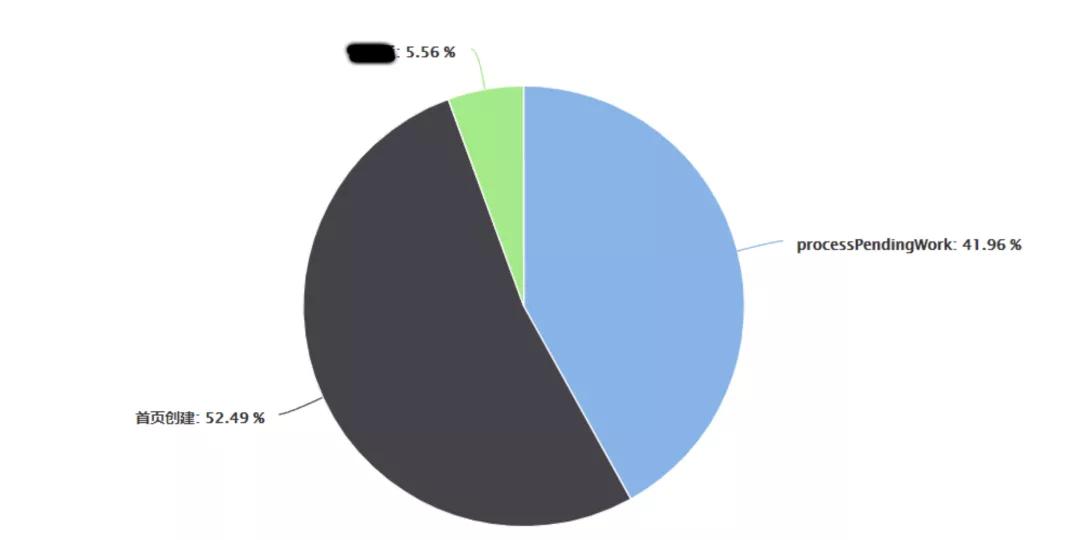
不難得出:
【QueuedWork.processPendingWork】、【??創建】類型的問題占?最?,必須優先處理。下?將詳細分析這兩個問題。
回到上?錯誤處理的思路中:
此問題的處理中,使?了通?的?源問題處理?案。通過 【假設 -> 驗證 -> 上線 ->數據變化 】這?流程,最終減少了此問題的發?或轉換成了有源問題。當然,這個問題的誘因不只以上兩個猜想,還有更多的可能需要進?步探索。
2. QueuedWork.processPendingWork 問題處理
問題調?棧:
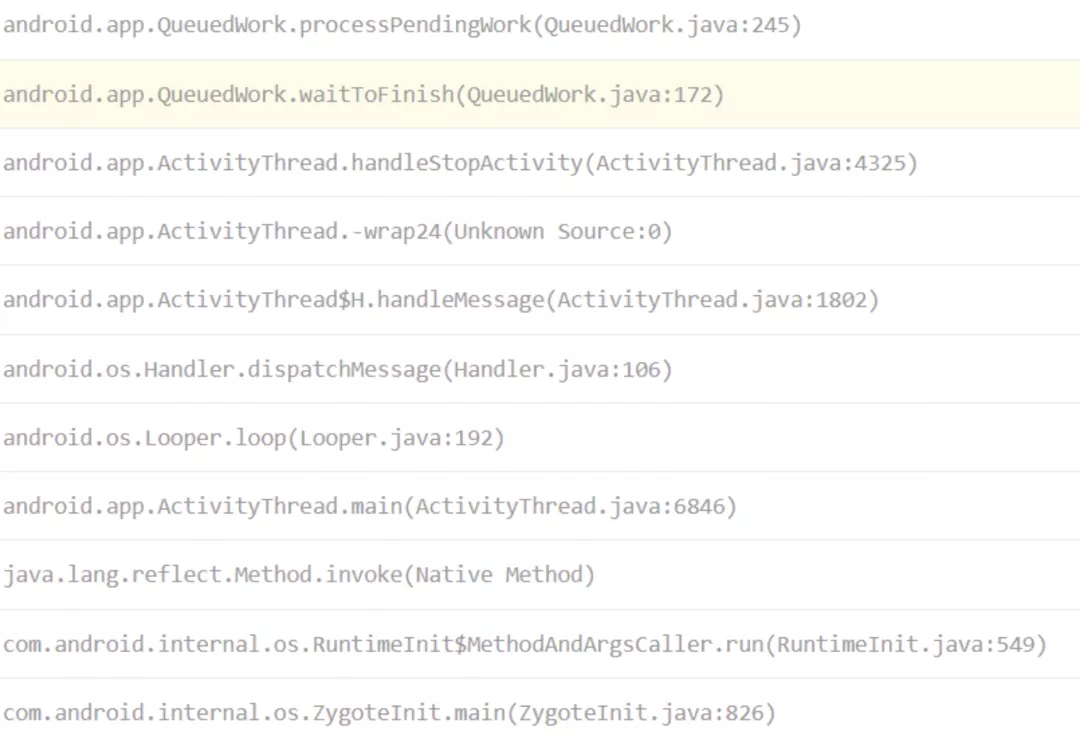
對 AndroidFrameWork 源碼接觸較少的同學們,可能并不了解這個類的作?。這時候可以借助 Android 源碼搜索引擎來?看究竟:
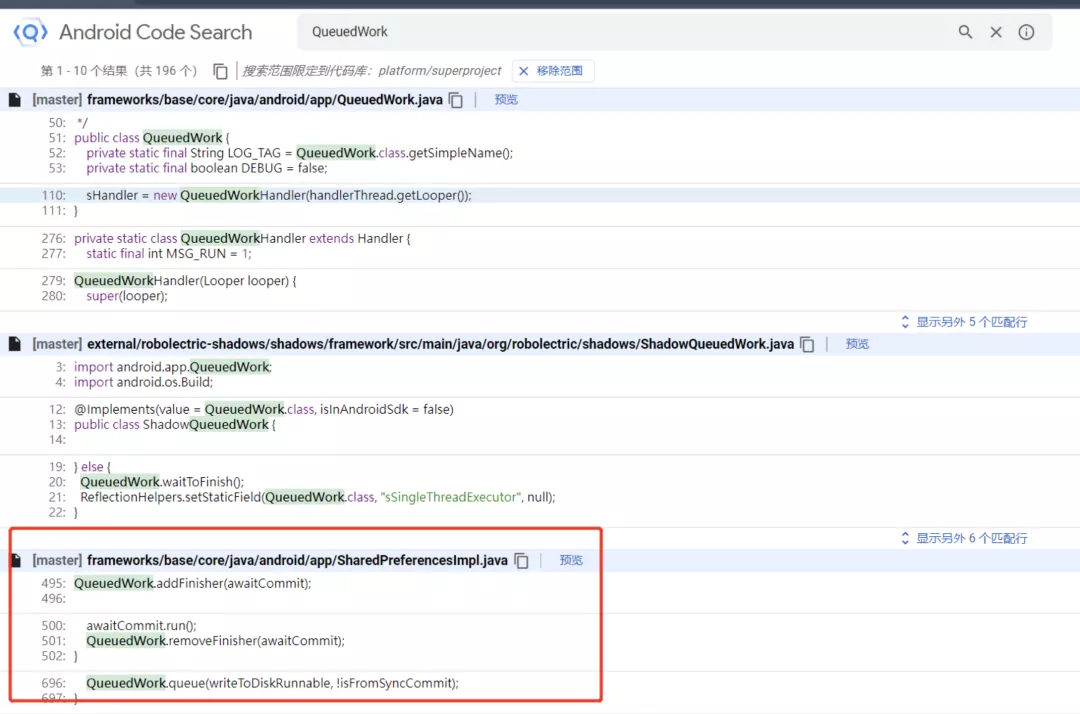
通過對源碼的分析,可以得出?個?致流程:
SharedPreferencesImpl.apply() ?法中調? QueuedWork.add() 將 SharedPreferences 的寫 ?任務添加進 QueuedWork 的任務隊列中,之后 ActivityThread 在?些組件?命周期?法中執?了 QueuedWork.waitToFinish → QueuedWork.processPendingWork 這?流程。這?個?命周期方法有:
- handleStopService
- handlePauseActivity
- handleStopActivity
- handleSleeping
以上的?命周期?法都會先等待 QueuedWork 中的異步隊列執?完成,再執?后續的流程。
很容易得出這樣的結論:SharedPreferences 的 apply ?法本身設計為異步寫?,?Android 系統為了保證數據有效性會在特定的?命周期?法中等待異步寫?任務的完成。如果這個任務處理耗時過?,就會產? ANR 問題
美圖秀秀內部開發了?款代碼的織??具 MtAjx 。其類似于?家熟知的 AspectJ ,相? AspectJ ?案, 有著更好的兼容性(司內?批項?編譯遇到 AspectJ 的問題)以及更?性化的 API 設計。
在處理這個問題時,我們使?了 MtAjx 來攔截 SharedPreferences 的創建,并返回帶?志輸出功能的 SharedPreferencesWrapper 。
簡化的流程如下:
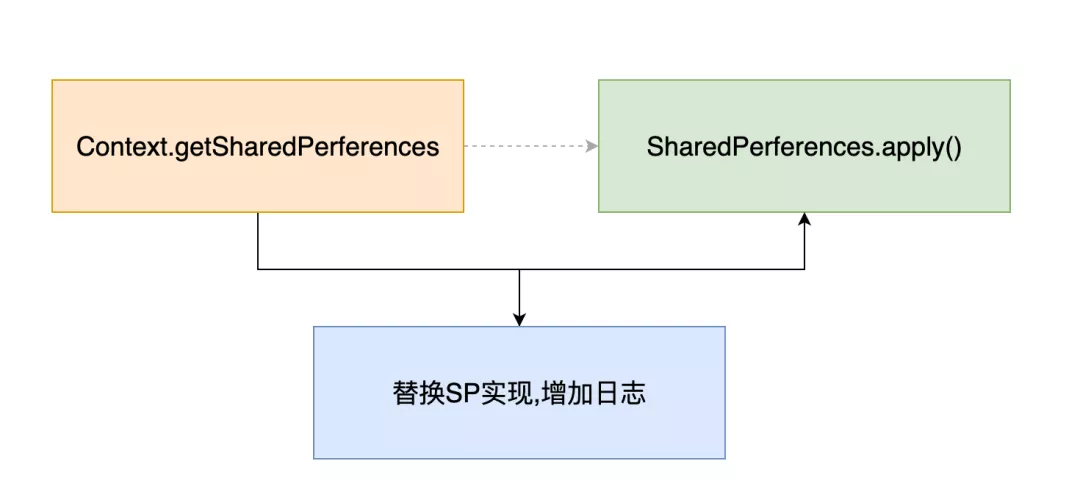
要完成上?的功能,使? MtAjx 只需要編寫?些簡單的規則即可實現:
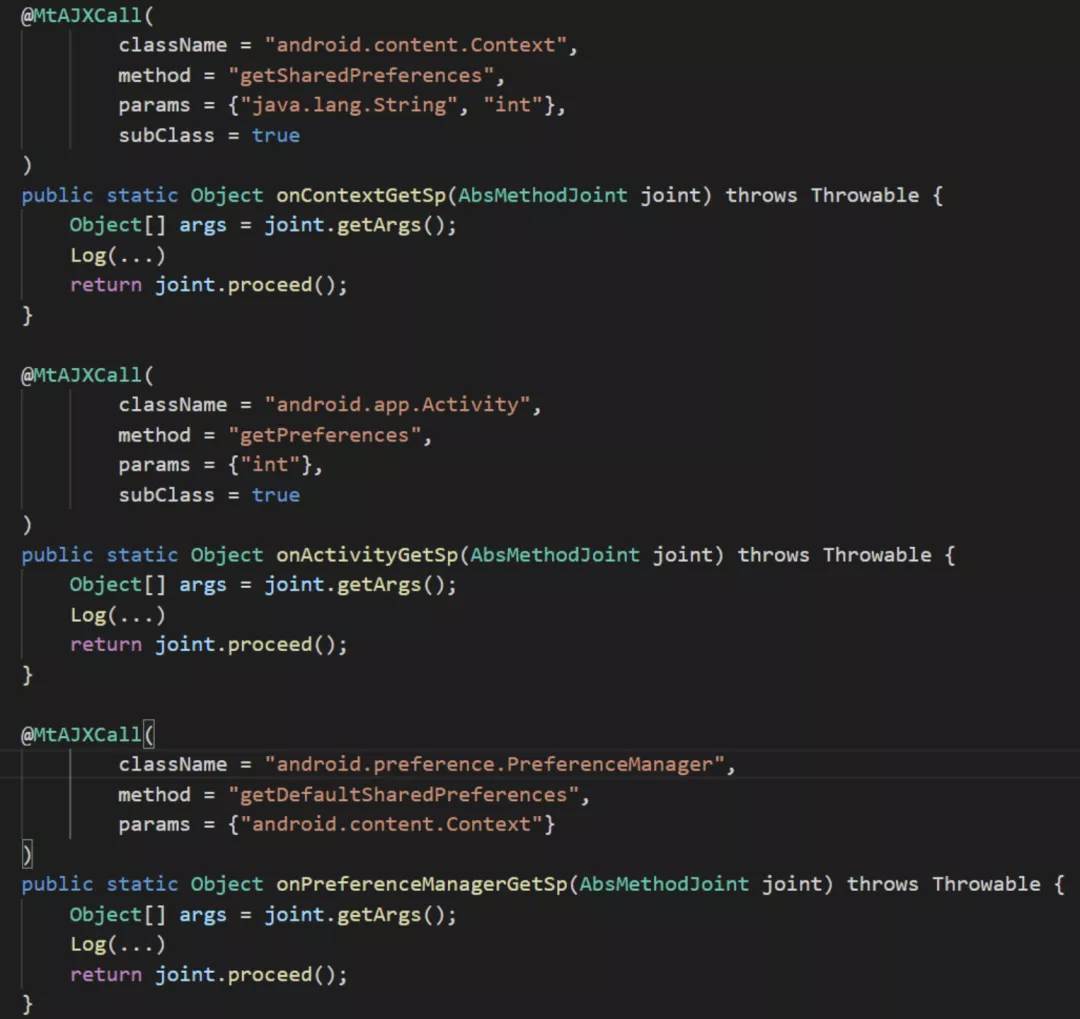
接下來可采??動化測試來模擬線上?戶的真實操作,并通過 SharedPreferencesWrapper 的?志對SharedPreferences 寫?頻率進?分析。
最終輸出的數據如下:
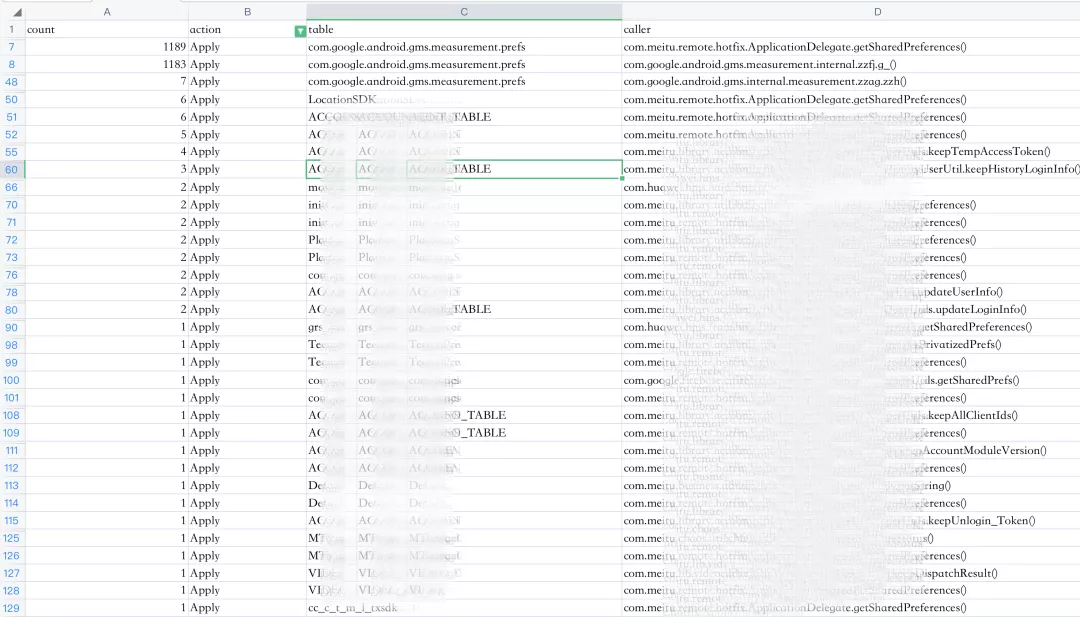
?前收集的線索可以推斷出: GMS 組件的某個操作,?量地調?了 SharedPreferences 的 apply ?法。這個操作可能會使 SharedPreferences 的異步寫?任務創建過多從?導致 ANR。后期處理此問題時,我們對這個組件進?了改造:使? MtAjx 在 GMS 中攔截 SharedPreferences 的創建、獲取操作, 并返回?個安全的 SharedPreferences 實現。?然上線之后,得到的數據跟預估的有些差距:
?身問題減少的?例很?
線上整體 ANR 波動不?
猜測這個問題發?時系統的 IO 負載已?分嚴重,處理部分場景可能收益并不?。于是之后上線了全量的 SharedPreferences 替換來避免此問題發?。
請注意,這?的“全量”并?真正的全量替換,?是排除了?些可能會受到影響的調?。?部分都只涉及 業務,這?不作為核?展開討論;使?“安全的” SharedPreferences 實現只是規避問題,其根本還 是需要降低系統負載。
處理全量 SharedPreferences 替換的處理的?法與?志輸出的流程類似。也采?了 MtAjx ?案來攔 截 SharedPreferences 的創建,并返回?個安全的實現。
此處為了容災,線上做了在線開關作為全量替換的整體控制策略來規避未知?險。
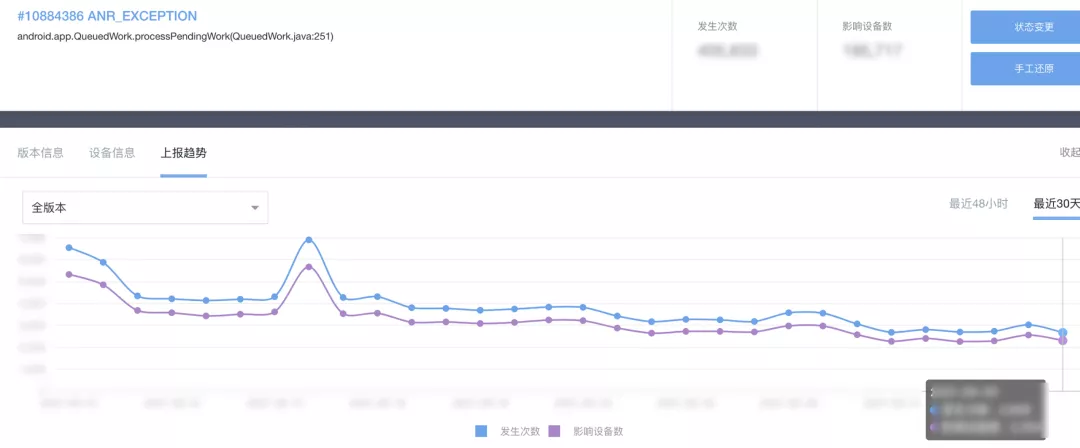
最終,這個策略上線之后,上述問題整體降低了 60%-70%,詳見下圖:
3. 首頁創建問題處理
這個問題是通過前?提到的慢函數數據分析發現的。經過堆棧類聚分析之后,關聯到了線上的兩個指 標:
- 慢函數——關聯了四個問題。
- ANR——關聯了 N 個問題,?且問題很分散。
其中,慢函數問題多發?在某些 View 的初始化過程中。下?是?些線上觸發此問題的點:
- ViewPagerFix.()
- MainTabItemLayout.()
- MainActivity.onCreate()
- HomeTopHeaderLayout.
篩選出上述問題的最終調?棧如下:

所有的卡頓點都落在 Runtime.loadLibrary0() 這個調?上。
線上 ANR 或者慢函數的數據表現也近乎?致:都是?通機型、低端機較多。
經過分析得知,?通機型存在?個 BoostFramework 組件?于加快應?的響應速度:類似的機制 可以在 特定情況下提升調度優先級、CPU 頻率,從?加快應?的響應速度。
但在某些情況下,這種機制會導致應?發?卡頓:BoostFramework 初始化依賴?個 so 的加載。?Runtime.loadlibrary0 是?個 synchronize 修飾的函數,多線程調?必然會存在鎖競爭情況。
美圖秀秀在啟動過程中,存在著?量“異步”加載 so 的操作。如果?線程先于主線程進? Runtime.loadLibrary0 ?法,拿不到鎖的主線程就會等待?線程釋放鎖之后再繼續執?。也就是說,如果某個?線程中存在著耗時較久的 so 加載?為,就會阻塞主線程的 so 加載。
?前 so 的加載時間還是盲區,?法針對性地去處理這個問題。與之前 SharedPreferences 問題處理的思路?樣:使? MtAjx 攔截 System.loadLibrary() ?法并輸出其耗時,最后得到如下數據(部分):
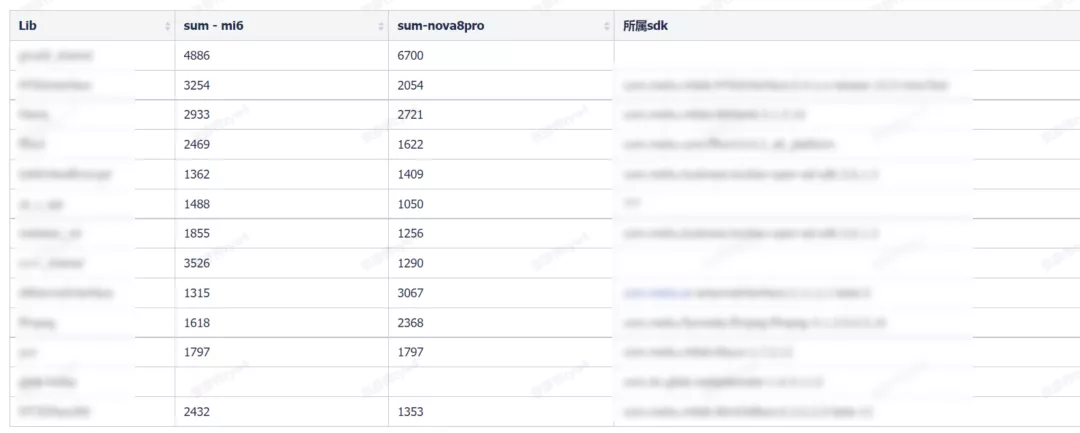
從數據上看,某些 so 加載確實消耗了不少時間。要解決此問題,?前初步的?案有:
盡量降低異步 so 加載對主線程 so 加載產?的影響
嘗試 Hack ?通平臺的 BoostFramework,讓其延遲加載或提前加載
列舉出可以執?的?案如下:
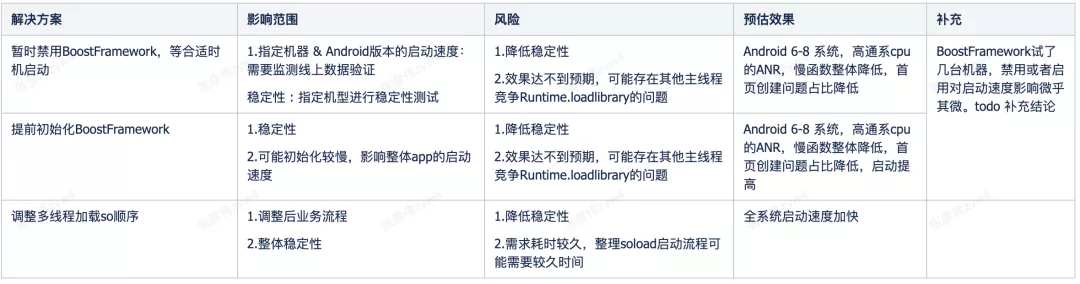
最終上線的?案:
- 延遲執?異步任務中的 so 加載
- ?通平臺的 BoostFramewok 加速在合理的時間啟動
對這種系統 Hack,必要的容災還是要做。這?與之前的?案?樣,通過在線開關去決定 BoostFramework 加載時機。
采?最終?案上線之后,得出了?些線上的數據:
- 關聯 ANR 問題發?數降低 50%
- 低端機啟動速度提升 13%
- 低端機 ANR 率降低,最?幅度在 50%
復盤 2、3 兩個問題,都經歷了類似的處理過程:
- 分析:這?包括對問題的根本原因、原理、發?場景全鏈路進?完整分析
- 建模:指將問題直觀地“數據化”。如SharedPreferences 的讀寫頻次分析、 so 加載中的加載時常數據分析、以及線上的慢函數、ANR 數據變化。
- 預估:列舉現有?案的優劣對?,以及可能產?的影響,容災措施等
- 驗證:最終結果和預估時的進?對?,是否影響到線上關聯問題的核?指標。
4. BinderProxy 問題處理
線上 Binder 問題的堆棧表現多種多樣,不過其最終調?點都是android.os.BinderProxy.transactNative() 方法。
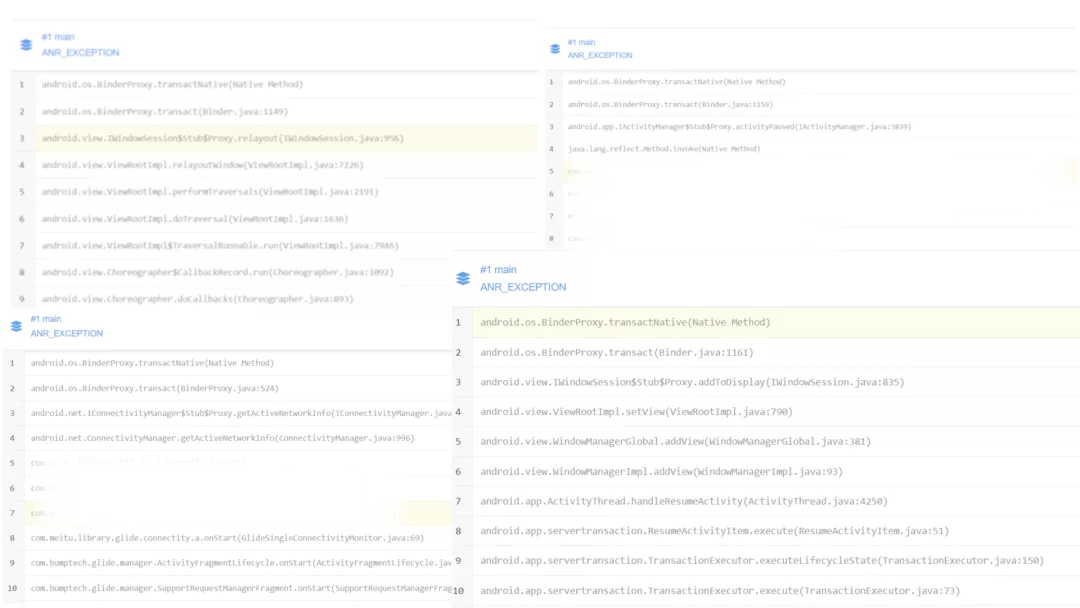
經過分析、查閱資料后,初步得出結論。當出現此類問題時,系統或應?基本都處于以下這些狀態:
- Binder 本地資源耗盡
- 遠程服務被頻繁調?,致使遠程服務負載過?
- 其他資源耗盡情況
這個問題的處理思路跟前?的?較類似:?先是收集不同場景下的 Binder 調?數據,然后針對數據進 ?分析、評估是否存在不合理場景。
不同于之前的例?:Binder 問題最終完全發?在系統層,?法通過 MtAjx 進?攔截。因此,換?種? 式:通過 NativeHook 可以攔截所有的 Binder 調?,從?獲取到 Binder 調?運?期的數據。此處選 擇了 BinderProxy.transact() 作為攔截點:
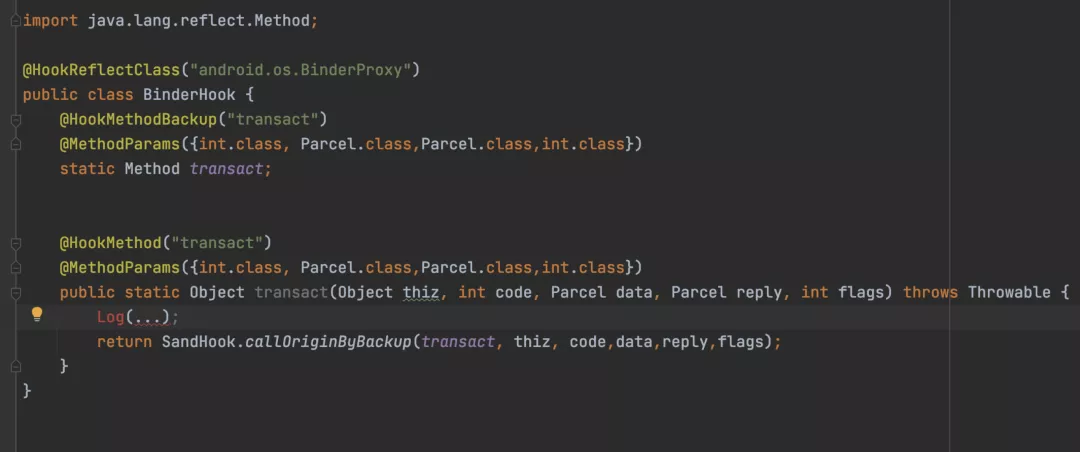
仍然采??動化測試來模擬線上?戶的使?情況并輸出?份?志,分析后得到如下數據(部分):
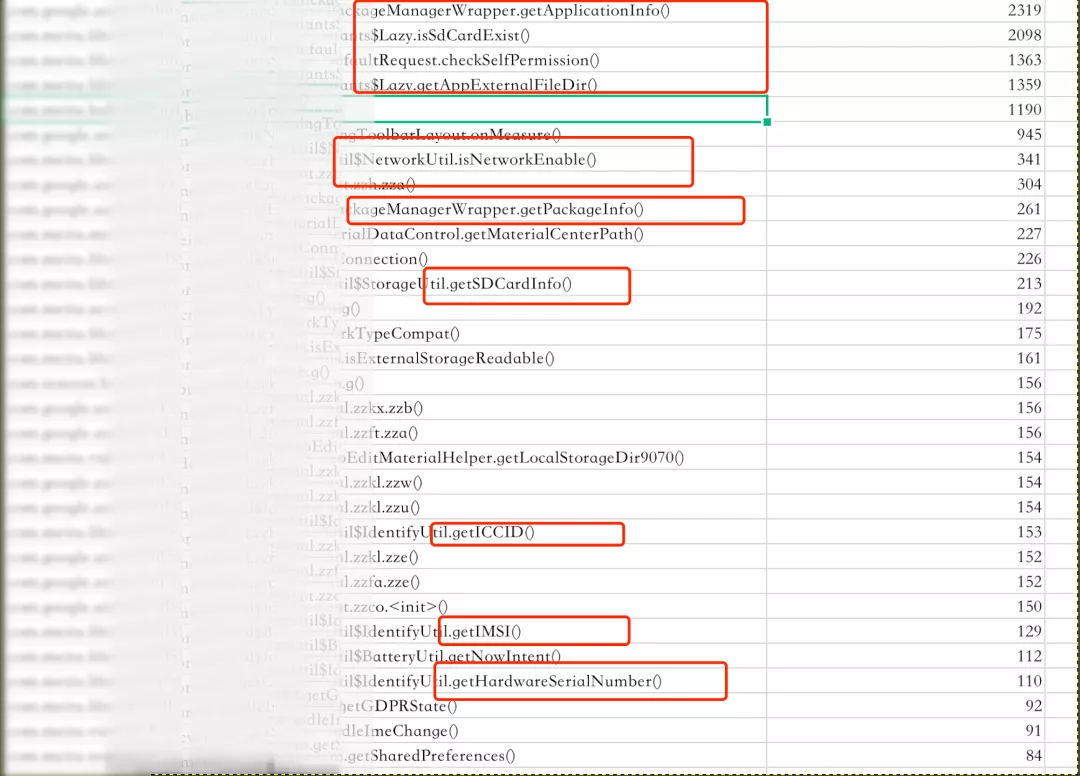
數據反映出了?系列問題:
- 頻繁獲取本身 package 信息:如 versionName,versionCode
- 頻繁獲取設備信息:如 IMEI,IMSI,?卡地址
- 頻繁?絡類型檢測,?絡狀態檢測
- 頻繁訪問本地?錄
- 頻繁權限檢測
這些?法的調?頻率都出現了異常(有些甚?超過了 View 繪制)。通過匯總整理,輸出?份最終修改結論和建議,供內部或者第三?去修改問題:
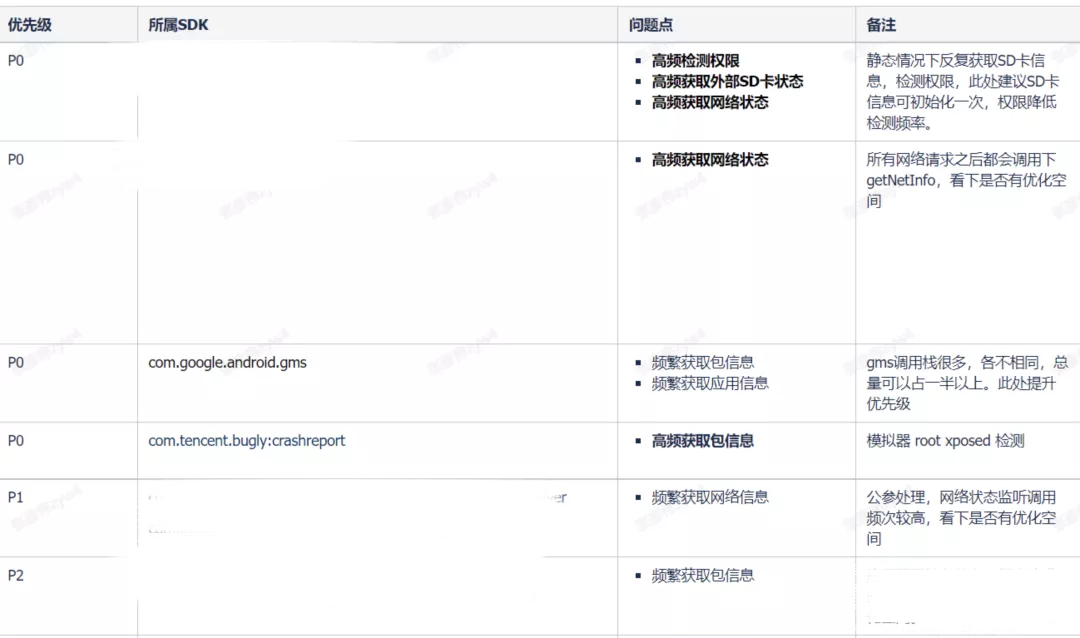
以上這些問題經過處理,整體 ANR 問題的發?都有?定程度地降低。所以,?部分 ANR 問題并?單體問題,通常降低整個應?的負載亦可降低整體 ANR 問題的發?率。
復盤思考
經過?整?的問題處理之后,通過復盤得出以下?系列思考。
1. 風險控制
在?險存在的時候,通常有以下?種做法:
本地容災策略
異常發?的時候,?適應去熔斷某些功能并上報。這個途徑?論從效率還是從?戶體驗上來講,都是最 好的。不過本地化意味著通常需要各種規則,各種條件去約束。所以?部分情況下這并不是最好的選擇。
在線開關控制
在觀測到異常數量上升(?為、報警)之后,通過在線開關關閉相應的功能。?前最常?的?法,在? 部分場景下都能適?。
熱修復補丁
在觀測到線上異常之后,通過下發熱修復補丁來避免問題的擴?。不過部分設備、渠道可能會失效。
發布緊急版本
迫不得已情況下使?的下策:緊急版本?論從修復效率還是從?戶體驗來講,都是?較糟糕的選擇。
2. 保持數據的準確 & 完整
完善的基礎數據建設更有助于發現問題
筆者之前接?公司另?個業務的性能優化需求時,發現該業務線的應?并沒有采集線上 ANR 指標,這部分在當時來看完全屬于盲區,并且根本?法評估有多少?戶流失與此關聯。
單?維度的數據,只能反映部分事實,能互相佐證的多維度的數據才更可信
?如性能問題中:ANR 數據、慢函數數據、甚?于啟動時?都能相互印證。
3. 別忽視了“蟻穴”
小問題積累到爆發再填坑,往往會耗費更多的精?。
之前公司內部的 AOP 處理?直使? AspectJ ,前期遇到的問題始終在通過加各種規則去規避。在后期問題爆發的時刻,?開發?套 AOP ?案耗費的??會更多。
沒有外?約束下,?個穩定的系統會逐漸地熵增,從?陷?混亂狀態,代碼也是?樣。
質量差的代碼不僅會拖慢研發效率,?且會增加各種各樣的穩定性隱患。平時不注意的細節會在上百萬、上千萬的?戶?前成倍放?。?如主線程的?次 IO 操作:很多?都覺得“? Kb 的數據?已,沒什么?不了的”,可事實真的是這樣嗎?
未來探索
?論過去、現在還是未來, ANR 問題的處理始終是?項具有挑戰的任務。依靠過去的經驗可以避免?些常見的問題,但是面向未來,還需要探索更多的?式去定位和解決問題。
1. 自研性能監控平臺
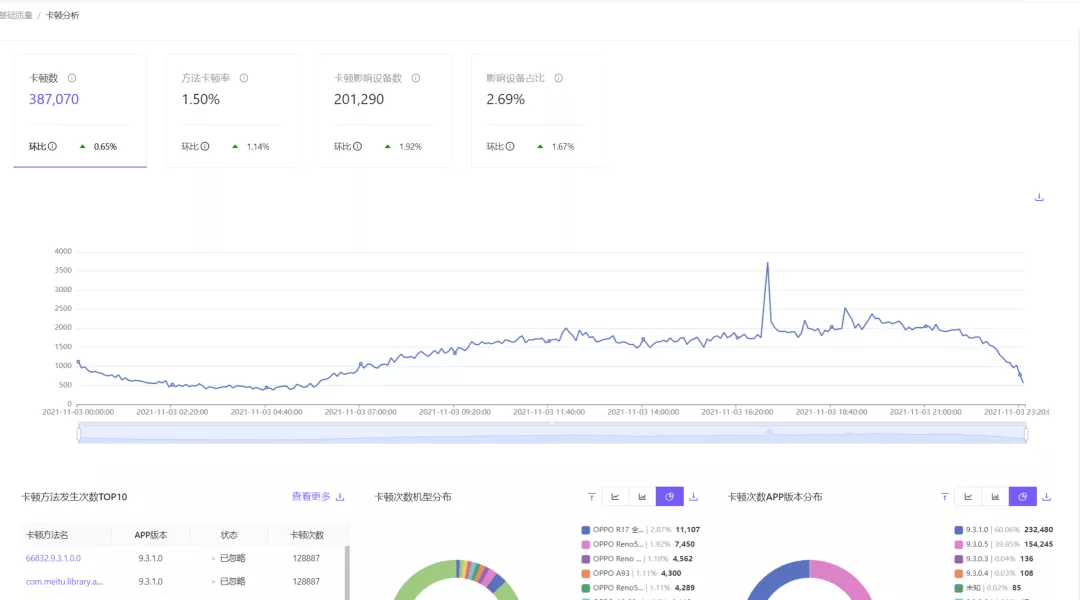
發現、預警,到 Bug 跟進,可以將整個開發和交付流程串聯起來。這將是未來性能優化?作的??利器。
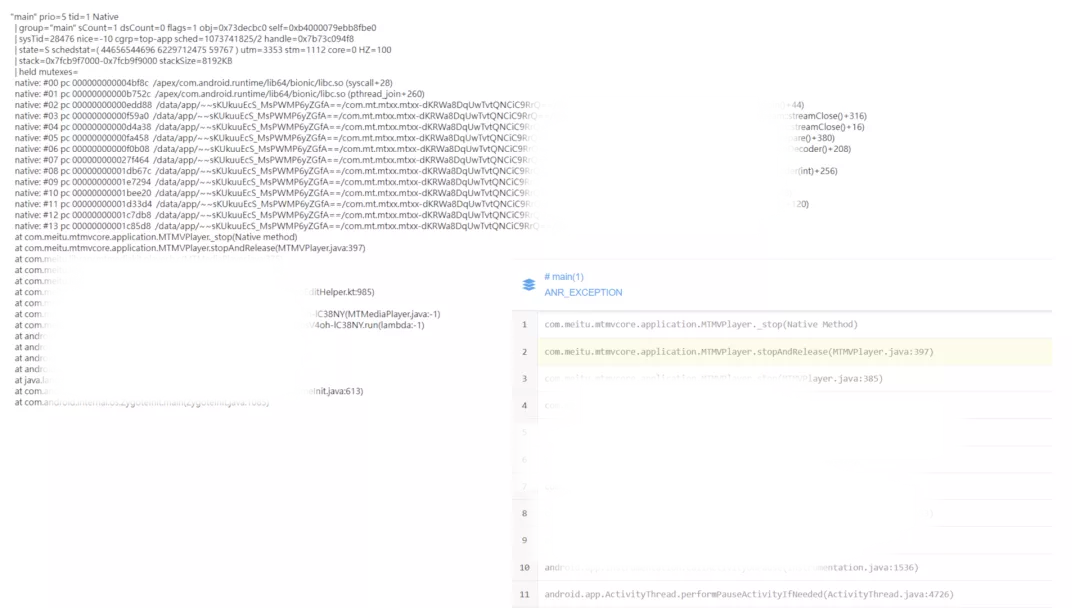
2. 抽樣上報的詳細 ANR?志
通過對? Bugly 和 XCrash 上報的 ANR ?志,可以看出 XCrash 上報的信息更適合開發同學進?問題定位。在后期,我們將 XCrash 接?作為?個抽樣的上報?案以補充 ANR 數據,為定位問題提供更有價值的信息。
3. 業務異常關聯數據分析
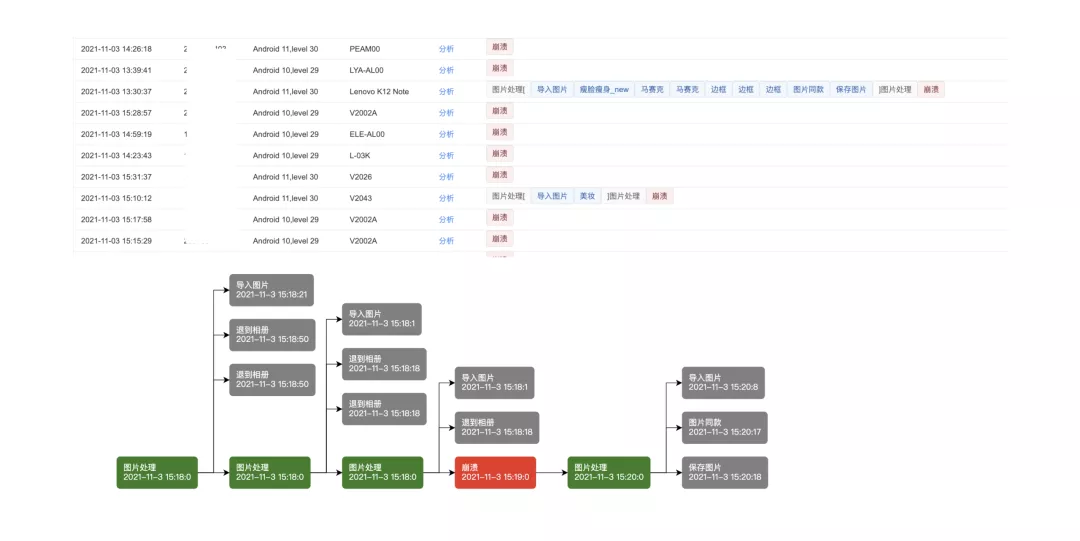
通過對核?業務的操作路徑和線上的異常數據關聯,可以發現?些平時容易被忽略的問題定位?法。我們關聯了圖?處理的業務與 ANR 或 Crash 的發?時間節點,來定位 ANR 或 Crash 是否與某個業務組件相關聯。
結語
ANR 問題并?單體問題。?部分 ANR 問題只是結果,其中的誘因千奇百怪,?中所述僅只是冰???。后續團隊還需要不斷地去解決新的問題,并持續地將已處理問題歸納、總結、規范,進而才能推?使?,更好地治理 ANR 問題。
注:
?中描述的 MtAjx 暫未公開,如有需要可使? AspectJ 代替
?中?量的經驗來源于前?貢獻;?平有限難免存在紕漏 -- 如有問題歡迎隨時與我交流:i@zhan gyanwei.com
專家介紹
作者張彥偉,美圖秀秀 Android 專家。2019 年加入美圖,現負責美圖秀秀 Android 端優化工作。美圖秀秀是 2008 年 10 月 8 日由廈門美圖科技有限公司研發、推出的一款免費影像處理軟件,全球累計超 10 億用戶,在影像類應用排行上長期保持領先優勢。