ICLR 2022|唯快不破!面向極限壓縮的全二值化BiBERT
本文經AI新媒體量子位(公眾號ID:QbitAI)授權轉載,轉載請聯系出處。
近年來,預訓練語言模型在自然語言處理上表現出色,但其龐大的參數量阻礙了它在真實世界的硬件設備上的部署。
近日,機器學習頂會ICLR 2022接收論文結果已經正式公布,至少有9項工作展示了神經網絡量化方向的相關進展。
本文將介紹首個用于自然語言任務的全二值量化BERT模型——BiBERT,具有高達56.3倍和31.2倍的FLOPs和模型尺寸的節省。
這項研究工作由北京航空航天大學劉祥龍教授團隊、南洋理工大學和百度公司共同完成。

預訓練語言模型在自然語言處理上表現出色,但其龐大的參數量阻礙了它在真實世界的硬件設備上的部署。
現有的模型壓縮方法包括參數量化、蒸餾、剪枝、參數共享等等。
其中,參數量化方法高效地通過將浮點參數轉換為定點數表示,使模型變得緊湊。
研究者們提出了許多方案例如Q-BERT[1]、Q8BERT[2]、GOBO[3]等,但量化模型仍舊面臨嚴重的表達能力有限和優化困難的問題。
幸運的是,知識蒸餾作為一種慣用的輔助優化的手段,令量化模型模仿全精度教師模型的特征表達,從而較好地解決精度損失問題。
在本文中,來自北航、NTU、百度的研究人員提出了BiBERT,將權重、激活和嵌入均量化到1比特(而不僅僅是將權重量化到1比特,而激活維持在4比特或更高)。
這樣能使模型在推理時使用逐位運算操作,大大加快了模型部署到真實硬件時的推理速度。
我們研究了BERT模型在二值化過程中的性能損失,作者在信息理論的基礎上引入了一個高效的Bi-Attention(二值注意力)機制,解決前向傳播中二值化后的注意力機制的信息退化問題;提出方向匹配蒸餾(Direction-Matching Distillation)方法,解決后向傳播中蒸餾的優化方向不匹配問題。
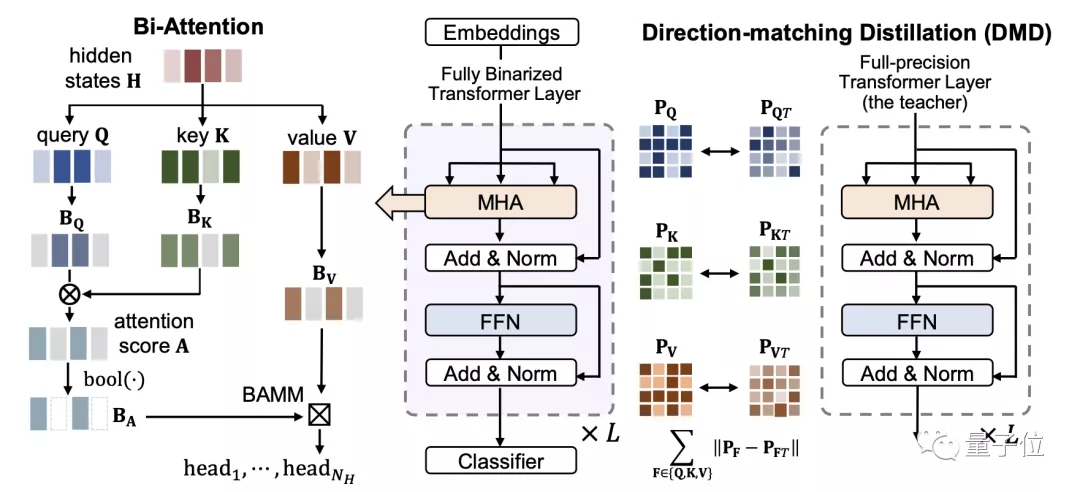
△圖 1 BiBERT的整體框架圖
BiBERT首次證明了BERT模型全二值化的可行性,在GLUE數據集上的準確性極大地超越了現有的BERT模型二值化算法,甚至超過了更高比特表示的模型。
在模型計算量和體積上,BiBERT理論上能夠帶來56.3倍和31.2倍的FLOPs和模型尺寸的減少。
方法
Bi-Attention:二值化注意力機制
我們的研究表明,在BERT模型的注意力機制中,softmax函數得到的歸一化注意力權重被視為遵循一個概率分布,而直接對其進行二值化會導致完全的信息喪失,其信息熵退化為0(見圖2)。
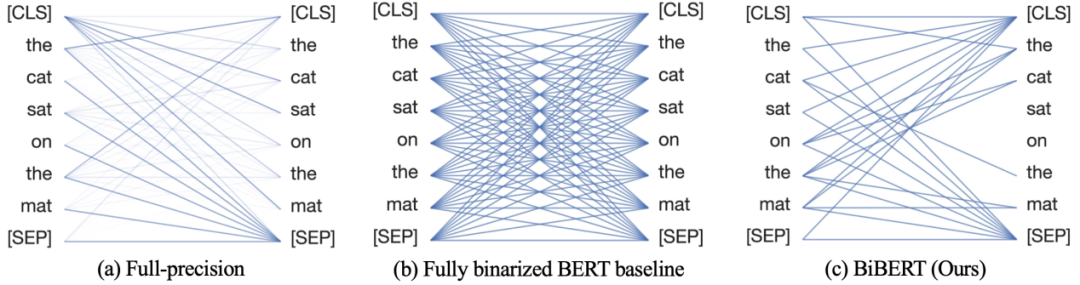
△圖 2 直接對softmax函數應用二值化導致完全的信息喪失
一個緩解這種信息退化的常用措施是,在應用sign函數之前對輸入張量的分布進行移位,可以表示為:
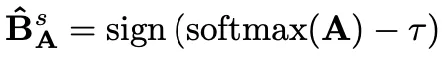
其中,移位參數也被認為是二值化的閾值,希望能使二值化后的熵達到最大。
我們注意到,softmax函數是保序的,這意味著存在一個固定的閾值使二值化表示的信息熵最大化。
受到Hard Attention的啟發[4],作者用bool函數來二值化注意力權重A:
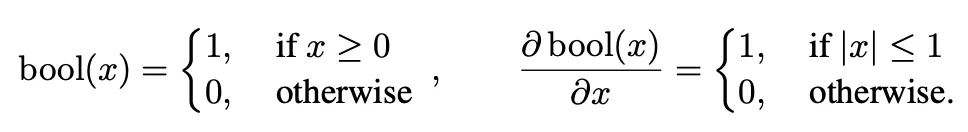
通過應用bool函數,注意權重中值較低的元素被二值化為0,因此得到的熵值最大的注意權重可以過濾出關鍵部分的元素。
最終二值注意力機制可以被表示為:
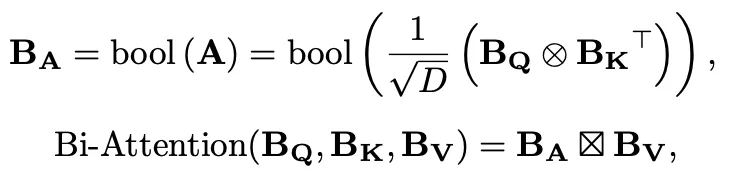
其中,BV是通過sign函數二值化得到的value值,BA是二值化注意力權重,是一個精心設計的Bitwise-Affine矩陣乘法 (BAMM)運算器,由和位移組成,用于對齊訓練和推理表征并進行有效的位計算。
DMD: 方向匹配蒸餾
作者發現,由于注意力權重是兩個二值化的激活直接相乘而得。
因此,處于決策邊緣的值很容易被二值化到相反一側,從而直接優化注意力權重常常在訓練過程中發生優化方向失配問題。(見圖3)
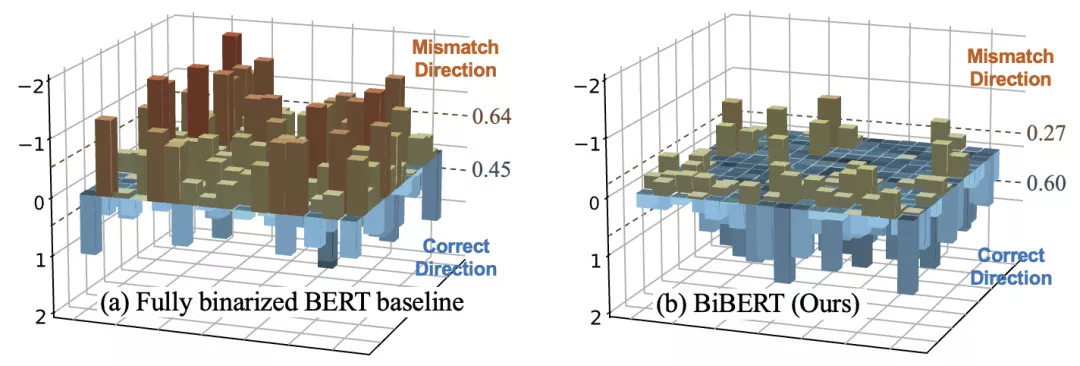
△圖 3 優化方向失配
因此,作者設計了新的蒸餾方案,即針對上游的Query、Key和Value矩陣,構建相似性矩陣進行對激活的蒸餾:
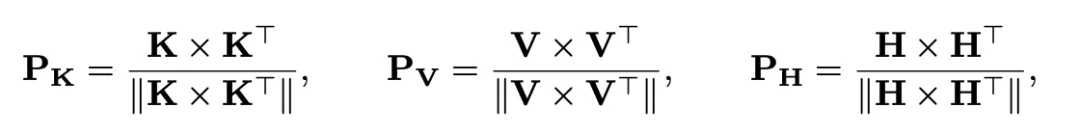
其中,||·||表示L2正則化。之前的研究工作表明,以這種方式構建的矩陣被認為能夠反映網絡對于特定模式的語義理解,并無視尺度和數值大小影響,能夠更加穩定地表示特征之間的內生相關性,更適合二值和全精度網絡之間的知識傳遞。
因此,蒸餾損失可以表示為對隱藏層、預測結果和上述激活相似性矩陣的損失之和:
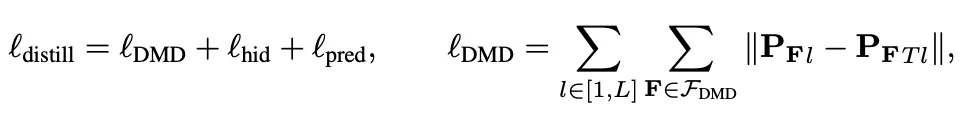
其中L表示transformer的層數,
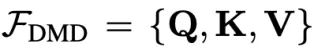
。
實驗
作者的實驗證明了所提出的BiBERT能夠出色地解決二值化BERT模型在GLUE基準數據集的部分任務上精度崩潰的問題,使模型能夠穩定優化。
表1表明所提出的Bi-Attention和DMD均可以顯著提升模型在二值化后的表現。
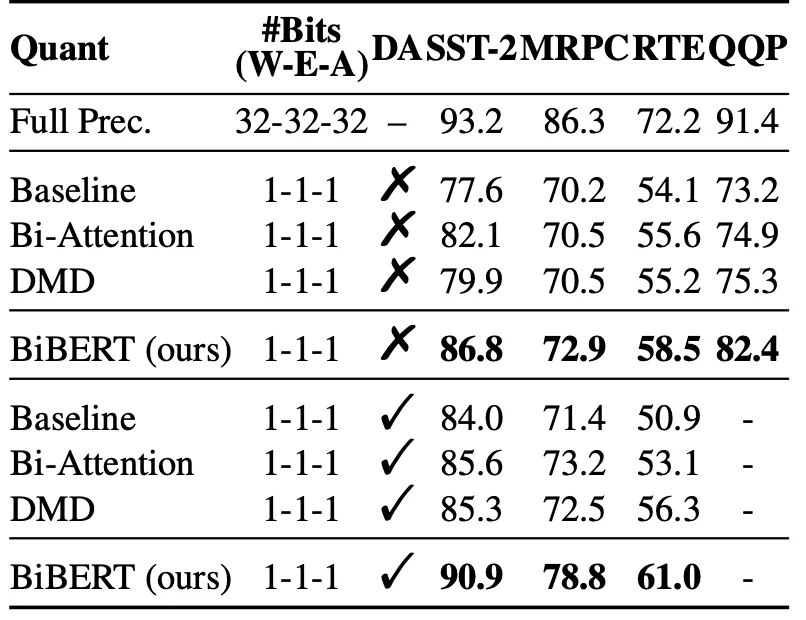
△表 1 消融實驗
表2和表3中,作者展示了BiBERT優于其他BERT二值化方法,甚至優于更高比特的量化方案:
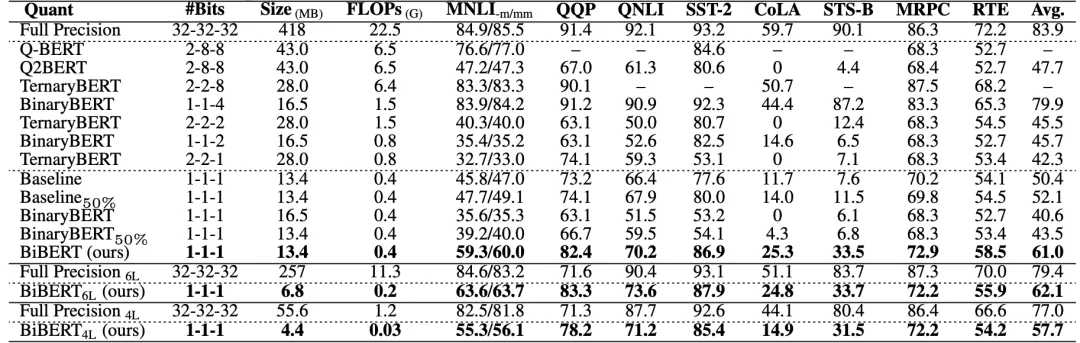
△表 2 基于BERT的二值化方法對比(無數據增強)
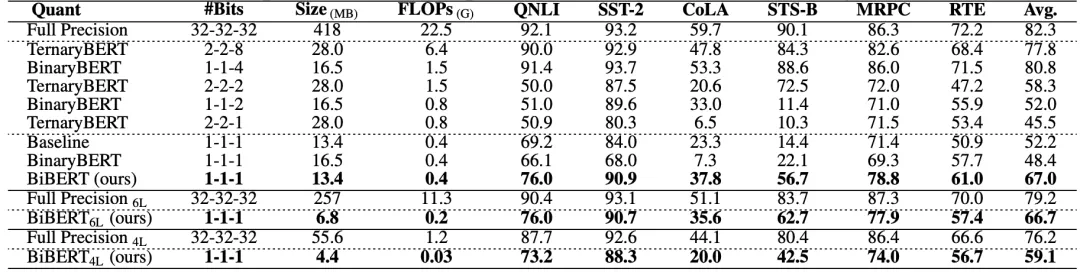
△表 3 基于BERT的二值化方法對比(有數據增強)
其中,50%表示要求二值化后有一半的注意力權重為0,且表中無特殊說明均采用12層的BERT模型進行量化。
此外,作者測量了在訓練過程中的信息熵(見圖4),作者提出的方法有效地恢復了注意力機制中完全損失的信息熵。
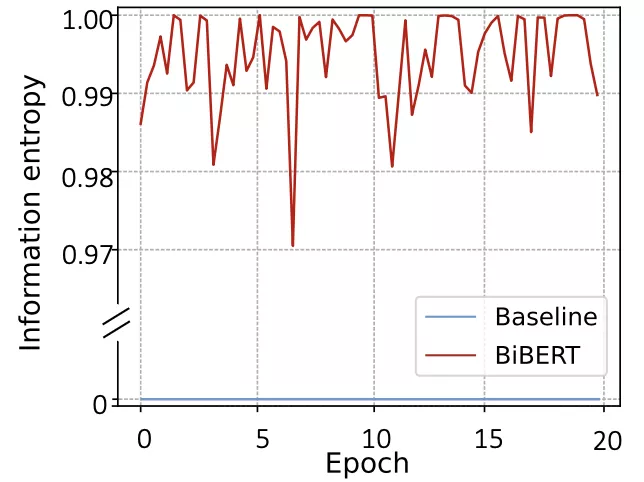
△圖 4 訓練過程中的信息熵
同時,作者繪制了訓練時的loss下降曲線和準確率,BiBERT相比于基線明顯更快收斂、準確性更高。
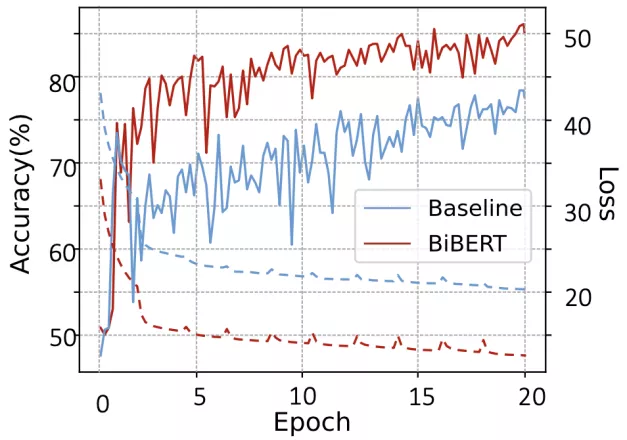
△圖 5 訓練時的Loss和準確率曲線
總結
作者提出的BiBERT作為第一個BERT模型的全二值化方法,為之后研究BERT二值化建立了理論基礎,并分析了其性能下降的原因,針對性地提出了Bi-Attention和DMD方法,有效提高模型的性能表現。
BiBERT超過了現有的BERT模型二值化方法,甚至優于采用更多比特的量化方案,理論上BiBERT能夠帶來56.3倍的FLOPs減少和31.2倍的模型存儲節省。
希望該的工作能夠為未來的研究打下堅實的基礎。
BiBERT即將基于百度飛槳開源深度學習模型壓縮工具PaddleSlim開源,盡情期待。
PaddleSlim:https://github.com/PaddlePaddle/PaddleSlim
傳送門
會議論文:https://openreview.net/forum?id=5xEgrl_5FAJ