什么是 Azure Synapse,它與 Azure Data Bricks 有何不同?
zure Synapse Analytics 是一項針對大型公司的無限信息分析服務,它被呈現為 Azure SQL 數據倉庫 (SQL DW) 的演變,將業務數據存儲和宏或大數據分析結合在一起。
在處理、管理和提供數據以滿足即時商業智能和數據預測需求時,Synapse 為所有工作負載提供單一服務。后者通過與 Power BI 和 Azure 機器學習的集成而成為可能,因為 Synapse 能夠使用 ONNX 格式集成數學機器學習模型。它提供了處理和查詢大量信息的自由度.作為微軟在西班牙為數不多的 Power BI 合作伙伴之一,在 Bismart,我們在使用 Power BI 和 Azure Synapse 方面擁有豐富的經驗。
Azure Synapse 分析如何工作?
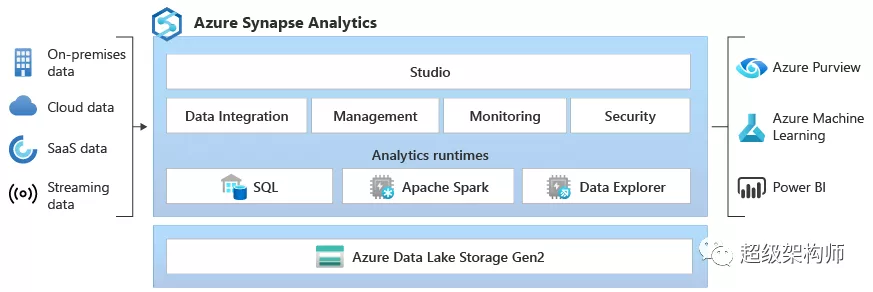
微軟的服務是SaaS(軟件即服務),可以按需使用,只在需要的時候運行(這對成本節約有影響)。它有四個組成部分:
- 具有完整基于 T-SQL 的分析的 SQL 分析:SQL 集群(按計算單位付費)和 SQL 按需(按處理的 TB 付費)。
- Apache Spark 完全集成。
- 具有多個數據源的連接器。
Azure Synapse 使用 Azure Data Lake Storage Gen2 作為數據倉庫和包含管理、監視和元數據管理部分的一致數據模型。在安全領域,它允許您保護、監視和管理您的數據和分析解決方案,例如使用單點登錄和 Azure Active Directory 集成。基本上,Azure Synapse 完成了整個數據集成和 ETL 過程,它不僅僅是一個普通的數據倉庫,因為它包括該過程的進一步階段,使用戶還可以創建報告和可視化。
在編程語言支持方面,它提供了 SQL、Python、.NET、Java、Scala 和 R 等多種語言的選擇。這使其非常適合不同的分析工作負載和不同的工程配置文件。
一切都包含在 Synapse Analytics Studio 中,可以輕松地將人工智能、機器學習、物聯網、智能應用程序或商業智能集成到同一個統一平臺中。
使用 T-SQL 和 Spark
關于執行時間,它允許兩個引擎。一方面是傳統的 SQL 引擎 (T-SQL),另一方面是 Spark 引擎。通過這種方式,可以將 T-SQL 用于批處理、流式處理和交互式處理,或者在需要使用 Python、Scala、R 或 .NET 進行大數據處理時使用 Spark。
在這里,它直接鏈接到 Azure Databricks,這是一種基于 Apache Spark 的人工智能和宏數據分析服務,允許在交互式工作區中對共享項目進行自動可擴展性和協作。Azure Synapse 在兩種服務之間提供了一個高性能連接器,可實現快速數據傳輸。這意味著可以繼續使用 Azure Databricks(Apache Spark 的優化)和專門用于提取、轉換和加載 (ETL) 工作負載的數據架構,以大規模準備和塑造數據。反過來,Azure Synapse 和 Azure Databricks 可以對 Azure Data Lake Storage 中的相同數據運行分析。
Azure Synapse 和 Azure Databricks 為我們提供了更大的機會,可以將分析、商業智能和數據科學解決方案與服務之間的共享數據湖相結合。
在實現最大兼容性和功率的道路上
最初,Microsoft 服務是作為公司必須面對的兩個基本問題的解決方案而提出的。首先是兼容性。它集成的數據分析系統能夠同時處理傳統系統和非結構化數據以及各種數據源。因此,它能夠分析存儲在系統中的數據,例如客戶數據庫(姓名和地址位于像電子表格一樣排列的行和列中)以及存儲在數據湖中的鑲木地板格式的數據。
但它還在自動處理任務以構建用于分析數據的系統方面提供了更大的多功能性。這種增強的功能直接導致減少了程序員所需的工作量,并延長了項目開發時間(它是第一個也是唯一一個以 PB 級執行所有 TPC-H 查詢的分析系統)。
Azure Synapse 實現了需要幾個月的項目可以在幾天內完成,或者需要幾分鐘或幾小時的復雜數據庫查詢現在只需幾秒鐘。
毫秒內成功協商
除了單獨擴展進程和存儲資源之外,Azure Synapse Analytics 還因其結果緩存功能而脫穎而出(它具有完全托管的 1 TB 緩存)。因此,當進行查詢時,它會存儲在此緩存中,以加快使用相同類型數據的下一個查詢。
這是它能夠在毫秒內引發響應的關鍵之一。這是因為緩存在暫停、恢復和擴展操作(可以通過為云設計的大規模并行處理架構非常快速地激活)中幸存下來。
工作負載和性能
同樣值得注意的是它對 JSON 的全面支持、數據屏蔽以確保高水平的安全性、對 SSDT(SQL Server 數據工具)的支持,尤其是工作負載管理以及如何對其進行優化和隔離。在這里,多個工作負載共享實現的資源。這使得創建工作負載并為其分配 CPU 數量和并發性成為可能。
例如,在擁有 1000 個 DWU(數據倉庫單元)的情況下,Azure Synapse 有助于將工作的一部分分配給銷售,另一部分分配給市場營銷(例如 60% 分配給一個,40% 分配給另一個)。這個想法是為了便于管理和優先考慮數據庫查詢。
在數據準備和攝取方面,它支持以集成方式流式傳輸(Native SQL Streaming)以生成分析,例如與事件中心或物聯網中心集成。它通過實現高達 200MB/秒的高性能、以秒為單位的交付延遲、隨計算規模擴展的攝取性能以及使用基于 Microsoft SQL 的組合、聚合、過濾器查詢的分析能力來實現這一目標……
一些附加功能
最后,我們必須強調 Azure Synapse Analytics 的其他有趣方面,這些方面有助于加快數據加載和促進流程。其中有:
- 對于數據準備和加載,復制命令不再需要外部表,因為它允許您將表直接加載到數據庫中。
- 它提供對標準 CSV 的全面支持:換行符和自定義分隔符以及 SQL 日期。
- 提供用戶控制的文件選擇(通配符支持)
- 機器學習支持:可以以 ONNX 格式創建和保存機器學習模型,這些模型存儲在 Azure Synapse 數據存儲中并與本機 PREDICT 指令一起使用。
與 Data Lake 集成:來自 Azure Synapse,文件以 Parquet 格式在 Data Lake 中讀取,從而實現了更高的性能,將 Polybase 執行提高了 13 倍以上。
簡而言之,一種保證開發線的服務,以確保 SQL DW 客戶可以繼續在生產中運行現有的數據存儲工作負載并自動受益于新功能。
本文轉載自微信公眾號「超級架構師」,可以通過以下二維碼關注。轉載本文請聯系超級架構師公眾號。