聊聊高可用方法論!你知道嗎?
Part One 可用性概念一覽
永不停機總歸是不現實的。那么,在可操作性的范圍內,怎樣把影響降到最小,而影響又該怎么衡量呢?
概念一:MTBF (mean time between failure)
MTBF是指兩次相鄰的系統失效(服務故障)之間的工作時間長度。也可以叫它無故障時間 或 失效間隔。這個值越大,說明系統的故障率越低,系統越可靠。因此,我們通常希望這個時間間隔越大越好。
概念二:MTTR (mean time to repair)
MTTR是指從出現故障到修復中間的時間長度。也叫做修復時間。這個值越低,說明故障越容易恢復,系統可維護性越好。因此,我們通常希望這個時間間隔越小越好。
因此,系統可用性可以量化為:
MTBF / (MTBF + MTTR)
示例:系統的可用性要求 99.999% ,那么,按一年365天來算:
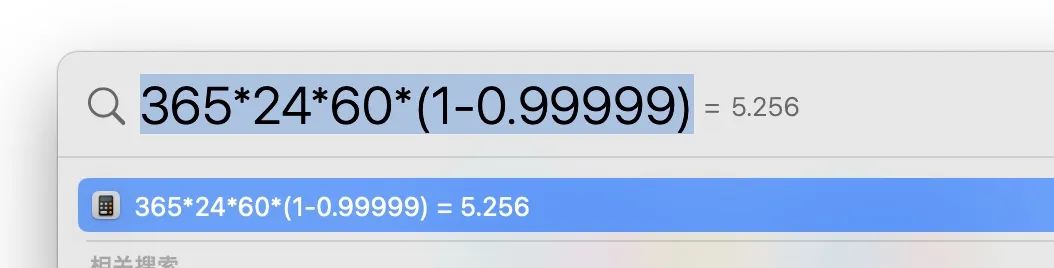
全年允許的宕機時間只有5分鐘多一點。
Part Two 高可用的保障
全年宕機5分鐘?從上一部分可以知道,我們的目的,是要盡可能的增大系統的無故障運行時間,同時,在發生故障時,盡可能迅速的完成恢復。
故障的發生多種多樣,經過了這么多年的研發前輩的踩坑,我們可以將其分類匯總,并給出分析和對應的方案。
Level1: 配置修改出錯
最不應該犯的錯,但是感覺很多人都沒少犯。
原因也很簡單,要不就是格式錯了,要不就是配置的數據不對,而且錯誤的配置還被直接發到了線上,直接導致業務異常,甚至宕機。
解決方案主要是兩部分:變更管控 + 配置灰度
- 用工單+審批的方式,讓配置變更流程化、正規化,提升配置變更的被重視程度。
- 利用配置灰度發布平臺功能,通過測試和灰度多環境的上線前驗證加上版本可回滾的能力,減少由于配置問題造成的可用性降級。

Level2: 代碼BUG
人為BUG往往是系統異常的罪魁禍首。coder? 不,請叫我buger ~ 雖然最是常見,但這一部分又是相對最容易應對的。
解決方案有兩個方面:
把控研發質量 + 測試質量:
- 需要通過系統分析文檔的撰寫和評審提前分析業務問題和系統邊界。
- 通過容錯設計、單側、CR來完善代碼的健壯性。
- 通過測試分析來明確測試重點和影響點。
- 通過線上請求錄制回放等仿真測試來保證原有的邏輯不受影響。

Level3: 依賴服務故障
業務高速發展,系統被水平垂直拆分,越來越復雜,幾乎沒有哪個系統可以獨立存在,總歸會有依賴。
然而,依賴系統在整個業務流程中占比很重,但我們自己又無法把控,因此,服務的依賴治理,是可用性保障中的非常重要的一環。
解決方案包括:
依賴梳理+指標約定+故障解決
- 首先,要根據業務本身的情況,梳理出強弱依賴,不同級別的依賴區分應對。比如,弱依賴就可以剝離主鏈路,采用異步或離線等方式進行;而強依賴如RPC中間件,就只能增加監控,提高問題發現速率。
- 其次,定制指標,做好指標監控和百分位預警。比如對依賴系統的調用量預估以及sla約定,達到百分位閾值時,及時報警
- 再次,制定故障預案,如主鏈路的限流、弱依賴的熔斷等。預案需要多次演練才能上線。

Level4: 突發流量和流量洪峰對應不足
讓業務按我們預先計劃的線路增長是不切實際的。吭哧癟肚做個需求想讓它漲10%,結果沒漲反而掉了,當你不注意的時候,突然來了一波上漲,都是很常見的事~
應對方法有兩個方面:
流量規律預估 + 異常流量防護
- 規律方面,要分析業務規律,合理安排策略,如請求排隊,提前擴容等。如打車場景,流量高峰(上下班)和流量突發(雨雪大風天)的情況都非常典型。為啥經常遇到司機吐槽接不到單,為啥一到雨雪天就要從派單模式切換成搶單模式,真的是因為選擇性突然變多了么~
- 異常流量方面,要讓上游協助減少無效重試,用緩存等策略防止底層服務雪崩。如電商商品詳情系統,一到晚上流量就徒增,爬蟲無疑;再如系統超時導致用戶不斷刷新的流量放大
Level5: 容量預估不足
上述的流量預估其實屬于容量預估的一個方面,除此之外,還有緩存容量、底層數據存儲容量、服務器容量、帶寬容量等等。
應對方案有四個方面:
容量規劃+限流降級+冗余+全鏈路壓測
- 前期,需要做好容量規劃和容量預警方案,爭取把可能的突發流量都考慮在內,核心模塊盡量實現冗余部署、容災部署;同時,利用多維度的報警,盡量早和及時的發現容量問題。
- 故障發生時,依據前面提到的依賴服務治理方案,根據重要程度的不同,進行限流、降級或熔斷。減少對容量的持續沖擊。
- 故障發生后,利用冗余部署,快速切換路由,分擔當前單元的容量壓力。
- 單服務壓測只能摸到當前服務的高度,但是這個高度是否滿足全鏈路的要求,就需要全鏈路去呀,這個時候,全局統一的路由、影子庫等的基礎建設就至關重要了。
Level6: 硬件甚至整個機房故障
相比于動則百萬造價的大型服務器,普通計算機以及docker的穩定性要大打折扣。因此,宕機是難免的事,除了服務器,還有交換機甚至是光纖抖動都有可能發生。
而應對方案有兩個方面:分散+冗余:
- 正所謂不要把雞蛋都裝到一個籃子里,而要多分幾個籃子裝。這樣,一個籃子打了,不至于影響全部雞蛋。螞蟻的單元化部署就是這個思路,不同的用戶按ID分到不同的處理單元,因此,就算這個單元全宕了,最差的情況也只會影響到這個單元的用戶群。
- 冗余,則是有備無患的思想。主從互備、同城機房互備、兩地三中心、三地五中心則是這個思路的具體落地。
Part Three 總結
越是重要的系統,對高可用的要求越高。而高可用的治理,會很考驗整個技術團隊的技術沉淀。如果后面大家遇到對系統可用性非常敏感的情況,希望本文可以對大家的思路和著手點有所幫忙。